3DDFA
1.0.0
بواسطة جيانزو قوه.

[تحديثات]
2022.5.14 : التوصية بتطبيق لغة بايثون لتحديد ملامح الوجه:face_pose_augmentation.2020.8.30 : تم نشر النموذج والكود المدربين مسبقًا لـ ECCV-20 على 3DDFA_V2، وتم شرح حقوق الطبع والنشر بواسطة Jianzhu Guo ومجموعة CBSR.2020.8.2 : تحديث منفذ c++ بسيط لهذا المشروع.2020.7.3 : تم قبول العمل الممتد نحو محاذاة وجه كثيفة ثلاثية الأبعاد سريعة ودقيقة ومستقرة من قبل ECCV 2020. راجع صفحتي لمزيد من التفاصيل.2019.9.15 : بعض التحديثات، راجع الالتزامات للحصول على التفاصيل.2019.6.17 : إضافة عرض فيديو ساهم به zjjMaiMai.2019.5.2 : تقييم سرعة الاستدلال على وحدة المعالجة المركزية باستخدام PyTorch v1.1.0، انظر هنا وspeed_cpu.py.2019.4.27 : مسار عرض بسيط يعمل بسرعة ~25 مللي ثانية/إطار (720 بكسل)، راجع render.py لمزيد من التفاصيل.2019.4.24 : توفير المبنى التجريبي لأوباما، راجع demo@obama/readme.md لمزيد من التفاصيل.2019.3.28 : بعض التحديثات.2018.12.23 : إضافة العديد من الميزات: تقدير عمق الصورة، PNCC، ميزة PAF وتسلسل obj. راجع خيارات dump_depth و dump_pncc و dump_paf و dump_obj لمزيد من التفاصيل.2018.12.2 : دعم اقتصاص الوجه بدون معالم، راجع خيار dlib_landmark .2018.12.1 : قم بتحسين الكود وإضافة ميزة تقدير الوضعية، راجع utils/estimate_pose.py لمزيد من التفاصيل.2018.11.17 : قم بتحسين الكود ورسم خريطة ثلاثية الأبعاد لمساحة الصورة الأصلية.2018.11.11 : تحديث خط الاستدلال الشامل: استنتاج/تسلسل شكل الوجه ثلاثي الأبعاد و68 معلمًا مع إعطاء صورة عشوائية واحدة، يرجى الاطلاع على readme.md أدناه للحصول على مزيد من التفاصيل.2018.10.4 : إضافة العرض التوضيحي لعرض شبكة الوجه Matlab في التصور.2018.9.9 : إضافة عملية مسبقة لقص الوجه في المعيار.[المهام]
يحتوي هذا الريبو على نسخة محسنة من الورقة: محاذاة الوجه في نطاق الوضع الكامل: حل إجمالي ثلاثي الأبعاد. تتم إضافة العديد من الأعمال خارج الورقة الأصلية، بما في ذلك التدريب في الوقت الحقيقي، واستراتيجيات التدريب. ولذلك، فإن هذا الريبو هو نسخة محسنة من العمل الأصلي. حتى الآن، يطلق هذا الريبو نماذج pytorch للمرحلة الأولى المدربة مسبقًا لبنية MobileNet-V1، ومجموعة بيانات التدريب والاختبار المعالجة مسبقًا وقاعدة التعليمات البرمجية. لاحظ أن وقت الاستدلال يبلغ حوالي 0.27 مللي ثانية لكل صورة (دفعة إدخال تحتوي على 128 صورة كدفعة إدخال) على GeForce GTX TITAN X.
سيستمر تحديث هذا الريبو في وقت فراغي، ويتم الترحيب بأية مشكلات ذات معنى أو علاقات عامة.
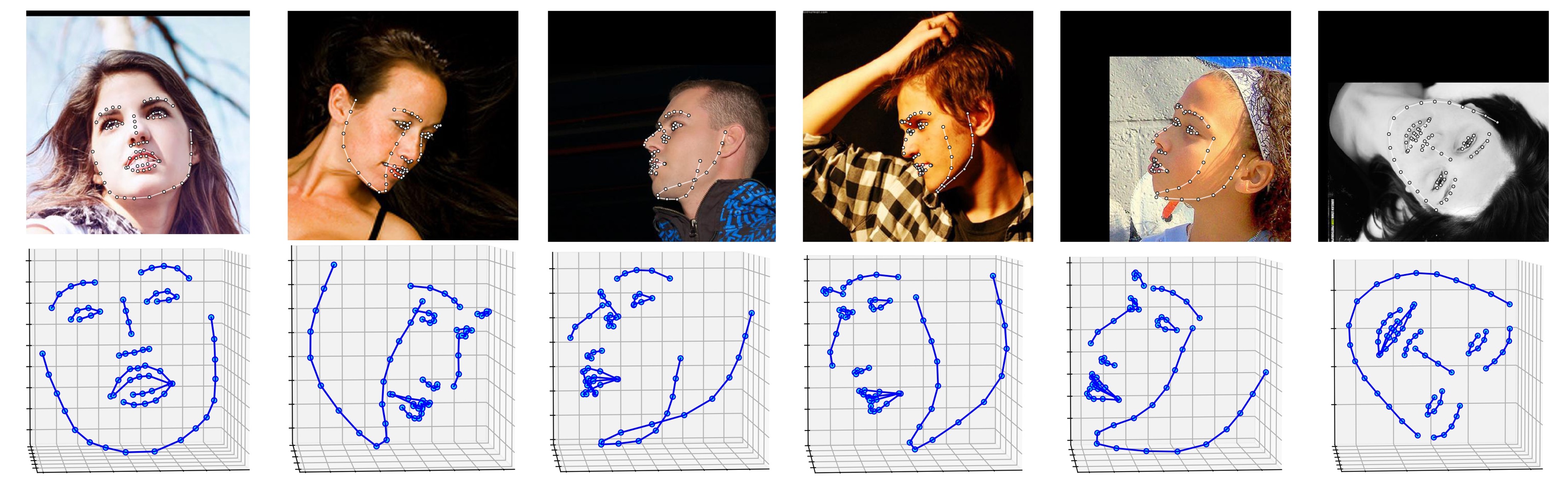
تظهر أدناه العديد من النتائج حول مجموعة بيانات ALFW-2000 (المستنتجة من النموذج phase1_wpdc_vdc.pth.tar ).





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
بالإضافة إلى ذلك، أوصي بشدة باستخدام Python3.6+ بدلاً من الإصدار الأقدم لتصميمه الأفضل.
استنساخ هذا الريبو (قد يستغرق هذا بعض الوقت لأنه كبير بعض الشيء)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
بعد ذلك، قم بتنزيل نموذج dlib معلمًا مُدرب مسبقًا في Google Drive أو Baidu Yun، ثم ضعه في دليل models . (لتقليل حجم الريبو هذا، قمت بإزالة بعض الملفات الثنائية كبيرة الحجم بما في ذلك هذا النموذج، لذا يجب عليك تنزيله :))
بناء وحدة cython (سطر واحد فقط للبناء)
cd utils/cython
python3 setup.py build_ext -i
هذا لتسريع تقدير العمق وعرض PNCC نظرًا لأن Python بطيء جدًا في الحلقة.
قم بتشغيل main.py باستخدام صورة عشوائية كمدخل
python3 main.py -f samples/test1.jpg
إذا كان بإمكانك رؤية سجل الإخراج هذا في الوحدة الطرفية، فهذا يعني أنك تقوم بتشغيله بنجاح.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
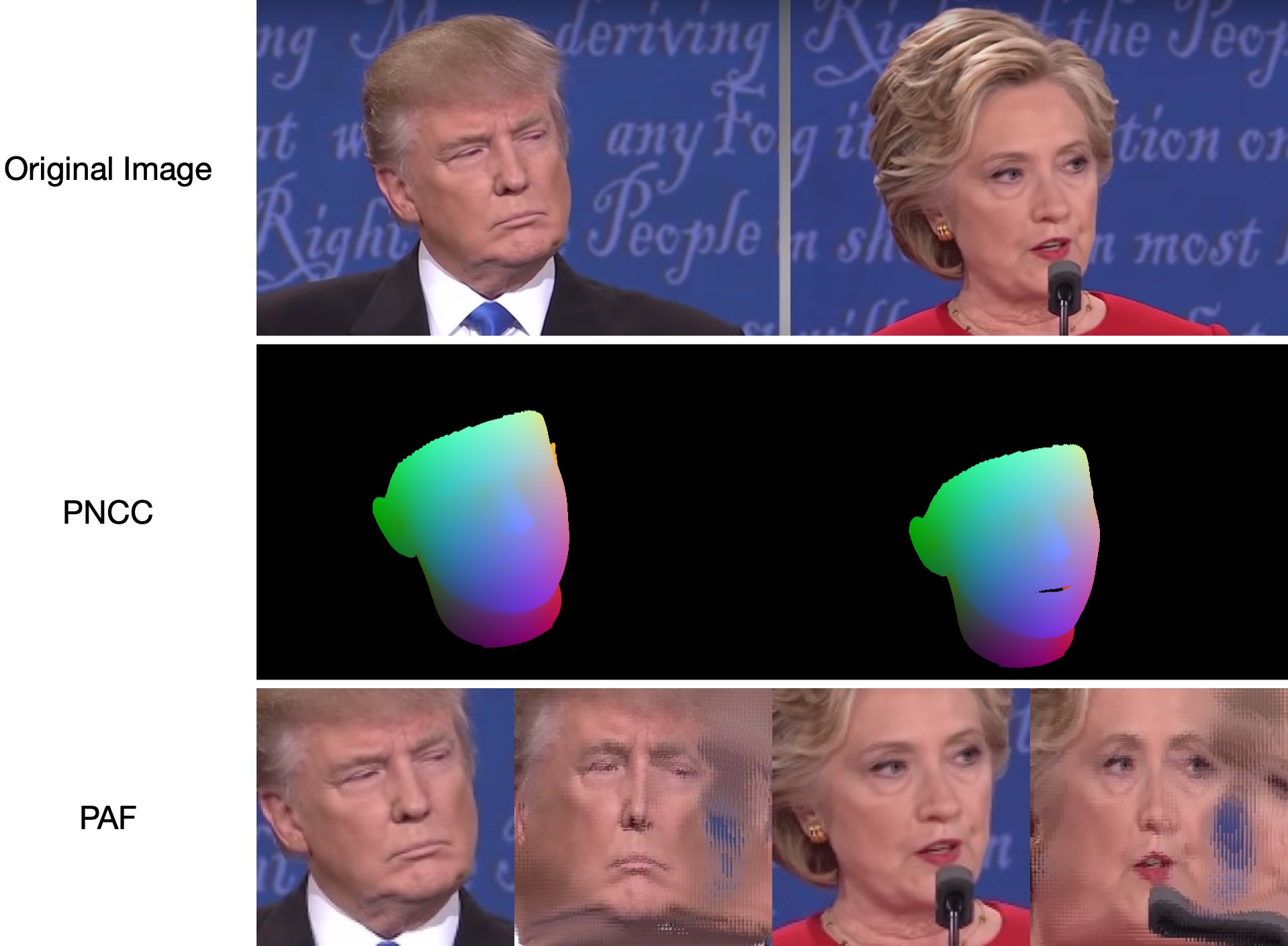
نظرًا لأن test1.jpg له وجهان، فهناك ملفان .ply و .obj (يمكن عرضهما بواسطة Meshlab أو Microsoft 3D Builder). يتم ضبط كل من العمق وPNCC وPAF وتقدير الوضع على أنه صحيح بشكل افتراضي. يرجى تشغيل python3 main.py -h أو مراجعة الكود لمزيد من التفاصيل.
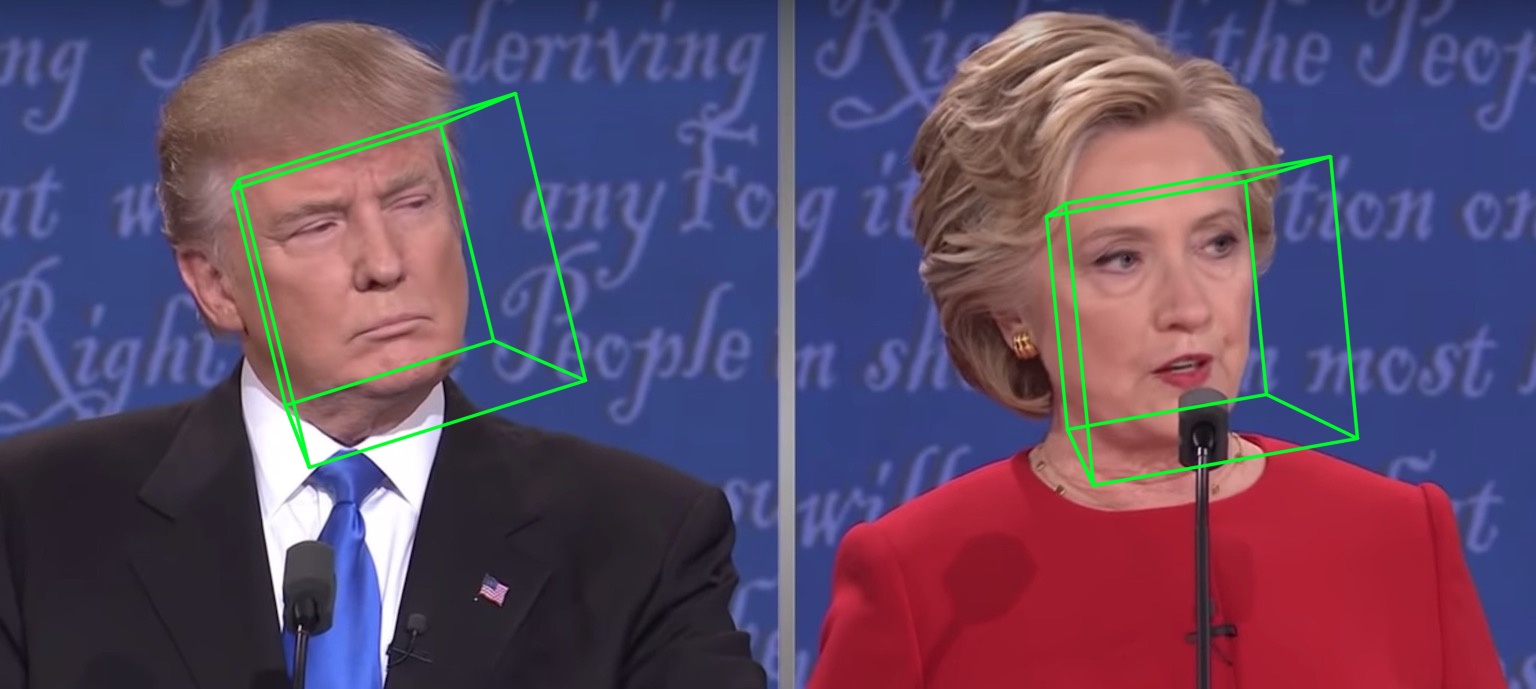
تظهر أدناه samples/test1_3DDFA.jpg samples/test1_pose.jpg :

مثال إضافي
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
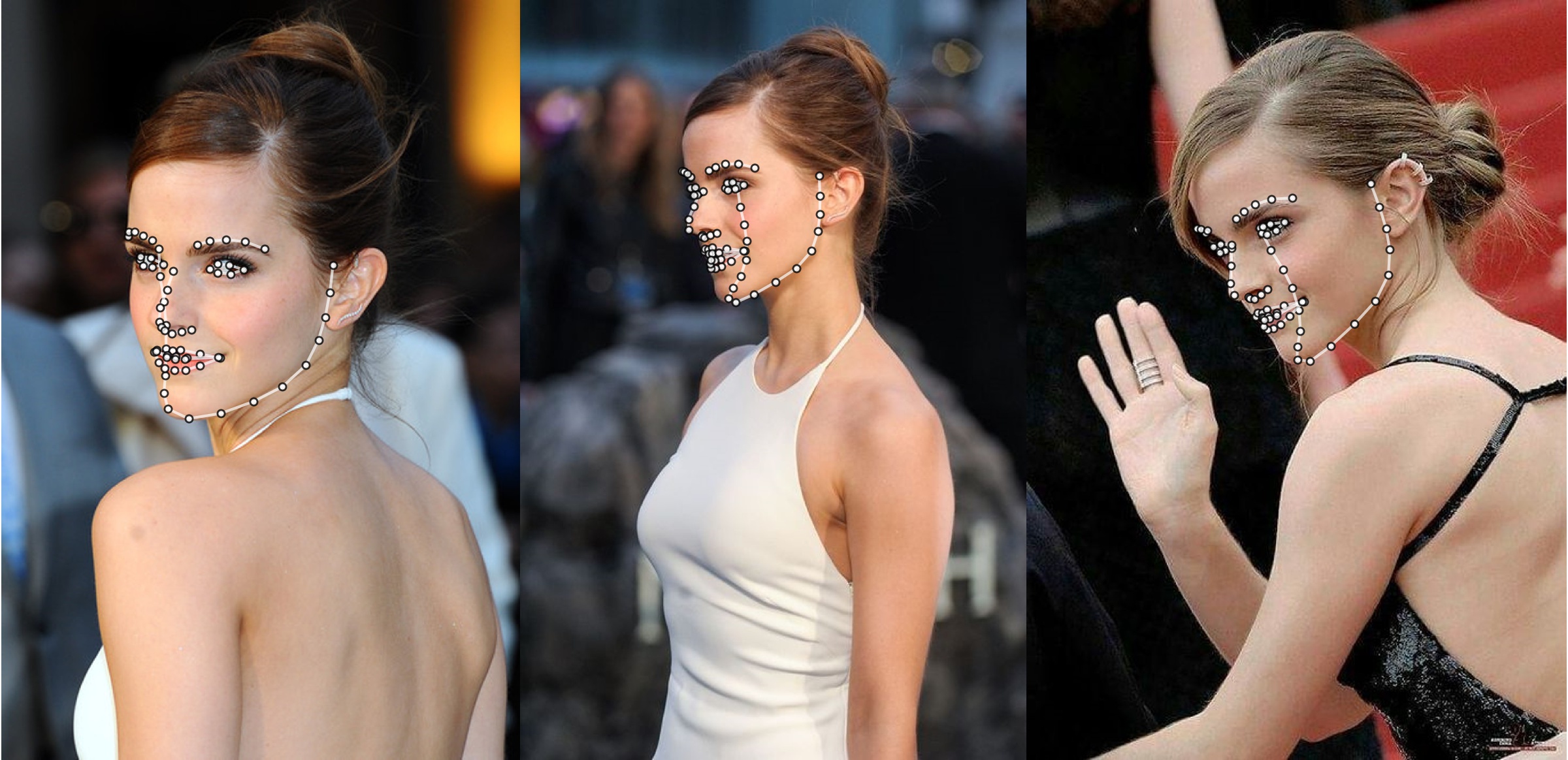
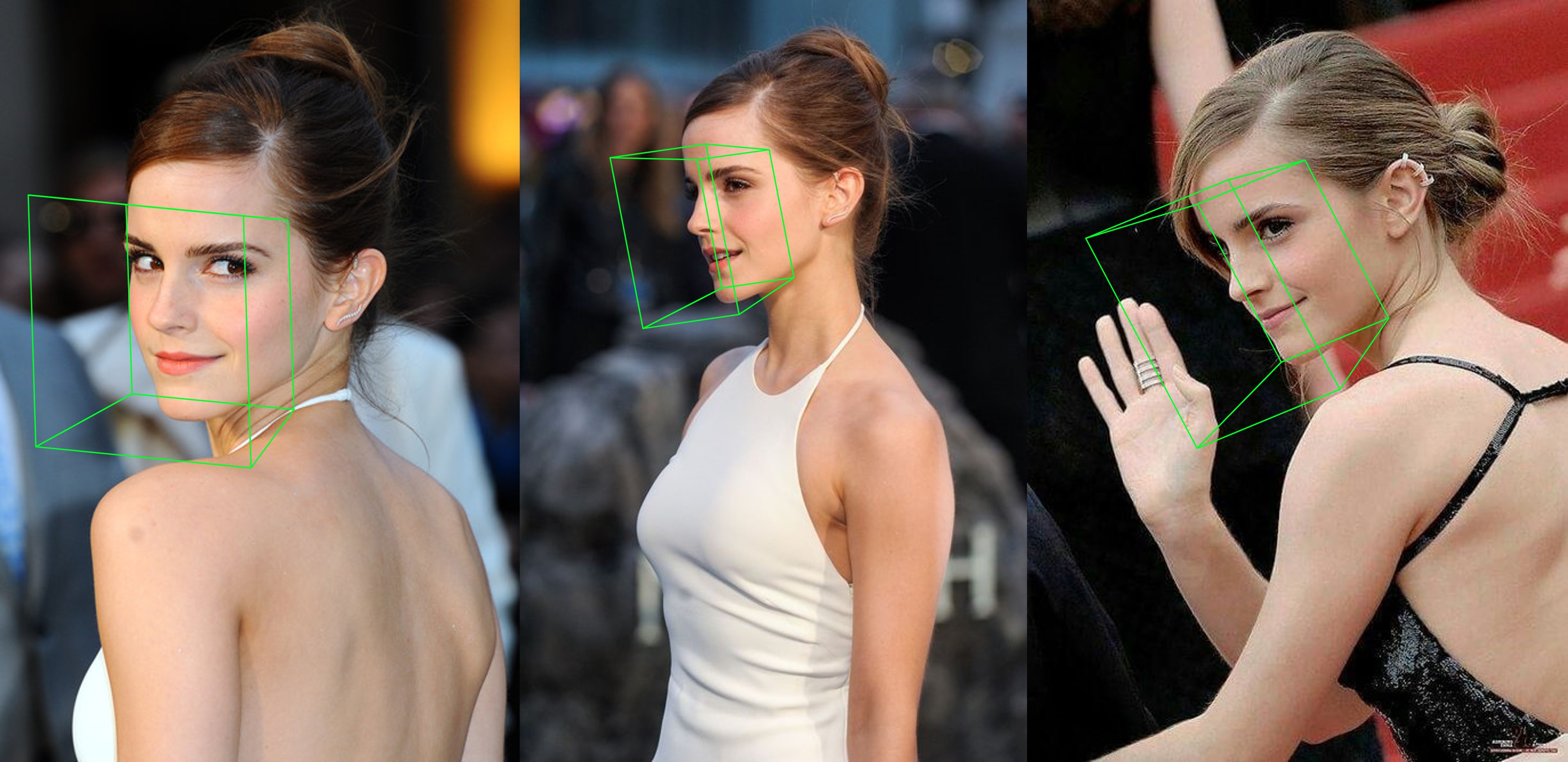
فقط اركض
python3 speed_cpu.py
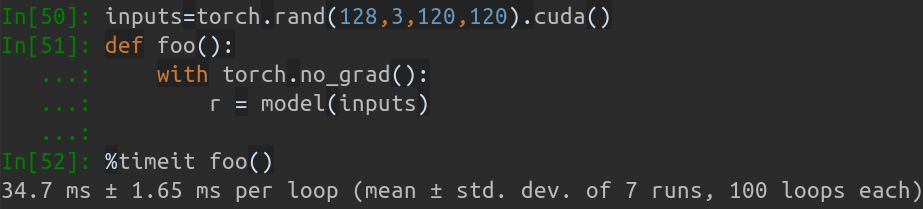
على جهاز MBP الخاص بي (وحدة المعالجة المركزية i5-8259U بسرعة 2.30 جيجا هرتز على جهاز MacBook Pro مقاس 13 بوصة)، استنادًا إلى PyTorch v1.1.0 ، مع إدخال واحد، يكون الإخراج قيد التشغيل هو:
Inference speed: 14.50±0.11 ms
عندما يكون حجم دفعة الإدخال 128، فإن إجمالي وقت الاستدلال لـ MobileNet-V1 يستغرق حوالي 34.7 مللي ثانية. متوسط السرعة حوالي 0.27 مللي ثانية/صورة .
نصوص التدريب تكمن في دليل training . الموارد ذات الصلة موجودة في الجدول أدناه.
| بيانات | رابط التحميل | وصف |
|---|---|---|
| Train.configs | بايدويون أو جوجل درايف، 217 ميجا | الدليل الذي يحتوي على معلمات 3DMM وقوائم الملفات الخاصة بمجموعة بيانات التدريب |
| Train_aug_120x120.zip | بايدويون أو جوجل درايف، 2.15 جيجا | الصور التي تم اقتصاصها من مجموعة بيانات التدريب المعزز |
| test.data.zip | بايدويون أو جوجل درايف، 151 ميجا | الصور المقطوعة لمجموعة اختبارات AFLW وALFW-2000-3D |
بعد إعداد مجموعة بيانات التدريب وملفات التكوين، انتقل إلى دليل training وقم بتشغيل البرامج النصية bash للتدريب. تعتبر train_wpdc.sh و train_vdc.sh و train_pdc.sh أمثلة على البرامج النصية للتدريب. بعد تكوين مجموعات التدريب والاختبار، ما عليك سوى تشغيلها للتدريب. خذ train_wpdc.sh على سبيل المثال على النحو التالي:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
يتم تقديم جميع معلمات التدريب المحددة في نصوص bash، بما في ذلك معدل التعلم وحجم الدفعة الصغيرة والعصور وما إلى ذلك.
أولاً، يجب عليك تنزيل مجموعة الاختبارات المقصوصة ALFW وALFW-2000-3D في test.data.zip، ثم فك ضغطها ووضعها في الدليل الجذر. بعد ذلك، قم بتشغيل التعليمات البرمجية المعيارية من خلال توفير مسار نموذج مدرب. لقد قمت بالفعل بتقديم خمسة نماذج مدربة مسبقًا في دليل models (كما هو موضح في الجدول أدناه). يتم تدريب هذه النماذج باستخدام خسارة مختلفة في المرحلة الأولى. يبلغ حجم النموذج حوالي 13 مليونًا نظرًا للكفاءة العالية لهيكل MobileNet-V1.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
يتم عرض أداء النماذج المدربة مسبقًا أدناه. في المرحلة الأولى، تكون فعالية الخسارة المختلفة بالترتيب: WPDC > VDC > PDC. بينما تحقق الإستراتيجية التي تستخدم VDC لضبط WPDC أفضل نتيجة.
| نموذج | اتحاد كرة القدم الأمريكية (21 نقطة) | AFLW 2000-3D (68 نقطة) | رابط التحميل |
|---|---|---|---|
| phase1_pdc.pth.tar | 6.956 ± 0.981 | 5.644 ± 1.323 | بايدو يون أو جوجل درايف |
| phase1_vdc.pth.tar | 6.717 ± 0.924 | 5.030 ± 1.044 | بايدو يون أو جوجل درايف |
| phase1_wpdc.pth.tar | 6.348 ± 0.929 | 4.759 ± 0.996 | بايدو يون أو جوجل درايف |
| phase1_wpdc_vdc.pth.tar | 5.401 ± 0.754 | 4.252 ± 0.976 | في هذا الريبو. |
صدقني أن إطار عمل هذا الريبو يمكن أن يحقق أداء أفضل من PRNet دون زيادة أي ميزانية حسابية. العمل ذو الصلة قيد المراجعة وسيتم إصدار الكود عند القبول.
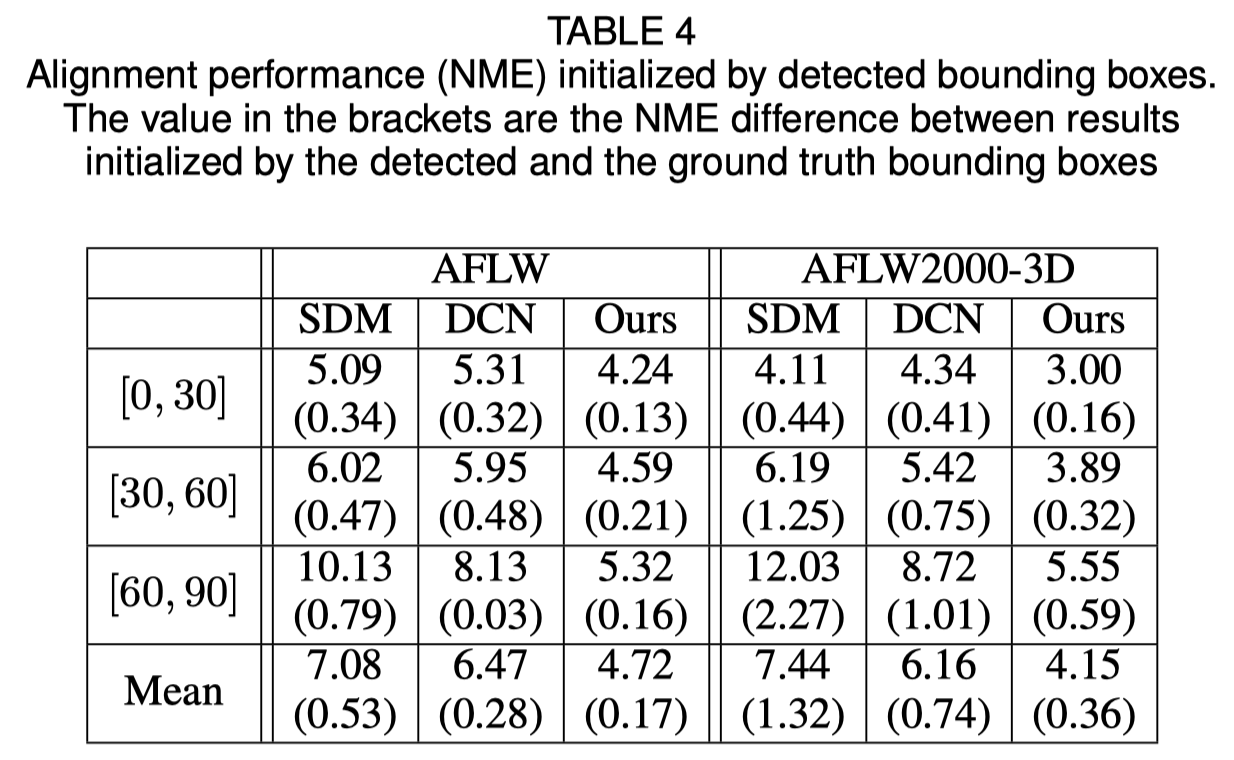
تهيئة المربع المحيط بالوجه
توضح الورقة الأصلية أن استخدام المربع المحيط المكتشف بدلاً من مربع الحقيقة الأرضي سيؤدي إلى انخفاض بسيط في الأداء. وبالتالي فإن طريقة قص الوجه الحالية هي الأقوى. وتظهر النتائج الكمية في الجدول أدناه.
إعادة بناء الوجه
يتم تشويه نسيج المنطقة غير المرئية بسبب الانغلاق الذاتي، وبالتالي قد تبدو منطقة الوجه غير المرئية غريبة (فظيعة بعض الشيء).
حول قص معلمات الشكل والتعبير
يؤدي قص المعلمات إلى تسريع عملية التدريب وإعادة البناء، ولكنه يقلل من الدقة وخاصة التفاصيل مثل إغلاق العيون. يوجد أدناه صورة بأبعاد المعلمات 40+10 و60+29 و199+29 (الصورة الأصلية). بالمقارنة بالشكل، فإن قص التعبير له تأثير أكبر على دقة إعادة البناء عندما يتعلق الأمر بالعاطفة. ولذلك، يمكنك اختيار المفاضلة بين السرعة/حجم المعلمة والدقة. توصية مقايضة القطع هي 60+29.

شكرا لاهتمامك في هذا الريبو. إذا كان عملك أو بحثك يستفيد من هذا الريبو، قم بتمييزه بنجمة؟
مرحبًا بكم في التركيز على أعمالي المتعلقة بالوجه ثلاثي الأبعاد: MeGlass وFace Anti-Spoofing.
إذا كان عملك يستفيد من هذا الريبو، يرجى ذكر ثلاث مراويل أدناه.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [الصفحة الرئيسية، الباحث العلمي من Google]: [email protected] أو [email protected] .


