GenDataAttribution
1.0.0
مشروع | ورق
شنغ يو وانغ 1 ، أليكسي أ. إفروس 2 ، جون يان تشو 1 ، ريتشارد تشانغ 3 .
جامعة كارنيجي ميلون 1 ، جامعة كاليفورنيا في بيركلي 2 ، أبحاث أدوبي 2
في ICCV، 2023.
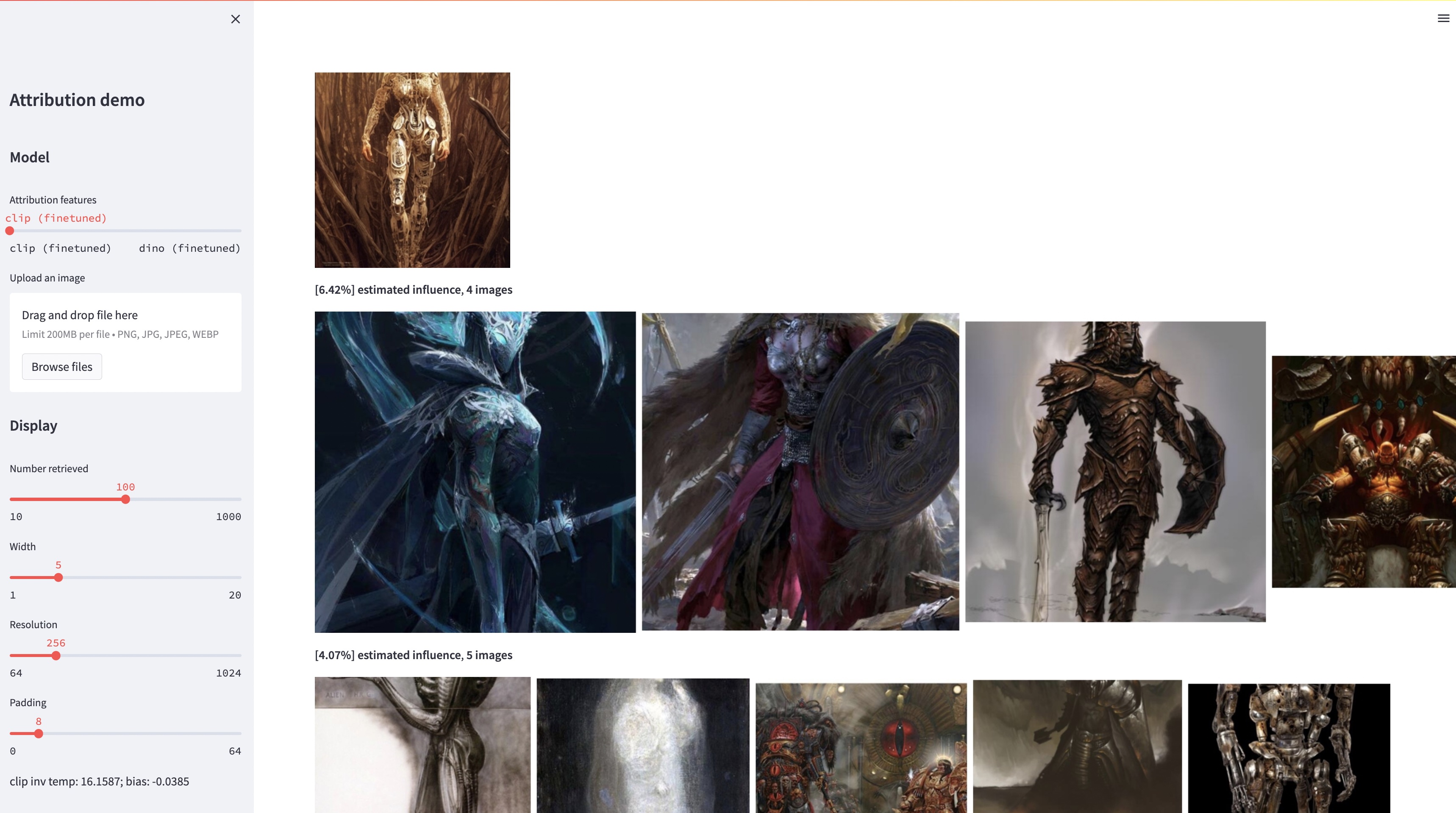
في حين أن نماذج تحويل النص إلى صورة كبيرة قادرة على تجميع صور "جديدة"، فإن هذه الصور هي بالضرورة انعكاس لبيانات التدريب. إن مشكلة إسناد البيانات في مثل هذه النماذج - أي الصور الموجودة في مجموعة التدريب هي الأكثر مسؤولية عن ظهور صورة معينة تم إنشاؤها - هي مشكلة صعبة ولكنها مهمة. كخطوة أولية تجاه هذه المشكلة، نقوم بتقييم الإسناد من خلال أساليب "التخصيص"، التي تعمل على ضبط نموذج موجود واسع النطاق تجاه كائن أو نمط نموذجي معين. رؤيتنا الرئيسية هي أن هذا يسمح لنا بإنشاء صور تركيبية بكفاءة تتأثر حسابيًا بالنموذج عن طريق البناء. ومن خلال مجموعة البيانات الجديدة الخاصة بنا والتي تحتوي على هذه الصور المتأثرة بالنموذج، يمكننا تقييم خوارزميات إسناد البيانات المختلفة ومساحات الميزات المحتملة المختلفة. علاوة على ذلك، من خلال التدريب على مجموعة البيانات الخاصة بنا، يمكننا ضبط النماذج القياسية، مثل DINO وCLIP وViT، تجاه مشكلة الإسناد. على الرغم من أن الإجراء تم ضبطه نحو مجموعات نموذجية صغيرة، إلا أننا نعرض التعميم على مجموعات أكبر. أخيرًا، من خلال الأخذ في الاعتبار عدم اليقين المتأصل في المشكلة، يمكننا تعيين درجات إسناد بسيطة لمجموعة من صور التدريب.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh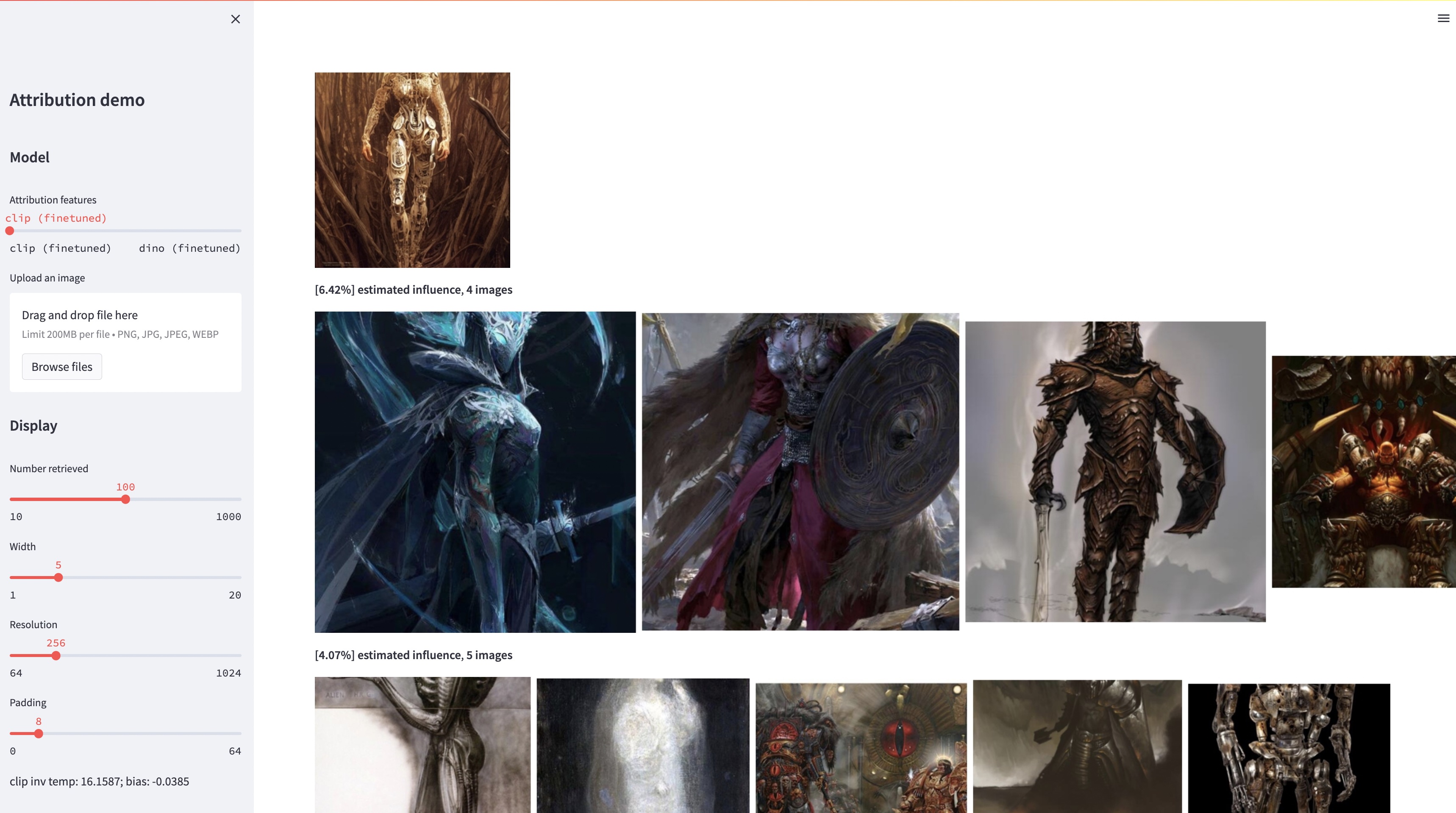
streamlit run streamlit_demo.pyنصدر مجموعة الاختبارات الخاصة بنا للتقييم. لتحميل مجموعة البيانات:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionيتم تنظيم مجموعة البيانات على النحو التالي:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
يتم تخزين جميع الصور النموذجية في dataset/exemplar ، ويتم تخزين جميع الصور المركبة في dataset/synth ، ويتم تخزين مليون صورة Laion في pngs في dataset/laion_subset . تحدد ملفات JSON في dataset/json تقسيمات القطار/val/test، بما في ذلك حالات الاختبار المختلفة، وتكون بمثابة تسميات الحقيقة الأساسية. يعد كل إدخال داخل ملف JSON نموذجًا فريدًا تم ضبطه بدقة. يسجل الإدخال أيضًا الصورة (الصور) النموذجية المستخدمة في الضبط الدقيق والصور المركبة التي تم إنشاؤها بواسطة النموذج. لدينا أربع حالات اختبار: test_artchive.json و test_bamfg.json و test_observed_imagenet.json و test_unobserved_imagenet.json .
بعد مجموعة الاختبار، يتم تنزيل ميزات LAION المحسوبة مسبقًا والأوزان المُدربة مسبقًا، يمكننا حساب الميزات مسبقًا من مجموعة الاختبار عن طريق تشغيل extract_feat.py ، ثم تقييم الأداء عن طريق تشغيل eval.py فيما يلي البرامج النصية bash التي تقوم بتشغيل التقييم على دفعات:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh يتم تخزين المقاييس في ملفات .pkl في results . حاليًا، يقوم البرنامج النصي بتشغيل كل أمر بالتسلسل. لا تتردد في تعديله لتشغيل الأوامر بالتوازي. سيقوم الأمر التالي بتحليل ملفات .pkl إلى جداول مخزنة كملفات .csv :
python results_to_csv.py تحديث 18/12/2023 لتنزيل النماذج التي تم تدريبها فقط على النماذج المرتكزة على الكائنات أو المرتكزة على النمط، قم بتشغيل bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
نشكر آرون هيرتزمان على قراءته مسودة سابقة وعلى تعليقاته الثاقبة. نشكر الزملاء في Adobe Research، بما في ذلك Eli Shechtman، وOliver Wang، وNick Kolkin، وTaesung Park، وJohn Collomosse، وSylvain Paris، إلى جانب Alex Li وYonglong Tian على المناقشة المفيدة. نحن نقدر نوبور كوماري لتوجيهاته بشأن التدريب على النشر المخصص، وRuihan Gao لمراجعة المسودة، وAlex Li للحصول على مؤشرات لاستخراج ميزات Stable Diffusion، وDan Ruta للمساعدة في مجموعة بيانات BAM-FG. نشكر بريان راسل على التنزه الوبائي والعصف الذهني. بدأ هذا العمل عندما كان SYW متدربًا في Adobe وكان مدعومًا جزئيًا بهدية Adobe وجائزة أبحاث كلية JP Morgan Chase.