Sound Content Music Recommendation System
1.0.0

إذا كنت مثلي، فأنت تحب الموسيقى. أحب الموسيقى وأحب العثور على موسيقى جديدة. تعد Spotify واحدة من أفضل خدمات بث الموسيقى على الإنترنت، وهي تتضمن بالفعل أدوات مذهلة تساعدك على اكتشاف موسيقى جديدة بناءً على ما تستمع إليه. يقوم بذلك من خلال مجموعة من الخوارزميات المختلفة، بما في ذلك التصفية التعاونية حيث يتم تتبع الاستخدام المماثل بين المستخدمين واستخدامه لإنشاء توصيات أو توصيات قائمة على المحتوى والتي توصي بأغاني جديدة بناءً على معلومات مماثلة بين المعلومات المرتبطة بالأغنية. مثل أغنية؟ على Spotify، يمكنك الاستماع إلى "راديو" تلك الأغنية، والذي سيجمع مجموعة من الأغاني المشابهة لتلك الأغنية بطريقة ما أو بمجموعة من الطرق. ماذا لو كنت تحب أغنية، ولكنك لا تهتم بأي معلومات أخرى غير الصوت الموجود فيها؟ في بعض الأحيان، هذا هو كل ما أريد أن أسمعه.
لقد أنشأت هذا المشروع لإنشاء نظام توصية موسيقية يعتمد على المعلومات الموجودة في صوت الموسيقى وحده. سيساعد المستخدم في العثور على موسيقى جديدة من خلال الأغاني ذات الصوت المماثل. للقيام بذلك، سيستكشف أيضًا أوجه التشابه بين جميع الموسيقى، ويحاول التقاط جرس الأغنية وإيقاعها وأسلوبها رياضيًا.
الصوت موجود دائمًا حولنا. طوال حياتنا، ننمو لتمييز الأصوات المختلفة عن الآخرين. الموسيقى ليست مختلفة - هناك أنواع عديدة من الموسيقى، وغالبًا ما تكون الموسيقى عبارة عن مزيج من أنواع مختلفة من الأصوات والإيقاعات التي يمكننا أيضًا تمييزها عن الآخرين. ولكن هل يمكننا قياس هذه المعلومات بأنفسنا؟ في بعض الأحيان، يتم تصنيف الموسيقى إلى أنواع، مما يعني أن النوع هو مجموعة من الموسيقيين ذوي الصفات المماثلة في الأسلوب أو الشكل أو الإيقاع أو الجرس أو الآلات أو الثقافة. لكن ليس كل فنان موسيقي ينتج صوتًا من نفس النوع، وليس كل نوع يحتوي على نفس النوع من الموسيقى. إذن ما هو الصوت، وكيف نميز الأنواع المختلفة من الصوت؟
الصوت عبارة عن اهتزاز للموجات الصوتية التي ندركها من خلال آذاننا عندما تهتز تلك الموجات طبلة الأذن. الموجة الصوتية هي إشارة وتعرف السرعة التي تهتز بها تلك الإشارة بالتردد. إذا كان تردد الصوت أعلى، فإننا ندرك أن الصوت له طبقة صوت أعلى. في الموسيقى، ستُنشئ الآلات مثل طبول الجهير أو الطبول أصواتًا تهتز بتردد أقل، في حين أن درجات الصوت العالية لها تردد أعلى. الأصوات مثل اصطدام الصنج أو القبعة العالية هي مزيج من العديد من الموجات بترددات مختلفة ويتم تمثيلها بموجة "صاخبة" شبه عشوائية المظهر.
كيف يبدو الصوت؟ إحدى الطرق التي يمكننا من خلالها تصور الصوت هي رسم إشارة عبر الزمن:
عندما نقوم بتقصير النافذة الزمنية في كل قطعة فرعية، يمكننا رؤية إشارة الصوت أقرب بكثير. لاحظ في الصورة الأكثر تكبيرًا للإشارة أن الموجة عبارة عن مجموعة من الترددات المختلفة. قد تكون هناك إشارة واحدة منخفضة التردد تتحد مع إشارات أصغر عالية التردد.
لذلك يمكننا تصور إشارة مع مرور الوقت، ولكن يمكننا بالفعل أن نقول أنه من الصعب فهم الكثير عن تلك الموجة الصوتية بمجرد النظر إلى هذا التصور. ما أنواع الترددات الموجودة في نافذة الـ 0.01 ثانية تلك؟ للإجابة على ذلك، سوف نستخدم تحويل فورييه لحساب المخطط الطيفي.
تحويل فورييه هو طريقة لحساب سعة الترددات الموجودة في جزء من الإشارة الصوتية. كما ترون في الرسم البياني أعلاه، يمكن أن تكون الموجات معقدة وكل اختلاف في الإشارة يمثل ترددًا مختلفًا (سرعة الاهتزاز). سوف يقوم تحويل فورييه بشكل أساسي باستخراج الترددات لكل قسم من الوقت وينتج مصفوفة ثنائية الأبعاد من اتساع التردد مقابل الوقت. ناتج تحويل فورييه هو مخطط طيفي. من المخطط الطيفي، نقوم بتحويل الترددات المنتجة إلى مقياس ميل لإنشاء مخطط طيفي ميل. يمثل المخطط الطيفي ميل بشكل أفضل المسافة المحسوسة بين الترددات التي نسمعها.
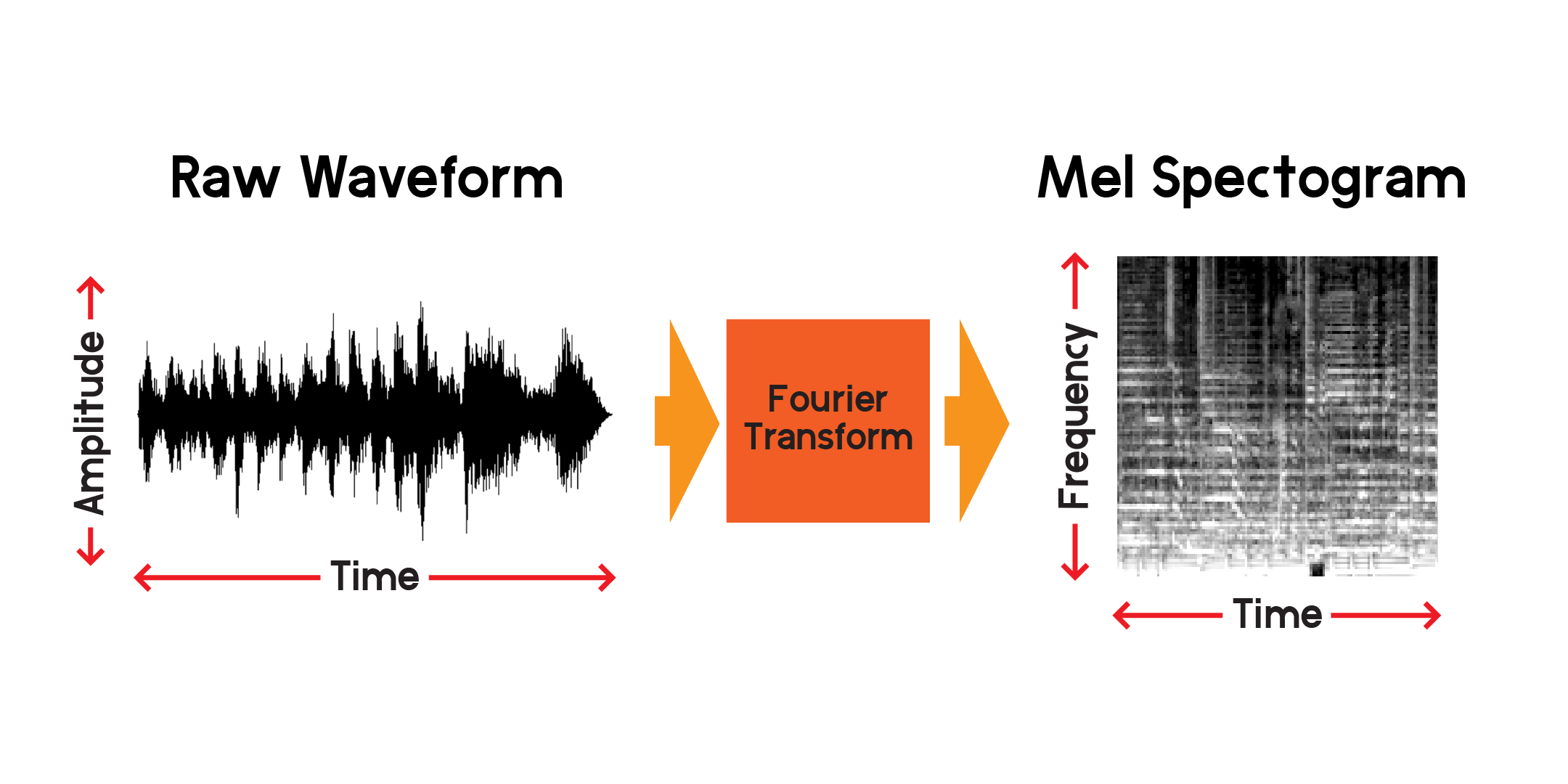
لنرسم مثالاً على مخطط طيفي ميل من نفس العينة الصوتية التي رسمناها أعلاه:
باستخدام واجهة API العامة لـ Spotify، قمت بجمع معلومات الأغنية في دفتر ملاحظات سابق. ومن هناك يمكنني تنزيل معاينة mp3 مدتها 30 ثانية لكل أغنية وتحويلها إلى مخطط طيفي ميل لاستخدامه في شبكة عصبية تتدرب على الصور. أولاً، دعونا نلقي نظرة على إطار البيانات، الذي سنستخدمه لجمع معاينات mp3.
في دفتر ملاحظات آخر، أخذت روابط معاينة من Spotify API، وقمت بتنزيل ملفات mp3، وقمت بتحويل ملفات الصوت إلى صورة مركبة تحتوي على مخطط ميل الطيفي، ومعامل Mel Frequency Cepstral، وChromagram. لقد أنشأت هذه الصورة المركبة بقصد استخدام هذه التحويلات الأخرى، لكن بالنسبة لهذا المشروع، سأقوم فقط بتدريب الشبكة العصبية على مخططات ميل الطيفية.
لتقديم توصيات لأغاني مماثلة بناءً على محتوى الصوت وحده، سأحتاج إلى إنشاء ميزات تشرح محتوى الأغاني بطريقة أو بأخرى. أيضًا، للقيام بذلك بسرعة، سأحتاج إلى ضغط معلومات كل أغنية في مجموعة أصغر من الأرقام مقارنة بإدخال مخططات ميل الطيفية.
لكل ملف معاينة أغنية، هناك أكثر من 600000 عينة. يوجد في كل مخطط طيفي ميل 512 × 128 بكسل بإجمالي 65,536 بكسل. حتى الصورة مقاس 128 × 128 تحتوي على 16384 بكسل. سيقوم نموذج التشفير التلقائي هذا بضغط محتوى الأغنية إلى 256 رقمًا فقط. بمجرد تدريب جهاز التشفير التلقائي بشكل كافٍ، ستكون الشبكة قادرة على إعادة بناء أغنية من هذا المتجه بطول 256 بأقل قدر من الخسارة.
جهاز التشفير التلقائي هو نوع من الشبكات العصبية التي تتكون من جهاز تشفير ووحدة فك تشفير . أولاً، سيقوم جهاز التشفير بضغط معلومات الإدخال إلى كمية أصغر بكثير من البيانات، وسيقوم جهاز فك التشفير بإعادة بناء البيانات لتكون أقرب إلى الإخراج الأصلي قدر الإمكان.
يعد جهاز التشفير التلقائي أيضًا نوعًا خاصًا من الشبكات العصبية حيث أنه لا يخضع للإشراف، على الرغم من أنه ليس غير خاضع للإشراف تمامًا. إنه خاضع للإشراف الذاتي لأنه يستخدم مدخلاته لتدريب مخرجات النموذج.
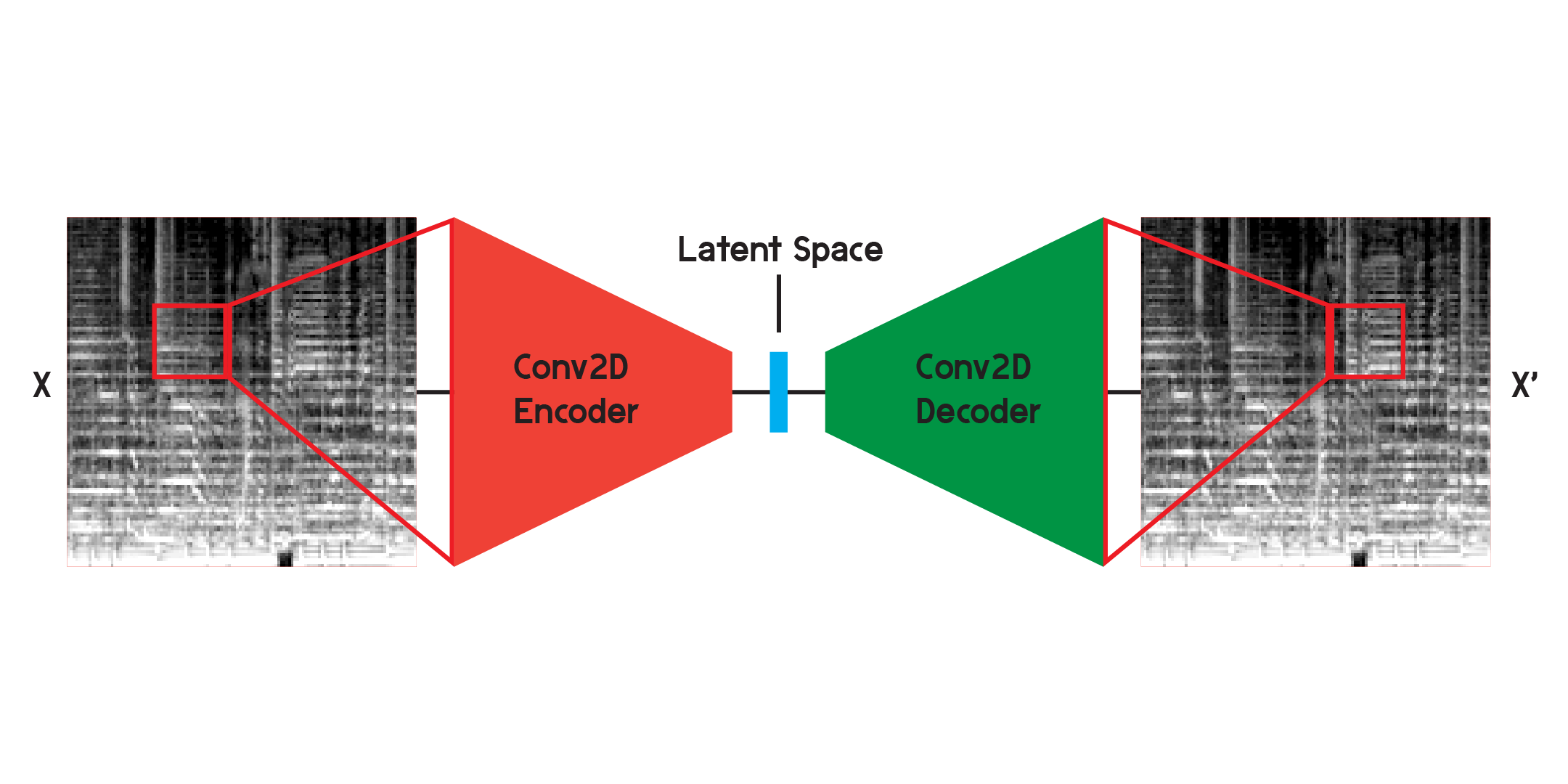
عند العمل مع الصور، يكون برنامج التشفير عبارة عن سلسلة من الطبقات التلافيفية ثنائية الأبعاد، التي تنشئ مرشحات موزونة لاستخراج الأنماط في الصورة، مع ضغط الصورة أيضًا إلى شكل أصغر فأصغر. وحدة فك التشفير هي انعكاس مرآة للعملية في أداة التشفير، حيث تقوم بإعادة تشكيل وتوسيع كمية صغيرة من البيانات إلى كمية أكبر. يقلل النموذج من متوسط الخطأ التربيعي بين الأصل وإعادة الإعمار. بمجرد التدريب بشكل كافٍ، سيكون متوسط الخطأ التربيعي بين النموذج الأصلي ومخرجات النموذج صغيرًا جدًا. على الرغم من أن متوسط الخطأ التربيعي سيكون في حده الأدنى، إلا أنه لا يزال هناك اختلاف بصري بين إعادة البناء والصورة الأصلية، خاصة في أصغر التفاصيل. جهاز التشفير التلقائي هو مخفض للضوضاء. نريد استخراج أكبر عدد ممكن من التفاصيل، ولكن في النهاية، سيقوم جهاز التشفير التلقائي أيضًا بمزج بعض التفاصيل.
لقد قمت في البداية بتدريب الشبكة باستخدام البنية الموضحة أعلاه ولكن وجدت أن العديد من التفاصيل كانت مفقودة في عمليات إعادة البناء. تبحث الطبقات التلافيفية عن الأنماط التي تمثل مجرد شريحة صغيرة من الصورة بأكملها. ولكن بعد التدريب ومراقبة المرشحات، من الصعب معرفة الأنماط التي يتم استخراجها.
يمكن استخدام أجهزة التشفير التلقائي مثل هذه في العديد من المشكلات المختلفة، ومع الطبقات التلافيفية، هناك العديد من التطبيقات للتعرف على الصور وإنشائها. ولكن نظرًا لأن المخطط الطيفي mel ليس مجرد صورة ولكنه رسم بياني للترددات في محتوى الصوت مع مرور الوقت، أعتقد أنه يمكن تنفيذ بنية مختلفة قليلاً لتقليل الخسارة في إعادة البناء، مع تقليل عدم اليقين الناتج عن التلافيفي ثنائي الأبعاد طبقات.
في النموذج المستخدم للنتائج النهائية للنموذج، قمت بتقسيم جهاز التشفير إلى جهازين تشفير منفصلين. يستخدم كل مشفر طبقات تلافيفية أحادية البعد لضغط مساحة الصورة. يقوم أحد التشفيرين بالتدريب على X، بينما يتدرب الآخر على تبديل X أو إصدار مستدير بزاوية 90 درجة للإدخال. بهذه الطريقة يتعلم أحد المشفرين المعلومات من المحور الزمني للصورة، والآخر يتعلم من محور التردد.
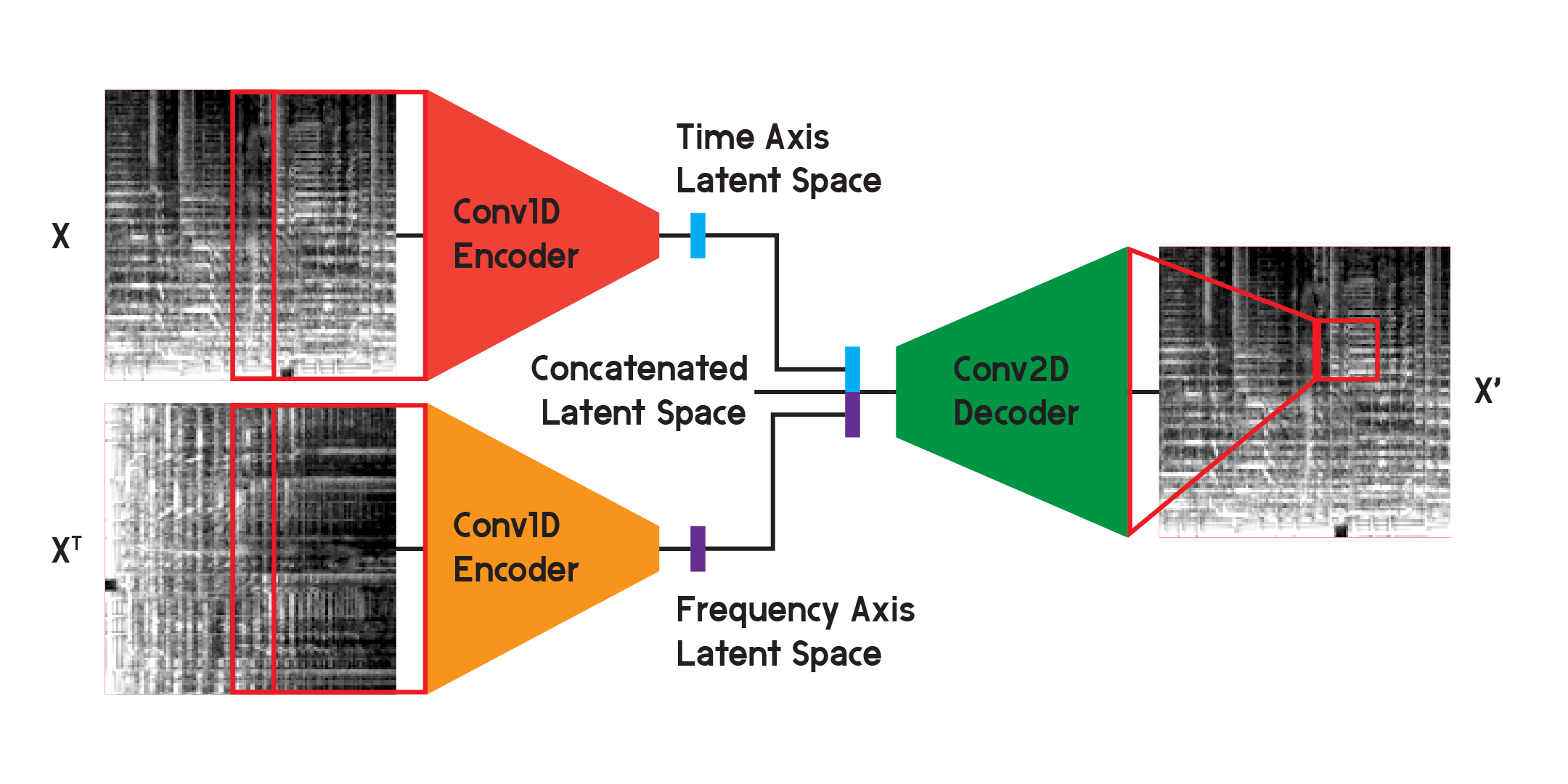
بعد تشغيل الإدخال عبر كل جهاز تشفير، يتم تجميع المتجهات المشفرة الناتجة في متجه واحد وإدخالها في وحدة فك التشفير التلافيفية ثنائية الأبعاد كما هو موضح من قبل. يتم تدريب المخرجات لتقليل الخسارة بين المدخلات كما كان من قبل.
في النهاية، كانت الخسارة في النموذج النهائي أقل بكثير مما كانت عليه في البنية الأساسية، حيث وصل متوسط الخطأ التربيعي إلى 0.0037 (التدريب) و0.0037 (التحقق من الصحة) بعد 20 حقبة، مع 125.440 صورة في مجموعة التدريب، و2560 في مجموعة التدريب. مجموعة التحقق من الصحة.
سنقوم ببناء النموذج هنا لأغراض توضيحية فقط، حيث قمت بتدريب النموذج في دفتر آخر، وسوف نقوم بتحميل الأوزان من النموذج المدرب بمجرد بنائه.
باستخدام فئة مخصصة لتشغيل الاستدلال عبر الشبكة وحفظ النتائج، يمكننا إنشاء المساحة الكامنة لكل ميل طيفي لدينا. يمكننا القيام بذلك عن طريق تشغيل البيانات فقط من خلال برنامج التشفير واستقبال متجه بالحجم الذي قمنا بتهيئة النموذج به، في هذه الحالة، 256 بُعدًا.
لاستكشاف المشهد التجريدي الناتج عن المساحة الكامنة للبيانات من خلال النموذج، يمكننا استخدام تقليل الأبعاد. يمكن لـ UMAP، مثل T-SNE، تقليل مساحة متعددة الأبعاد إلى بعدين للتصور في قطعة الأرض.
ستبحث فئة LatentSpace المخصصة عن التوصيات باستخدام تشابه جيب التمام لكل متجه.
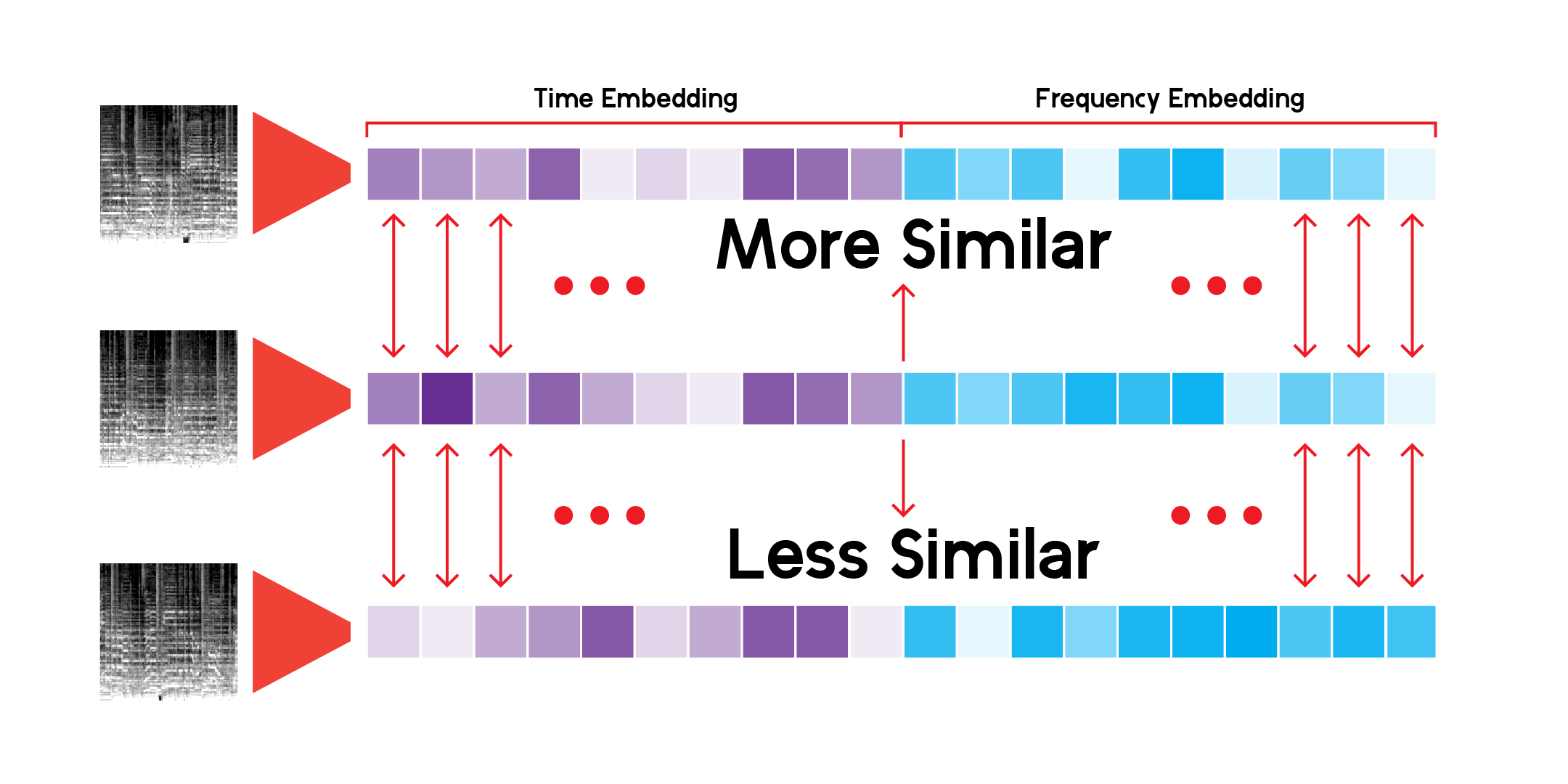
لقد كنت أبحث بلا نهاية في نظام التوصية هذا، وأنا مقتنع بأن النموذج يمكنه انتقاء روابط مثيرة جدًا بين أصوات موسيقية مختلفة ولكنها متشابهة أيضًا. فيما يلي بعض استنتاجاتي:
ما أعنيه بهذا هو أن العارضة تقدم توصيات بناءً على محتوى الصوت في كل أغنية، ولكنها لا تستمع إلى الأغنية. يقوم بإنشاء مخطط طيفي ميل وإجراء مقارنة رياضية.
في بعض الأحيان، يقدم النظام توصية لأغنية بناءً على عمرها. إذا تم تسجيل أغنية منذ وقت طويل، فسيتم التقاط هذه الترددات المحددة لمواد أو معدات التسجيل بواسطة النموذج، وعرض النتائج.
كما أن النموذج جيد جدًا في التقاط الصوت أو أدوات معينة. ولهذا السبب، إذا كانت الأغنية تحتوي على الكثير من الحديث أو الغناء، فقد توصي فقط بمسارات الكلمات المنطوقة. وأيضًا، إذا كان هناك الكثير من التشويه في الأغنية، فقد يوصي بأصوات المطر أو أغاني الطيور.
بعض معاينات الأغاني غير متوفرة في Spotify API، كما هو موضح في EDA الأولي الخاص بي. ولذلك، فإن مساهمتهم في النموذج مفقودة أيضًا ولن تكون توصية عندما تكون مناسبة تمامًا لأحدهم. على سبيل المثال، لا توجد أغاني لجيمس براون، أو فرقة البيتلز، أو برينس. يحتاج الى مزيد من البيانات.
يستخدم النظام أكثر من 278000 معاينة لتقديم التوصيات، ولا يزال هذا غير كاف. بالنظر إلى إسقاط UMAP لجميع المسارات، هناك الكثير من الاستمرارية في البيانات، ولكن هناك بعض الثغرات. ومن الناحية المثالية، يمكن للنظام استخدام الكثير من البيانات للاستفادة منها.
ما يجعل نظام/خدمات التوصية مثل Spotify جيدًا جدًا في تقديم التوصيات هو أنه يجمع بين العديد من الأنواع المختلفة من أنظمة وميزات التوصية مثل هذا النظام لتقديم التوصيات. بدءًا من تتبع ما تستمع إليه بانتظام، ووصولاً إلى استخدام التصفية التعاونية للعثور على توصيات بناءً على استخدام المستخدم المماثل، يمكن لـ Spotify تقديم تنبؤات أكثر توازناً لما سيحبه شخص ما ويستمع إليه. أجد هذا النموذج مثيرًا للاهتمام لإجراء التنبؤات، ولكن يمكن تحسينه عن طريق إضافة المزيد من الميزات مثل الأنواع المشابهة وسنوات الإصدار وبيانات المستخدم المماثلة لإجراء تنبؤات أفضل.
بشكل عام، وبصرف النظر عن تقديم التنبؤات والتوصيات، أشعر أن الأهمية الحقيقية لهذا النموذج موجودة في شرح استمرارية وطيف اللغة الموسيقية والصوت. الأنواع هي تسميات يضعها الناس على الفنان أو الصوت، لكن الأنواع تمتزج وكل صوت موجود في هذا الفضاء المستمر، على الأقل رياضيًا.
كما أن الموسيقى ليس لها حواجز. في معظم الأوقات، عند الاستعلام عن أغنية في نظام التوصيات، ستأتي النتائج من جميع العصور المختلفة وجميع الأماكن المختلفة. نظرًا لأن أيًا من البيانات الوصفية للأغنية لا تعد مدخلاً لجهاز التشفير التلقائي، فإن النتائج تعتمد على التشابه الصوتي بينها، وليس أكثر.


