EasyNLU
1.0.0
EasyNLU هي مكتبة لفهم اللغة الطبيعية (NLU) مكتوبة بلغة Java لتطبيقات الأجهزة المحمولة. نظرًا لكونه يعتمد على القواعد النحوية، فهو مناسب تمامًا للمجالات الضيقة ولكنها تتطلب تحكمًا مشددًا.
يحتوي المشروع على نموذج لتطبيق Android يمكنه جدولة التذكيرات من خلال إدخال اللغة الطبيعية:
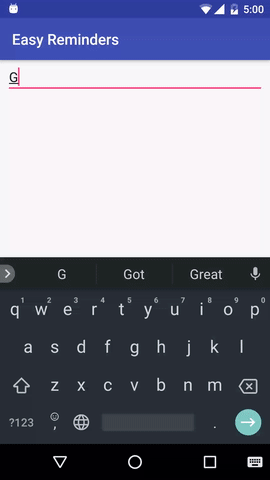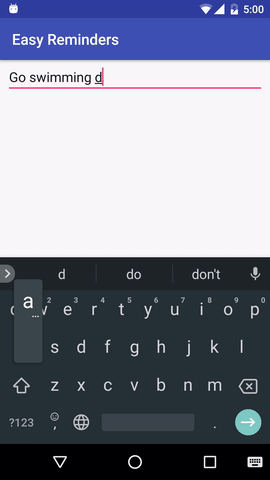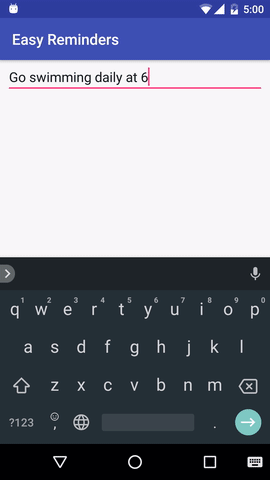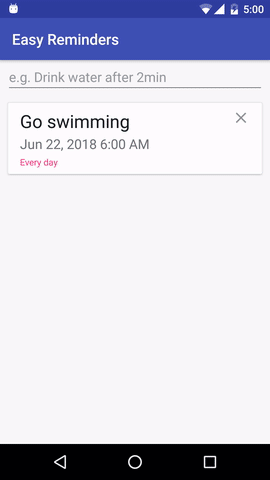
تم ترخيص EasyNLU بموجب Apache 2.0.
EasyNLU في جوهره هو محلل دلالي يعتمد على CCG. يمكن العثور على مقدمة جيدة للتحليل الدلالي هنا. يمكن للمحلل الدلالي تحليل مدخلات مثل:
اذهب إلى طبيب الأسنان في الساعة 5 مساءً غدًا
في شكل منظم:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
يوفر EasyNLU النموذج المنظم كخريطة Java متكررة. يمكن بعد ذلك تحويل هذا النموذج المنظم إلى كائن محدد للمهمة يتم "تنفيذه". على سبيل المثال، في نموذج المشروع، يتم تحويل النموذج المنظم إلى كائن Reminder يحتوي على حقول مثل task startTime repeat ويستخدم لإعداد إنذار باستخدام خدمة AlarmManager.
بشكل عام، فيما يلي الخطوات عالية المستوى لإعداد إمكانية NLU:
قبل كتابة أي قواعد، يجب علينا تحديد نطاق المهمة ومعلمات النموذج المنظم. كمثال على لعبة، لنفترض أن مهمتنا هي تشغيل وإيقاف ميزات الهاتف مثل Bluetooh وWifi وGPS. إذن الحقول هي:
مثال على النموذج المنظم سيكون:
{feature: "bluetooth", action: "enable" }
كما أنه من المفيد الحصول على بعض نماذج المدخلات لفهم الاختلافات:
بالاستمرار في مثال اللعبة، يمكننا القول أنه في المستوى الأعلى لدينا إجراء إعداد يجب أن يكون له ميزة وإجراء. ثم نستخدم القواعد لالتقاط هذه المعلومات:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" ); تحتوي القاعدة على LHS وRHS كحد أدنى. وفقًا للاتفاقية، نقوم بإضافة "$" إلى الكلمة للإشارة إلى فئة ما. تمثل الفئة مجموعة من الكلمات أو الفئات الأخرى. في القواعد المذكورة أعلاه، يمثل $Feature كلمات مثل bluetooth وbt وwifi وما إلى ذلك والتي نلتقطها باستخدام القواعد "المعجمية":
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
); لتطبيع الاختلافات في أسماء الميزات، نقوم ببناء $Features في ميزات فرعية:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); مماثل لـ $Action :
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
); لاحظ "؟" وفي القاعدة الثالثة؛ وهذا يعني أن فئة $Switch اختيارية. لتحديد ما إذا كان التحليل ناجحًا، يبحث المحلل اللغوي عن فئة خاصة تسمى الفئة الجذرية. حسب الاصطلاح يُشار إليه بـ $ROOT . نحتاج إلى إضافة قاعدة للوصول إلى هذه الفئة:
Rule root = new Rule ( "$ROOT" , "$Setting" );باستخدام هذه المجموعة من القواعد، يجب أن يكون المحلل اللغوي لدينا قادرًا على تحليل الأمثلة المذكورة أعلاه، وتحويلها إلى ما يسمى بأشجار بناء الجملة.
الإعراب ليس جيدًا إذا لم نتمكن من استخراج معنى الجملة. يتم التقاط هذا المعنى من خلال النموذج المنظم (الشكل المنطقي في لغة البرمجة اللغوية العصبية). في EasyNLU نقوم بتمرير معلمة ثالثة في تعريف القاعدة لتحديد كيفية استخراج الدلالات. نستخدم بناء جملة JSON مع علامات خاصة للقيام بذلك:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first يخبر المحلل اللغوي باختيار قيمة الفئة الأولى من قاعدة RHS. في هذه الحالة سيكون إما "تمكين" أو "تعطيل" بناءً على الجملة. تشمل العلامات الأخرى ما يلي:
@identity : وظيفة الهوية@last : اختر قيمة فئة RHS الأخيرة@N : اختر قيمة فئة N RHS، على سبيل المثال @3 سيختار الفئة الثالثة@merge : دمج قيم جميع الفئات. سيتم دمج القيم المسماة فقط (على سبيل المثال {action: enable} )@append : إلحاق قيم جميع الفئات في القائمة. يجب تسمية القائمة الناتجة. يُسمح فقط بالقيم المسماةبعد إضافة العلامات الدلالية تصبح قواعدنا:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);إذا لم يتم توفير معلمة الدلالات، فسيقوم المحلل اللغوي بإنشاء قيمة افتراضية تساوي RHS.
لتشغيل المحلل اللغوي، قم باستنساخ هذا المستودع واستيراد وحدة المحلل اللغوي إلى مشروع Android Studio/IntelliJ الخاص بك. يأخذ المحلل اللغوي EasyNLU كائنًا Grammar يحتوي على القواعد، وكائن Tokenizer لتحويل جملة الإدخال إلى كلمات وقائمة اختيارية من كائنات Annotator للتعليق على كيانات مثل الأرقام والتواريخ والأماكن وما إلى ذلك. قم بتشغيل التعليمات البرمجية التالية بعد تحديد القواعد:
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));يجب أن تحصل على الإخراج التالي:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
جرب الاختلافات الأخرى. إذا فشل التحليل لمتغير العينة، فلن تحصل على أي مخرجات. يمكنك بعد ذلك إضافة القواعد أو تعديلها وتكرار عملية الهندسة النحوية.
يدعم EasyNLU الآن القوائم في النموذج المنظم. بالنسبة للمجال أعلاه، يمكنه التعامل مع المدخلات مثل
تعطيل الموقع عبر نظام تحديد المواقع العالمي (GPS).
أضف هذه القواعد الثلاث الإضافية إلى القواعد المذكورة أعلاه:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
قم بتشغيل استعلام جديد مثل:
System.out.println(parser.parse("disable location bt gps"));
يجب أن تحصل على هذا الإخراج:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
لاحظ أنه يتم تشغيل هذه القواعد فقط في حالة وجود أكثر من ميزة واحدة في الاستعلام
تعمل التعليقات التوضيحية على تسهيل التعامل مع أنواع معينة من الرموز المميزة التي قد تكون مرهقة أو مستحيلة تمامًا التعامل معها عبر القواعد. على سبيل المثال، خذ فئة NumberAnnotator . سوف يكتشف جميع الأرقام ويعلق عليها كـ $NUMBER . يمكنك بعد ذلك الإشارة مباشرة إلى الفئة في القواعد الخاصة بك، على سبيل المثال:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
يأتي EasyNLU حاليًا مع عدد قليل من التعليقات التوضيحية:
NumberAnnotator : يعلق على الأرقامDateTimeAnnotator : يعلق على بعض تنسيقات التاريخ. يوفر أيضًا قواعده الخاصة التي تضيفها باستخدام DateTimeAnnotator.rules()TokenAnnotator : يقوم بتعليق كل رمز مميز للإدخال كـ $TOKENPhraseAnnotator : يضيف تعليقًا توضيحيًا لكل عبارة متجاورة من الإدخال كـ $PHRASE لاستخدام أداة التعليق التوضيحي المخصصة الخاصة بك، قم بتطبيق واجهة Annotator وتمريرها إلى المحلل اللغوي. قم بالرجوع إلى التعليقات التوضيحية المضمنة للحصول على فكرة عن كيفية تنفيذ واحدة.
يدعم EasyNLU قواعد التحميل من الملفات النصية. يجب أن تكون كل قاعدة في سطر منفصل. يجب فصل LHS وRHS والدلالات بعلامات تبويب:
$EnableDisable ?$Switch $OnOff @last
احرص على عدم استخدام IDEs التي تقوم تلقائيًا بتحويل علامات التبويب إلى مسافات
مع إضافة المزيد من القواعد إلى المحلل اللغوي، ستجد أن المحلل اللغوي يعثر على تحليلات متعددة لمدخلات معينة. ويرجع ذلك إلى الغموض العام للغات البشرية. لتحديد مدى دقة المحلل اللغوي لمهمتك، يتعين عليك تشغيله من خلال أمثلة مصنفة.
مثل القواعد السابقة، تأخذ EasyNLU أمثلة محددة بنص عادي. يجب أن يكون كل سطر مثالًا منفصلاً ويجب أن يحتوي على النص الأولي والنموذج المنظم مفصولين بعلامة تبويب:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
من المهم أن تغطي عددًا أو اختلافات مقبولة في الإدخال. ستحصل على مزيد من التنوع إذا طلبت من أشخاص مختلفين القيام بهذه المهمة. يعتمد عدد الأمثلة على مدى تعقيد المجال. تحتوي مجموعة البيانات النموذجية المقدمة في هذا المشروع على أكثر من 100 مثال.
بمجرد حصولك على البيانات، يمكنك ذلك في مجموعة بيانات. يتم التعامل مع الجزء التعليمي من خلال وحدة trainer ؛ استيراده إلى المشروع الخاص بك. قم بتحميل مجموعة بيانات مثل هذا:
Dataset dataset = Dataset . fromText ( 'filename.txt' )نقوم بتقييم المحلل اللغوي لتحديد نوعين من الدقة
لإجراء التقييم نستخدم فئة Model :
Model model = new Model(parser);
model.evaluate(dataset, 2);
المعلمة الثانية لوظيفة التقييم هي المستوى المطول. كلما زاد الرقم، أصبح الإخراج أكثر تفصيلاً. تقوم وظيفة evaluate() بتشغيل المحلل اللغوي من خلال كل مثال وإظهار التحليلات غير الصحيحة التي تعرض الدقة في النهاية. إذا حصلت على كلا الدقة في التسعينات، فإن التدريب ليس ضروريًا، وربما يمكنك التعامل مع تلك التحليلات القليلة السيئة من خلال المعالجة اللاحقة. إذا كانت دقة أوراكل عالية ولكن دقة التنبؤ منخفضة، فإن تدريب النظام سيساعد. إذا كانت دقة أوراكل منخفضة في حد ذاتها، فأنت بحاجة إلى إجراء المزيد من الهندسة النحوية.
للحصول على التحليل الصحيح، نقوم بتسجيل النقاط واختيار النتيجة التي حصلت على أعلى الدرجات. يستخدم EasyNLU نموذجًا خطيًا بسيطًا لحساب النتائج. يتم إجراء التدريب باستخدام Stochastic Gradient Descent (SGD) مع وظيفة فقدان المفصلة. تعتمد ميزات الإدخال على عدد القواعد والحقول في النموذج المنظم. يتم بعد ذلك حفظ الأوزان المدربة في ملف نصي.
يمكنك ضبط بعض معلمات النموذج/التدريب للحصول على دقة أفضل. بالنسبة لنماذج التذكير، تم استخدام المعلمات التالية:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );قم بتشغيل كود التدريب كما يلي:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );سيؤدي هذا إلى تدريب النموذج لمدة 100 حقبة مع تقسيم اختبار التدريب إلى 0.8. سيعرض الدقة في مجموعة الاختبار ويحفظ أوزان النموذج في مسار الملف المقدم. للتدريب على مجموعة البيانات بأكملها، قم بتعيين معلمة النشر على "صحيح". يمكنك تشغيل الوضع التفاعلي وتلقي المدخلات من وحدة التحكم:
experiement.interactive();
ملحوظة: هذا التدريب ليس مضمونًا لإنتاج دقة عالية حتى مع وجود عدد كبير من الأمثلة. في بعض السيناريوهات، قد لا تكون الميزات المتوفرة تمييزية بدرجة كافية. إذا واجهتك مشكلة في مثل هذه الحالة، فيرجى تسجيل مشكلة ويمكننا العثور على ميزات إضافية.
أوزان النموذج عبارة عن ملف نصي عادي. بالنسبة لمشروع Android، يمكنك وضعه في مجلد assets وتحميله باستخدام AssetManager. يرجى الرجوع إلى ReminderNlu.java لمزيد من التفاصيل. يمكنك أيضًا تخزين أوزانك وقواعدك في السحابة وتحديث نموذجك عبر الهواء (أي شخص في Firebase؟).
بمجرد أن يقوم المحلل اللغوي بعمل جيد في تحويل إدخال اللغة الطبيعية إلى نموذج منظم، فمن المحتمل أنك ستحتاج إلى تلك البيانات في كائن مهمة محددة. بالنسبة لبعض المجالات مثل مثال اللعبة أعلاه، يمكن أن يكون الأمر واضحًا ومباشرًا. بالنسبة للآخرين، قد يتعين عليك حل الإشارات إلى أشياء مثل التواريخ والأماكن وجهات الاتصال وما إلى ذلك. في نموذج التذكير، غالبًا ما تكون التواريخ نسبية (على سبيل المثال "غدًا" أو "بعد ساعتين" وما إلى ذلك) والتي تحتاج إلى تحويلها إلى قيم مطلقة. الرجاء الرجوع إلى ArgumentResolver.java لمعرفة كيفية تنفيذ الحل.
نصيحة: حافظ على منطق الحل عند الحد الأدنى عند تحديد القواعد وقم بمعظمه في المعالجة اللاحقة. وسوف تبقي القواعد أبسط.


