Multi Modality Arena
1.0.0
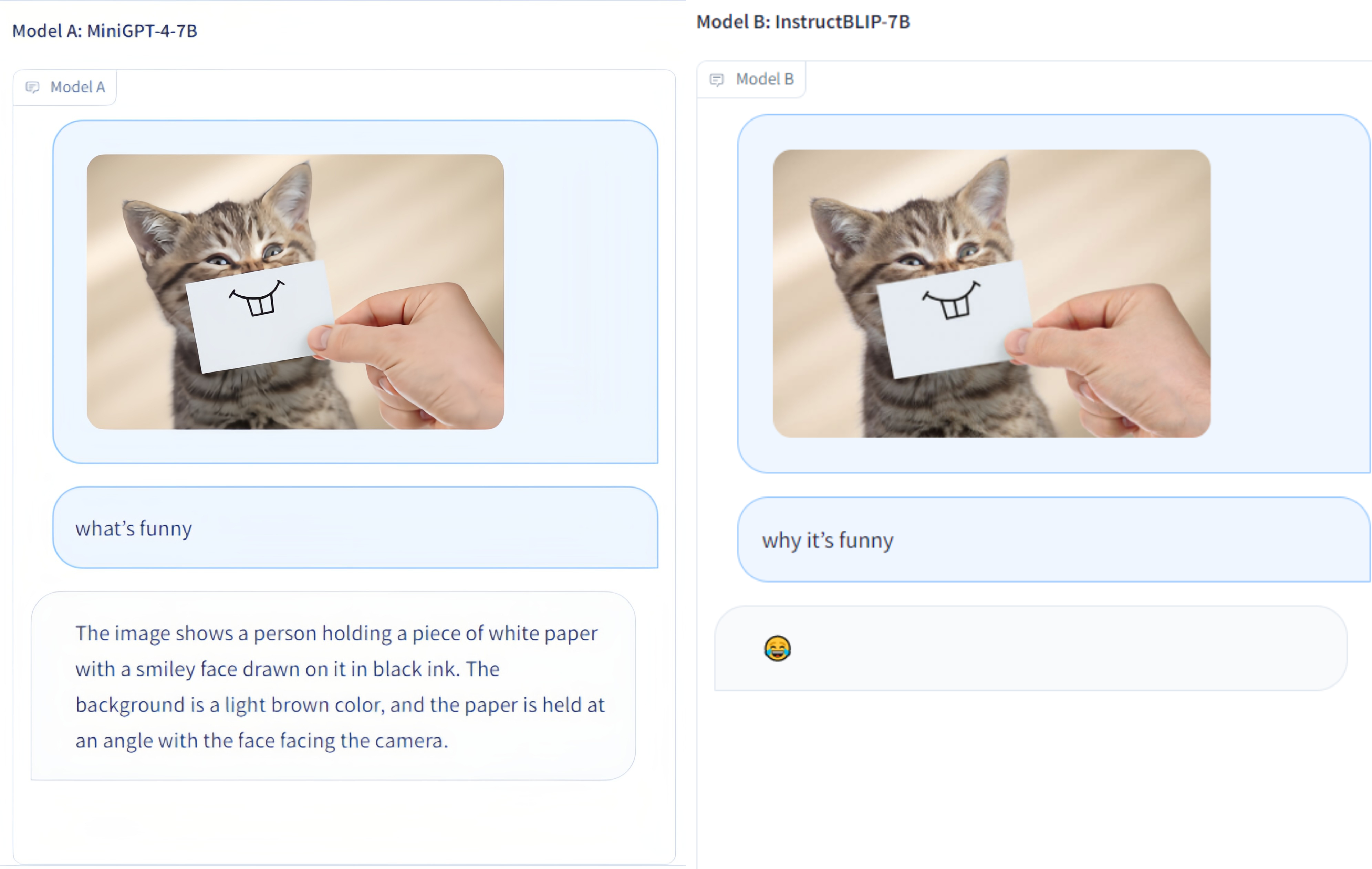
Multi-Modality Arena عبارة عن منصة تقييم للنماذج الكبيرة متعددة الوسائط. بعد Fastchat، تتم مقارنة نموذجين مجهولين جنبًا إلى جنب في مهمة مرئية للإجابة على الأسئلة. نصدر العرض التوضيحي ونرحب بمشاركة الجميع في مبادرة التقييم هذه.
مجموعة بيانات OmniMedVQA: تحتوي على 118,010 صورة مع 127,995 عنصر ضمان الجودة، تغطي 12 طريقة مختلفة وتشير إلى أكثر من 20 منطقة تشريحية بشرية. يمكن تنزيل مجموعة البيانات من هنا.
12 نموذجًا: 8 نماذج LVLM للمجال العام و4 نماذج LVLM متخصصة في المجال الطبي.
مجموعات بيانات صغيرة: 50 عينة فقط تم اختيارها عشوائيًا لكل مجموعة بيانات، أي 42 معيارًا مرئيًا مرتبطًا بالنص و2.1 ألف عينة إجمالاً لسهولة الاستخدام.
المزيد من النماذج: 4 نماذج أخرى، أي 12 نموذجًا إجمالاً، بما في ذلك Google Bard .
تقييم مجموعة ChatGPT : تحسين التوافق مع التقييم البشري مقارنة بنهج مطابقة الكلمات السابق.
LVLM-eHub هو معيار تقييم شامل للنماذج الكبيرة متعددة الوسائط المتاحة للجمهور (LVLM). ويقيم على نطاق واسع
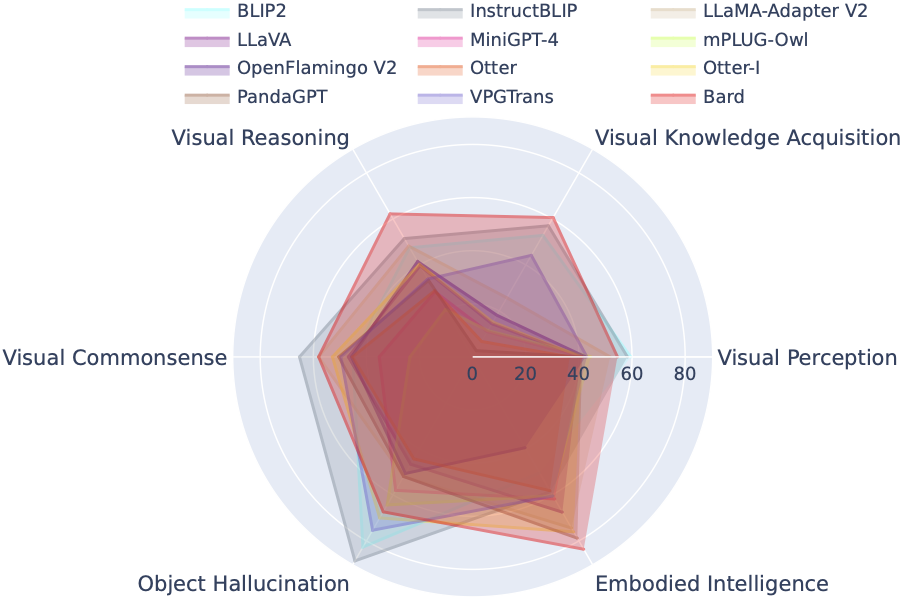
تقوم لوحة المتصدرين LVLM بتصنيف مجموعات البيانات الواردة في تقييم Tiny LVLM بشكل منهجي وفقًا لقدراتها المستهدفة المحددة بما في ذلك الإدراك البصري، والتفكير البصري، والحس البصري السليم، واكتساب المعرفة البصرية، وهلوسة الأشياء. تتضمن لوحة المتصدرين هذه نماذج تم إصدارها مؤخرًا لتعزيز شموليتها.
يمكنك تنزيل المعيار من هنا، ويمكن العثور على مزيد من التفاصيل هنا.
| رتبة | نموذج | إصدار | نتيجة |
|---|---|---|---|
| 1 | InterVL | InterVL-دردشة | 327.61 |
| 2 | InterLM-XComposer-VL | InterLM-XComposer-VL-7B | 322.51 |
| 3 | بارد | بارد | 319.59 |
| 4 | كوين-VL-دردشة | كوين-VL-دردشة | 316.81 |
| 5 | لافا-1.5 | فيكونا-7 ب | 307.17 |
| 6 | InstructBLIP | فيكونا-7 ب | 300.64 |
| 7 | InterLM-XComposer | إنترLM-XComposer-7B | 288.89 |
| 8 | بليب2 | فلانت5xl | 284.72 |
| 9 | بليفا | فيكونا-7 ب | 284.17 |
| 10 | الوشق | فيكونا-7 ب | 279.24 |
| 11 | الفهد | فيكونا-7 ب | 258.91 |
| 12 | LLaMA-Adapter-v2 | لاما-7ب | 229.16 |
| 13 | VPGTrans | فيكونا-7 ب | 218.91 |
| 14 | صورة قضاعة | أوتر-9B-LA-InContext | 216.43 |
| 15 | فيجوالGLM-6B | فيجوالGLM-6B | 211.98 |
| 16 | mPLUG-البومة | لاما-7ب | 209.40 |
| 17 | لافا | فيكونا-7 ب | 200.93 |
| 18 | ميني جي بي تي-4 | فيكونا-7 ب | 192.62 |
| 19 | قضاعة | أوتر-9ب | 180.87 |
| 20 | OFv2_4BI | بيجامة حمراء-INCITE-Instruct-3B-v1 | 176.37 |
| 21 | بانداGPT | فيكونا-7 ب | 174.25 |
| 22 | لافين | لاما-7ب | 97.51 |
| 23 | هيئة التصنيع العسكري | فلانت5xl | 94.09 |
31 مارس 2024. أطلقنا OmniMedVQA، وهو معيار تقييم شامل واسع النطاق لـ LVLMs الطبية. وفي الوقت نفسه، نحن 8 LVLMs للمجال العام و 4 LVLMs متخصصة في الطب. لمزيد من التفاصيل، يرجى زيارة موقع MedicalEval.
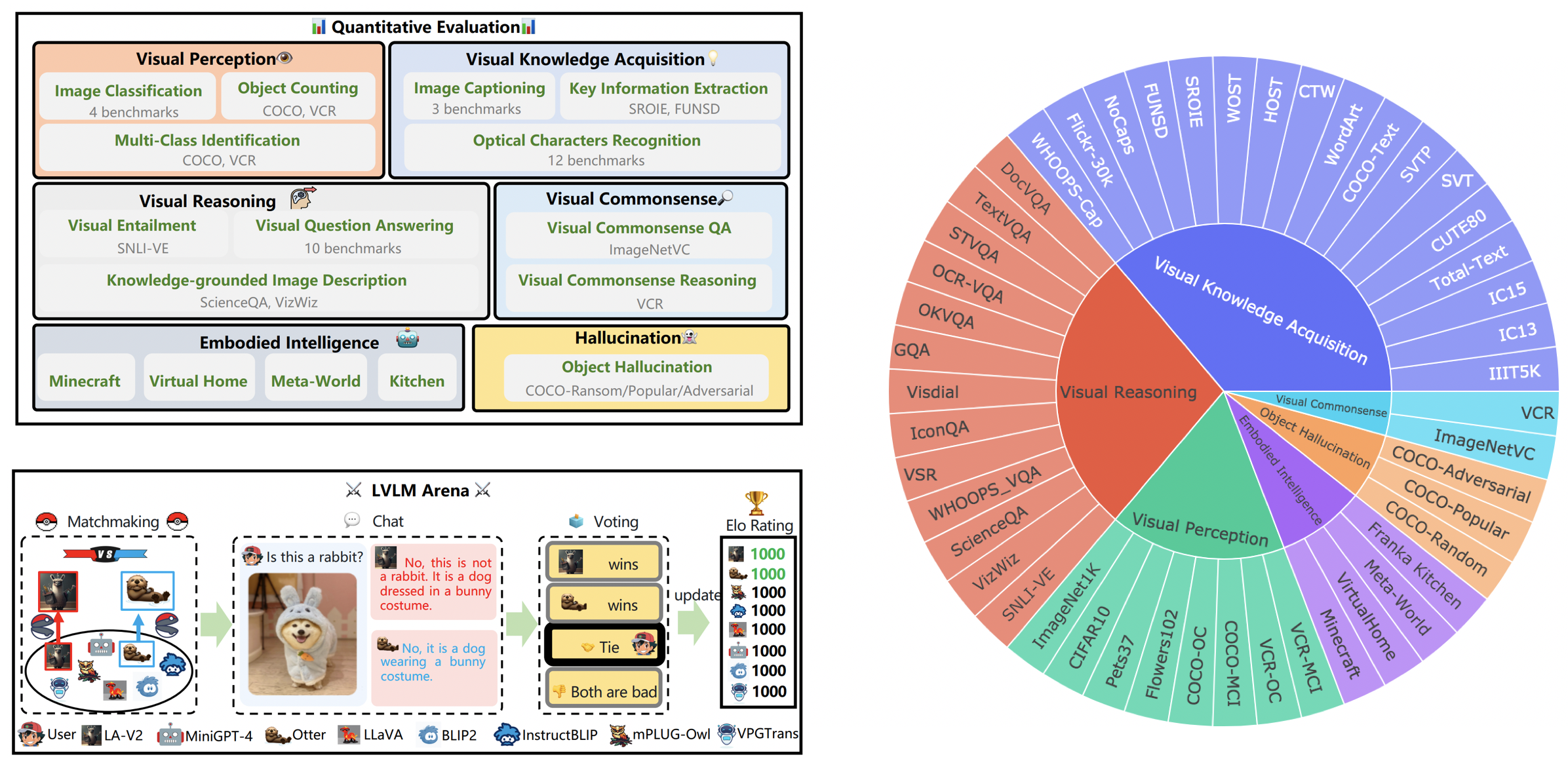
16 أكتوبر 2023. نقدم مجموعة بيانات مقسمة على مستوى القدرة مستمدة من LVLM-eHub، مكملة بتضمين ثمانية نماذج تم إصدارها مؤخرًا. للوصول إلى تقسيمات مجموعة البيانات، ورمز التقييم، ونتائج الاستدلال النموذجي، وجداول الأداء الشاملة، يرجى زيارة tiny_lvlm_evaluation ✅.
8 أغسطس 2023. أصدرنا [Tiny LVLM-eHub] . أكواد مصدر التقييم ونتائج الاستدلال النموذجي مفتوحة المصدر ضمن tiny_lvlm_evaluation.
15 يونيو 2023. أطلقنا [LVLM-eHub] ، وهو معيار تقييم لنماذج لغة الرؤية الكبيرة. الكود قادم قريبا.
8 يونيو 2023. شكرًا دكتور تشانغ، مؤلف VPGTrans، على تصحيحاته. يأتي مؤلفو VPGTrans أساسًا من جامعة سنغافورة الوطنية وجامعة تسينغهوا. لقد واجهنا سابقًا بعض المشكلات البسيطة عند إعادة تنفيذ VPGTrans، لكننا وجدنا أن أدائه أفضل بالفعل. لمزيد من المؤلفين النموذجيين، يرجى الاتصال بي للمناقشة على البريد الإلكتروني. يرجى أيضًا اتباع قائمة تصنيف النماذج لدينا، حيث ستتوفر نتائج أكثر دقة.
يمكن. 22 تشرين الثاني (نوفمبر) 2023. شكرًا دكتور يي، مؤلف mPLUG-Owl، على تصحيحاته. لقد قمنا بإصلاح بعض المشكلات البسيطة في تنفيذنا لـ mPLIG-Owl.
النماذج التالية تشارك في معارك عشوائية حاليا،
جامعة الملك عبد الله/MiniGPT-4
سيلزفورس/BLIP2
Salesforce/InstructBLIP
أكاديمية دامو/mPLUG-Owl
NTU/أوتر
جامعة ويسكونسن ماديسون/LLaVA
مختبر شنغهاي للذكاء الاصطناعي/llama_adapter_v2
NUS/VPGTrans
يمكن العثور على مزيد من التفاصيل حول هذه النماذج على ./model_detail/.model.jpg . سنحاول جدولة موارد الحوسبة لاستضافة المزيد من النماذج متعددة الوسائط في الساحة.
إذا كنت مهتمًا بأي جزء من منصة VLarena الخاصة بنا، فلا تتردد في الانضمام إلى مجموعة Wechat.

إنشاء بيئة كوندا
conda create -n arena python=3.10 كوندا تفعيل الساحة
تثبيت الحزم المطلوبة لتشغيل وحدة التحكم والخادم
نقطة تثبيت numpy gradio uvicorn fastapi
بعد ذلك، قد يتطلب كل نموذج إصدارات متعارضة من حزم بايثون، نوصي بإنشاء بيئة محددة لكل نموذج بناءً على مستودع GitHub الخاص به.
للخدمة باستخدام واجهة مستخدم الويب، تحتاج إلى ثلاثة مكونات رئيسية: خوادم الويب التي تتفاعل مع المستخدمين، والعاملين النموذجيين الذين يستضيفون نموذجين أو أكثر، ووحدة التحكم لتنسيق خادم الويب والعاملين النموذجيين.
فيما يلي الأوامر التي يجب اتباعها في المحطة الطرفية الخاصة بك:
بيثون تحكم.py
تدير وحدة التحكم هذه العمال الموزعين.
بيثون model_worker.py - اسم النموذج SELECTED_MODEL - الجهاز TARGET_DEVICE
انتظر حتى تنتهي عملية تحميل النموذج وسترى "Uvicorn Running on...". سيقوم العامل النموذجي بتسجيل نفسه في وحدة التحكم. بالنسبة لكل عامل نموذج، تحتاج إلى تحديد النموذج والجهاز الذي تريد استخدامه.
بيثون server_demo.py
هذه هي واجهة المستخدم التي سيتفاعل معها المستخدمون.
باتباع هذه الخطوات، ستتمكن من خدمة نماذجك باستخدام واجهة مستخدم الويب. يمكنك فتح متصفحك والدردشة مع عارضة الأزياء الآن. إذا لم تظهر النماذج، فحاول إعادة تشغيل خادم ويب Gradio.
نحن نقدر بشدة جميع المساهمات التي تهدف إلى تحسين جودة تقييماتنا. يشتمل هذا القسم على جزأين رئيسيين: Contributions to LVLM Evaluation والمساهمات Contributions to LVLM Arena .
يمكنك الوصول إلى أحدث إصدار من رمز التقييم الخاص بنا في مجلد LVLM_evaluation. يشتمل هذا الدليل على مجموعة شاملة من أكواد التقييم، مصحوبة بمجموعات البيانات الضرورية. إذا كنت متحمسًا للمشاركة في عملية التقييم، فيرجى عدم التردد في مشاركة نتائج التقييم أو واجهة برمجة تطبيقات الاستدلال النموذجي معنا عبر البريد الإلكتروني على [email protected].
نعرب عن امتناننا لاهتمامك بدمج النموذج الخاص بك في LVLM Arena الخاص بنا! إذا كنت ترغب في دمج النموذج الخاص بك في ساحتنا، يرجى إعداد نموذج اختبار منظم على النحو التالي:
فئة ModelTester:def __init__(self, devices=None) -> لا شيء:# TODO: تهيئة النموذج والمعالجات المسبقة المطلوبةdef move_to_device(self, devices) -> لا شيء:# TODO: تُستخدم هذه الوظيفة لنقل النموذج بين وحدة المعالجة المركزية ووحدة المعالجة المركزية GPU (اختياري)def generator(self, image, question) -> str: # TODO: رمز استنتاج النموذج
علاوة على ذلك، نحن منفتحون على روابط الاستدلال النموذجي عبر الإنترنت، مثل تلك التي توفرها منصات مثل Gradio. مساهماتك موضع تقدير من كل قلبي.
نعرب عن امتناننا للفريق الموقر في ChatBot Arena وورقتهم البحثية Judging LLM-as-a-a-حكم لعملهم المؤثر، والذي كان بمثابة مصدر إلهام لمساعينا التقييمية في LVLM. نود أيضًا أن نعرب عن خالص تقديرنا لمقدمي LVLM، الذين ساهمت مساهماتهم القيمة بشكل كبير في تقدم وتقدم نماذج لغة الرؤية الكبيرة. أخيرًا، نشكر مقدمي مجموعات البيانات المستخدمة في LVLM-eHub.
المشروع عبارة عن أداة بحثية تجريبية للأغراض غير التجارية فقط. لديها ضمانات محدودة وقد تولد محتوى غير مناسب. ولا يمكن استخدامه لأي شيء غير قانوني أو ضار أو عنيف أو عنصري أو جنسي.


