
يحتوي هذا الريبو على أسئلة وتمارين حول موضوعات تقنية مختلفة، تتعلق أحيانًا بـ DevOps وSRE
يوجد حاليًا 2624 تمرينًا وسؤالًا
️ يمكنك استخدامها للتحضير للمقابلة ولكن معظم الأسئلة والتمارين لا تمثل مقابلة فعلية. يرجى قراءة صفحة الأسئلة الشائعة لمزيد من التفاصيل
؟ إذا كنت مهتمًا بممارسة مهنة كمهندس DevOps، فإن تعلم بعض المفاهيم المذكورة هنا سيكون مفيدًا، ولكن يجب أن تعلم أن الأمر لا يتعلق بتعلم جميع الموضوعات والتقنيات المذكورة في هذا المستودع
يمكنك إضافة المزيد من التمارين عن طريق إرسال طلبات السحب :) اقرأ عن إرشادات المساهمة هنا

ديف أوبس | 
بوابة | 
شبكة | 
الأجهزة | 
كوبيرنيتيس |

تطوير البرمجيات | 
بايثون | 
يذهب | 
بيرل | 
التعبير العادي |

سحاب | 
أوس | 
أزور | 
منصة جوجل السحابية | 
OpenStack |

نظام التشغيل | 
لينكس | 
الافتراضية | 
DNS | 
البرمجة النصية شل |

قواعد البيانات | 
SQL | 
مونجو | 
اختبار | 
البيانات الضخمة |

سي آي/سي دي | 
الشهادات | 
حاويات | 
أوبن شيفت | 
تخزين |

Terraform | 
دمية | 
وزعت | 
الأسئلة التي يمكنك طرحها | 
غير مقبول |

إمكانية الملاحظة | 
بروميثيوس | 
دائرة سي آي | 
| 
جرافانا |

أرغو | 
المهارات الناعمة | 
حماية | 
تصميم النظام |

هندسة الفوضى | 
متنوعات | 
مرن | 
كافكا | 
NodeJs |
شبكة
بشكل عام، ماذا تحتاج من أجل التواصل؟
- لغة مشتركة (ليفهمها الطرفان)
- طريقة لمخاطبة من تريد التواصل معه
- (حتى يصل محتوى الاتصال إلى المستلمين)
ما هو TCP/IP؟
مجموعة من البروتوكولات التي تحدد كيفية تواصل جهازين أو أكثر مع بعضهم البعض.
لمعرفة المزيد حول TCP/IP، اقرأ هنا
ما هو إيثرنت؟
تشير شبكة Ethernet ببساطة إلى النوع الأكثر شيوعًا من شبكة المنطقة المحلية (LAN) المستخدمة اليوم. الشبكة المحلية (LAN) - على عكس شبكة WAN (الشبكة الواسعة)، التي تمتد على منطقة جغرافية أكبر - هي شبكة متصلة من أجهزة الكمبيوتر في منطقة صغيرة، مثل مكتبك أو الحرم الجامعي أو حتى المنزل.
ما هو عنوان MAC؟ ما هو استخدامه ل؟
عنوان MAC هو رقم تعريف فريد أو رمز يُستخدم لتحديد الأجهزة الفردية على الشبكة.
تأتي الحزم التي يتم إرسالها عبر شبكة إيثرنت دائمًا من عنوان MAC ويتم إرسالها إلى عنوان MAC. إذا كان محول الشبكة يتلقى حزمة، فإنه يقوم بمقارنة عنوان MAC الوجهة للحزمة بعنوان MAC الخاص بالمحول.
متى يتم استخدام عنوان MAC هذا؟: ff:ff:ff:ff:ff:ff
عندما يرسل جهاز حزمة إلى عنوان MAC للبث (FF:FF:FF:FF:FF:FF)، يتم تسليمها إلى جميع المحطات الموجودة على الشبكة المحلية. تُستخدم عمليات بث Ethernet لتحليل عناوين IP إلى عناوين MAC (بواسطة ARP) في طبقة ارتباط البيانات.
ما هو عنوان IP؟
عنوان بروتوكول الإنترنت (عنوان IP) هو تسمية رقمية يتم تعيينها لكل جهاز متصل بشبكة كمبيوتر تستخدم بروتوكول الإنترنت للاتصال. يخدم عنوان IP وظيفتين رئيسيتين: تحديد واجهة المضيف أو الشبكة وعنونة الموقع.
اشرح قناع الشبكة الفرعية وأعطي مثالا
قناع الشبكة الفرعية هو رقم 32 بت يخفي عنوان IP ويقسم عناوين IP إلى عناوين الشبكة وعناوين المضيف. يتم إنشاء قناع الشبكة الفرعية عن طريق تعيين بتات الشبكة على كافة "1" وتعيين بتات المضيف على كافة "0". ضمن شبكة معينة، من إجمالي عناوين المضيف القابلة للاستخدام، يتم حجز عنوانين دائمًا لأغراض محددة ولا يمكن تخصيصهما لأي مضيف. هذان هو العنوان الأول، الذي تم حجزه كعنوان شبكة (المعروف أيضًا باسم معرف الشبكة)، وآخر عنوان يستخدم لبث الشبكة.
مثال
ما هو عنوان IP الخاص؟ في أي السيناريوهات/تصاميم النظام يجب على المرء استخدامه؟
يتم تعيين عناوين IP الخاصة للمضيفين في نفس الشبكة للتواصل مع بعضهم البعض. كما يوحي الاسم "خاص"، لا يمكن للأجهزة التي تم تعيين عناوين IP الخاصة لها الوصول إليها من أي شبكة خارجية. على سبيل المثال، إذا كنت أعيش في نزل وأريد من زملائي في النزل أن ينضموا إلى خادم اللعبة الذي استضفته، فسأطلب منهم الانضمام عبر عنوان IP الخاص بالخادم الخاص بي، نظرًا لأن الشبكة محلية في النزل. ما هو عنوان IP العام؟ في أي السيناريوهات/تصاميم النظام يجب على المرء استخدامه؟
عنوان IP العام هو عنوان IP عام. في حالة كنت تستضيف خادم ألعاب تريد أن ينضم إليه أصدقاؤك، فسوف تمنح أصدقائك عنوان IP العام الخاص بك للسماح لأجهزة الكمبيوتر الخاصة بهم بالتعرف على شبكتك وخادمك وتحديد موقعهما حتى يتم الاتصال. في إحدى المرات التي لن تحتاج فيها إلى استخدام عنوان IP عام، إذا كنت تلعب مع أصدقاء متصلين بنفس الشبكة مثلك، في هذه الحالة، ستستخدم عنوان IP خاصًا. لكي يتمكن شخص ما من الاتصال بخادمك الموجود داخليًا، سيتعين عليك إعداد منفذ للأمام لإخبار جهاز التوجيه الخاص بك بالسماح بحركة المرور من المجال العام إلى شبكتك والعكس صحيح. شرح نموذج OSI. ما هي الطبقات هناك؟ ما هي كل طبقة مسؤولة عن؟
- التطبيق: نهاية المستخدم (HTTP هنا)
- العرض التقديمي: إنشاء سياق بين كيانات طبقة التطبيق (التشفير هنا)
- الجلسة: إنشاء الاتصالات وإدارتها وإنهائها
- النقل: نقل تسلسلات البيانات ذات الطول المتغير من المصدر إلى مضيف الوجهة (TCP) & UDP هنا)
- الشبكة: تنقل مخططات البيانات من شبكة إلى أخرى (IP هنا)
- رابط البيانات: يوفر رابطًا بين عقدتين متصلتين مباشرة (MAC هنا)
- المادية: المواصفات الكهربائية والمادية لاتصال البيانات (البتات هي هنا)
يمكنك قراءة المزيد عن نموذج OSI في penguintutor.com
لكل مما يلي يحدد طبقة OSI التي ينتمي إليها:- تصحيح الخطأ
- توجيه الحزم
- الكابلات والإشارات الكهربائية
- عنوان ماك
- عنوان IP
- إنهاء الاتصالات
- 3 طريقة المصافحة
تصحيح الأخطاء - توجيه حزم ارتباط البيانات - كابلات الشبكة والإشارات الكهربائية - عنوان MAC الفعلي - عنوان IP لرابط البيانات - اتصالات إنهاء الشبكة - الجلسة المصافحة الثلاثية - النقل ما هي خطط التسليم التي تعرفها؟
البث الأحادي: اتصال واحد لواحد حيث يوجد مرسل واحد ومستقبل واحد.
البث: إرسال رسالة إلى كل شخص في الشبكة. يتم استخدام العنوان ff:ff:ff:ff:ff:ff للبث. هناك بروتوكولان شائعان يستخدمان البث هما ARP وDHCP.
البث المتعدد: إرسال رسالة إلى مجموعة من المشتركين. يمكن أن يكون واحد إلى متعدد أو متعدد إلى متعدد.
ما هو CSMA/CD؟ هل يستخدم في شبكات الأيثرنت الحديثة؟
يرمز CSMA/CD إلى اكتشاف الوصول المتعدد/اكتشاف الاصطدام بواسطة تحسس الناقل. ينصب تركيزها الأساسي على إدارة الوصول إلى وسيط/حافلة مشتركة حيث يمكن لمضيف واحد فقط الإرسال في وقت معين.
خوارزمية CSMA/CD:
قبل إرسال إطار، يتحقق مما إذا كان مضيف آخر يرسل إطارًا بالفعل.- إذا لم يكن هناك أحد يقوم بالإرسال، فإنه يبدأ في إرسال الإطار.
- إذا أرسل مضيفان في نفس الوقت، فسنحصل على تصادم.
- يتوقف كلا المضيفين عن إرسال الإطار ويرسلان للجميع "إشارة انحشار" لإخطار الجميع بحدوث تصادم
- إنهم ينتظرون وقتًا عشوائيًا قبل إرساله مرة أخرى
- بمجرد انتظار كل مضيف لوقت عشوائي، يحاول إرسال الإطار مرة أخرى، ومن ثم تبدأ الدورة مرة أخرى
وصف أجهزة الشبكة التالية والفرق بينها:- جهاز التوجيه
- يُحوّل
- مَركَز
يعد جهاز التوجيه والمحول والموزع جميعها أجهزة شبكة تُستخدم لتوصيل الأجهزة في شبكة محلية (LAN). ومع ذلك، يعمل كل جهاز بشكل مختلف وله حالات الاستخدام الخاصة به. وفيما يلي وصف مختصر لكل جهاز والاختلافات بينهما:
جهاز التوجيه: جهاز شبكة يربط عدة أجزاء من الشبكة معًا. وهو يعمل في طبقة الشبكة (الطبقة 3) من نموذج OSI ويستخدم بروتوكولات التوجيه لتوجيه البيانات بين الشبكات. تستخدم أجهزة التوجيه عناوين IP لتحديد الأجهزة وتوجيه حزم البيانات إلى الوجهة الصحيحة.- التبديل: جهاز شبكة يربط أجهزة متعددة على شبكة LAN. يعمل في طبقة ارتباط البيانات (الطبقة 2) لنموذج OSI ويستخدم عناوين MAC لتحديد الأجهزة وتوجيه حزم البيانات إلى الوجهة الصحيحة. تسمح المحولات للأجهزة الموجودة على نفس الشبكة بالتواصل مع بعضها البعض بشكل أكثر كفاءة ويمكن أن تمنع تضارب البيانات الذي يمكن أن يحدث عندما ترسل أجهزة متعددة البيانات في وقت واحد.
- Hub: جهاز شبكة يربط أجهزة متعددة عبر كابل واحد ويستخدم لتوصيل أجهزة متعددة دون تجزئة الشبكة. ومع ذلك، على عكس المحول، فهو يعمل في الطبقة المادية (الطبقة 1) لنموذج OSI ويقوم ببساطة ببث حزم البيانات إلى جميع الأجهزة المتصلة به، بغض النظر عما إذا كان الجهاز هو المستلم المقصود أم لا. وهذا يعني إمكانية حدوث تصادمات للبيانات، مما قد يؤثر على كفاءة الشبكة نتيجة لذلك. لا تُستخدم المحاور بشكل عام في إعدادات الشبكة الحديثة، حيث أن المحولات أكثر كفاءة وتوفر أداءً أفضل للشبكة.
ما هو "مجال التصادم"؟
مجال التصادم هو جزء من الشبكة يمكن أن تتداخل فيه الأجهزة مع بعضها البعض من خلال محاولة إرسال البيانات في نفس الوقت. عندما يقوم جهازان بنقل البيانات في نفس الوقت، فقد يتسبب ذلك في حدوث تصادم، مما يؤدي إلى فقدان البيانات أو تلفها. في مجال التصادم، تشترك جميع الأجهزة في نفس النطاق الترددي، ومن المحتمل أن يتداخل أي جهاز مع نقل البيانات بواسطة الأجهزة الأخرى. ما هو "نطاق البث"؟
مجال البث هو جزء من الشبكة حيث يمكن لجميع الأجهزة التواصل مع بعضها البعض عن طريق إرسال رسائل البث. رسالة البث هي رسالة يتم إرسالها إلى جميع الأجهزة الموجودة في الشبكة وليس إلى جهاز معين. في مجال البث، يمكن لجميع الأجهزة استقبال رسائل البث ومعالجتها، بغض النظر عما إذا كانت الرسالة مخصصة لها أم لا. ثلاثة أجهزة كمبيوتر متصلة بالتبديل. كم عدد مجالات التصادم هناك؟ كم عدد مجالات البث؟
ثلاثة مجالات تصادمية ومجال بث واحد
كيف يعمل جهاز التوجيه؟
جهاز التوجيه هو جهاز فعلي أو افتراضي يقوم بتمرير المعلومات بين شبكتين أو أكثر من شبكات الكمبيوتر التي تعمل بتبديل الحزم. يقوم جهاز التوجيه بفحص عنوان بروتوكول الإنترنت (عنوان IP) الخاص بوجهة حزمة بيانات معينة، ويحسب أفضل طريقة للوصول إلى وجهتها، ثم يعيد توجيهها وفقًا لذلك.
ما هو NAT؟
ترجمة عنوان الشبكة (NAT) هي عملية يتم فيها ترجمة عنوان IP محلي واحد أو أكثر إلى عنوان IP عالمي واحد أو أكثر والعكس لتوفير الوصول إلى الإنترنت للمضيفين المحليين.
ما هو الوكيل؟ كيف يعمل؟ لماذا نحتاجه؟
يعمل الخادم الوكيل كبوابة بينك وبين الإنترنت. إنه خادم وسيط يفصل المستخدمين النهائيين عن مواقع الويب التي يتصفحونها.
إذا كنت تستخدم خادمًا وكيلاً، فستتدفق حركة مرور الإنترنت عبر الخادم الوكيل في طريقها إلى العنوان الذي طلبته. يعود الطلب بعد ذلك من خلال نفس الخادم الوكيل (هناك استثناءات لهذه القاعدة)، ثم يقوم الخادم الوكيل بإعادة توجيه البيانات الواردة من موقع الويب إليك.
توفر الخوادم الوكيلة مستويات مختلفة من الوظائف والأمان والخصوصية اعتمادًا على حالة الاستخدام أو الاحتياجات أو سياسة الشركة.
ما هو برنامج التعاون الفني؟ كيف يعمل؟ ما هي المصافحة الثلاثية؟
مصافحة TCP ثلاثية الاتجاه أو المصافحة ثلاثية الاتجاه هي عملية تُستخدم في شبكة TCP/IP لإجراء اتصال بين الخادم والعميل.
يتم استخدام المصافحة الثلاثية بشكل أساسي لإنشاء اتصال مقبس TCP. يعمل عندما:
ترسل عقدة العميل حزمة بيانات SYN عبر شبكة IP إلى خادم على نفس الشبكة أو شبكة خارجية. الهدف من هذه الحزمة هو السؤال/الاستدلال على ما إذا كان الخادم مفتوحًا للاتصالات الجديدة.- يجب أن يكون لدى الخادم الهدف منافذ مفتوحة يمكنها قبول الاتصالات الجديدة وبدءها. عندما يتلقى الخادم حزمة SYN من عقدة العميل، فإنه يستجيب ويعيد إيصال التأكيد - حزمة ACK أو حزمة SYN/ACK.
- تتلقى عقدة العميل SYN/ACK من الخادم وتستجيب بحزمة ACK.
ما هو تأخير رحلة الذهاب والإياب أو وقت رحلة الذهاب والإياب؟
من ويكيبيديا: "طول الوقت الذي يستغرقه إرسال الإشارة بالإضافة إلى طول الوقت الذي يستغرقه استلام تلك الإشارة"
سؤال إضافي: ما هو RTT للشبكة المحلية (LAN)؟
كيف تعمل مصافحة SSL؟
مصافحة SSL هي عملية تنشئ اتصالاً آمنًا بين العميل والخادم. يرسل العميل رسالة "ترحيب العميل" إلى الخادم، والتي تتضمن إصدار العميل من بروتوكول SSL/TLS، وقائمة بخوارزميات التشفير التي يدعمها العميل، وقيمة عشوائية.- يستجيب الخادم برسالة Server Hello، والتي تتضمن إصدار الخادم من بروتوكول SSL/TLS، وقيمة عشوائية، ومعرف الجلسة.
- يرسل الخادم رسالة شهادة تحتوي على شهادة الخادم.
- يرسل الخادم رسالة تم الترحيب بالخادم، والتي تشير إلى أن الخادم قد انتهى من إرسال الرسائل الخاصة بمرحلة الترحيب بالخادم.
- يرسل العميل رسالة Client Key Exchange، والتي تحتوي على المفتاح العام للعميل.
- يرسل العميل رسالة تغيير مواصفات التشفير، والتي تُعلم الخادم بأن العميل على وشك إرسال رسالة مشفرة باستخدام مواصفات التشفير الجديدة.
- يرسل العميل رسالة مصافحة مشفرة، تحتوي على سر ما قبل الماجستير المشفر بالمفتاح العام للخادم.
- يرسل الخادم رسالة تغيير مواصفات التشفير، والتي تُعلم العميل بأن الخادم على وشك إرسال رسالة مشفرة بمواصفات التشفير الجديدة.
- يرسل الخادم رسالة مصافحة مشفرة، تحتوي على سر ما قبل الماجستير المشفر بالمفتاح العام للعميل.
- يمكن الآن للعميل والخادم تبادل بيانات التطبيق.
ما هو الفرق بين TCP و UDP؟
يقوم TCP بإنشاء اتصال بين العميل والخادم لضمان ترتيب الحزم، ومن ناحية أخرى، لا يقوم UDP بإنشاء اتصال بين العميل والخادم ولا يتعامل مع أوامر الحزم. وهذا يجعل UDP أخف وزنًا من TCP ومرشحًا مثاليًا لخدمات مثل البث.
يقدم موقع Penguintutor.com شرحًا جيدًا.
ما هي بروتوكولات TCP/IP التي تعرفها؟
شرح "البوابة الافتراضية"
تعمل البوابة الافتراضية كنقطة وصول أو جهاز توجيه IP يستخدمه الكمبيوتر المتصل بالشبكة لإرسال المعلومات إلى كمبيوتر في شبكة أخرى أو الإنترنت.
ما هو ARP؟ كيف يعمل؟
يعنيARP بروتوكول تحليل العنوان. عندما تحاول اختبار اتصال عنوان IP على شبكتك المحلية، على سبيل المثال 192.168.1.1، يجب على نظامك تحويل عنوان IP 192.168.1.1 إلى عنوان MAC. يتضمن ذلك استخدام ARP لتحليل العنوان، ومن هنا اسمه.
تحتفظ الأنظمة بجدول بحث ARP حيث تقوم بتخزين معلومات حول عناوين IP المرتبطة بعناوين MAC. عند محاولة إرسال حزمة إلى عنوان IP، سيقوم النظام أولاً بمراجعة هذا الجدول لمعرفة ما إذا كان يعرف عنوان MAC بالفعل. إذا كانت هناك قيمة مخزنة مؤقتًا، فلن يتم استخدام ARP.
ما هو TTL؟ ما الذي يساعد على الوقاية؟
TTL (مدة البقاء) هي قيمة في حزمة IP (بروتوكول الإنترنت) تحدد عدد القفزات أو أجهزة التوجيه التي يمكن أن تنتقل إليها الحزمة قبل التخلص منها. في كل مرة يتم فيها إعادة توجيه الحزمة بواسطة جهاز التوجيه، تنخفض قيمة TTL بمقدار واحد. عندما تصل قيمة TTL إلى الصفر، يتم إسقاط الحزمة، ويتم إرسال رسالة ICMP (بروتوكول رسائل التحكم في الإنترنت) مرة أخرى إلى المرسل للإشارة إلى انتهاء صلاحية الحزمة.- يتم استخدام TTL لمنع تداول الحزم إلى أجل غير مسمى في الشبكة، مما قد يسبب ازدحامًا ويقلل من أداء الشبكة.
- كما أنه يساعد على منع الحزم من الوقوع في حلقات التوجيه، حيث تنتقل الحزم بشكل مستمر بين نفس مجموعة أجهزة التوجيه دون الوصول إلى وجهتها على الإطلاق.
- بالإضافة إلى ذلك، يمكن استخدام TTL للمساعدة في اكتشاف هجمات انتحال IP ومنعها، حيث يحاول المهاجم انتحال شخصية جهاز آخر على الشبكة باستخدام عنوان IP مزيف أو مزيف. من خلال الحد من عدد القفزات التي يمكن أن تنتقلها الحزمة، يمكن أن تساعد TTL في منع توجيه الحزم إلى وجهات غير شرعية.
ما هو DHCP؟ كيف يعمل؟
إنه يرمز إلى بروتوكول التكوين الديناميكي للمضيف ويخصص عناوين IP وأقنعة الشبكة الفرعية والبوابات للمضيفين. هذه هي الطريقة التي تعمل بها:
- يقوم المضيف عند الدخول إلى الشبكة ببث رسالة بحثًا عن خادم DHCP (DHCP DISCOVER)
- يتم إرسال رسالة العرض مرة أخرى بواسطة خادم DHCP كحزمة تحتوي على وقت الإيجار وقناع الشبكة الفرعية وعناوين IP وما إلى ذلك (عرض DHCP)
- اعتمادًا على العرض الذي تم قبوله، يرسل العميل بثًا للرد لإعلام كافة خوادم DHCP (طلب DHCP)
- يرسل الخادم إقرارًا (DHCP ACK)
اقرأ المزيد هنا
هل يمكن أن يكون لديك خادمين DHCP على نفس الشبكة؟ كيف يعمل؟
من الممكن أن يكون لديك خادمين DHCP على نفس الشبكة، ومع ذلك، لا يوصى بذلك، ومن المهم تكوينهما بعناية لمنع التعارضات ومشاكل التكوين.
عند تكوين خادمين DHCP على نفس الشبكة، هناك خطر من قيام كلا الخادمين بتعيين عناوين IP وإعدادات تكوين الشبكة الأخرى لنفس الجهاز، مما قد يتسبب في حدوث تعارضات ومشكلات في الاتصال. بالإضافة إلى ذلك، إذا تم تكوين خوادم DHCP بإعدادات أو خيارات مختلفة للشبكة، فقد تتلقى الأجهزة الموجودة على الشبكة إعدادات تكوين متعارضة أو غير متناسقة.- ومع ذلك، في بعض الحالات، قد يكون من الضروري وجود خادمي DHCP على نفس الشبكة، كما هو الحال في الشبكات الكبيرة حيث قد لا يتمكن خادم DHCP واحد من التعامل مع جميع الطلبات. في مثل هذه الحالات، يمكن تكوين خوادم DHCP لخدمة نطاقات عناوين IP مختلفة أو شبكات فرعية مختلفة، بحيث لا تتداخل مع بعضها البعض.
ما هو نفق SSL؟ كيف يعمل؟
- إن نفق SSL (طبقة المقابس الآمنة) هو أسلوب يستخدم لإنشاء اتصال آمن ومشفر بين نقطتي نهاية عبر شبكة غير آمنة، مثل الإنترنت. يتم إنشاء نفق SSL عن طريق تغليف حركة المرور داخل اتصال SSL، مما يوفر السرية والنزاهة والمصادقة.
وإليك كيفية عمل نفق SSL:
يبدأ العميل اتصال SSL بالخادم، وهو ما يتضمن عملية مصافحة لإنشاء جلسة SSL.- بمجرد إنشاء جلسة SSL، يتفاوض العميل والخادم على معلمات التشفير، مثل خوارزمية التشفير وطول المفتاح، ثم يتبادلان الشهادات الرقمية لمصادقة بعضهما البعض.
- يرسل العميل بعد ذلك حركة المرور عبر نفق SSL إلى الخادم، الذي يقوم بفك تشفير حركة المرور وإعادة توجيهها إلى وجهتها.
- يرسل الخادم حركة المرور مرة أخرى عبر نفق SSL إلى العميل، الذي يقوم بفك تشفير حركة المرور وإعادة توجيهها إلى التطبيق.
ما هو المقبس؟ أين يمكنك رؤية قائمة المقابس في نظامك؟
المقبس عبارة عن نقطة نهاية برمجية تتيح الاتصال ثنائي الاتجاه بين العمليات عبر الشبكة. توفر المقابس واجهة موحدة لاتصالات الشبكة، مما يسمح للتطبيقات بإرسال واستقبال البيانات عبر الشبكة. لعرض قائمة المقابس المفتوحة على نظام Linux: netstat -an- يعرض هذا الأمر قائمة بجميع المقابس المفتوحة، بالإضافة إلى البروتوكول والعنوان المحلي والعنوان الخارجي والحالة.
ما هو IPv6؟ لماذا يجب أن نفكر في استخدامه إذا كان لدينا IPv4؟
- IPv6 (بروتوكول الإنترنت الإصدار 6) هو أحدث إصدار من بروتوكول الإنترنت (IP)، والذي يُستخدم للتعرف على الأجهزة الموجودة على الشبكة والتواصل معها. عناوين IPv6 هي عناوين 128 بت ويتم التعبير عنها بالتدوين الست عشري، مثل 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
هناك عدة أسباب تدفعنا إلى التفكير في استخدام IPv6 بدلاً من IPv4:
مساحة العنوان: يحتوي IPv4 على مساحة عنوان محدودة، والتي تم استنفادها في أجزاء كثيرة من العالم. يوفر IPv6 مساحة عنوان أكبر بكثير، مما يسمح بتريليونات عناوين IP الفريدة.- الأمان: يتضمن IPv6 دعمًا مدمجًا لـ IPsec، الذي يوفر تشفيرًا ومصادقة شاملة لحركة مرور الشبكة.
- الأداء: يتضمن IPv6 ميزات يمكن أن تساعد في تحسين أداء الشبكة، مثل توجيه البث المتعدد، الذي يسمح بإرسال حزمة واحدة إلى وجهات متعددة في وقت واحد.
- تكوين مبسط للشبكة: يتضمن IPv6 ميزات يمكنها تبسيط تكوين الشبكة، مثل التكوين التلقائي عديم الحالة، والذي يسمح للأجهزة بتكوين عناوين IPv6 الخاصة بها تلقائيًا دون الحاجة إلى خادم DHCP.
- دعم أفضل للتنقل: يتضمن IPv6 ميزات يمكنها تحسين دعم التنقل، مثل Mobile IPv6، الذي يسمح للأجهزة بالحفاظ على عناوين IPv6 الخاصة بها أثناء تنقلها بين الشبكات المختلفة.
ما هي شبكة محلية ظاهرية (VLAN)؟
- شبكة VLAN (شبكة المنطقة المحلية الافتراضية) هي شبكة منطقية تجمع مجموعة من الأجهزة معًا على شبكة فعلية، بغض النظر عن موقعها الفعلي. يتم إنشاء شبكات VLAN عن طريق تكوين محولات الشبكة لتعيين معرف VLAN محدد للإطارات المرسلة بواسطة الأجهزة المتصلة بمنفذ معين أو مجموعة من المنافذ الموجودة على المحول.
ما هو MTU؟
يعنيMTU وحدة الإرسال القصوى. إنه حجم أكبر وحدة بيانات البروتوكول (PDU) التي يمكن إرسالها في معاملة واحدة.
ماذا يحدث إذا قمت بإرسال حزمة أكبر من MTU؟
باستخدام بروتوكول IPv4، يمكن لجهاز التوجيه تجزئة وحدة PDU ثم إرسال كافة وحدات PDU المجزأة من خلال المعاملة.
مع بروتوكول IPv6، فإنه يصدر خطأ لجهاز الكمبيوتر الخاص بالمستخدم.
صحيح أم خطأ؟ يستخدم Ping UDP لأنه لا يهتم بالاتصال الموثوق
خطأ شنيع. يستخدم Ping بالفعل ICMP (بروتوكول رسائل التحكم في الإنترنت) وهو بروتوكول شبكة يستخدم لإرسال رسائل التشخيص ورسائل التحكم المتعلقة باتصالات الشبكة.
ما هو SDN؟
يعنيSDN الشبكات المعرفة بالبرمجيات. إنه أسلوب لإدارة الشبكة يركز على مركزية التحكم في الشبكة، مما يمكّن المسؤولين من إدارة سلوك الشبكة من خلال تجريد البرامج.- في الشبكة التقليدية، يتم تكوين وإدارة أجهزة الشبكة مثل أجهزة التوجيه والمحولات وجدران الحماية بشكل فردي، باستخدام برامج متخصصة أو واجهات سطر الأوامر. في المقابل، يفصل SDN مستوى التحكم في الشبكة عن مستوى البيانات، مما يسمح للمسؤولين بإدارة سلوك الشبكة من خلال وحدة تحكم برمجية مركزية.
ما هي اللجنة الدولية لشؤون المفقودين؟ ما هو استخدامه ل؟
- يعنيICMP بروتوكول رسائل التحكم في الإنترنت. وهو بروتوكول يستخدم لأغراض التشخيص والتحكم في شبكات IP. وهو جزء من مجموعة بروتوكولات الإنترنت، ويعمل في طبقة الشبكة.
يتم استخدام رسائل ICMP لمجموعة متنوعة من الأغراض، بما في ذلك:
الإبلاغ عن الأخطاء: تُستخدم رسائل ICMP للإبلاغ عن الأخطاء التي تحدث في الشبكة، مثل الحزمة التي لا يمكن تسليمها إلى وجهتها.- Ping: يُستخدم ICMP لإرسال رسائل ping، والتي تُستخدم لاختبار ما إذا كان يمكن الوصول إلى مضيف أو شبكة وقياس وقت ذهاب الحزم ذهابًا وإيابًا.
- اكتشاف MTU للمسار: يتم استخدام ICMP لاكتشاف وحدة الإرسال القصوى (MTU) للمسار، وهو أكبر حجم للحزمة التي يمكن إرسالها دون تجزئة.
- Traceroute: يتم استخدام ICMP بواسطة الأداة المساعدة Traceroute لتتبع المسار الذي تسلكه الحزم عبر الشبكة.
- اكتشاف جهاز التوجيه: يتم استخدام ICMP لاكتشاف أجهزة التوجيه في الشبكة.
ما هو NAT؟ كيف يعمل؟
NAT تعني ترجمة عنوان الشبكة. إنها طريقة لتعيين عدة عناوين خاصة محلية إلى عنوان عام قبل نقل المعلومات. تستخدم المؤسسات التي تريد أن تستخدم أجهزة متعددة عنوان IP واحدًا NAT، كما تفعل معظم أجهزة التوجيه المنزلية. على سبيل المثال، يمكن أن يكون عنوان IP الخاص بجهاز الكمبيوتر الخاص بك هو 192.168.1.100، لكن جهاز التوجيه الخاص بك يقوم بتعيين حركة المرور إلى عنوان IP العام الخاص به (على سبيل المثال 1.1.1.1). سيرى أي جهاز على الإنترنت حركة المرور القادمة من عنوان IP العام الخاص بك (1.1.1.1) بدلاً من عنوان IP الخاص بك (192.168.1.100).
ما رقم المنفذ المستخدم في كل من البروتوكولات التالية؟:- سش
- SMTP
- HTTP
- DNS
- HTTPS
- بروتوكول نقل الملفات
- سفتب
إس إس إتش - 22- سمتب - 25
- HTTP - 80
- DNS - 53
- HTTPS - 443
- بروتوكول نقل الملفات - 21
- سفتب - 22
ما هي العوامل التي تؤثر على أداء الشبكة؟
يمكن أن تؤثر عدة عوامل على أداء الشبكة، بما في ذلك:
عرض النطاق الترددي: يمكن أن يؤثر عرض النطاق الترددي المتوفر لاتصال الشبكة بشكل كبير على أدائها. يمكن أن تواجه الشبكات ذات النطاق الترددي المحدود معدلات نقل بيانات بطيئة وزمن وصول مرتفع واستجابة ضعيفة.- الكمون: يشير الكمون إلى التأخير الذي يحدث عند نقل البيانات من نقطة واحدة في الشبكة إلى أخرى. يمكن أن يؤدي زمن الوصول العالي إلى بطء أداء الشبكة، خاصة بالنسبة لتطبيقات الوقت الفعلي مثل مؤتمرات الفيديو والألعاب عبر الإنترنت.
- ازدحام الشبكة: عندما يستخدم عدد كبير جدًا من الأجهزة شبكة في نفس الوقت، يمكن أن يحدث ازدحام الشبكة، مما يؤدي إلى بطء معدلات نقل البيانات وضعف أداء الشبكة.
- فقدان الحزمة: يحدث فقدان الحزمة عندما يتم إسقاط حزم البيانات أثناء الإرسال. يمكن أن يؤدي ذلك إلى تباطؤ سرعات الشبكة وانخفاض أداء الشبكة بشكل عام.
- طوبولوجيا الشبكة: يمكن أن يؤثر التخطيط الفعلي للشبكة، بما في ذلك وضع المحولات وأجهزة التوجيه وأجهزة الشبكة الأخرى، على أداء الشبكة.
- بروتوكول الشبكة: تتميز بروتوكولات الشبكة المختلفة بخصائص أداء مختلفة، مما قد يؤثر على أداء الشبكة. على سبيل المثال، يعد TCP بروتوكولًا موثوقًا يمكنه ضمان تسليم البيانات، ولكنه قد يؤدي أيضًا إلى أداء أبطأ بسبب الحمل المطلوب للتحقق من الأخطاء وإعادة الإرسال.
- أمان الشبكة: يمكن أن تؤثر التدابير الأمنية مثل جدران الحماية والتشفير على أداء الشبكة، خاصة إذا كانت تتطلب قوة معالجة كبيرة أو تقدم زمن وصول إضافي.
- المسافة: يمكن أن تؤثر المسافة المادية بين الأجهزة الموجودة على الشبكة على أداء الشبكة، خاصة بالنسبة للشبكات اللاسلكية حيث يمكن أن تؤثر قوة الإشارة والتداخل على معدلات الاتصال ونقل البيانات.
ما هو APIPA؟
APIPA عبارة عن مجموعة من عناوين IP التي يتم تخصيصها للأجهزة عندما لا يمكن الوصول إلى خادم DHCP الرئيسي
ما هو نطاق IP الذي تستخدمه APIPA؟
تستخدم APIPA نطاق IP: 169.254.0.1 - 169.254.255.254.
طائرة التحكم وطائرة البيانات
إلى ماذا تشير عبارة "طائرة التحكم"؟
يعد مستوى التحكم جزءًا من الشبكة الذي يقرر كيفية توجيه الحزم وإعادة توجيهها إلى موقع مختلف.
ما الذي يشير إليه "مستوى البيانات"؟
يعد مستوى البيانات جزءًا من الشبكة التي تقوم فعليًا بإعادة توجيه البيانات/الحزم.
إلى ماذا تشير عبارة "طائرة الإدارة"؟
ويشير إلى وظائف المراقبة والإدارة.
إلى أي مستوى (بيانات، تحكم، ...) ينتمي إنشاء جداول التوجيه؟
طائرة التحكم.
شرح بروتوكول الشجرة الممتدة (STP).
ما هو تجميع الارتباط؟ لماذا يتم استخدامه؟
ما هو التوجيه غير المتماثل؟ كيفية التعامل معها؟
ما هي بروتوكولات التراكب (النفق) التي تعرفها؟
ما هو GRE؟ كيف يعمل؟
ما هو VXLAN؟ كيف يعمل؟
ما هو SNAT؟
شرح OSPF.
OSPF (افتح أقصر مسار أولاً) هو بروتوكول توجيه يمكن تنفيذه على أنواع مختلفة من أجهزة التوجيه. بشكل عام، يتم دعم OSPF على معظم أجهزة التوجيه الحديثة، بما في ذلك تلك التي يقدمها بائعون مثل Cisco وJuniper وHuawei. تم تصميم البروتوكول للعمل مع الشبكات القائمة على IP، بما في ذلك IPv4 وIPv6. كما أنه يستخدم تصميمًا هرميًا للشبكة، حيث يتم تجميع أجهزة التوجيه في مناطق، بحيث يكون لكل منطقة خريطة هيكلية خاصة بها وجدول توجيه. يساعد هذا التصميم على تقليل كمية معلومات التوجيه التي يلزم تبادلها بين أجهزة التوجيه وتحسين قابلية توسيع الشبكة.
أنواع أجهزة التوجيه OSPF 4 هي:
- راوتر داخلي
- أجهزة توجيه حدود المنطقة
- أجهزة التوجيه الحدودية للأنظمة المستقلة
- أجهزة التوجيه العمود الفقري
تعرف على المزيد حول أنواع أجهزة توجيه OSPF: https://www.educba.com/ospf-router-types/
ما هو الكمون؟
الكمون هو الوقت الذي تستغرقه المعلومات للوصول إلى وجهتها من المصدر.
ما هو عرض النطاق الترددي؟
عرض النطاق الترددي هو قدرة قناة الاتصال على قياس كمية البيانات التي يمكن لهذه الأخيرة التعامل معها خلال فترة زمنية محددة. المزيد من عرض النطاق الترددي يعني المزيد من التعامل مع حركة المرور وبالتالي المزيد من نقل البيانات.
ما هو الإنتاجية؟
تشير الإنتاجية إلى قياس الكمية الحقيقية للبيانات المنقولة خلال فترة زمنية معينة عبر أي قناة إرسال.
عند إجراء استعلام بحث، ما هو الأهم، زمن الوصول أم الإنتاجية؟ وكيف نضمن أننا ندير البنية التحتية العالمية؟
كمون. للحصول على زمن استجابة جيد، يجب إعادة توجيه استعلام البحث إلى أقرب مركز بيانات.
عند تحميل مقطع فيديو، ما هو الأهم، زمن الوصول أم الإنتاجية؟ وكيف يمكن التأكد من ذلك؟
الإنتاجية. للحصول على إنتاجية جيدة، يجب توجيه دفق التحميل إلى رابط غير مستغل بشكل كافٍ.
ما هي الاعتبارات الأخرى (باستثناء زمن الوصول والإنتاجية) الموجودة عند إعادة توجيه الطلبات؟
- حافظ على تحديث ذاكرة التخزين المؤقت (مما يعني أنه لا يمكن إعادة توجيه الطلب إلى أقرب مركز بيانات)
شرح العمود الفقري والأوراق
"Spine & Leaf" عبارة عن طوبولوجيا شبكة تُستخدم بشكل شائع في بيئات مراكز البيانات لتوصيل محولات متعددة وإدارة حركة مرور الشبكة بكفاءة. تُعرف أيضًا باسم بنية "العمود الفقري" أو طوبولوجيا "العمود الفقري للورقة". يوفر هذا التصميم نطاقًا تردديًا عاليًا وزمن وصول منخفض وقابلية للتوسع، مما يجعله مثاليًا لمراكز البيانات الحديثة التي تتعامل مع كميات كبيرة من البيانات وحركة المرور. يوجد داخل شبكة Spine & Leaf نوعان رئيسيان من المفاتيح:
- مفاتيح العمود الفقري: مفاتيح العمود الفقري هي مفاتيح عالية الأداء مرتبة في طبقة العمود الفقري. تعمل هذه المفاتيح بمثابة قلب الشبكة وعادةً ما تكون مترابطة مع كل مفتاح طرفي. يتم توصيل كل مفتاح عمود الفقري بجميع المفاتيح الطرفية الموجودة في مركز البيانات.
- مفاتيح الأوراق: تتصل مفاتيح الأوراق بالأجهزة الطرفية مثل الخوادم ومصفوفات التخزين ومعدات الشبكات الأخرى. يتم توصيل كل مفتاح ورقي بكل مفتاح عمود فقري في مركز البيانات. يؤدي هذا إلى إنشاء اتصال شبكي كامل وغير معوق بين مفاتيح الأوراق والعمود الفقري، مما يضمن إمكانية اتصال أي مفتاح أوراق مع أي مفتاح أوراق آخر بأقصى قدر من الإنتاجية.
أصبحت بنية Spine & Leaf ذات شعبية متزايدة في مراكز البيانات نظرًا لقدرتها على التعامل مع متطلبات الحوسبة السحابية الحديثة والمحاكاة الافتراضية وتطبيقات البيانات الضخمة، مما يوفر بنية تحتية شبكية قابلة للتطوير وعالية الأداء وموثوقة
ما هو ازدحام الشبكة؟ ما الذي يمكن أن يسبب ذلك؟
يحدث ازدحام الشبكة عندما يكون هناك الكثير من البيانات التي يمكن نقلها على الشبكة ولا تملك سعة كافية للتعامل مع الطلب.
يمكن أن يؤدي هذا إلى زيادة زمن الوصول وفقدان الحزمة. يمكن أن تكون الأسباب متعددة، مثل الاستخدام العالي للشبكة، أو عمليات نقل الملفات الكبيرة، أو البرامج الضارة، أو مشكلات الأجهزة، أو مشكلات تصميم الشبكة.
لمنع ازدحام الشبكة، من المهم مراقبة استخدام الشبكة وتنفيذ إستراتيجيات للحد من الطلب أو إدارته.
ماذا يمكنك أن تخبرني عن تنسيق حزمة UDP؟ ماذا عن تنسيق حزمة TCP؟ كيف يختلف الأمر؟
ما هي خوارزمية التراجع الأسي؟ أين يتم استخدامه؟
باستخدام كود هامينغ، ما هي الكلمة الرمزية لكلمة البيانات التالية 100111010001101؟
00110011110100011101
أعط أمثلة على البروتوكولات الموجودة في طبقة التطبيق
بروتوكول نقل النص التشعبي (HTTP) - يستخدم لصفحات الويب على الإنترنت- بروتوكول نقل البريد البسيط (SMTP) - نقل البريد الإلكتروني
- شبكة الاتصالات - (TELNET) - محاكاة طرفية للسماح للعميل بالوصول إلى خادم telnet
- بروتوكول نقل الملفات (FTP) - يسهل نقل الملفات بين أي جهازين
- نظام اسم المجال (DNS) - ترجمة اسم المجال
- بروتوكول التكوين الديناميكي للمضيف (DHCP) - يخصص عناوين IP وأقنعة الشبكة الفرعية والبوابات للمضيفين
- بروتوكول إدارة الشبكة البسيط (SNMP) - يجمع البيانات على الأجهزة الموجودة على الشبكة
أعط أمثلة على البروتوكولات الموجودة في طبقة الشبكة
بروتوكول الإنترنت (IP) - يساعد في توجيه الحزم من جهاز إلى آخر- بروتوكول رسائل التحكم بالإنترنت (ICMP) - يتيح للشخص معرفة ما يحدث مثل رسائل الخطأ ومعلومات تصحيح الأخطاء
ما هو HSTS؟
HTTP Strict Transport Security هو توجيه لخادم الويب يُعلم وكلاء المستخدم ومتصفحات الويب بكيفية التعامل مع اتصاله من خلال رأس استجابة يتم إرساله في البداية والعودة إلى المتصفح. يؤدي هذا إلى فرض الاتصالات عبر تشفير HTTPS، متجاهلاً استدعاء أي برنامج نصي لتحميل أي مورد في هذا المجال عبر HTTP. اقرأ المزيد [هنا](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security %20(HSTS، و%20back%20to%20the%20browser.)
الشبكة - منوعات
ما هو الإنترنت؟ هل هي نفس شبكة الويب العالمية؟
يشير الإنترنت إلى شبكة من الشبكات، تنقل كميات هائلة من البيانات حول العالم.
شبكة الويب العالمية هي تطبيق يعمل على ملايين الخوادم، أعلى شبكة الإنترنت، ويمكن الوصول إليها من خلال ما يعرف بمتصفح الويب
ما هو مزود خدمة الإنترنت؟
ISP (مزود خدمة الإنترنت) هو مزود شركة الإنترنت المحلية.
نظام التشغيل
تمارين نظام التشغيل
| اسم | عنوان | الهدف والتعليمات | حل | تعليقات |
|---|
| شوكة 101 | شوكة | وصلة | وصلة | |
| شوكة 102 | شوكة | وصلة | وصلة | |
نظام التشغيل - التقييم الذاتي
ما هو نظام التشغيل؟
من كتاب "أنظمة التشغيل: ثلاث قطع سهلة":
"مسؤول عن تسهيل تشغيل البرامج (حتى السماح لك بتشغيل الكثيرين على ما يبدو في نفس الوقت) ، والسماح للبرامج بمشاركة الذاكرة ، وتمكين البرامج للتفاعل مع الأجهزة ، وغيرها من الأشياء الممتعة من هذا القبيل".
نظام التشغيل - العملية
هل يمكنك شرح ما هي العملية؟
العملية هي برنامج قيد التشغيل. البرنامج هو واحد أو أكثر من التعليمات ويتم تنفيذ البرنامج (أو العملية) بواسطة نظام التشغيل.
إذا كان عليك تصميم واجهة برمجة تطبيقات للعمليات في نظام التشغيل ، كيف ستبدو API هذه؟
سوف تدعم ما يلي:
إنشاء - اسمح لإنشاء عمليات جديدة- حذف - السماح لإزالة/تدمير العمليات
- الدولة - اسمح للتحقق من حالة العملية ، سواء كانت قيد التشغيل ، أو توقف ، أو انتظار ، إلخ.
- توقف - اسمح لوقف عملية التشغيل
كيف يتم إنشاء العملية؟
نظام التشغيل يقرأ رمز البرنامج وأي بيانات إضافية ذات صلة- يتم تحميل رمز البرنامج في الذاكرة أو بشكل أكثر تحديداً ، في مساحة عنوان العملية.
- يتم تخصيص الذاكرة لمكدس البرنامج (ويعرف أيضًا باسم مكدس وقت التشغيل). المكدس الذي تم تهيئته أيضًا بواسطة نظام التشغيل مع بيانات مثل ArgV و ArgC والمعلمات إلى Main ()
- تم تخصيص الذاكرة لكومة البرنامج المطلوبة للبيانات المخصصة ديناميكيًا مثل قوائم هياكل البيانات المرتبطة وجداول التجزئة
- يتم تنفيذ مهام تهيئة الإدخال/الإخراج ، كما هو الحال في أنظمة UNIX/Linux ، حيث تحتوي كل عملية على 3 واصفات ملفات (الإدخال والإخراج والخطأ)
- تشغيل البرنامج ، بدءًا من Main ()
صحيح أم خطأ؟ يتم تحميل البرنامج في الذاكرة بفارغ الصبر (كل مرة)
خطأ شنيع. كان هذا صحيحًا في الماضي ، لكن أنظمة التشغيل اليوم تؤدي تحميل كسول ، مما يعني فقط أن القطع ذات الصلة المطلوبة للعملية يتم تشغيلها أولاً.
ما هي حالات العملية المختلفة؟
التشغيل - إنه تنفيذ تعليمات- جاهز - إنه جاهز للتشغيل ، ولكن لأسباب مختلفة معلقة
- تم حظره - إنه ينتظر إكمال بعض العمليات ، على سبيل المثال طلب القرص I/O
ما هي بعض الأسباب التي تجعل العملية محظورة؟
عمليات الإدخال/الإخراج (مثل القراءة من قرص)- في انتظار حزمة من شبكة
ما هو الاتصالات Inter Process (IPC)؟
يشير الاتصال بين العمليات (IPC) إلى الآليات التي يوفرها نظام تشغيل يسمح للعمليات بإدارة البيانات المشتركة.
ما هو "مشاركة الوقت"؟
حتى عند استخدام نظام مع وحدة المعالجة المركزية المادية ، من الممكن السماح لمستخدمين متعددين بالعمل عليها وتشغيل البرامج. هذا ممكن مع مشاركة الوقت ، حيث تتم مشاركة موارد الحوسبة بطريقة يبدو للمستخدم ، يحتوي النظام على وحدات المعالجة المركزية متعددة ، ولكن في الواقع ، فهو ببساطة وحدة معالجة مُشاركت من خلال تطبيق Multiprogramming و Multi-Tasking.
ما هو "مشاركة الفضاء"؟
إلى حد ما عكس الوقت المشاركة. بينما يتم استخدام مورد في الوقت المناسب لفترة من الوقت من قبل كيان ، ثم يمكن استخدام نفس المورد من قبل مورد آخر ، في المساحة تتم مشاركة المساحة من قبل كيانات متعددة ولكن بطريقة لا يتم نقلها بينهما.
يتم استخدامه بواسطة كيان واحد ، حتى يقرر هذا الكيان التخلص منه. خذ على سبيل المثال التخزين. في التخزين ، ملف لك ، حتى تقرر حذفه.
ما المكون الذي يحدد العملية التي يتم تشغيلها في لحظة معينة في الوقت المناسب؟
مجدول وحدة المعالجة المركزية
نظام التشغيل - الذاكرة
ما هي "الذاكرة الافتراضية" وما الغرض الذي يخدم؟
تجمع الذاكرة الافتراضية بين ذاكرة الوصول العشوائي لجهاز الكمبيوتر الخاص بك ومساحة مؤقتة على القرص الصلب. عندما تعمل RAM ، تساعد الذاكرة الظاهرية على نقل البيانات من ذاكرة الوصول العشوائي إلى مساحة تسمى ملف الترحيل. يمكن أن يؤدي نقل البيانات إلى ملف الترحيل إلى تحرير ذاكرة الوصول العشوائي ، حتى يتمكن جهاز الكمبيوتر الخاص بك من إكمال عمله. بشكل عام ، كلما زاد عدد ذاكرة الوصول العشوائي التي يتمتع بها جهاز الكمبيوتر الخاص بك ، زادت أسرع البرامج. https://www.minitool.com/lib/virtual-memory.html
ما هو ترحيل الطلب؟
ترحيل الطلب هو تقنية لإدارة الذاكرة حيث يتم تحميل الصفحات في الذاكرة الفعلية فقط عند الوصول إليها من قبل العملية. يعمل على تحسين استخدام الذاكرة عن طريق تحميل الصفحات عند الطلب ، مما يقلل من زمن التشغيل الناتج عن العمل والنفقات العامة. ومع ذلك ، فإنه يقدم بعض الكمون عند الوصول إلى الصفحات لأول مرة. بشكل عام ، إنه نهج فعال من حيث التكلفة لإدارة موارد الذاكرة في أنظمة التشغيل.
ما هي النسخ على الكتابة؟
النسخ على write (Cow) هو مفهوم إدارة الموارد ، بهدف تقليل نسخ المعلومات غير الضرورية. إنه مفهوم ، يتم تنفيذه على سبيل المثال داخل Posix Fork Syscall ، والذي ينشئ عملية مكررة لعملية الاتصال. الفكرة:
إذا تمت مشاركة الموارد بين كيانين أو أكثر (على سبيل المثال ، فإن شرائح الذاكرة المشتركة بين عمليتين) ، لا تحتاج الموارد إلى نسخها لكل كيان ، ولكن كل كيان لديه إذن الوصول إلى عملية القراءة على المورد المشترك. (يتم تمييز الأجزاء المشتركة على أنها قراءة فقط) (فكر في كل كيان له مؤشر إلى موقع المورد المشترك ، والذي يمكن إلحاقه بقراءة قيمته)- إذا كان أحد الكيانات يقوم بإجراء عملية كتابة على مورد مشترك ، فستنشأ مشكلة ، حيث سيتم تغيير المورد أيضًا بشكل دائم لجميع الكيانات الأخرى التي تشاركها. (فكر في عملية تعديل بعض المتغيرات على المكدس ، أو تخصيص بعض البيانات ديناميكيًا على الكومة ، فإن هذه التغييرات على المورد المشترك ستطبق أيضًا على جميع العمليات الأخرى ، وهذا بالتأكيد سلوك غير مرغوب فيه)
- كحل فقط ، إذا كانت عملية الكتابة على وشك أن يتم تنفيذها على مورد مشترك ، يتم نسخ هذا المورد أولاً ثم يتم تطبيق التغييرات.
ما هي النواة ، وماذا تفعل؟
kernel جزء من نظام التشغيل وهو مسؤول عن مهام مثل:
تخصيص الذاكرة- عمليات الجدول الزمني
- التحكم في وحدة المعالجة المركزية
صحيح أم خطأ؟ يتم تحميل بعض أجزاء الكود في النواة في مناطق محمية من الذاكرة بحيث لا يمكن للتطبيقات الكتابة فوقها.
حقيقي
ما هو Posix؟
POSIX (واجهة نظام التشغيل المحمولة) هي مجموعة من المعايير التي تحدد الواجهة بين نظام تشغيل وبرامج تطبيق يشبه UNIX.
اشرح ما هو Semaphore وما دوره في أنظمة التشغيل.
الإشارة هي عبارة عن متزامنة بدائية تستخدم في أنظمة التشغيل والبرمجة المتزامنة للتحكم في الوصول إلى الموارد المشتركة. إنه نوع بيانات متغير أو مجردة يعمل كآلية عداد أو آلية إشارات لإدارة الوصول إلى الموارد عن طريق عمليات أو مؤشرات الترابط المتعددة.
ما هو ذاكرة التخزين المؤقت؟ ما هو المخزن المؤقت؟
ذاكرة التخزين المؤقت: يتم استخدام ذاكرة التخزين المؤقت عادةً عندما تقرأ العمليات والكتابة إلى القرص لجعل العملية أسرع ، من خلال جعل بيانات مماثلة تستخدمها برامج مختلفة يمكن الوصول إليها بسهولة. العازلة: مكان محجوز في ذاكرة الوصول العشوائي ، والذي يستخدم للاحتفاظ بالبيانات لأغراض مؤقتة.
الافتراضية
ما هو الافتراضية؟
يستخدم المحاكاة الافتراضية البرامج لإنشاء طبقة تجريبية فوق أجهزة الكمبيوتر ، والتي تتيح لعناصر الأجهزة لجهاز كمبيوتر واحد - المعالجات ، الذاكرة ، التخزين والمزيد - تقسيمها إلى أجهزة كمبيوتر افتراضية متعددة ، تسمى بشكل شائع الأجهزة الظاهرية (VMS).
ما هو Hypervisor؟
Red Hat: "Hypervisor هو برنامج يقوم بإنشاء وتشغيل الأجهزة الافتراضية (VMS). VMs. "
اقرأ المزيد هنا
ما هي أنواع العناوين المفرطة؟
استضافت Hypervisors و Hypervisors المعادن.
ما هي مزايا وعيوب فرط المعادن العارية على Hypervisor المستضافة؟
نظرًا لوجود برامج تشغيل خاصة به وصول مباشر إلى مكونات الأجهزة ، فإن Hypervisor الباريمي في كثير من الأحيان يكون له عروض أفضل مع الاستقرار وقابلية التوسع.
من ناحية أخرى ، من المحتمل أن يكون هناك بعض القيود المتعلقة بالتحميل (أي) برامج التشغيل ، وبالتالي فإن Hypervisor المستضافة عادةً ما يستفيد من توافق أفضل في الأجهزة.
ما هي أنواع المحاكاة الافتراضية الموجودة؟
نظام تشغيل نظام المحاكاة الافتراضية نظام التشغيل الافتراضي للمحاكاة الافتراضية للمحاكاة الافتراضية
هل الحاويات هو نوع من المحاكاة الافتراضية؟
نعم ، إنه محاكاة افتراضية على مستوى النظام ، حيث تتم مشاركة النواة وتسمح باستخدام مثيلات متعددة من مساحات المستخدم المعزولة.
كيف غير إدخال الأجهزة الافتراضية الصناعة والطريقة التي تم بها نشر التطبيقات؟
سمح إدخال الأجهزة الافتراضية للشركات بنشر تطبيقات أعمال متعددة على نفس الأجهزة ، بينما يتم فصل كل تطبيق عن بعضها البعض بطريقة مضمونة ، حيث يعمل كل منها على نظام التشغيل المنفصل الخاص به.
الآلات الافتراضية
هل نحتاج إلى أجهزة افتراضية في عصر الحاويات؟ هل ما زالوا ذوي الصلة؟
نعم ، لا تزال الأجهزة الافتراضية ذات صلة حتى في عصر الحاويات. في حين توفر الحاويات بديلاً خفيف الوزن ومحمول للأجهزة الافتراضية ، إلا أن لديها قيودًا معينة. لا تزال الأجهزة الافتراضية مهمة لأنها توفر العزلة والأمان ، ويمكنها تشغيل أنظمة تشغيل مختلفة ، وهي جيدة للتطبيقات القديمة. قيود الحاويات على سبيل المثال هي مشاركة kernel المضيف.
بروميثيوس
ما هو بروميثيوس؟ ما هي بعض ميزات بروميثيوس الرئيسية؟
Prometheus هي مجموعة أدوات شهيرة لمراقبة وتنبيه الأنظمة المفتوحة المصدر ، والتي تم تطويرها في الأصل في SoundCloud. تم تصميمه لجمع وتخزين بيانات السلسلة الزمنية ، والسماح بالاستعلام عن تلك البيانات وتحليلها باستخدام لغة استعلام قوية تسمى PROMQL. يستخدم Prometheus بشكل متكرر لمراقبة التطبيقات السحابية الأصلية ، والخدمات الدقيقة ، والبنية التحتية الحديثة الأخرى.
تشمل بعض الميزات الرئيسية لـ Prometheus:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
بشكل عام ، تعد Prometheus أداة قوية ومرنة لرصد وتحليل الأنظمة والتطبيقات ، وتستخدم على نطاق واسع في الصناعة للمراقبة والملاحظة السحابية.
في أي سيناريوهات ، قد يكون من الأفضل عدم استخدام بروميثيوس؟
من وثائق Prometheus: "إذا كنت بحاجة إلى دقة 100 ٪ ، مثل الفواتير لكل طلب".
صف بنية بروميثيوس والمكونات
تتكون بنية بروميثيوس من أربعة مكونات رئيسية:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
بشكل عام ، تم تصميم بنية بروميثيوس لتكون قابلة للتطوير ومرونة للغاية. يمكن نشر مكتبات الخادم ومكتبات العميل بطريقة موزعة لدعم المراقبة عبر بيئات واسعة النطاق ديناميكية للغاية
هل يمكنك مقارنة Prometheus مع حلول أخرى مثل influxDB على سبيل المثال؟
بالمقارنة مع حلول المراقبة الأخرى ، مثل influxDB ، تشتهر Prometheus بأدائه العالي وقابلية التوسع. يمكنه التعامل مع كميات كبيرة من البيانات ويمكن دمجها بسهولة مع أدوات أخرى في النظام البيئي للمراقبة. من ناحية أخرى ، تشتهر effressdb بسهولة الاستخدام والبساطة. يحتوي على واجهة سهلة الاستخدام وتوفر واجهات برمجة التطبيقات سهلة الاستخدام لجمع البيانات والاستعلام عنها.
الحل الشائع الآخر ، Nagios ، هو نظام مراقبة أكثر تقليدية يعتمد على نموذج قائم على الدفع لجمع البيانات. كانت Nagios موجودة منذ فترة طويلة وهي معروفة باستقرارها وموثوقيتها. ومع ذلك ، بالمقارنة مع Prometheus ، يفتقر Nagios إلى بعض الميزات الأكثر تقدماً ، مثل نموذج البيانات متعدد الأبعاد ولغة الاستعلام القوية.
بشكل عام ، يعتمد اختيار حل المراقبة على الاحتياجات والمتطلبات المحددة للمؤسسة. على الرغم من أن Prometheus هو خيار رائع للمراقبة والتنبيه على نطاق واسع ، فقد يكون InfluxDB مناسبًا للبيئات الأصغر التي تتطلب سهولة الاستخدام والبساطة. لا يزال Nagios اختيارًا قويًا للمؤسسات التي تعطي الأولوية للاستقرار والموثوقية على الميزات المتقدمة.
ما هو تنبيه؟
في بروميثيوس ، يكون التنبيه هو الإخطار الذي يتم تشغيله عند استيفاء حالة أو عتبة محددة. يمكن تكوين التنبيهات للتشغيل عندما تعبر مقاييس معينة عتبة معينة أو عند حدوث أحداث محددة. بمجرد تشغيل التنبيه ، يمكن توجيهه إلى قنوات مختلفة ، مثل البريد الإلكتروني أو النداء أو الدردشة ، لإخطار الفرق أو الأفراد ذات الصلة لاتخاذ الإجراءات المناسبة. تعد التنبيهات مكونًا مهمًا في أي نظام مراقبة ، حيث تسمح للفرق باكتشاف المشكلات والاستجابة لها بشكل استباقي قبل أن تؤثر على المستخدمين أو تسبب وقت توقف النظام. ما هو مثال؟ ما هي الوظيفة؟
في بروميثيوس ، يشير مثيل إلى هدف واحد يتم مراقبه. على سبيل المثال ، خادم واحد أو خدمة واحدة. الوظيفة هي مجموعة من الحالات التي تؤدي نفس الوظيفة ، مثل مجموعة من خوادم الويب التي تخدم نفس التطبيق. تتيح لك الوظائف تحديد وإدارة مجموعة من الأهداف معًا.
في جوهرها ، فإن المثال هو هدف فردي يجمع Prometheus المقاييس ، في حين أن الوظيفة هي مجموعة من الحالات المماثلة التي يمكن إدارتها كمجموعة.
ما هي أنواع المقاييس الأساسية التي يدعمها بروميثيوس؟
يدعم Prometheus عدة أنواع من المقاييس ، بما في ذلك: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
يدعم Prometheus أيضًا مختلف الوظائف والمشغلين لتجميع المقاييس والتلاعب بها ، مثل SUM و MAX و MIN والمعدل. هذه الميزات تجعلها أداة قوية لمراقبة وتنبيه مقاييس النظام.
ما هو المصدر؟ ما هو استخدامه ل؟
يعمل المصدر كجسر بين نظام الطرف الثالث أو التطبيق و Prometheus ، مما يجعل من الممكن لـ Prometheus مراقبة وتجميع البيانات من هذا النظام أو التطبيق. يعمل المصدر كخادم ، ويستمع على منفذ شبكة معين لطلبات من Prometheus لكشط المقاييس. يجمع مقاييس من نظام أو تطبيق الطرف الثالث ويحولها إلى تنسيق يمكن فهمه بواسطة Prometheus. ثم يعرض المصدر هذه المقاييس إلى Prometheus عبر نقطة نهاية HTTP ، مما يجعلها متاحة للجمع والتحليل.
يستخدم المصدرون بشكل شائع لمراقبة أنواع مختلفة من مكونات البنية التحتية مثل قواعد البيانات وخوادم الويب وأنظمة التخزين. على سبيل المثال ، هناك مصدرون متاحون لمراقبة قواعد البيانات الشائعة مثل MySQL و PostgreSQL ، وكذلك خوادم الويب مثل Apache و Nginx.
بشكل عام ، يعد المصدرون مكونًا حاسمًا في النظام البيئي Prometheus ، مما يسمح بمراقبة مجموعة واسعة من الأنظمة والتطبيقات ، وتوفير درجة عالية من المرونة والتمديد للمنصة.
ما هي أفضل ممارسات بروميثيوس؟
فيما يلي ثلاثة منهم: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
كيف تحصل على إجمالي الطلبات في فترة زمنية معينة؟
للحصول على إجمالي الطلبات في فترة زمنية معينة باستخدام Prometheus ، يمكنك استخدام وظيفة * sum * جنبا إلى جنب مع وظيفة * المعدل *. فيما يلي استفسار مثال يمنحك إجمالي عدد الطلبات في الساعة الأخيرة: sum(rate(http_requests_total[1h]))
في هذا الاستعلام ، يكون http_requests_total هو اسم المقياس الذي يتتبع العدد الإجمالي لطلبات HTTP ، وتحسب وظيفة المعدل معدل الطلبات لكل ثانية على مدار الساعة الأخيرة. ثم تضيف وظيفة المجموع جميع الطلبات لمنحك إجمالي عدد الطلبات في الساعة الأخيرة.
يمكنك ضبط النطاق الزمني عن طريق تغيير المدة في وظيفة المعدل . على سبيل المثال ، إذا كنت ترغب في الحصول على إجمالي عدد الطلبات في اليوم الأخير ، فيمكنك تغيير الوظيفة إلى التقييم (http_requests_total [1d]) .
ماذا تعني هكتار في بروميثيوس؟
HA يرمز إلى ارتفاع توافر. هذا يعني أن النظام مصمم ليكون موثوقًا للغاية ومتاحًا دائمًا ، حتى في مواجهة الإخفاقات أو غيرها من القضايا. في الممارسة العملية ، يتضمن هذا عادةً إنشاء مثيلات متعددة من Prometheus وضمان أن يتم مزامنتها جميعًا وقادرة على العمل بسلاسة. يمكن تحقيق ذلك من خلال مجموعة متنوعة من التقنيات ، مثل موازنة التحميل ، والنسخ المتماثل ، وآليات الفشل. من خلال تنفيذ HA في Prometheus ، يمكن للمستخدمين التأكد من أن بيانات المراقبة الخاصة بهم متوفرة دائمًا ومحدثة ، حتى في مواجهة فشل الأجهزة أو البرامج ، أو مشكلات الشبكة ، أو المشكلات الأخرى التي قد تسبب وقت التوقف أو فقدان البيانات.
كيف تنضم إلى مقايين؟
في Prometheus ، يمكن تحقيق الانضمام إلى مقايين باستخدام وظيفة * Join () *. تجمع وظيفة * Join () * بين سلسلة زمنية أو أكثر بناءً على قيم التسمية الخاصة بهم. يستغرق وسيطتين إلزاميتين: *على *و *الجدول *. تحدد الوسيطة ON الملصقات للانضمام * على * و * الجدول * الوسيطة تحدد السلسلة الزمنية للانضمام. إليك مثال على كيفية الانضمام إلى مقايين باستخدام وظيفة Join () :
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
في هذا المثال ، تجمع وظيفة Join () بين سلسلة الوقت request_count_total و error_count_total استنادًا إلى قيم خدمتهم وقيم التسمية . وظيفة sum_series () ثم تحسب مجموع السلسلة الزمنية الناتجة
كيف تكتب استعلامًا يعيد قيمة الملصق؟
لكتابة استعلام يرجع قيمة التسمية في Prometheus ، يمكنك استخدام وظيفة * label_values *. تأخذ وظيفة * label_values * وسيطتين: اسم التسمية واسم المقياس. على سبيل المثال ، إذا كان لديك مقياس يسمى http_requests_total مع تسمية تسمى الطريقة ، وتريد إرجاع جميع قيم تسمية الطريقة ، يمكنك استخدام الاستعلام التالي:
label_values(http_requests_total, method)
سيؤدي ذلك إلى إرجاع قائمة بجميع القيم الخاصة بملصق الطريقة في مقياس HTTP_Requests_Total . يمكنك بعد ذلك استخدام هذه القائمة في استفسارات أخرى أو لتصفية بياناتك.
كيف يمكنك تحويل CPU_USER_Seconds إلى استخدام وحدة المعالجة المركزية في النسبة المئوية؟
لتحويل * CPU_USER_SECONDS * إلى استخدام وحدة المعالجة المركزية في النسبة المئوية ، تحتاج إلى تقسيمها على إجمالي الوقت المنقضي وعدد نوى وحدة المعالجة المركزية ، ثم تضاعف بمقدار 100 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
هنا، هو اسم الوظيفة التي تريد الاستعلام عنها ، هو النطاق الزمني الذي تريد الاستعلام عنه (على سبيل المثال 5M ، 1H ) ، و هو عدد نوى وحدة المعالجة المركزية على الجهاز الذي تستفسر عنه.
على سبيل المثال ، للحصول على استخدام وحدة المعالجة المركزية في النسبة المئوية لآخر 5 دقائق لوظيفة تدعى My-Job تعمل على جهاز مع 4 نوى وحدة المعالجة المركزية ، يمكنك استخدام الاستعلام التالي:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
يذهب
ما هي بعض خصائص لغة البرمجة GO؟
- كتابة قوية وثابتة - لا يمكن تغيير نوع المتغيرات مع مرور الوقت ويجب تعريفها في وقت الترجمة
- البساطة
في - أوقات التجميع السريعة
- المدمجة المدمجة
- القمامة التي تم جمعها
- منصة مستقلة
- إلى ثنائية مستقلة - أي شيء تحتاجه لتشغيل التطبيق الخاص بك سيتم تجميعها في ثنائي واحد. مفيد جدا لإدارة الإصدار في وقت التشغيل.
الذهاب أيضا مجتمع جيد.
ما هو الفرق بين var x int = 2 و x := 2 ؟
والنتيجة هي نفسها ، متغير مع القيمة 2.
مع var x int = 2 نقوم بإعداد النوع المتغير إلى عدد صحيح بينما مع x := 2 نسمح للذهاب إلى حد ذاته من النوع.
صحيح أم خطأ؟ في GO ، يمكننا RedeClare متغيرات وبمجرد إعلاننا أنه يجب علينا استخدامه.
خطأ شنيع. لا يمكننا Redeclare المتغيرات ولكن نعم ، يجب أن نستخدم المتغيرات المعلنة.
ما هي مكتبات الذهاب التي استخدمتها؟
يجب الإجابة على ذلك بناءً على استخدامك ولكن بعض الأمثلة هي:
ما هي المشكلة في كتلة الكود التالية؟ كيفية اصلاحها؟ func main() {
var x float32 = 13.5
var y int
y = x
}
تحاول الكتلة التالية من الكود تحويل عدد صحيح 101 إلى سلسلة ولكن بدلاً من ذلك نحصل على "E". لماذا هذا؟ كيفية اصلاحها؟ package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
يبدو أن قيمة Unicode التي يتم تعيينها في 101 وتستخدمها لتحويل عدد صحيح إلى سلسلة. إذا كنت ترغب في الحصول على "101" ، فيجب عليك استخدام الحزمة "strconv" واستبدال y = string(x) بـ y = strconv.Itoa(x)
ما هو الخطأ في الكود التالي؟: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
لا يمكن إعلان الثوابت في GO إلا باستخدام تعبيرات ثابتة. لكن x ، y ومجموعها متغير.
const initializer x + y is not a constant
ماذا سيكون إخراج الكتلة التالية من الكود؟: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
يتم استخدام معرف IOTA GO في إعلانات const لتبسيط تعريفات الأرقام المتزايدة. لأنه يمكن استخدامه في التعبيرات ، فإنه يوفر عمومية تتجاوز التعدادات البسيطة.
x و y في مجموعة iota الأولى ، z في الثانية.
صفحة iota في Go Wiki
ما الذي يستخدم في الذهاب؟
إنه يتجنب الاضطرار إلى إعلان جميع المتغيرات لقيم الإرجاع. ويسمى المعرف الفارغ.
الجواب في ذلك
ماذا سيكون إخراج الكتلة التالية من الكود؟: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
منذ إعلان IOTA الأول بالقيمة 3 ( + 3 ) ، فإن القيمة التالية لها القيمة 4
ماذا سيكون إخراج الكتلة التالية من الكود؟: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
الإخراج: 2 1 3
Aritcle حول Sync/WaitGroup
حزمة جولانج مزامنة
ماذا سيكون إخراج الكتلة التالية من الكود؟: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
الإخراج:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
في mod1 A IS Link ، وعندما نستخدم a[i] ، فإننا نغير قيمة s1 إلى. ولكن في mod2 ، يقوم append بإنشاء شريحة جديدة ، ونحن نغير فقط a ، وليس s2 .
aritcle حول المصفوفات ، مدونة منشور حول append
ماذا سيكون إخراج الكتلة التالية من الكود؟: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
الإخراج: 3
حاوية/حاوية Golang
مونجو
ما هي مزايا mongodb؟ أو بعبارة أخرى ، لماذا اختيار mongodb وليس تنفيذ آخر من NOSQL؟
مزايا MongoDB هي على النحو التالي:
- مخطط
- من السهل التوسع
- لا يوجد معقد ينضم
- هيكل كائن واحد واضح
ما هو الفرق بين SQL و NOSQL؟
الفرق الرئيسي هو أن قواعد بيانات SQL يتم تنظيمها (يتم تخزين البيانات في شكل جداول ذات صفوف وأعمدة - مثل جدول جدول بيانات Excel) بينما لا يتم تنظيم NOSQL ، ويمكن أن يختلف تخزين البيانات اعتمادًا على كيفية إعداد NOSQL DB ، مثل زوج القيمة الرئيسية ، الموجهة نحو المستند ، إلخ.
في أي سيناريوهات تفضل استخدام NoSQL/Mongo على SQL؟
بيانات غير متجانسة تتغير في كثير من الأحيان- اتساق البيانات والنزاهة ليست أولوية قصوى
- أفضل إذا كانت قاعدة البيانات تحتاج إلى التوسع بسرعة
ما هي الوثيقة؟ ما هي المجموعة؟
المستند هو سجل في MongoDB ، والذي يتم تخزينه بتنسيق BSON (Binary JSON) وهو الوحدة الأساسية للبيانات في MongoDB.- المجموعة عبارة عن مجموعة من المستندات ذات الصلة المخزنة في قاعدة بيانات واحدة في MongoDB.
ما هو المجمع؟
- المجمع هو إطار عمل في MongoDB يقوم بعمليات على مجموعة من البيانات لإرجاع نتيجة محسوبة واحدة.
ما هو أفضل؟ مستندات مضمنة أو مشار إليها؟
- لا توجد إجابة نهائية على ما هو أفضل ، فهذا يعتمد على حالة الاستخدام المحددة والمتطلبات. بعض التفسيرات: توفر المستندات المدمجة تحديثات ذرية ، بينما تسمح المستندات المرجعية بتطبيع أفضل.
هل قمت بإجراء تحسينات استرجاع البيانات في مونغو؟ إذا لم يكن الأمر كذلك ، هل يمكنك التفكير في طرق لتحسين استرجاع البيانات البطيء؟
- بعض الطرق لتحسين استرجاع البيانات في MongoDB هي: الفهرسة وتصميم المخطط المناسب وتحسين الاستعلام وموازنة تحميل قاعدة البيانات.
استفسارات
اشرح هذا الاستعلام: db.books.find({"name": /abc/})
اشرح هذا الاستعلام: db.books.find().sort({x:1})
ما هو الفرق بين Find () و find_one ()؟
find() إرجاع جميع المستندات التي تتطابق مع ظروف الاستعلام.- تقوم Find_One () بإرجاع مستند واحد فقط يطابق ظروف الاستعلام (أو NULL إذا لم يتم العثور على تطابق).
كيف يمكنك تصدير البيانات من Mongo DB؟
SQL
تمارين SQL
| اسم | عنوان | الهدف والتعليمات | حل | تعليقات |
|---|
| وظائف مقابل المقارنات | تحسينات الاستعلام | يمارس | حل | |
SQL التقييم الذاتي
ما هو SQL؟
SQL (لغة الاستعلام المنظمة) هي لغة قياسية لقواعد البيانات العلائقية (مثل MySQL ، MariaDB ، ...).
يتم استخدامه للقراءة وتحديث وإزالة وإنشاء البيانات في قاعدة بيانات علائقية.
كيف تختلف SQL عن NoSQL
الفرق الرئيسي هو أن قواعد بيانات SQL يتم تنظيمها (يتم تخزين البيانات في شكل جداول ذات صفوف وأعمدة - مثل جدول جدول بيانات Excel) بينما لا يتم تنظيم NOSQL ، ويمكن أن يختلف تخزين البيانات اعتمادًا على كيفية إعداد NOSQL DB ، مثل زوج القيمة الرئيسية ، الموجهة نحو المستند ، إلخ.
متى من الأفضل استخدام SQL؟ NoSQL؟
SQL - أفضل استخدام عندما تكون تكامل البيانات أمرًا بالغ الأهمية. عادة ما يتم تنفيذ SQL مع العديد من الشركات والمناطق داخل مجال التمويل بسبب امتثاله للحمض.
NOSQL - رائع إذا كنت بحاجة إلى توسيع نطاق الأشياء بسرعة. تم تصميم NOSQL مع وضع تطبيقات الويب في الاعتبار ، لذلك يعمل بشكل رائع إذا كنت بحاجة إلى نشر نفس المعلومات حولها بسرعة على خوادم متعددة
بالإضافة إلى ذلك ، نظرًا لأن NOSQL لا يلتزم بالجدول الصارم مع بنية الأعمدة والصفوف التي تتطلبها قواعد البيانات العلائقية ، يمكنك تخزين أنواع البيانات المختلفة معًا.
SQL العملي - الأساسيات
بالنسبة لهذه الأسئلة ، سنستخدم جداول العملاء والطلبات الموضحة أدناه:
عملاء
| customer_id | اسم_العميل | items_in_cart | cash_spent_to_date |
|---|
| 100204 | جون سميث | 0 | 20.00 |
| 100205 | جين سميث | 3 | 40.00 |
| 100206 | بوبي فرانك | 1 | 100.20 |
طلبات
| customer_id | معرف_الطلب | غرض | سعر | Date_sold |
|---|
| 100206 | أ123 | مطاط الحبيب | 2.20 | 2019-09-18 |
| 100206 | أ123 | حمام الفقاعة | 8.00 | 2019-09-18 |
| 100206 | Q987 | 80 حزمة TP | 90.00 | 2019-09-20 |
| 100205 | Z001 | طعام القط - سمك التونة | 10.00 | 2019-08-05 |
| 100205 | Z001 | طعام القط - الدجاج | 10.00 | 2019-08-05 |
| 100205 | Z001 | طعام القط - لحوم البقر | 10.00 | 2019-08-05 |
| 100205 | Z001 | Cat Food - Kitty Quesadilla | 10.00 | 2019-08-05 |
| 100204 | x202 | قهوة | 20.00 | 2019-04-29 |
كيف يمكنني اختيار جميع الحقول من هذا الجدول؟
يختار *
من العملاء ؛
كم عدد العناصر الموجودة في عربة جون؟
حدد العناصر_in_cart
من العملاء
حيث customer_name = "John Smith" ؛
ما هو مجموع جميع الأموال التي تنفقها جميع العملاء؟
حدد SUM (cash_spent_to_date) كـ sum_cash
من العملاء ؛
كم عدد الأشخاص الذين لديهم عناصر في عربة التسوق الخاصة بهم؟
حدد العد (1) كـ number_of_people_w_items
من العملاء
حيث العناصر _in_cart> 0 ؛
كيف تنضم إلى جدول العميل إلى جدول الطلبات؟
سوف تنضم إليهم على المفتاح الفريد. في هذه الحالة ، يكون المفتاح الفريد هو Customer_ID في كل من جدول العملاء وجدول الطلبات
كيف يمكنك إظهار أي عميل طلب العناصر؟
حدد C.Customer_Name ، O.Item
من العملاء ج
اليسار الانضمام أوامر o
على c.customer_id = o.customer_id ؛
باستخدام بيان مع بيان ، كيف تُظهر من الذي طلب طعام القط ، والمبلغ الإجمالي من الأموال التي تنفق؟
مع cat_food مثل (
حدد customer_id ، sum (السعر) كـ Total_price
من أوامر
حيث عنصر مثل "٪ Cat Food ٪"
مجموعة من قبل العميل
)
حدد Customer_Name ، Total_price
من العملاء ج
Inner Join Cat_food F
على c.customer_id = f.customer_id
حيث c.customer_id في (حدد customer_id من cat_food) ؛
على الرغم من أن هذا كان عبارة بسيطة ، إلا أن بند "مع" يضيء حقًا عندما يحتاج استعلام معقد إلى تشغيل على طاولة قبل الانضمام إلى آخر. مع العبارات لطيفة ، لأنك تنشئ درجة حرارة زائفة عند تشغيل استعلامك ، بدلاً من إنشاء جدول جديد بالكامل.
لم يكن مجموع عمليات شراء Cat Food متاحة بسهولة ، لذلك استخدمنا عبارة مع بيان لإنشاء جدول زائفة لاسترداد مجموع الأسعار التي ينفقها كل عميل ، ثم انضم إلى الجدول بشكل طبيعي.
أي من الاستفسارات التالية التي ستستخدمها؟ SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
عندما تستخدم وظيفة ( YEAR(purchased_at) ) ، يتعين عليها مسح قاعدة البيانات بأكملها بدلاً من استخدام الفهارس وبشكل الأساس للعمود كما هو ، في حالته الطبيعية.
OpenStack
ما هي المكونات/مشاريع OpenStack التي تعرفها؟
هل يمكن أن تخبرني ما هي كل من الخدمات/المشاريع التالية المسؤولة عن؟:- نوفا
- نيوترون
- جمرة
- يلمح
- Keystone
نوفا - إدارة الحالات الافتراضية- النيوترون - إدارة الشبكات من خلال تزويد الشبكة كخدمة (NAAS)
- سندر - تخزين كتلة
- Glance - إدارة الصور للأجهزة والحاويات الافتراضية (البحث ، الحصول والتسجيل)
- Keystone - خدمة المصادقة عبر السحابة
حدد الخدمة/المشروع المستخدم لكل مما يلي:- نسخ أو مثيلات لقطة
- واجهة المستخدم الرسومية لعرض الموارد وتعديلها
- تخزين كتلة
- إدارة الحالات الافتراضية
لمحة - خدمة الصور. يستخدم أيضًا لنسخ أو مثيلات لقطة- Horizon - واجهة المستخدم الرسومية لعرض الموارد وتعديلها
- سندر - تخزين كتلة
- نوفا - إدارة الحالات الافتراضية
ما هو المستأجر/المشروع؟
تحديد صواب أو خطأ:- OpenStack مجاني للاستخدام
- الخدمة المسؤولة عن الشبكات هي نظرة
- الغرض من المستأجر/المشروع هو مشاركة الموارد بين المشاريع المختلفة ومستخدمي OpenStack
صف بالتفصيل كيف تطرح مثيلًا مع عنوان IP عائم
يمكنك الحصول على مكالمة من أحد العملاء يقولون: "يمكنني ping مثيلتي ولكن لا يمكنني الاتصال (SSH)". ماذا قد تكون المشكلة؟
ما هي أنواع الشبكات التي تدعمها OpenStack؟
كيف يمكنك تصحيح مشكلات تخزين OpenStack؟ (الأدوات ، السجلات ، ...)
كيف يمكنك تصحيح مشكلات حساب OpenStack؟ (الأدوات ، السجلات ، ...)
OpenStack Deployment & Tripleo
هل قمت بنشر OpenStack في الماضي؟ إذا كانت الإجابة بنعم ، هل يمكنك وصف كيف فعلت ذلك؟
هل أنت على دراية بـ Tripleo؟ كيف يختلف عن DevStack أو Packstack؟
يمكنك أن تقرأ عن Tripleo هنا
OpenStack حساب
هل يمكنك وصف نوفا بالتفصيل؟
تستخدم لتوفير وإدارة الحالات الافتراضية- وهو يدعم متعددة في المستويات المختلفة-التسجيل ، والتحكم في المستخدم النهائي ، والتدقيق ، إلخ.
- قابلة للتطوير للغاية
- يمكن إجراء المصادقة باستخدام النظام الداخلي أو LDAP
- يدعم أنواعًا متعددة من تخزين الكتلة
- يحاول أن تكون أجهزة وفرط لاضوت
ماذا تعرف عن هندسة نوفا والمكونات؟
Nova -api - الخادم الذي يقدم البيانات الوصفية وحساب واجهات برمجة التطبيقات- تتواصل مكونات Nova المختلفة باستخدام قائمة انتظار (RabbitMQ عادة) وقاعدة بيانات
- يتم فحص طلب إنشاء مثيل بواسطة Nova-Scheduler الذي يحدد مكان إنشاء المثيل وتشغيله
- Nova-Compute هو المكون المسؤول عن التواصل مع Hypervisor لإنشاء المثيل وإدارة دورة حياته
OpenStack Networking (نيوترون)
اشرح النيوترون بالتفصيل
أحد المكونات الأساسية في OpenStack ومشروع مستقل- ركز النيوترون على توصيل الشبكات كخدمة
- مع النيوترون ، يمكن للمستخدمين إعداد شبكات في السحابة وتكوين وإدارة مجموعة متنوعة من خدمات الشبكة
- يتفاعل النيوترون مع:
Keystone - تفويض مكالمات API
- نوفا - تواصل نوفا مع النيوترون لتوصيل NECs في شبكة
- Horizon - يدعم كيانات الشبكات في لوحة القيادة ويوفر أيضًا عرض طوبولوجيا يتضمن تفاصيل الشبكات
اشرح كل من المكونات التالية:- النيوترون DHCP-Agent
- النيوترون-L3 وكيل
- وكيل قياس النيوترون
- النيوترون-*-AgTent
- خادم نيوتروني
Neutron-L3-Agent-L3/NAT إعادة توجيه (يوفر الوصول الخارجي للشبكة لـ VMs على سبيل المثال)- Neutron-DHCP-Agent-خدمات DHCP
- وكيل قياس النيوترون-L3 قياس حركة المرور
- Neutron-*-AgTent-يدير تكوين Vswitch المحلي على كل حساب (استنادًا إلى البرنامج المساعد المختار)
- خادم النيوترون - يعرض واجهة برمجة تطبيقات الشبكات وينتقل الطلبات إلى المكونات الإضافية الأخرى إذا لزم الأمر
اشرح أنواع الشبكة هذه:- شبكة الإدارة
- شبكة الضيف
- شبكة API
- الشبكة الخارجية
شبكة الإدارة - تستخدم للاتصال الداخلي بين مكونات OpenStack. لا يمكن الوصول إلى أي عنوان IP في هذه الشبكة إلا داخل جهاز البيانات- شبكة الضيوف - تستخدم للتواصل بين الحالات/VMS
- شبكة API - تستخدم للخدمات API الاتصالات. يمكن الوصول إلى أي عنوان IP في هذه الشبكة للجمهور
- الشبكة الخارجية - تستخدم للاتصال العام. يمكن لأي شخص الوصول إلى أي عنوان IP في هذه الشبكة على الإنترنت
في أي ترتيب يجب عليك إزالة الكيانات التالية:- شبكة
- ميناء
- جهاز التوجيه
- الشبكة الفرعية
- شبكة
- توجيه الشبكة
- الفرعية
- المنفذ
هناك العديد من الأسباب لذلك. واحد على سبيل المثال: لا يمكنك إزالة جهاز التوجيه إذا كانت هناك منافذ نشطة مخصصة له.
ما هي شبكة المزود؟
ما هي المكونات والخدمات الموجودة لـ L2 و L3؟
ما هو مكون ML2؟ اشرح الهندسة المعمارية
ما هو وكيل L2؟ كيف تعمل وما هو المسؤول؟
ما هو وكيل L3؟ كيف تعمل وما هو المسؤول؟
اشرح ما هو وكيل البيانات الوصفية مسؤولة عن
ما هي كيانات الشبكات التي تدعمها نيوترون؟
How do you debug OpenStack networking issues? (tools, logs, ...)
OpenStack - Glance
Explain Glance in detail
Glance is the OpenStack image service- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
صحيح أم خطأ؟ there can be two objects with the same name in the same container but not in two different containers
خطأ شنيع. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- دور
- Tenant/Project
- خدمة
- نقطة النهاية
- رمز مميز
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
استخدام:
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- سويفت
- الصحراء
- ساخر
- دفين
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- PAM
- ميمكاشد
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
دمية
What is Puppet? How does it works?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:- الوحدة النمطية
- يظهر
- العقدة
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
مرن
What is the Elastic Stack?
The Elastic Stack consists of:
- بحث مرن
- كيبانا
- لوغستاش
- يدق
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
بحث مرن
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. ماذا يعني ذلك؟ What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
صحيح أم خطأ؟ Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
خطأ شنيع. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
_فِهرِس- _بطاقة تعريف
- _يكتب
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". ماذا يعني ذلك؟
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? ما الذي ستستخدمه من أجله؟
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
لوغستاش
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
كيبانا
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". ماذا يعني ذلك؟
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Read here
صحيح أم خطأ؟ a single harvester harvest multiple files, according to the limits set in filebeat.yml
خطأ شنيع. One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
Elastic Stack
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
وزعت
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
شبكة- وحدة المعالجة المركزية
- ذاكرة
- القرص
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
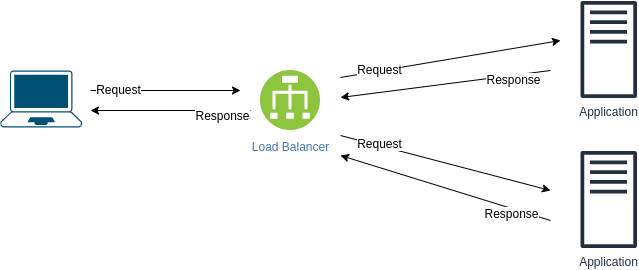
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage, memory, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
متنوعات
| اسم | عنوان | Objective & Instructions | حل | تعليقات |
|---|
| Highly Available "Hello World" | يمارس | حل | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
واجهة برمجة التطبيقات
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
صحيح أم خطأ؟ API Definition is the same as API Specification
خطأ شنيع. From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
المزايا:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
إذن- التسجيل
- المصادقة
- Ordering
- الواجهة الأمامية
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use? لماذا؟
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
صحيح أم خطأ؟ Any valid JSON file is also a valid YAML file
حقيقي. Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
البرامج الثابتة
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
كاساندرا
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
What is HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP response
صحيح أم خطأ؟ HTTP is stateful
خطأ شنيع. It doesn't maintain state for incoming request.
How HTTP request looks like?
يتكون من:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
يحصل- بريد
- رأس
- يضع
- يمسح
- يتصل
- خيارات
- يتعقب
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. ماذا يعني ذلك؟
The server didn't receive a response from another server it communicates with in a timely manner.
What is a proxy?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Round Robin- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
السلبيات:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
ملفات تعريف الارتباط. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Round Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
التراخيص
Are you familiar with "Creative Commons"? What do you know about it?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
عشوائي
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache. مصدر
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
تخزين
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
الايجابيات:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
الايجابيات:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
اختبار
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- اختبار القدرات
- Volume Testing
- Endurance Testing
التعبير العادي
Given a text file, perform the following exercises
يستخرج
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
يستبدل
Replace tabs with four spaces
Replace 'red' with 'green'
System Design
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. قابلية التوسع
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
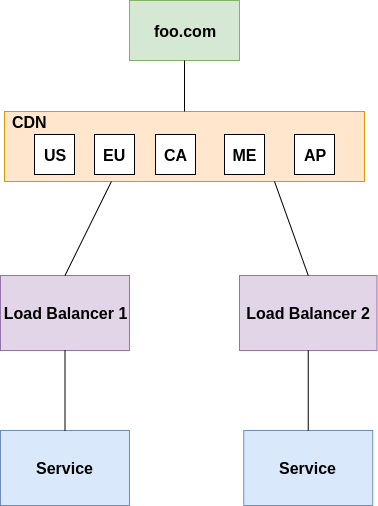
What is the problem with the following architecture and how would you fix it?
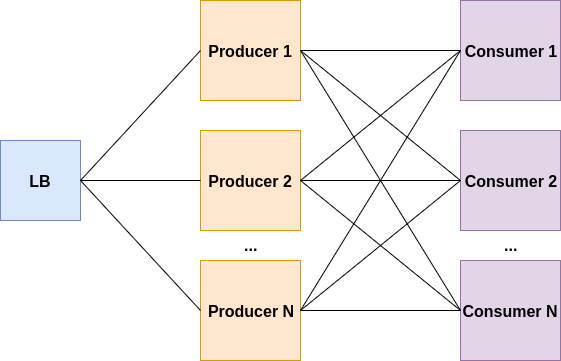
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?

How would you scale the architecture from the previous question to hundreds of users?
مخبأ
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
نلقي نظرة هنا
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrations
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

الأجهزة
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
خارجي- Machine check
- الإدخال/الإخراج
- برنامج
- إعادة تشغيل
- Supervisor call (SVC)
Big Data
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers. صحيح أم خطأ؟ Ceph favor consistency and correctness over performances
حقيقي Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
شاشة- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- مدير
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? كيف يعمل؟
باكر
What is Packer? ما هو استخدامه ل؟
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
يطلق
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
الشهادات
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. حظ سعيد :)
أوس
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
أزور
- AZ-900 (Latest update: 2021)
كوبيرنيتيس
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




الاعتمادات
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
رخصة


