vaex
Version linked to the paper
Vaex هي مكتبة Python عالية الأداء لإطارات البيانات البطيئة خارج النواة (على غرار Pandas)، لتصور مجموعات البيانات الجدولية الكبيرة واستكشافها. يقوم بحساب الإحصائيات مثل المتوسط والمجموع والعدد والانحراف المعياري وما إلى ذلك، على شبكة ذات أبعاد N لأكثر من مليار ( 10^9 ) عينة/صف في الثانية . يتم التصور باستخدام الرسوم البيانية ومخططات الكثافة وعرض الحجم ثلاثي الأبعاد ، مما يسمح بالاستكشاف التفاعلي للبيانات الضخمة. يستخدم Vaex تعيين الذاكرة وسياسة نسخ الذاكرة الصفرية والحسابات البطيئة للحصول على أفضل أداء (دون إهدار الذاكرة).
مع النقطة:
$ pip install vaex
أو كوندا:
$ conda install -c conda-forge vaex
لمزيد من التفاصيل، راجع الوثائق
دعم HDF5 وApache Arrow.

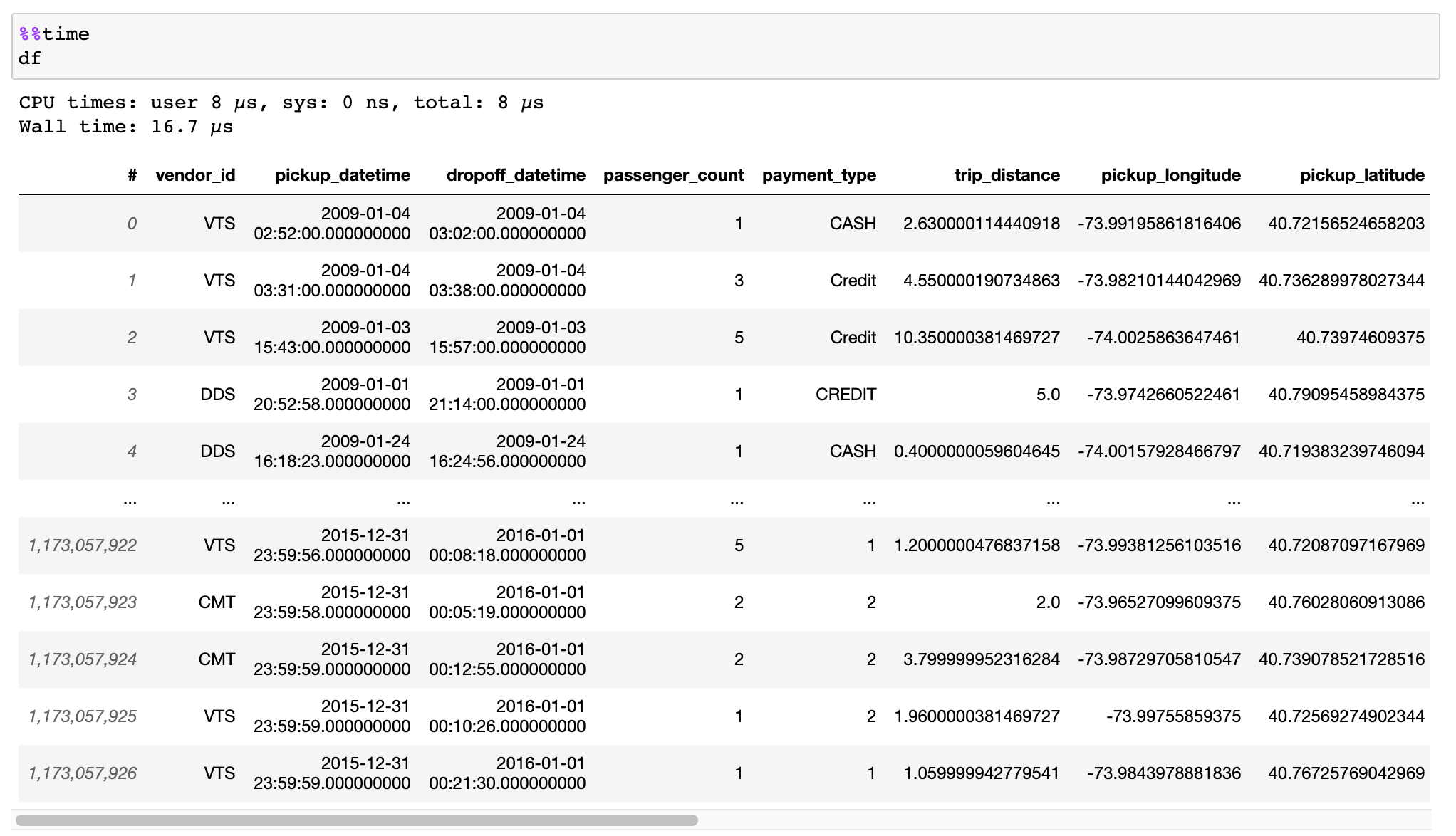
اقرأ الوثائق حول كيفية تحويل بياناتك بكفاءة من ملفات CSV أو Pandas DataFrames أو مصادر أخرى.
يتم دعم البث البطيء من S3 مع تعيين الذاكرة.

لا تضيع الذاكرة أو الوقت في هندسة الميزات، فنحن نقوم (بتكاسل) بتحويل بياناتك عند الحاجة.
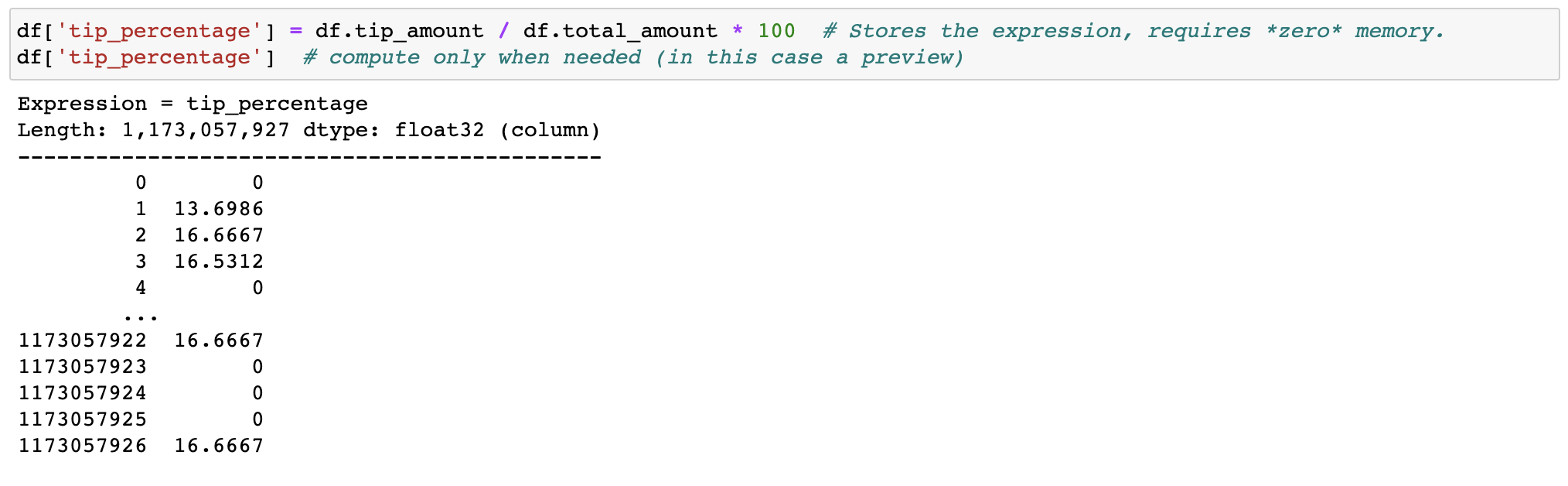
لن تؤدي تصفية التعبيرات وتقييمها إلى إضاعة الذاكرة عن طريق عمل نسخ؛ يتم الاحتفاظ بالبيانات دون تغيير على القرص، وسيتم بثها فقط عند الحاجة إليها. قم بتأخير الوقت قبل أن تحتاج إلى مجموعة.
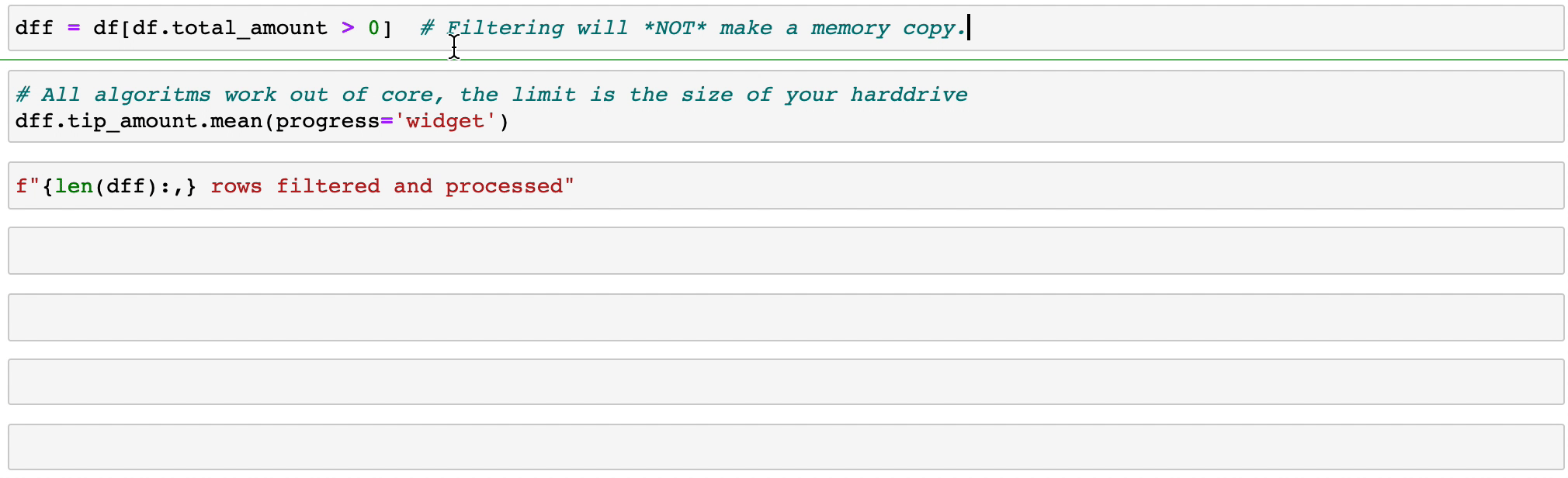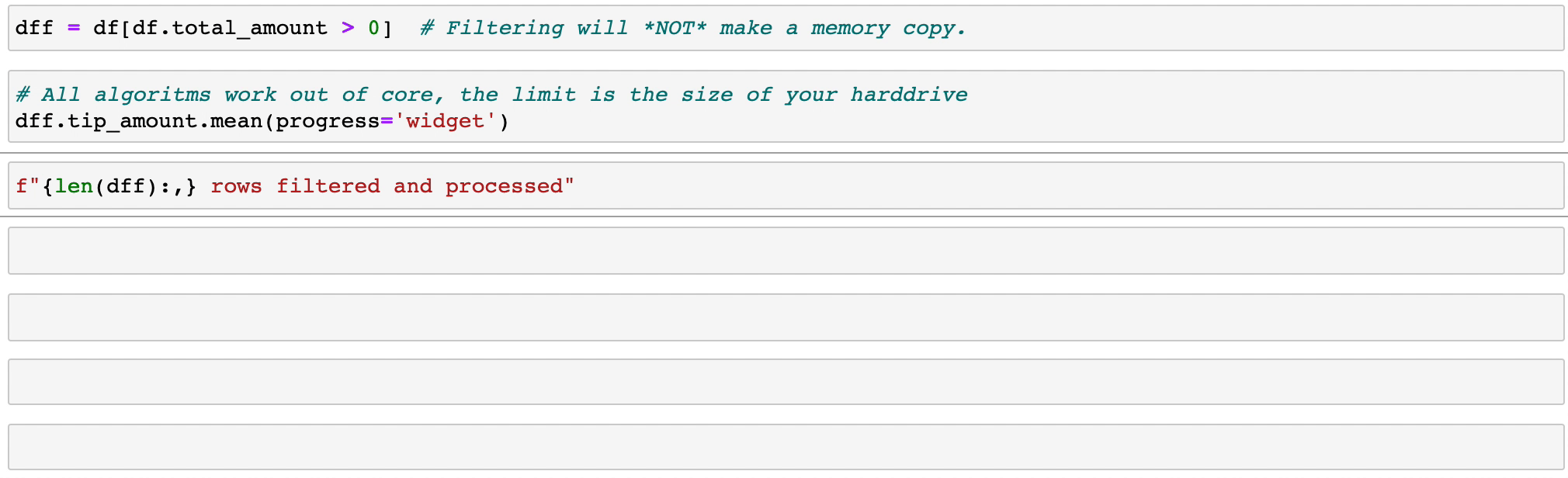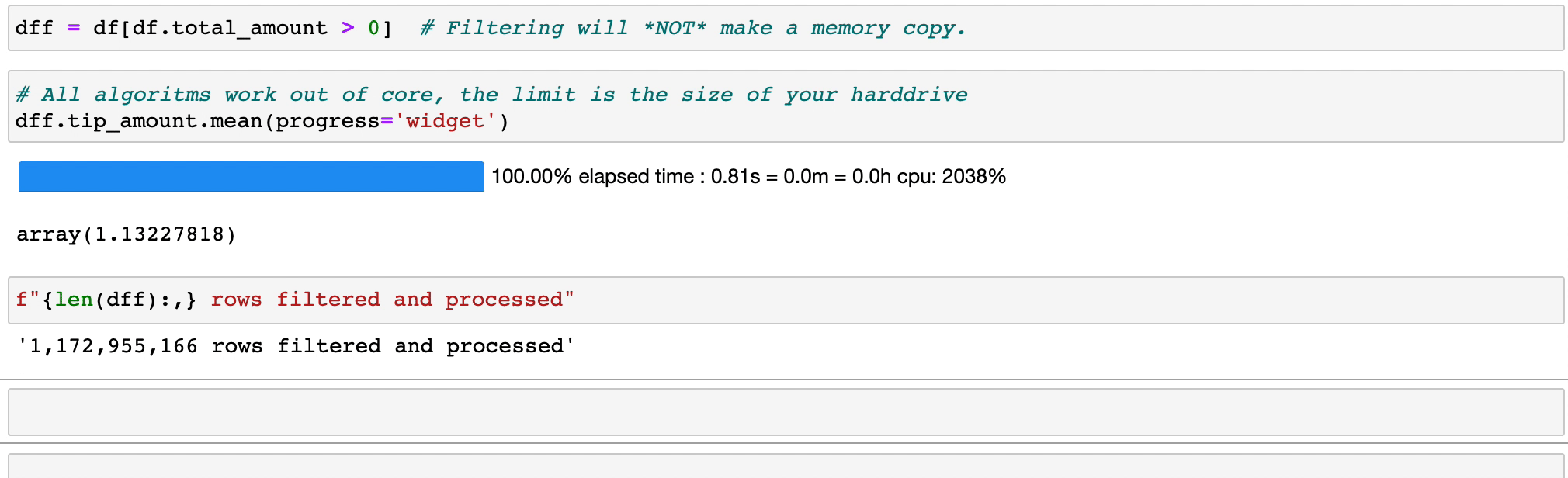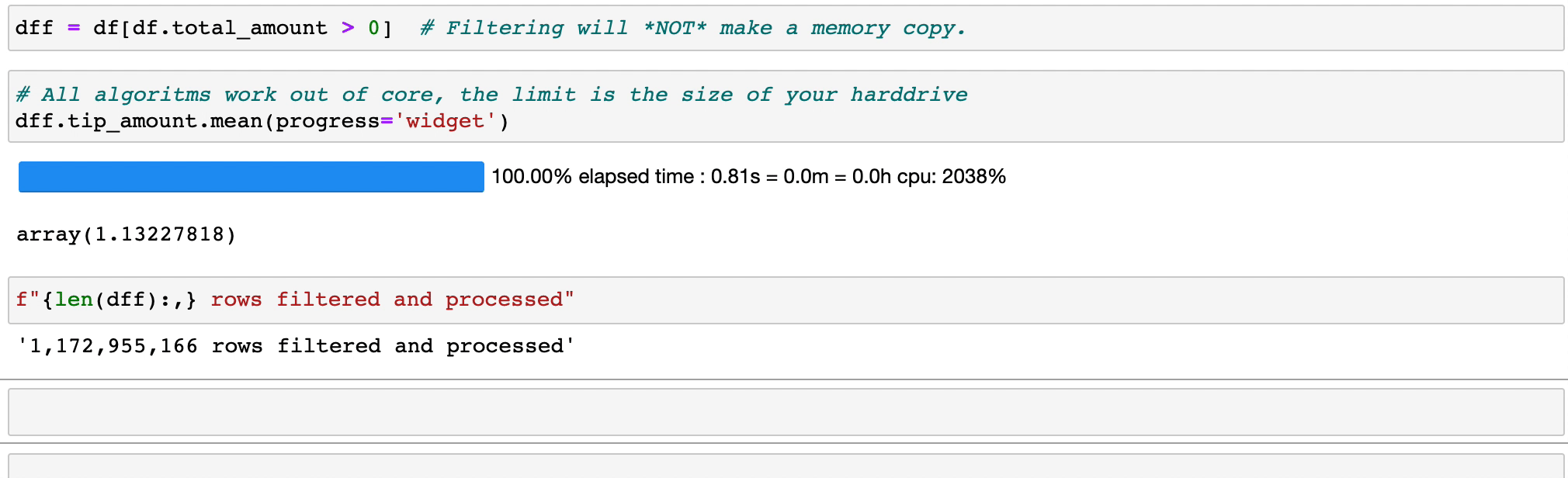
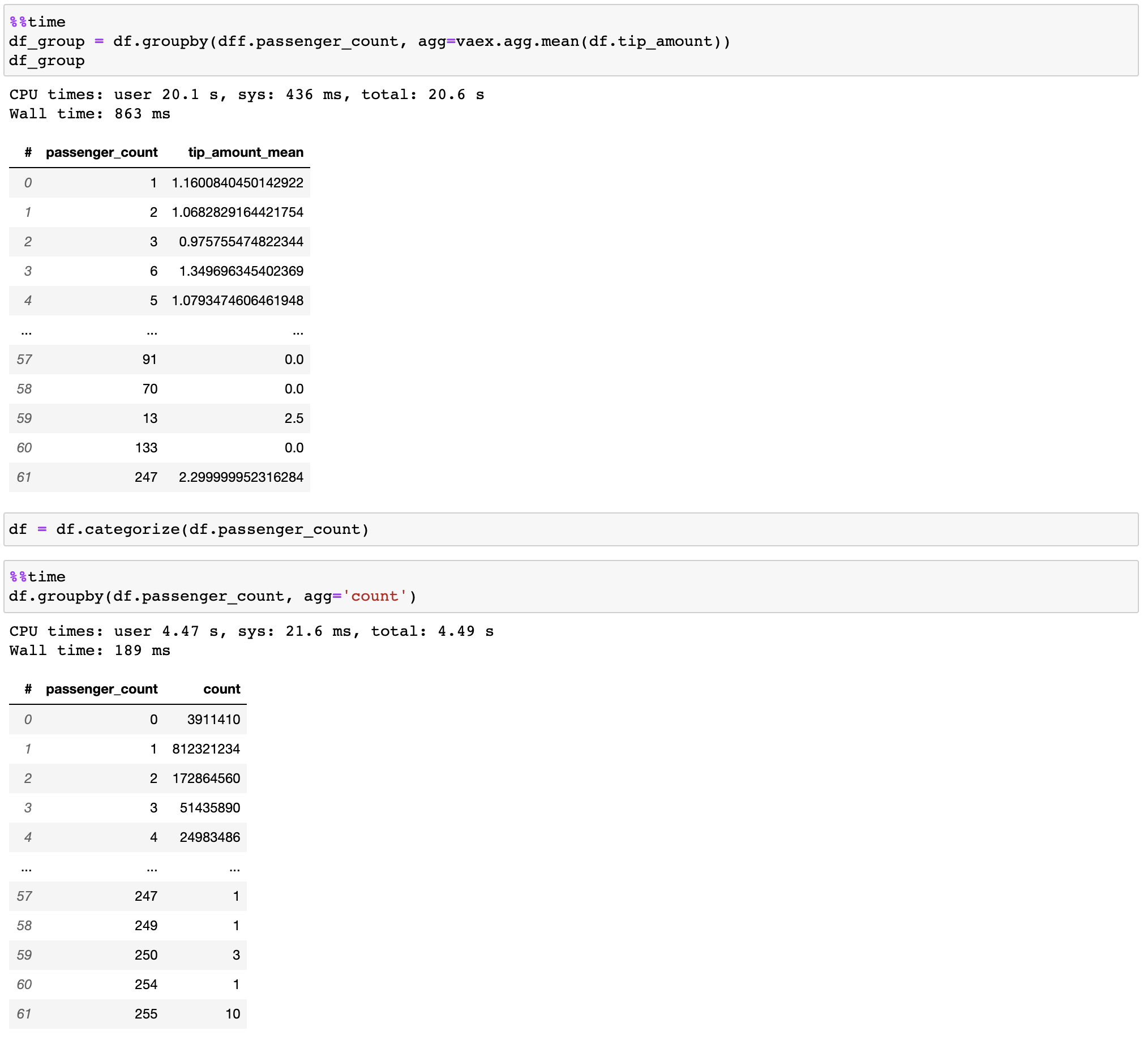
تنفذ Vaex عمليات groupby متوازية وعالية الأداء، خاصة عند استخدام الفئات (> 1 مليار/ثانية).
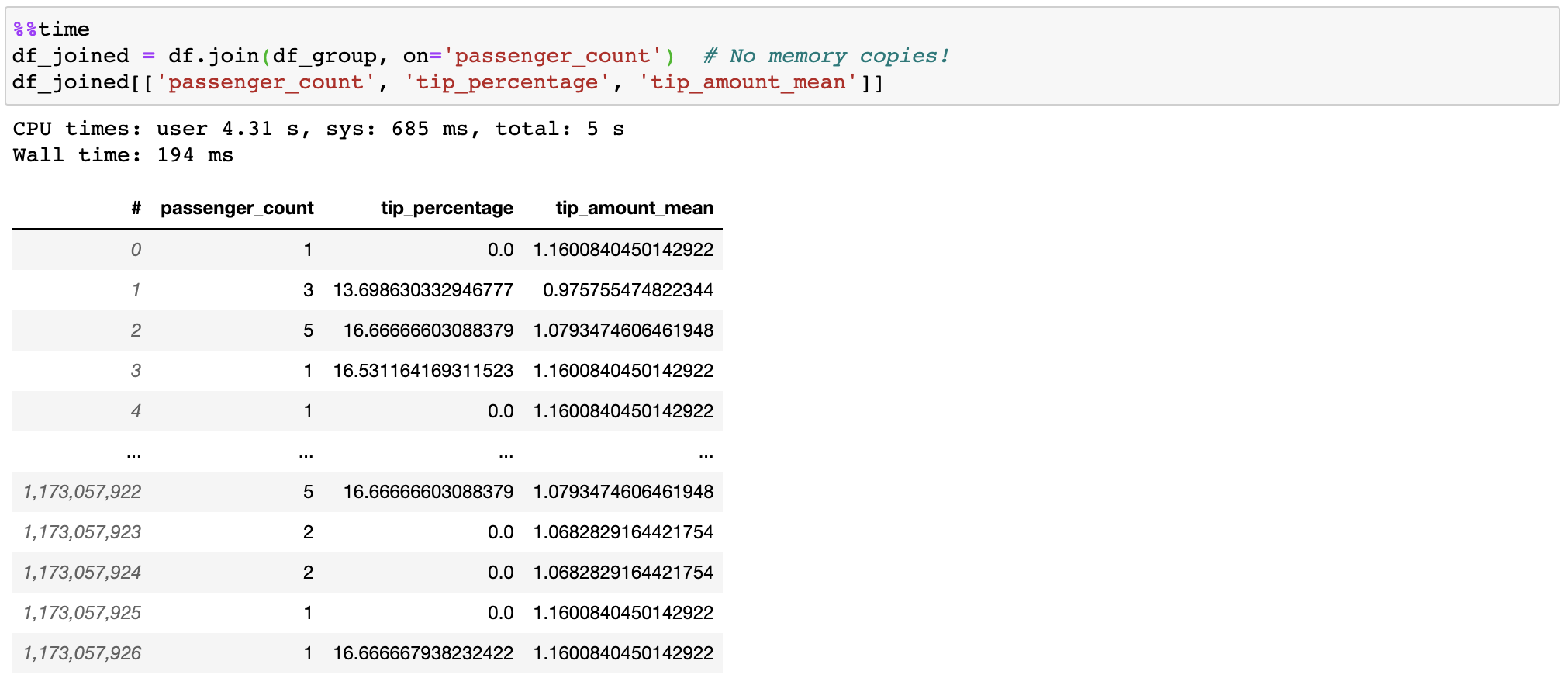
لا يقوم Vaex بنسخ/تجسيد الجدول "الصحيح" عند الانضمام، مما يوفر غيغابايت من الذاكرة. مع انضمام أقل من ثانية إلى مليار صف، يكون الأمر سريعًا جدًا!
انظر صفحة المساهمة.
انضم إلى المناقشة في قناة Slack الخاصة بنا!
مقالات
اتبع الدروس لدينا
شاهد أحدث محادثاتنا:
اتصل بنا للحصول على حلول علوم البيانات أو التدريب أو دعم المؤسسات على https://vaex.io/


