textgenrnn
T
قم بتدريب الشبكة العصبية الخاصة بك لإنشاء النصوص بسهولة، مهما كان حجمها وتعقيدها، على أي مجموعة بيانات نصية باستخدام بضعة أسطر من التعليمات البرمجية، أو تدرب بسرعة على نص باستخدام نموذج تم تدريبه مسبقًا.
textgenrnn عبارة عن وحدة Python 3 أعلى Keras/TensorFlow لإنشاء char-rnns، مع العديد من الميزات الرائعة:
يمكنك اللعب باستخدام textgenrnn وتدريب أي ملف نصي باستخدام وحدة معالجة الرسومات مجانًا في دفتر الملاحظات التعاوني هذا! اقرأ منشور المدونة هذا أو شاهد هذا الفيديو لمزيد من المعلومات!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
يمكن تدريب النموذج المضمن بسهولة على النصوص الجديدة، ويمكنه إنشاء نص مناسب حتى بعد تمرير واحد للبيانات المدخلة .
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
أوزان النموذج صغيرة نسبيًا (2 ميجابايت على القرص)، ويمكن بسهولة حفظها وتحميلها في نسخة textgenrnn جديدة. ونتيجة لذلك، يمكنك اللعب بالنماذج التي تم تدريبها على مئات التمريرات عبر البيانات. (في الواقع، يتعلم textgenrnn جيدًا لدرجة أنه يتعين عليك زيادة درجة الحرارة بشكل كبير للحصول على مخرجات إبداعية!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
يمكنك أيضًا تدريب نموذج جديد، مع دعم التضمينات على مستوى الكلمة وطبقات RNN ثنائية الاتجاه عن طريق إضافة new_model=True إلى أي وظيفة تدريب.
من الممكن أيضًا المشاركة في كيفية ظهور المخرجات خطوة بخطوة. سيقترح عليك الوضع التفاعلي أفضل خيارات N للحرف/الكلمة التالية، ويسمح لك باختيار واحد.
عند تشغيل textgenrnn في الوحدة الطرفية، قم بتمرير interactive=True و top=N generate . الافتراضي N هو 3.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
وهذا يمكن أن يضيف لمسة إنسانية إلى الإخراج؛ يبدو الأمر وكأنك الكاتب! (مرجع)
يمكن تثبيت textgenrnn من pypi عبر pip :
pip3 install textgenrnnللحصول على أحدث إصدار من textgenrnn، يجب أن يكون لديك إصدار TensorFlow على الأقل 2.1.0 .
يمكنك عرض عرض توضيحي للميزات الشائعة وخيارات تكوين النموذج في Jupyter Notebook هذا.
يحتوي /datasets على أمثلة لمجموعات البيانات باستخدام بيانات Hacker News/Reddit للتدريب على textgenrnn.
يحتوي /weights على نماذج تم تدريبها مسبقًا على مجموعات البيانات المذكورة أعلاه والتي يمكن تحميلها في textgenrnn.
يحتوي /outputs على أمثلة للنص الذي تم إنشاؤه من النماذج المُدربة أعلاه.
يعتمد textgenrnn على مشروع char-rnn بواسطة Andrej Karpathy مع بعض التحسينات الحديثة، مثل القدرة على العمل مع تسلسلات نصية صغيرة جدًا.
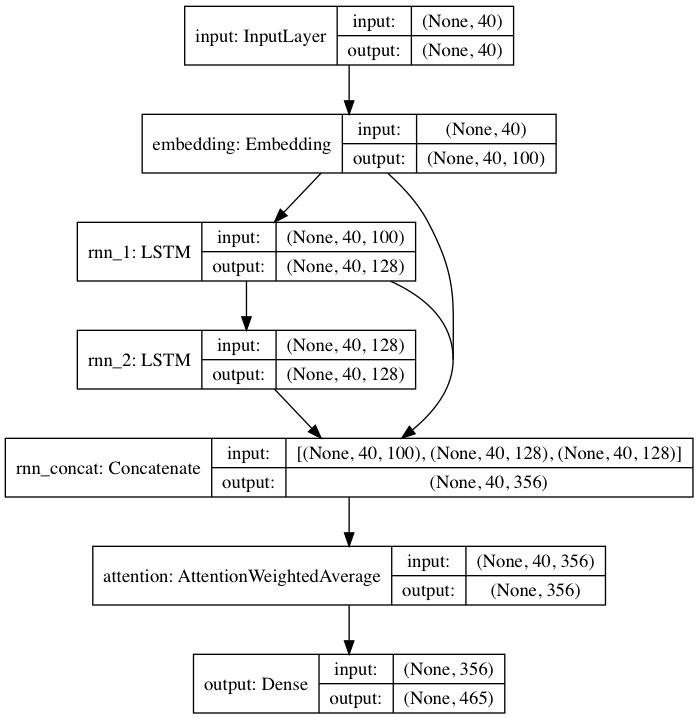
يتبع النموذج المدرّب مسبقًا بنية الشبكة العصبية المستوحاة من DeepMoji. بالنسبة للنموذج الافتراضي، يأخذ textgenrnn مدخلات تصل إلى 40 حرفًا، ويحول كل حرف إلى متجه تضمين أحرف 100-D، ويغذيها في طبقة متكررة ذات ذاكرة طويلة قصيرة المدى (LSTM) مكونة من 128 خلية. يتم بعد ذلك تغذية هذه المخرجات في LSTM آخر مكون من 128 خلية. يتم بعد ذلك تغذية الطبقات الثلاث في طبقة الانتباه لوزن أهم الميزات الزمنية ومتوسطها معًا (وبما أن التضمينات + LSTM الأولى متصلة بالتخطي في طبقة الانتباه، يمكن أن تنتقل تحديثات النموذج إليها بسهولة أكبر وتمنع التلاشي التدرجات). يتم تعيين هذا الإخراج إلى احتمالات لما يصل إلى 394 حرفًا مختلفًا بأنهم الحرف التالي في التسلسل، بما في ذلك الأحرف الكبيرة والأحرف الصغيرة وعلامات الترقيم والرموز التعبيرية. (في حالة تدريب نموذج جديد على مجموعة بيانات جديدة، يمكن تكوين جميع المعلمات الرقمية أعلاه)
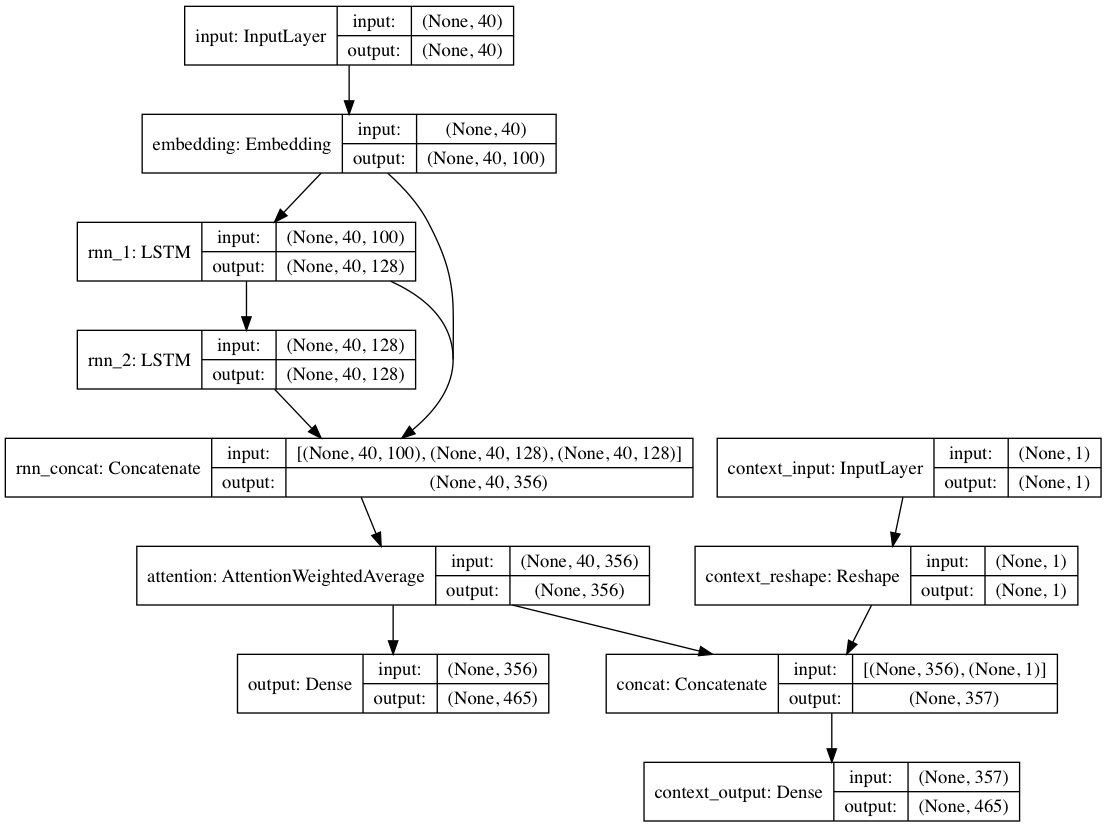
وبدلاً من ذلك، إذا تم توفير تسميات السياق مع كل مستند نصي، فيمكن تدريب النموذج في الوضع السياقي، حيث يتعلم النموذج النص في ضوء السياق بحيث تتعلم الطبقات المتكررة اللغة غير السياقية . يمكن لمسار النص فقط أن يتراجع عن الطبقات غير السياقية؛ وبشكل عام، يؤدي هذا إلى تدريب أسرع بكثير وأداء نموذجي كمي ونوعي أفضل من مجرد تدريب النموذج على النص وحده.
يتم تدريب أوزان النماذج المضمنة في الحزمة على مئات الآلاف من المستندات النصية من عمليات إرسال Reddit (عبر BigQuery)، من مجموعة متنوعة جدًا من subreddits. تم تدريب الشبكة أيضًا باستخدام النهج غير السياقي المذكور أعلاه من أجل تحسين أداء التدريب وتخفيف التحيز التأليفي.
عند ضبط النموذج على مجموعة بيانات جديدة من النصوص باستخدام textgenrnn، يتم إعادة تدريب جميع الطبقات. ومع ذلك، نظرًا لأن الشبكة الأصلية المدربة مسبقًا لديها "معرفة" أكثر قوة في البداية، فإن textgenrnn الجديد يتدرب بشكل أسرع وأكثر دقة في النهاية، ويمكن أن يتعلم علاقات جديدة غير موجودة في مجموعة البيانات الأصلية (على سبيل المثال، تتضمن عمليات تضمين الأحرف المدربة مسبقًا السياق للشخصية لجميع الأنواع الممكنة من قواعد الإنترنت الحديثة).
بالإضافة إلى ذلك، تتم إعادة التدريب باستخدام مُحسِّن قائم على الزخم ومعدل تعلم متدهور خطيًا، وكلاهما يمنع انفجار التدرجات ويقلل من احتمالية انحراف النموذج بعد التدريب لفترة طويلة.
لن تحصل على نص عالي الجودة بنسبة 100% من الوقت ، حتى مع وجود شبكة عصبية مدربة تدريبًا عاليًا. هذا هو السبب الرئيسي وراء قيام منشورات المدونات سريعة الانتشار/تغريدات Twitter التي تستخدم إنشاء نص NN غالبًا بتوليد الكثير من النصوص وتنظيم/تحرير أفضل النصوص بعد ذلك.
وسوف تختلف النتائج بشكل كبير بين مجموعات البيانات . نظرًا لأن الشبكة العصبية المدربة مسبقًا صغيرة نسبيًا، فلا يمكنها تخزين قدر كبير من البيانات مثل شبكات RNN التي تتباهى عادةً في منشورات المدونات. للحصول على أفضل النتائج، استخدم مجموعة بيانات تحتوي على ما لا يقل عن 2000 إلى 5000 مستند. إذا كانت مجموعة البيانات أصغر، فستحتاج إلى تدريبها لفترة أطول عن طريق تعيين num_epochs أعلى عند استدعاء طريقة تدريب و/أو تدريب نموذج جديد من البداية. وحتى مع ذلك، لا يوجد حاليًا أي إرشاد جيد لتحديد النموذج "الجيد".
ليست هناك حاجة إلى وحدة معالجة الرسومات لإعادة تدريب textgenrnn، ولكن التدريب على وحدة المعالجة المركزية سيستغرق وقتًا أطول بكثير. إذا كنت تستخدم وحدة معالجة الرسومات، فإنني أوصي بزيادة معلمة batch_size لاستخدام أفضل للأجهزة.
مزيد من الوثائق الرسمية
تنفيذ على الويب باستخدام Tensorflow.js (يعمل بشكل جيد نظرًا لصغر حجم الشبكة)
طريقة لتصور مخرجات طبقة الانتباه لمعرفة كيف "تتعلم" الشبكة.
وضع يسمح باستخدام بنية النموذج في محادثات chatbot (قد يتم إصداره كمشروع منفصل)
المزيد من العمق تجاه السياق (السياق الموضعي + السماح بتسميات السياق المتعددة)
شبكة أكبر مدربة مسبقًا يمكنها استيعاب تسلسلات أطول للأحرف وفهم أكثر تعمقًا للغة، مما يؤدي إلى إنشاء جمل أفضل.
تفعيل softmax الهرمي للنماذج على مستوى الكلمات (بمجرد حصول Keras على دعم جيد لها).
FP16 للتدريب فائق السرعة على وحدات Volta/TPUs (بمجرد حصول Keras على دعم جيد لها).
ماكس وولف (@minimaxir)
يتم دعم مشاريع ماكس مفتوحة المصدر من خلال موقع Patreon الخاص به. إذا وجدت هذا المشروع مفيدًا، فإن أي مساهمات مالية لـ Patreon موضع تقدير وسيتم استخدامها بشكل إبداعي جيد.
Andrej Karpathy على الاقتراح الأصلي لـ char-rnn عبر منشور المدونة "الفعالية غير المعقولة للشبكات العصبية المتكررة".
دانيال جريجالفا لمساهمته في الوضع التفاعلي.
معهد ماساتشوستس للتكنولوجيا
رمز طبقة الانتباه المستخدم من DeepMoji (مرخص من معهد ماساتشوستس للتكنولوجيا)


