nlp lt
1.0.0
الهدف الرئيسي من هذا البحث هو دراسة وتعلم مبادئ معالجة اللغة الطبيعية (NLP) للغة الليتوانية. من المثير للاهتمام تحليل أساليب البرمجة اللغوية العصبية الكلاسيكية ومعرفة كيفية عملها، لذلك قمت في هذا العمل بتطبيق تصنيف النص واستخراج الموضوعات والاستعلام عن البحث وتجميع الأفكار. يتم تخزين تفاصيل التنفيذ والمعلومات الإضافية على الرابط التالي: Paper/paper.pdf
لا يمكن القيام بتحليل البيانات دون الحصول على بيانات نصية، ولذلك بدأ عملي من الحصول على البيانات الأولية من الموقع الإخباري الأكثر شهرة www.delfi.lt. قررت الزحف إلى المقالات من 5 فئات (المجرمون [227 مقالة]، الموسيقى [120 مقالة]، الأفلام [167 مقالة]، الرياضة [136 مقالة]، العلوم [204 مقالة]).
يتم قياس أداء التصنيف باستخدام مصفوفة الارتباك حيث تكون الصفوف فئة حقيقية والأعمدة فئة متوقعة. علاوة على ذلك، يصل هذا النهج إلى ما يزيد عن 90% من الاستدعاء و90% من الدقة. 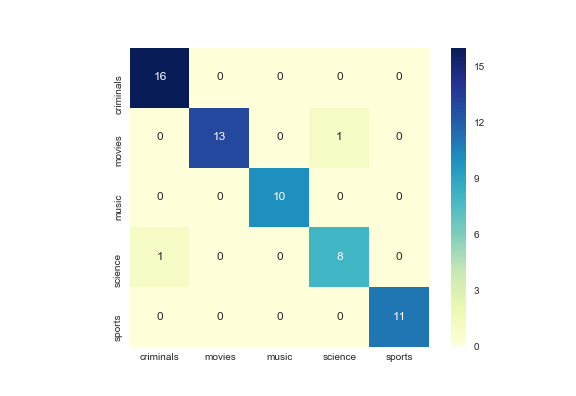
يوضح الشكل 6 مكونات مع 10 رموز لكل مكون. من هذه النتائج يمكننا اكتشاف الكلمات الأكثر أهمية وتخمين الموضوع بشكل حدسي لكل مكون رئيسي. على سبيل المثال، يقوم 4 مكونات رئيسية بتخزين معلومات حول الرياضة والموسيقى بينما تقوم 6 مكونات رئيسية بتخزين معلومات حول المجرمين.
النتائج الرئيسية معروضة أدناه: 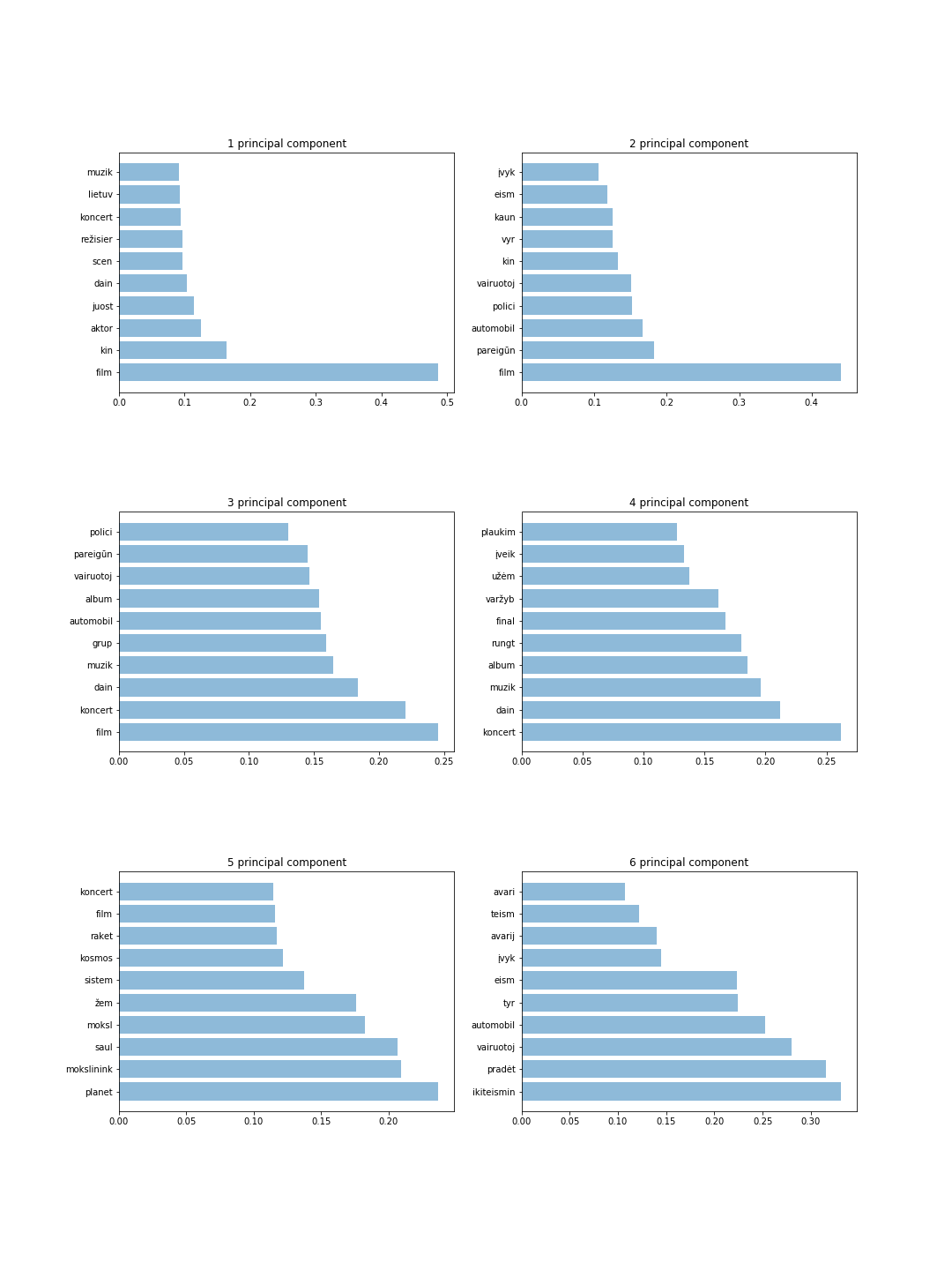
يعتمد البحث على مقالة http://webhome.cs.uvic.ca/~thomo/svd.pdf، حيث يتم تطبيق LSA للعثور على المستندات ذات الصلة ليس فقط باستخدام أوجه التشابه الدقيقة في الاستعلام، ولكن باستخدام العلاقات الأعمق بين المستندات. 
الاستعلام = "švietim apdovanojam"
نتيجة:
في التقدم


