docReader
1.0.0

التثبيت المفتوح لـ git clone https://github.com/KoBruhh/docReader.git pip install -r requirements.txt
أنواع الملفات المدعومة:
.png .jpeg .jpg .pdf .py .rs .c .cpp .js .txt .sh
الهدف الرئيسي هو ببساطة البحث عن الكلمات داخل الملفات الكبيرة في أنواع ملفات متنوعة (بما في ذلك ملفات الصور)
هناك برنامجان مختلفان في هذا الريبو:
-Python: ما عليك سوى الدخول إلى python dir باستخدام cd Python
وبعد ذلك، إذا كتبت ls فستشاهد بعض الأمثلة على الصور التي يمكنك تجربتها وأيضًا main.py وهو رمز يجب تنفيذه
اكتب: python main.py لتنفيذ البرنامج
اسحب مجلدًا إلى المحطة أو اكتبه يدويًا
أدخل كلمة للبحث
إذا عثر البرنامج على أي كلمة قدمتها، فسوف يقوم بطباعة <Your word> Found!
-Javascript لقد استخدمت Javascript/html/css لإنشاء موقع ويب بسيط لجعل الأمور أكثر روعة بعض الشيء. ولكن هناك مشكلة تتمثل في أنني لم أتمكن من التواصل بين python وjavascript بحيث يعمل إصدار واجهة المستخدم الرسومية فقط مع الملفات النصية! لتشغيل كود جافا سكريبت:
انتقل إلى المجلد الرئيسي للدليل وانتقل إلى مجلد GUI (JS) عن طريق cd GUI (JS)/
اكتب pwd وانسخ النتيجة
افتح أي متصفح والصقه في محرك البحث (في الأعلى) وأضف index.html إلى نهايته
يجب أن ترى شيئًا مثل هذا: 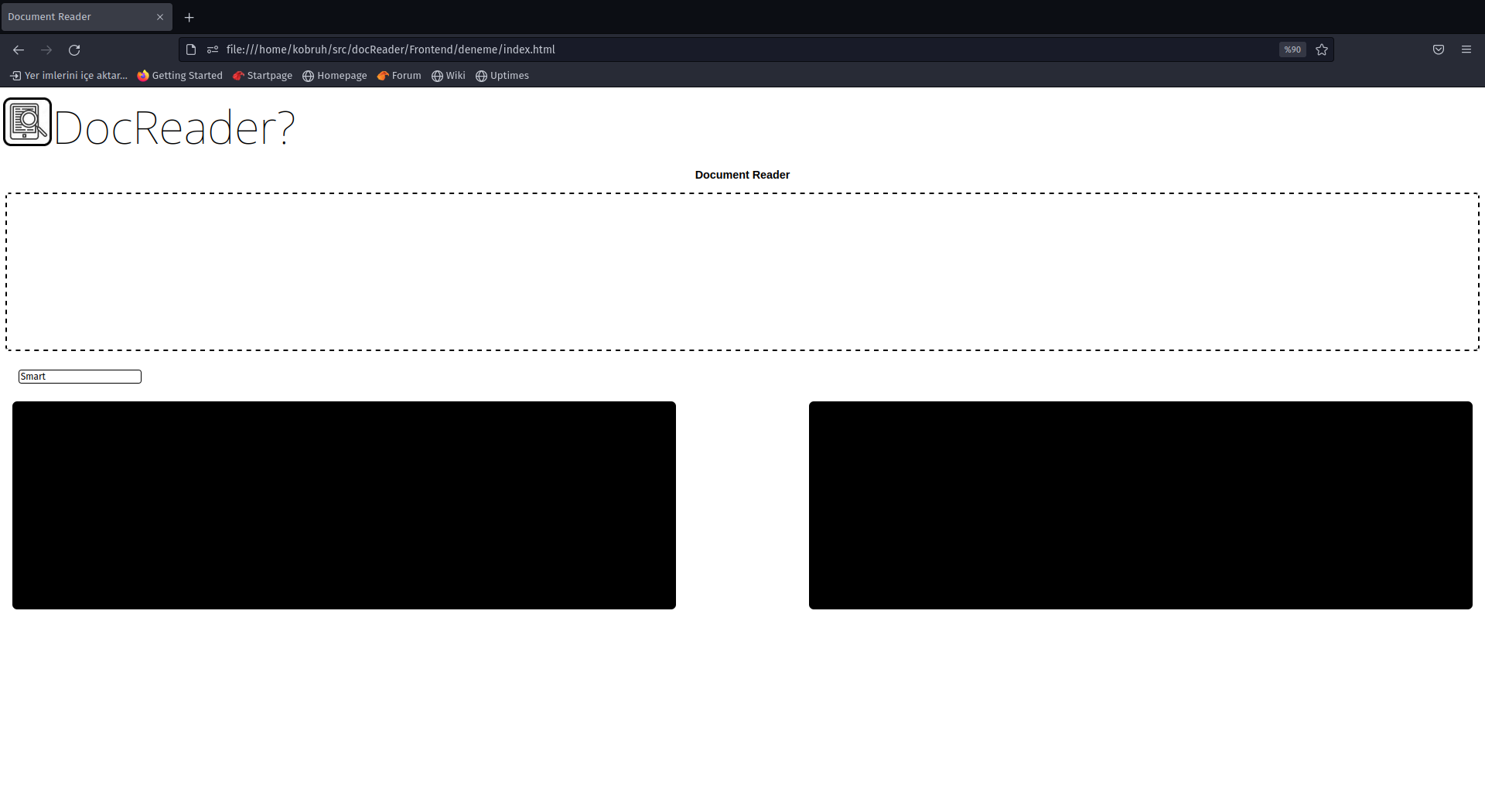
هنا يجب عليك سحب ملفك إلى المربع المتقطع أو النقر في أي مكان داخل المربع المتقطع وتحديد الملف الذي تريده (يجب أن يكون ملفًا نصيًا حتى يعمل!) اكتب كلمة للبحث داخل مربع النص المصغر (في الجانب الأيسر العلوي من الصندوق الأسود الأيمن) اضغط على زر الإدخال لتنشيط البحث وستحصل على الرد عبر الصندوق الأسود الأيمن
السلبيات - إنه قبيح جدًا (JS): ليس لدي أي خبرة تقريبًا في استخدام html وjs لذا فإن موقع الويب سيء.
- غير فعال إلى حد كبير (PY): بايثون بطيء جدًا في استخدامه في محرك البحث ولكن استخدام التعرف الضوئي على الحروف (OCR) مثل (الأشياء ذات الصلة بتعلم الآلة) تتم كتابته من أجل بايثون.
الأشياء التي لم أتمكن من تحقيقها:
- لم أتمكن من استخدام عدة لغات معًا. لذلك قمت بإنشاء إصدارات مختلفة من Js وPy.


