amazon bedrock rag
1.0.0
إن عملية الاسترجاع المعزز (RAG) هي عملية تحسين مخرجات نموذج لغة كبير، لذلك فهي تشير إلى قاعدة معرفية موثوقة خارج مصادر بيانات التدريب الخاصة بها قبل إنشاء استجابة. يتم تدريب نماذج اللغات الكبيرة (LLMs) على كميات هائلة من البيانات وتستخدم مليارات من المعلمات لإنشاء مخرجات أصلية لمهام مثل الإجابة على الأسئلة وترجمة اللغات وإكمال الجمل. تعمل RAG على توسيع القدرات القوية بالفعل لـ LLM إلى مجالات محددة أو قاعدة المعرفة الداخلية للمؤسسة، كل ذلك دون الحاجة إلى إعادة تدريب النموذج. إنه نهج فعال من حيث التكلفة لتحسين مخرجات LLM بحيث يظل مناسبًا ودقيقًا ومفيدًا في سياقات مختلفة. تعرف على المزيد حول RAG هنا.
Amazon Bedrock هي خدمة مُدارة بالكامل توفر مجموعة مختارة من نماذج الأساس عالية الأداء (FMs) من شركات الذكاء الاصطناعي الرائدة مثل AI21 Labs وAnthropic وCohere وMeta وStability AI وAmazon عبر واجهة برمجة تطبيقات واحدة، إلى جانب مجموعة واسعة من القدرات التي تحتاجها لإنشاء تطبيقات ذكاء اصطناعي منتجة تتمتع بالأمان والخصوصية والذكاء الاصطناعي المسؤول. باستخدام Amazon Bedrock، يمكنك بسهولة تجربة وتقييم أفضل FMs لحالة الاستخدام الخاصة بك، وتخصيصها بشكل خاص باستخدام بياناتك باستخدام تقنيات مثل الضبط الدقيق وRAG، وإنشاء وكلاء ينفذون المهام باستخدام أنظمة مؤسستك ومصادر البيانات. نظرًا لأن Amazon Bedrock لا يحتوي على خادم، فلن يتعين عليك إدارة أي بنية تحتية، ويمكنك دمج ونشر قدرات الذكاء الاصطناعي التوليدية بشكل آمن في تطبيقاتك باستخدام خدمات AWS التي تعرفها بالفعل.
قواعد المعرفة لـ Amazon Bedrock هي إمكانية مُدارة بالكامل تساعدك على تنفيذ سير عمل RAG بالكامل بدءًا من الاستيعاب وحتى الاسترجاع والزيادة السريعة دون الحاجة إلى إنشاء عمليات تكامل مخصصة لمصادر البيانات وإدارة تدفقات البيانات. تم تضمين إدارة سياق الجلسة، بحيث يمكن لتطبيقك دعم المحادثات متعددة الأدوار بسهولة.
كجزء من إنشاء قاعدة معارف، يمكنك تكوين مصدر بيانات ومخزن متجه من اختيارك. يتيح لك موصل مصدر البيانات توصيل بياناتك الخاصة بقاعدة المعرفة. بمجرد تكوين موصل مصدر البيانات، يمكنك مزامنة بياناتك أو تحديثها باستمرار مع قاعدة معارفك وإتاحة بياناتك للاستعلام عنها. تقوم Amazon Bedrock أولاً بتقسيم المستندات أو المحتوى الخاص بك إلى أجزاء يمكن التحكم فيها من أجل استرجاع البيانات بكفاءة. يتم بعد ذلك تحويل القطع إلى تضمينات وكتابتها في فهرس متجه (تمثيل متجه للبيانات)، مع الحفاظ على التعيين للمستند الأصلي. تسمح التضمينات المتجهة بمقارنة النصوص رياضيًا من أجل التشابه.
يتم تنفيذ هذا المشروع باستخدام مصدرين للبيانات؛ مصدر بيانات للمستندات المخزنة في Amazon S3 ومصدر بيانات آخر للمحتوى المنشور على موقع الويب. يتم إنشاء مجموعة بحث متجهة في Amazon OpenSearch Serverless لتخزين المتجهات.
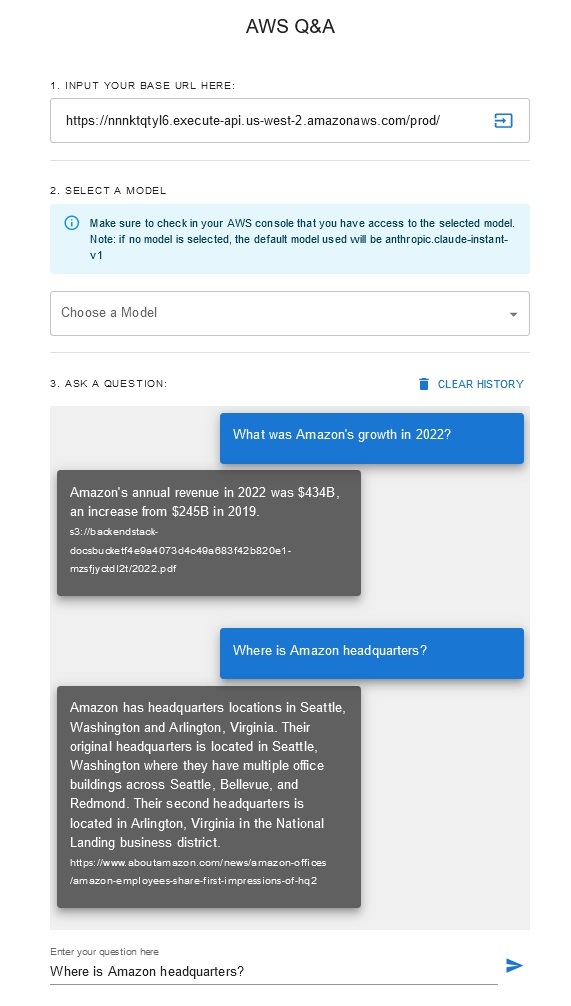
سؤال وجواب Chatbot 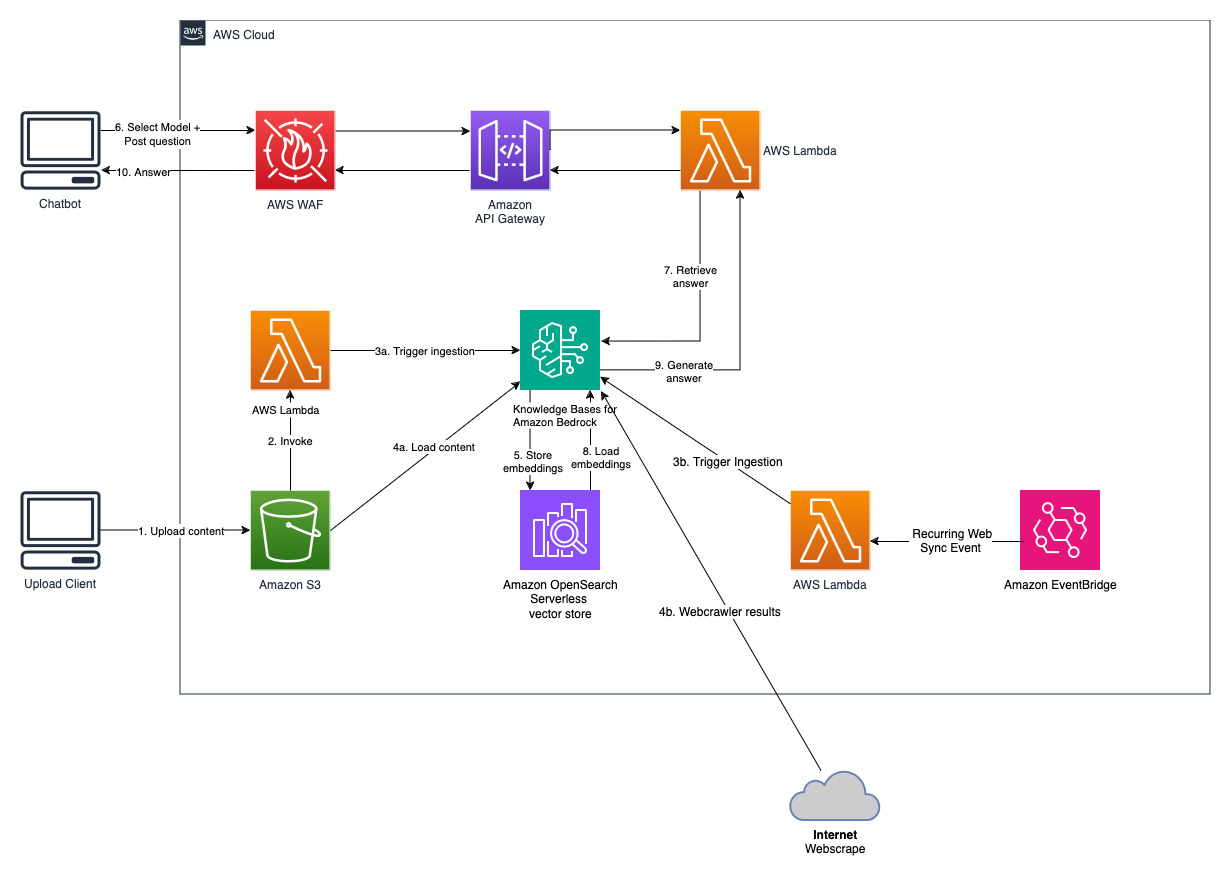
إضافة مواقع ويب جديدة لمصدر بيانات الويب 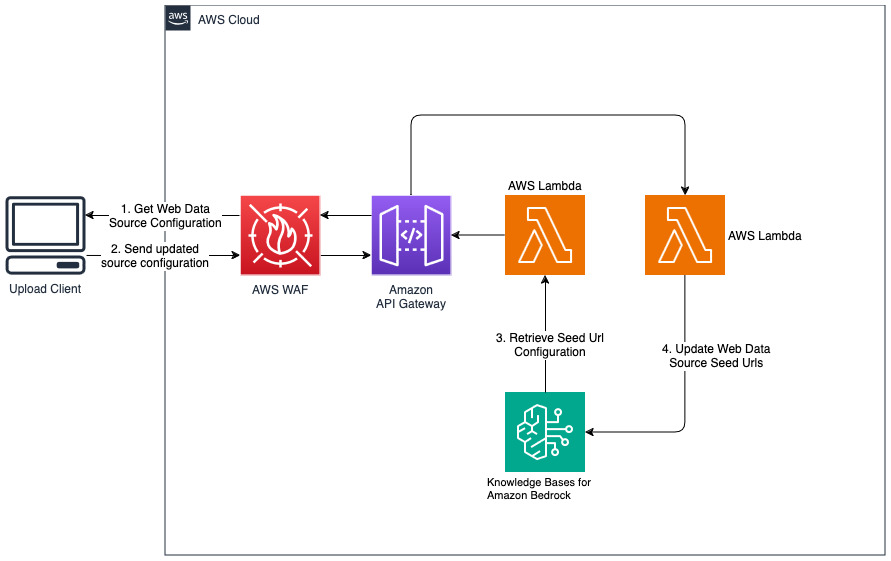
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
قم بتوفير عنوان IP للعميل المسموح له بالوصول إلى بوابة API بتنسيق CIDR كجزء من متغير السياق "allowedip".
عند اكتمال النشر،
يتيح هذا الحل للمستخدمين تحديد النموذج الأساسي الذي يريدون استخدامه أثناء مرحلة الاسترجاع والتوليد. النموذج الافتراضي هو Anthropic Claude Instant . بالنسبة لنموذج تضمين قاعدة المعرفة، يستخدم هذا الحل Amazon Titan Embeddings G1 - نموذج النص . تأكد من أنه يمكنك الوصول إلى نماذج الأساس هذه.
احصل على تقرير سنوي حديث متاح للجمهور من Amazon وانسخه إلى اسم حاوية S3 المذكور سابقًا. لإجراء اختبار سريع، يمكنك نسخ تقرير Amazon السنوي لعام 2022 باستخدام وحدة تحكم AWS S3. ستتم مزامنة المحتوى من حاوية S3 تلقائيًا مع قاعدة المعرفة لأن نشر الحل يراقب المحتوى الجديد في حاوية S3 ويقوم بتشغيل سير عمل الاستيعاب.
يقوم الحل المنشور بتهيئة مصدر بيانات الويب المسمى "WebCrawlerDataSource" بعنوان URL https://www.aboutamazon.com/news/amazon-offices . تحتاج إلى مزامنة مصدر بيانات Web Crawler مع قاعدة المعرفة من وحدة تحكم AWS يدويًا للبحث في محتوى موقع الويب لأنه من المقرر أن يتم استيعاب موقع الويب في المستقبل. حدد مصدر البيانات هذا من المعرفة المستندة إلى وحدة تحكم Amazon Bedrock وابدأ عملية "المزامنة". راجع مزامنة مصدر بياناتك مع قاعدة معارف Amazon Bedrock للحصول على التفاصيل. لاحظ أن محتوى موقع الويب سيكون متاحًا لبرنامج الدردشة الآلي للأسئلة والأجوبة فقط بعد اكتمال المزامنة. يرجى استخدام هذا التوجيه عند إعداد مواقع الويب كمصدر بيانات.
استخدم "cdk Destroy" لحذف مجموعة الموارد السحابية التي تم إنشاؤها في نشر هذا الحل.


