T5Elasticsearch
1.0.0
فيما يلي مثال للبحث عن وظيفة:
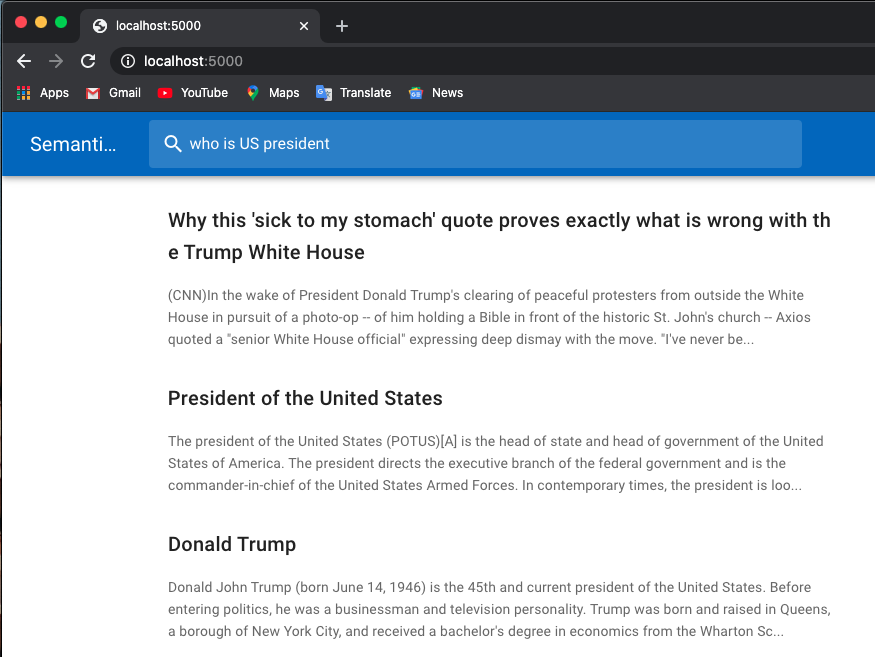
أستخدم نماذج مُدربة مسبقًا من محولات العناق.
قم بتنزيل الرمز المميز المُدرب مسبقًا ونموذج t5/bert يدويًا في الدلائل المحلية. يمكنك التحقق من النماذج هنا.
أستخدم النموذج "t5-small"، حدد هنا وانقر فوق " List all files in model لتنزيل الملفات. 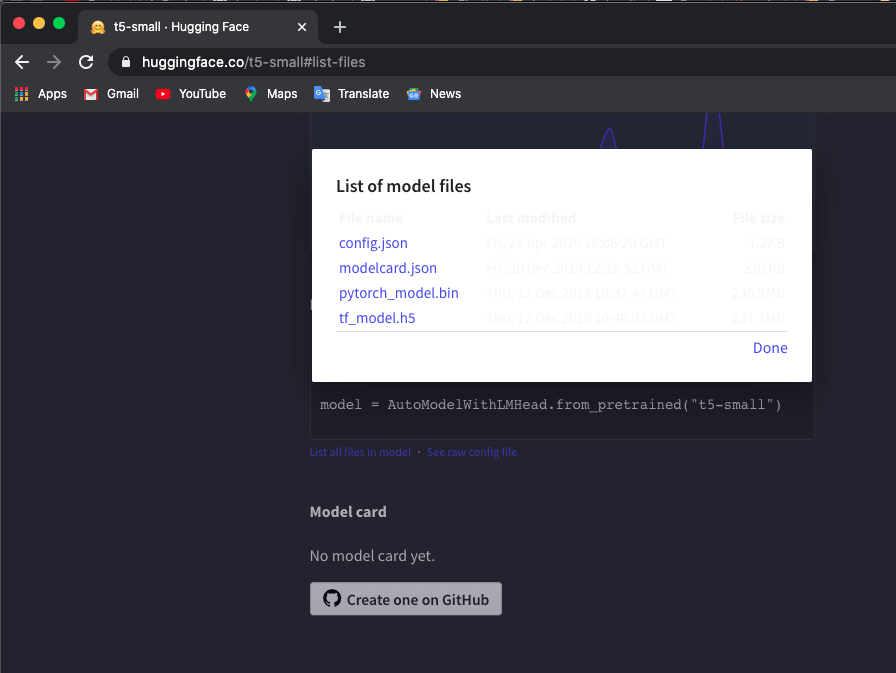
لاحظ بنية دليل الملفات التي تم تنزيلها يدويًا.
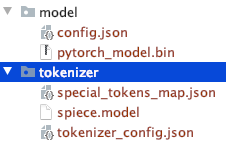
يمكنك استخدام نماذج T5 أو Bert أخرى.
إذا قمت بتنزيل نماذج أخرى، فراجع قائمة نماذج محولات Hugaface المسبقة للتحقق من اسم الطراز.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build أستخدم أيضًا docker system prune لإزالة جميع الحاويات والشبكات والصور غير المستخدمة للحصول على المزيد من الذاكرة. قم بزيادة ذاكرة عامل الإرساء الخاصة بك (أستخدم 8GB ) إذا واجهت Container exits with non-zero exit code 137 .
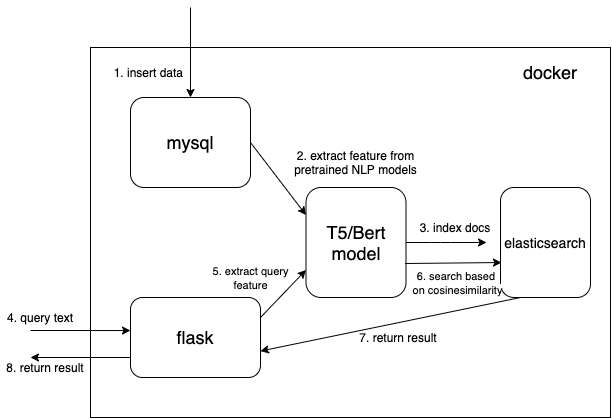
نحن نستخدم نوع بيانات متجه كثيف لحفظ الميزات المستخرجة من نماذج البرمجة اللغوية العصبية (NLP) المدربة مسبقًا (t5 أو bert هنا، ولكن يمكنك إضافة نماذجك المدربة مسبقًا بنفسك)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} الأبعاد dims:512 مخصصة لنماذج T5. قم بتغيير dims إلى 768 إذا كنت تستخدم نماذج Bert.
اقرأ المستند من mysql وقم بتحويل المستند إلى تنسيق json الصحيح لتجميعه في Elasticsearch.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'انتقل إلى http://127.0.0.1:5000.
الرمز الرئيسي لاستخدام النموذج المُدرب مسبقًا لاستخراج الميزات هو وظيفة get_emb في ملفات ./index_files/indexing_files.py و ./web/app.py .
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()يمكنك تغيير الكود واستخدام النموذج المُدرب المفضل لديك. على سبيل المثال، يمكنك استخدام نموذج GPT2.
يمكنك أيضًا تخصيص Elasticsearch الخاص بك باستخدام دالة النتيجة الخاصة بك بدلاً من cosineSimilarity في .webapp.py .
تم تعديل هذا المندوب استنادًا إلى Hironsan/bertsearch، الذي يستخدم حزم bert-serving لاستخراج ميزات bert. فهو يقتصر على TF1.x


