Hibernate SpringBoot
1.0.0
| إذا كنت بحاجة إلى التعمق في وصفات الأداء المعروضة في هذا المستودع، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات التمهيد الربيعي" | إذا كنت بحاجة إلى مجموعة من النصائح والرسوم التوضيحية لأكثر من 100 مشكلة في أداء استمرارية Java، فإن "الدليل المصور لأداء استمرارية Java" هو ما يناسبك. |
|
|
عينات التمهيد السبات والربيع
الوصف: هذا التطبيق عبارة عن نموذج لكيفية تخزين التاريخ والوقت والطوابع الزمنية بالمنطقة الزمنية UTC. الإعداد الثاني، useLegacyDatetimeCode مطلوب فقط لـ MySQL. بخلاف ذلك، قم بتعيين hibernate.jdbc.time_zone فقط.
النقاط الرئيسية:
spring.jpa.properties.hibernate.jdbc.time_zone=UTCspring.datasource.url=jdbc:mysql://localhost:3306/screenshotdb?useLegacyDatetimeCode=falseالوصف: عرض المعلمات الملزمة/المستخرجة للبيان المُعد عبر إعداد المسجل Log4J 2.
النقاط الرئيسية:
pom.xml ، استبعد التسجيل الافتراضي لـ Spring Bootpom.xml ، أضف تبعية Log4j 2log4j2.xml أضف، <Logger name="org.hibernate.type.descriptor.sql" level="trace"/> مثال الإخراج: 
الوصف: عرض تفاصيل الاستعلام (نوع الاستعلام، معلمات الربط، حجم الدفعة، وقت التنفيذ، إلخ) عبر DataSource-Proxy
النقاط الرئيسية:
pom.xml تبعية datasource-proxyDataSourceDataSource عبر ProxyFactory وتنفيذ MethodInterceptor مثال الإخراج: 
saveAll(Iterable<S> entities) في MySQL الوصف: إدراج الدفعة عبر طريقة SimpleJpaRepository#saveAll(Iterable<S> entities) في MySQL
النقاط الرئيسية:
application.properties مجموعة spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties قم بتعيين spring.jpa.properties.hibernate.generate_statistics (فقط للتأكد من أن التجميع يعمل)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام rewriteBatchedStatements=true (التحسين لـ MySQL)application.properties قم بتعيين عنوان URL لـ JDBC مع cachePrepStmts=true (تمكين التخزين المؤقت ويكون مفيدًا إذا قررت تعيين prepStmtCacheSize و prepStmtCacheSqlLimit وما إلى ذلك أيضًا؛ بدون هذا الإعداد، يتم تعطيل ذاكرة التخزين المؤقت)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام useServerPrepStmts=true (بهذه الطريقة يمكنك التبديل إلى البيانات المعدة من جانب الخادم (قد تؤدي إلى زيادة كبيرة في الأداء))spring.jpa.properties.hibernate.order_inserts=true لتحسين التجميع عن طريق طلب الإدخالاتIDENTITY سيؤدي إلى تعطيل تجميع الإدخال@Version لتجنب إطلاق عبارات SELECT الإضافية قبل التجميع (يمنع أيضًا فقدان التحديثات في المعاملات متعددة الطلبات). عبارات SELECT الإضافية هي نتيجة استخدام merge() بدلاً من persist() ; خلف الكواليس، يستخدم saveAll() save() ، والذي في حالة الكيانات غير الجديدة (الكيانات التي لها معرفات) سوف يستدعي merge() ، والذي يوجه Hibernate لإطلاق عبارة SELECT للتأكد من عدم وجود سجل في قاعدة بيانات لها نفس المعرفsaveAll() حتى لا "تطغى" على سياق الثبات؛ عادةً يجب مسح EntityManager ومسحه من وقت لآخر، ولكن أثناء تنفيذ saveAll() لا يمكنك ببساطة القيام بذلك، لذا إذا كانت هناك قائمة تحتوي على كمية كبيرة من البيانات في saveAll() ، فستصل كل هذه البيانات إلى زر الثبات السياق (ذاكرة التخزين المؤقت للمستوى الأول) وسيبقى في الذاكرة حتى وقت التدفق؛ يجب أن يكون استخدام كمية صغيرة نسبيًا من البيانات أمرًا جيدًا (في هذا المثال، يتم تشغيل كل دفعة مكونة من 30 كيانًا في معاملة منفصلة وسياق ثابت)saveAll() بإرجاع List<S> تحتوي على الكيانات المستمرة؛ تتم إضافة كل كيان مستمر إلى هذه القائمة؛ إذا كنت لا تحتاج إلى هذه List ، فسيتم إنشاؤها من أجل لا شيءspring.jpa.properties.hibernate.cache.use_second_level_cache=false الوصف: هذا التطبيق عبارة عن عينة من الإدخالات المجمعة عبر EntityManager في MySQL. بهذه الطريقة يمكنك بسهولة التحكم في دورات flush() و clear() لسياق الثبات (ذاكرة التخزين المؤقت للمستوى الأول) داخل المعاملة الحالية. هذا غير ممكن عبر Spring Boot، saveAll(Iterable<S> entities) ، نظرًا لأن هذه الطريقة تنفذ تدفقًا واحدًا لكل معاملة. ميزة أخرى هي أنه يمكنك الاتصال بـ persist() بدلاً من merge() - يتم استخدام هذا خلف الكواليس بواسطة SpringBoot saveAll(Iterable<S> entities) و save(S entity) .
إذا كنت تريد تنفيذ دفعة لكل معاملة (مستحسن)، فتحقق من هذا المثال.
النقاط الرئيسية:
application.properties مجموعة spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties قم بتعيين spring.jpa.properties.hibernate.generate_statistics (فقط للتأكد من أن التجميع يعمل)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام rewriteBatchedStatements=true (التحسين لـ MySQL)application.properties قم بتعيين عنوان URL لـ JDBC مع cachePrepStmts=true (تمكين التخزين المؤقت ويكون مفيدًا إذا قررت تعيين prepStmtCacheSize و prepStmtCacheSqlLimit وما إلى ذلك أيضًا؛ بدون هذا الإعداد، يتم تعطيل ذاكرة التخزين المؤقت)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام useServerPrepStmts=true (بهذه الطريقة يمكنك التبديل إلى البيانات المعدة من جانب الخادم (قد تؤدي إلى تعزيز كبير للأداء))spring.jpa.properties.hibernate.order_inserts=true لتحسين التجميع عن طريق طلب الإدخالاتIDENTITY سيؤدي إلى تعطيل تجميع الإدخالspring.jpa.properties.hibernate.cache.use_second_level_cache=false مثال الإخراج: 
الوصف: إدراج دفعة عبر JpaContext/EntityManager في MySQL.
النقاط الرئيسية:
application.properties spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties قم بتعيين spring.jpa.properties.hibernate.generate_statistics (فقط للتأكد من أن التجميع يعمل)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام rewriteBatchedStatements=true (التحسين لـ MySQL)application.properties قم بتعيين عنوان URL لـ JDBC مع cachePrepStmts=true (تمكين التخزين المؤقت ويكون مفيدًا إذا قررت تعيين prepStmtCacheSize و prepStmtCacheSqlLimit وما إلى ذلك أيضًا؛ بدون هذا الإعداد، يتم تعطيل ذاكرة التخزين المؤقت)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام useServerPrepStmts=true (بهذه الطريقة يمكنك التبديل إلى البيانات المعدة من جانب الخادم (قد تؤدي إلى تعزيز كبير للأداء))spring.jpa.properties.hibernate.order_inserts=true لتحسين التجميع عن طريق طلب الإدخالاتIDENTITY سيؤدي إلى تعطيل تجميع الإدخالEntityManager لكل نوع كيان عبر JpaContext#getEntityManagerByManagedType(Class<?> entity)spring.jpa.properties.hibernate.cache.use_second_level_cache=false مثال الإخراج: 
الوصف: يتم إدراج الدُفعات من خلال التجميع على مستوى جلسة الإسبات (الإسبات 5.2 أو أعلى) في MySQL.
النقاط الرئيسية:
application.properties قم بتعيين spring.jpa.properties.hibernate.generate_statistics (فقط للتأكد من أن التجميع يعمل)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام rewriteBatchedStatements=true (التحسين لـ MySQL)application.properties قم بتعيين عنوان URL لـ JDBC مع cachePrepStmts=true (تمكين التخزين المؤقت ويكون مفيدًا إذا قررت تعيين prepStmtCacheSize و prepStmtCacheSqlLimit وما إلى ذلك أيضًا؛ بدون هذا الإعداد، يتم تعطيل ذاكرة التخزين المؤقت)application.properties قم بتعيين عنوان URL لـ JDBC باستخدام useServerPrepStmts=true (بهذه الطريقة يمكنك التبديل إلى البيانات المعدة من جانب الخادم (قد تؤدي إلى تعزيز كبير للأداء))spring.jpa.properties.hibernate.order_inserts=true لتحسين التجميع عن طريق طلب الإدخالاتIDENTITY سيؤدي إلى تعطيل تجميع الإدخالSession السبات عن طريق إلغاء تغليفها عبر EntityManager#unwrap(Session.class)Session#setJdbcBatchSize(Integer size) والحصول عليه عبر Session#getJdbcBatchSize()spring.jpa.properties.hibernate.cache.use_second_level_cache=false مثال الإخراج: 
findById() وJPA EntityManager Session السبات الوصف: الجلب المباشر عبر أمثلة Spring Data و EntityManager وHbernate Session .
النقاط الرئيسية:
findById()EntityManager يستخدم find()Session السبات يستخدم get()ملاحظة: قد ترغب أيضًا في قراءة الوصفة، "كيفية إثراء DTOs بالخصائص الافتراضية عبر إسقاطات الربيع"
الوصف: جلب البيانات المطلوبة فقط من قاعدة البيانات عبر Spring Data Projections (DTO).
النقاط الرئيسية:
List<projection>LIMIT )ملاحظة: لا يقتصر استخدام الإسقاطات على استخدام آلية إنشاء الاستعلامات المضمنة في البنية الأساسية لمستودع بيانات Spring. يمكننا جلب التوقعات عبر JPQL أو الاستعلامات الأصلية أيضًا. على سبيل المثال، في هذا التطبيق نستخدم ملف JPQL.
مثال على الإخراج (حدد أول صفين، وحدد فقط "الاسم" و"العمر"): 
| إذا كنت بحاجة إلى التعمق في وصفات الأداء المعروضة في هذا المستودع، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات التمهيد الربيعي" | إذا كنت بحاجة إلى مجموعة من النصائح والرسوم التوضيحية لأكثر من 100 مشكلة في أداء استمرارية Java، فإن "الدليل المصور لأداء استمرارية Java" هو ما يناسبك. |
|
|
الوصف: بشكل افتراضي، يتم تحميل سمات الكيان بفارغ الصبر (مرة واحدة). لكن يمكننا تحميلهم كسولًا أيضًا. يعد هذا مفيدًا لأنواع الأعمدة التي تخزن كميات كبيرة من البيانات: CLOB أو BLOB أو VARBINARY وما إلى ذلك أو التفاصيل التي يجب تحميلها عند الطلب. في هذا التطبيق، لدينا كيان اسمه Author . خصائصه هي: id ، name ، genre ، avatar age . ونحن نريد تحميل avatar كسول. لذلك، يجب تحميل avatar عند الطلب.
النقاط الرئيسية:
pom.xml ، قم بتنشيط تحسين رمز بايت Hibernate (على سبيل المثال، استخدم البرنامج المساعد لتحسين رمز Maven بايت كود )@Basic(fetch = FetchType.LAZY)application.properties ، قم بتعطيل فتح الجلسة في العرض تحقق كذلك:
- القيم الافتراضية للسمات المحملة البطيئة
- سمة التحميل البطيء وتسلسل جاكسون
الوصف: يمكن أن يكون وكيل السبات مفيدًا عندما يمكن استمرار كيان فرعي بمرجع إلى أصله (ارتباط @ManyToOne أو @OneToOne ). في مثل هذه الحالات، يعد جلب الكيان الأصلي من قاعدة البيانات (تنفيذ عبارة SELECT ) بمثابة عقوبة أداء وإجراء لا معنى له، لأن السبات يمكنه تعيين قيمة المفتاح الخارجي الأساسي لوكيل غير مهيأ.
النقاط الرئيسية:
EntityManager#getReference()JpaRepository#getOne() -> المستخدم في هذا المثالload()Author Book ، متورطين في اقتران @ManyToOne أحادي الاتجاه ( Author هو الجانب الأصلي)SELECT )، وننشئ كتابًا جديدًا، ونقوم بتعيين الوكيل كمؤلف لهذا الكتاب ونحفظ الكتاب (سيؤدي هذا إلى تشغيل INSERT في جدول book )مثال الإخراج:
INSERT فقط، ولم يتم SELECTالوصف: إن N+1 هي مشكلة جلب بطيء (لكن الرغبة ليست مستثناة). يقوم هذا التطبيق بإعادة إنتاج سلوك N+1.
النقاط الرئيسية:
Author Book في ارتباط @OneToMany كسول ثنائي الاتجاهBook كسول، لذا بدون Author (ينتج عنه استعلام واحد)Book التي تم جلبها ولكل إدخال جلب Author المقابل (النتائج N استعلامات)Author كسولًا، لذلك بدون Book (ينتج عنه استعلام واحد)Author التي تم جلبها ولكل إدخال جلب Book المقابل (النتائج N استعلامات) مثال الإخراج: 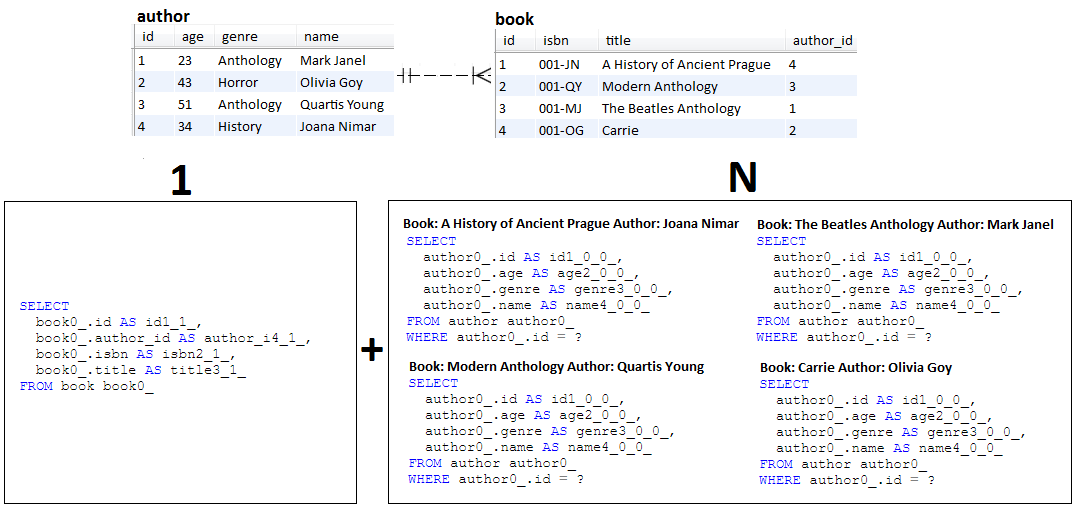
SELECT DISTINCT عبر تلميح السبات HINT_PASS_DISTINCT_THROUGH الوصف: بدءًا من Hibernate 5.2.2، يمكننا تحسين وحدات استعلام JPQL (HQL) من النوع SELECT DISTINCT عبر تلميح HINT_PASS_DISTINCT_THROUGH . ضع في اعتبارك أن هذا التلميح مفيد فقط لاستعلامات JOIN FETCH-ing JPQL (HQL). ليس مفيدًا للاستعلامات العددية (على سبيل المثال، List<Integer> )، أو DTO أو HHH-13280. في مثل هذه الحالات، يلزم تمرير الكلمة الأساسية DISTINCT JPQL إلى استعلام SQL الأساسي. سيؤدي هذا إلى توجيه قاعدة البيانات لإزالة التكرارات من مجموعة النتائج.
النقاط الرئيسية:
@QueryHints(value = @QueryHint(name = HINT_PASS_DISTINCT_THROUGH, value = "false")) مثال الإخراج: 
ملاحظة: تعد آلية Hibernate Dirty Checking مسؤولة عن تحديد تعديلات الكيانات في وقت التدفق ولتشغيل عبارات UPDATE المقابلة نيابةً عنا.
الوصف: قبل إصدار Hibernate 5، كانت آلية Dirty Checking تعتمد على Java Reflection API للتحقق من كل خاصية لكل كيان مُدار. بدءًا من الإصدار 5 من Hibernate، يمكن أن تعتمد آلية Dirty Checking على آلية Dirty Tracking (وهي قدرة الكيان على تتبع تغييرات السمات الخاصة به) والتي تتطلب وجود تحسين Hibernate Bytecode في التطبيق. تحافظ آلية التتبع القذر على أداء أفضل، خاصة عندما يكون لديك عدد كبير نسبيًا من الكيانات.
بالنسبة للتتبع القذر ، أثناء عملية تحسين Bytecode ، يتم التحكم في الكود الثانوي لفئات الكيانات بواسطة Hibernate عن طريق إضافة متتبع ، $$_hibernate_tracker . في وقت التدفق، سيستخدم Hibernate هذا المتعقب لاكتشاف تغييرات الكيانات (سيقوم كل متتبع كيان بالإبلاغ عن التغييرات). وهذا أفضل من التحقق من كل خاصية لكل كيان مُدار.
عادةً (افتراضيًا)، يتم تنفيذ الأجهزة في وقت الإنشاء، ولكن يمكن تهيئتها لتتم في وقت التشغيل أو وقت النشر أيضًا. من الأفضل أن يتم ذلك في وقت الإنشاء لتجنب الحمل الزائد في وقت التشغيل.
يمكن إضافة تحسين Bytecode وتمكين Dirty Tracking عبر مكون إضافي تمت إضافته عبر Maven أو Gradle (يمكن استخدام Ant أيضًا). نحن نستخدم Maven، لذلك نضيفه في pom.xml .
النقاط الرئيسية:
pom.xml مثال الإخراج: 
يمكن رؤية تأثير تحسين Bytecode على Author.class هنا. لاحظ كيف تم استخدام الكود الثانوي مع $$_hibernate_tracker .
Optional في الكيانات والاستعلامات الوصف: يعد هذا التطبيق مثالاً على كيفية استخدام Java 8 Optional بشكل صحيح في الكيانات والاستعلامات.
النقاط الرئيسية:
Optional (على سبيل المثال، findById() )OptionalOptional في الحروف الكياناتdata-mysql.sql@OneToMany ثنائية الاتجاه الوصف: يعد هذا التطبيق دليلاً على مفهوم كيفية تنفيذ اقتران @OneToMany ثنائي الاتجاه من منظور الأداء.
النقاط الرئيسية:
mappedBy على الأصلorphanRemoval على الأصل لإزالة الأطفال دون مراجع@NaturalId )) و/أو المعرفات التي تم إنشاؤها بواسطة قاعدة البيانات وتجاوز (على الجانب الفرعي) بشكل صحيح أساليب equals() و hashCode() كما هناtoString() ، فعليك الانتباه إلى تضمين السمات الأساسية التي يتم جلبها فقط عند تحميل الكيان من قاعدة البيانات ملاحظة: انتبه إلى إزالة العمليات، وخاصةً إزالة الكيانات الفرعية. قد ينتج عن CascadeType.REMOVE و orphanRemoval=true عدد كبير جدًا من الاستعلامات. في مثل هذه السيناريوهات، يعد الاعتماد على العمليات المجمعة في أغلب الأحيان أفضل طريقة لإجراء عمليات الحذف.
الوصف: هذا التطبيق هو مثال لكيفية كتابة استعلام عبر JpaRepository و EntityManager و Session .
النقاط الرئيسية:
JpaRepository استخدم @Query أو إنشاء استعلام بيانات الربيعEntityManager و Session استخدم طريقة createQuery()AUTO في Hibernate 5 وMySQL الوصف: في MySQL & Hibernate 5، سيؤدي نوع المولد GenerationType.AUTO إلى استخدام منشئ TABLE . وهذا يضيف عقوبة أداء كبيرة. يمكن الحصول على تحويل هذا السلوك إلى منشئ IDENTITY باستخدام GenerationType.IDENTITY أو المولد الأصلي .
النقاط الرئيسية:
GenerationType.IDENTITY بدلاً من GenerationType.AUTO مثال الإخراج: 
الوصف: هذا التطبيق هو مثال عندما يكون استدعاء save() لكيان زائدًا عن الحاجة (ليس ضروريًا).
النقاط الرئيسية:
UPDATE المقابلة دون الحاجة إلى استدعاء الأسلوب save() بشكل صريحsave() عندما لا يكون ذلك ضروريًا) على عدد الاستعلامات التي تم تشغيلها، ولكنه يعني فرض عقوبة على الأداء في عمليات السبات الأساسية| إذا كنت بحاجة إلى التعمق في وصفات الأداء المعروضة في هذا المستودع، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات التمهيد الربيعي" | إذا كنت بحاجة إلى مجموعة من النصائح والرسوم التوضيحية لأكثر من 100 مشكلة في أداء استمرارية Java، فإن "الدليل المصور لأداء استمرارية Java" هو ما يناسبك. |
|
|
BIG ) SERIAL في عمليات الإدخال المجمعة عبر السبات الوصف: في PostgreSQL، سيؤدي استخدام GenerationType.IDENTITY إلى تعطيل تجميع الإدراج. يعمل (BIG)SERIAL "تقريبًا" مثل MySQL، AUTO_INCREMENT . في هذا التطبيق، نستخدم GenerationType.SEQUENCE الذي يسمح بدمج الإدخالات، ونقوم بتحسينه عبر خوارزمية التحسين hi/lo .
النقاط الرئيسية:
GenerationType.SEQUENCE بدلاً من GenerationType.IDENTITYhi/lo لجلب قيمة hi في رحلة ذهابًا وإيابًا لقاعدة البيانات (قيمة hi مفيدة لإنشاء عدد معين/معطى من المعرفات في الذاكرة؛ حتى لا تستنفد جميع المعرفات الموجودة في الذاكرة، ليست هناك حاجة لجلب مرحبا آخر)pooled pooled-lo (هذه عبارة عن تحسينات لـ hi/lo تسمح للخدمات الخارجية باستخدام قاعدة البيانات دون التسبب في أخطاء مفاتيح مكررة)spring.datasource.hikari.data-source-properties.reWriteBatchedInserts=true مثال الإخراج: 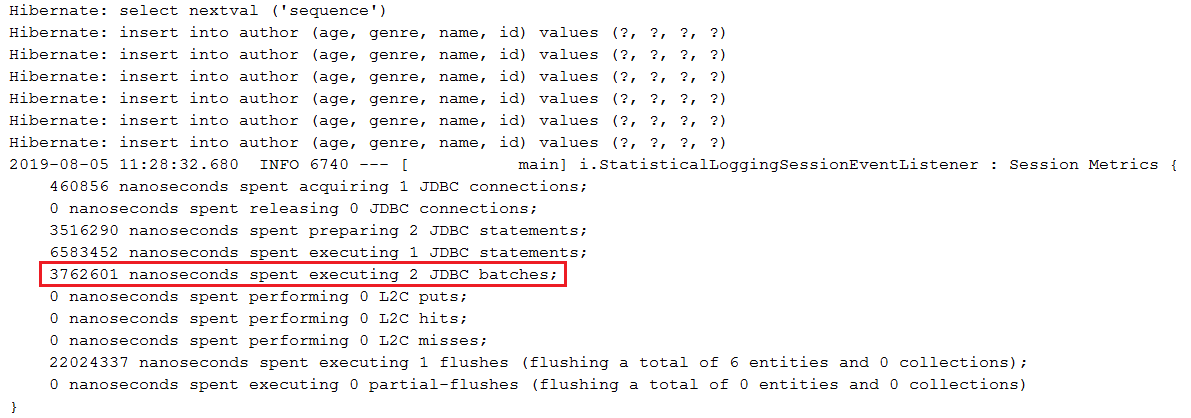
SINGLE_TABLE الوصف: هذا التطبيق هو نموذج لاستخدام استراتيجية وراثة الجدول الواحد JPA ( SINGLE_TABLE ).
النقاط الرئيسية:
@Inheritance(strategy=InheritanceType.SINGLE_TABLE) ) )@NotNull وMySQLTINYINT مثال على المخرجات (يوجد أدناه جدول واحد تم الحصول عليه من 3 كيانات): 
الوصف: هذا التطبيق هو نموذج لعد وتأكيد عبارات SQL التي يتم تشغيلها "خلف الكواليس". من المفيد جدًا حساب عبارات SQL للتأكد من أن التعليمات البرمجية الخاصة بك لا تولد المزيد من عبارات SQL التي قد تعتقدها (على سبيل المثال، يمكن اكتشاف N+1 بسهولة عن طريق تأكيد عدد العبارات المتوقعة).
النقاط الرئيسية:
pom.xml ، قم بإضافة تبعيات لمكتبة DataSource-Proxy ومكتبة db-util الخاصة بـ Vlad MihalceaProxyDataSourceBuilder باستخدام countQuery()SQLStatementCountValidator.reset()INSERT و UPDATE و DELETE و SELECT عبر assertInsert/Update/Delete/Select/Count(long expectedNumberOfSql) مثال على الإخراج (عندما لا يكون عدد SQLs المتوقع مساوياً للواقع، يتم طرح استثناء): 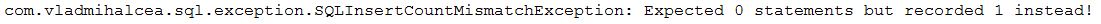
الوصف: هذا التطبيق هو نموذج لإعداد عمليات رد اتصال JPA ( Pre/PostPersist ، Pre/PostUpdate ، Pre/PostRemove ، و PostLoad ).
النقاط الرئيسية:
void ولا تأخذ أي وسائط مثال الإخراج: 
@MapsId لمشاركة المعرف في علاقة @OneToOne الوصف: بدلاً من @OneToOne العادي /ثنائي الاتجاه، من الأفضل الاعتماد على @OneToOne و @MapsId أحادي الاتجاه. هذا التطبيق هو دليل على المفهوم.
النقاط الرئيسية:
@MapsId على الجانب الطفل@JoinColumn لتخصيص اسم عمود المفتاح الأساسي@OneToOne ، سيشارك @MapsId المفتاح الأساسي مع الجدول الأصلي (تعمل خاصية id كمفتاح أساسي ومفتاح خارجي)ملحوظة:
@MapsId لـ @ManyToOne أيضًاSqlResultSetMapping و EntityManager الوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. نعتمد في هذا التطبيق على SqlResultSetMapping و EntityManager .
النقاط الرئيسية:
SqlResultSetMapping و EntityManagerSqlResultSetMapping و NamedNativeQuery ملاحظة: إذا كنت تريد الاعتماد على اصطلاح {EntityName}.{RepositoryMethodName} لإنشاء أساليب واجهة المستودع بنفس اسم الاستعلام المسمى الأصلي، فتخطى هذا التطبيق وتحقق من هذا.
الوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. نعتمد في هذا التطبيق على SqlResultSetMapping و NamedNativeQuery .
النقاط الرئيسية:
SqlResultSetMapping ، NamedNativeQueryjavax.persistence.Tuple وNative SQL الوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. في هذا التطبيق نعتمد على javax.persistence.Tuple وSQL الأصلي.
النقاط الرئيسية:
java.persistence.Tuple في مستودع Spring وقم بوضع علامة على الاستعلام كـ nativeQuery = truejavax.persistence.Tuple وJPQL الوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. نعتمد في هذا التطبيق على javax.persistence.Tuple و JPQL.
النقاط الرئيسية:
java.persistence.Tuple في مستودع الربيعالوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. نعتمد في هذا التطبيق على Constructor Expression و JPQL.
النقاط الرئيسية:
SELECT new com.bookstore.dto.AuthorDto(a.name, a.age) FROM Author a أنظر أيضا:
كيفية جلب DTO عبر آلية منشئ استعلام بيانات الربيع والمنشئ
| إذا كنت بحاجة إلى التعمق في وصفات الأداء المعروضة في هذا المستودع، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات التمهيد الربيعي" | إذا كنت بحاجة إلى مجموعة من النصائح والرسوم التوضيحية لأكثر من 100 مشكلة في أداء استمرارية Java، فإن "الدليل المصور لأداء استمرارية Java" هو ما يناسبك. |
|
|
ResultTransformer وSQL الأصلي الوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. في هذا التطبيق نعتمد على Hibernate و ResultTransformer وSQL الأصلي.
النقاط الرئيسية:
AliasToBeanConstructorResultTransformer لـ DTO بدون أدوات ضبط، ولكن باستخدام المُنشئTransformers.aliasToBean() لـ DTO مع المستوطنينEntityManager.createNativeQuery() وقم unwrap(org.hibernate.query.NativeQuery.class)ResultTransformer ، ولكن حتى يتوفر بديل (ربما في Hibernate 6.0) يمكن استخدامه (اقرأ المزيد)ResultTransformer وJPQL الوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. نعتمد في هذا التطبيق على Hibernate و ResultTransformer وJPQL.
النقاط الرئيسية:
AliasToBeanConstructorResultTransformer لـ DTO بدون أدوات ضبط، مع المُنشئTransformers.aliasToBean() لـ DTO مع المستوطنينEntityManager.createQuery() unwrap(org.hibernate.query.Query.class)ResultTransformer ، ولكن حتى يتوفر بديل (في Hibernate 6.0) يمكن استخدامه (اقرأ المزيد)الوصف: جلب بيانات أكثر مما هو مطلوب يكون عرضة لعقوبات الأداء. يتيح لنا استخدام DTO استخراج البيانات المطلوبة فقط. نعتمد في هذا التطبيق على طرق عرض كيان Blaze-Persistence.
النقاط الرئيسية:
pom.xml التبعيات الخاصة بـ Blaze-PersistenceCriteriaBuilderFactory و EntityViewManagerEntityViewRepositoryfindAll() و findOne() وما إلى ذلك@ElementCollection العادي (بدون @OrderColumn ). الوصف: يكشف هذا التطبيق عن عقوبات الأداء المحتملة لاستخدام @ElementCollection . في هذه الحالة، بدون @OrderColumn . كما ترون في العنصر التالي (34) فإن إضافة @OrderColumn يمكن أن يخفف من بعض عقوبات الأداء.
النقاط الرئيسية:
@ElementCollection على مفتاح أساسي@ElementCollection في جدول منفصل@ElementCollection عندما يكون لديك الكثير من عمليات الإدخال/الحذف في هذه المجموعة؛ ستؤدي عمليات الإدراج/الحذف إلى حذف السبات لجميع صفوف الجدول الموجودة، ومعالجة المجموعة في الذاكرة، وإعادة إدراج صفوف الجدول المتبقية لعكس المجموعة من الذاكرة مثال الإخراج: 
@ElementCollection مع @OrderColumn الوصف: يكشف هذا التطبيق عن عقوبات الأداء لاستخدام @ElementCollection . في هذه الحالة، مع @OrderColumn . ولكن، كما ترون في هذا التطبيق (مقارنة بالعنصر 33)، فإن إضافة @OrderColumn يمكن أن يخفف من بعض عقوبات الأداء عندما تتم العمليات بالقرب من ذيل المجموعة (على سبيل المثال، إضافة/إزالة في/من نهاية المجموعة). بشكل أساسي، يتم ترك جميع العناصر الموجودة قبل إدخال الإضافة/الإزالة دون تغيير، لذلك يمكن تجاهل عقوبة الأداء إذا أثرنا على الصفوف القريبة من ذيل المجموعة.
النقاط الرئيسية:
@ElementCollection على مفتاح أساسي@ElementCollection في جدول منفصل@ElementCollection مع @OrderColumn عندما يكون لديك الكثير من عمليات الإدخال والحذف بالقرب من ذيل المجموعة مثال الإخراج: 
ملاحظة: قبل قراءة هذا العنصر، حاول معرفة ما إذا كان Hibernate5Module ليس هو ما تبحث عنه.
الوصف: يتم تنشيط النمط المضاد للجلسة المفتوحة في العرض افتراضيًا في SpringBoot. الآن، تخيل وجود ارتباط بطيء (على سبيل المثال، @OneToMany ) بين كيانين، Author Book (قام المؤلف بربط المزيد من الكتب). بعد ذلك، تقوم نقطة نهاية وحدة التحكم REST بإحضار Author بدون Book المرتبط به. لكن وجهة النظر (بتعبير أدق، جاكسون)، تفرض التحميل البطيء Book المرتبط أيضًا. نظرًا لأن OSIV سيوفر Session المفتوحة بالفعل، فستتم تهيئة الوكلاء بنجاح. الحل لتجنب عقوبة الأداء هذه يبدأ بتعطيل OSIV. علاوة على ذلك، قم بتهيئة الارتباطات البطيئة غير المُجلبة بشكل صريح. بهذه الطريقة، لن يفرض العرض التحميل البطيء.
النقاط الرئيسية:
application.properties : spring.jpa.open-in-view=falseAuthor وتهيئة Book المرتبط به بشكل صريح باستخدام القيم (الافتراضية) (على سبيل المثال، null )@JsonInclude(Include.NON_EMPTY) على مستوى الكيان هذا لتجنب عرضه null أو ما يعتبر فارغًا في JSON الناتج ملاحظة: إذا تم تمكين OSIV، فلا يزال بإمكان المطور تهيئة الارتباطات البطيئة التي لم يتم جلبها يدويًا طالما أنه يفعل ذلك خارج المعاملة لتجنب المسح. لكن لماذا يعمل هذا؟ نظرًا لأن Session مفتوحة، فلماذا لا تؤدي التهيئة اليدوية لاقترانات الكيان المُدار إلى تشغيل التدفق؟ يمكن العثور على الإجابة في وثائق OpenSessionInViewFilter التي تحدد ما يلي: لن يقوم هذا المرشح افتراضيًا بتدفق Session السبات، مع تعيين وضع التدفق على FlushMode.NEVER . يفترض أن يتم استخدامه مع معاملات طبقة الخدمة التي تهتم بالمسح: سيقوم مدير المعاملات النشط بتغيير وضع التدفق مؤقتًا إلى FlushMode.AUTO أثناء معاملة القراءة والكتابة، مع إعادة تعيين وضع التدفق إلى FlushMode.NEVER في النهاية من كل معاملة. إذا كنت تنوي استخدام هذا المرشح بدون معاملات، ففكر في تغيير وضع التدفق الافتراضي (من خلال خاصية "flushMode").

الوصف: يعد هذا التطبيق دليلاً على مفهوم استخدام Spring Projections(DTO) والروابط الداخلية المكتوبة عبر JPQL وSQL الأصلية (لـ MySQL).
النقاط الرئيسية:
Author Book في اقتران @OneToMany ثنائي الاتجاه (كسول))resources/data-mysql.sql )AuthorNameBookTitle.java )
الوصف: يعد هذا التطبيق دليلاً على مفهوم استخدام Spring Projections(DTO) والروابط اليسرى المكتوبة عبر JPQL وSQL الأصلية (لـ MySQL).
النقاط الرئيسية:
Author Book في جمعية @OneToMany ثنائية الاتجاه (كسول))resources/data-mysql.sql )AuthorNameBookTitle.java )
الوصف: هذا التطبيق هو دليل على استخدام الإسقاطات الربيع (DTO) والوصول اليمين المكتوبة عبر JPQL و Native SQL (لـ MySQL).
النقاط الرئيسية:
Author Book في جمعية @OneToMany ثنائية الاتجاه (كسول))resources/data-mysql.sql )AuthorNameBookTitle.java )
الوصف: هذا التطبيق هو دليل على استخدام الإسقاطات الربيع (DTO) والوصلات الكاملة الشاملة المكتوبة عبر JPQL و SQL الأصلي (لـ PostgreSQL).
النقاط الرئيسية:
Author Book في جمعية @OneToMany ثنائية الاتجاه (كسول))resources/data-mysql.sql )AuthorNameBookTitle.java )| إذا كنت بحاجة إلى غوص عميق في وصفات الأداء المكشوفة في هذا المستودع ، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات الحذاء" | إذا كنت بحاجة إلى يد من نصائح ورسوم توضيحية لمشكلات أداء الثبات 100+ جافا ، فإن "دليل تصوير أداء جافا" يناسبك. |
|
|

الوصف: هذا التطبيق هو دليل على استخدام الإسقاطات الربيع (DTO) والوصلات اليسرى الحصرية المكتوبة عبر JPQL و SQL الأصلي (لـ MySQL).
النقاط الرئيسية:
Author Book في جمعية @OneToMany ثنائية الاتجاه (كسول))resources/data-mysql.sql )AuthorNameBookTitle.java )
الوصف: هذا التطبيق هو دليل على استخدام الإسقاطات الربيع (DTO) والوصول اليمنى الحصري المكتوب عبر JPQL و SQL الأصلي (لـ MySQL).
النقاط الرئيسية:
Author Book في جمعية @OneToMany ثنائية الاتجاه (كسول))resources/data-mysql.sql )AuthorNameBookTitle.java )
الوصف: هذا التطبيق هو دليل على استخدام الإسقاطات الربيع (DTO) والوصول الكامل الحصري المكتوبة عبر JPQL و SQL الأصلي (لـ PostgreSQL).
النقاط الرئيسية:
Author Book في جمعية @OneToMany ثنائية الاتجاه (كسول))resources/data-mysql.sql )AuthorNameBookTitle.java )الوصف: هذا التطبيق هو دليل على استخدام السنانير بعد الالتزام الربيع وكيف قد يؤثر على أداء طبقة الثبات.
النقاط الرئيسية:
الوصف: هذا التطبيق هو دليل على استخدام توقعات الربيع (DTO) والانضمام إلى الكيانات غير ذات الصلة. إدخال Hibernate 5.1 تم تقديم صلة واضحة على الكيانات غير ذات الصلة وبناء الجملة والسلوك تشبه عبارات JOIN SQL.
النقاط الرئيسية:
Author Book غير ذات الصلة)resources/data-mysql.sql )BookstoreDto )@EqualsAndHashCode و @Data في الكيانات وكيفية تجاوز equals() و hashCode() الوصف: يجب أن تنفذ الكيانات equals() و hashCode() كما هو الحال هنا. الفكرة الرئيسية هي أن السبات يتطلب أن يكون الكيان مساوياً لنفسه عبر جميع انتقالات حالته ( عابرة ، متصلة ، منفصلة وإزالة ). لن يحترم استخدام @EqualsAndHashCode (أو @Data ) هذا المطلب.
النقاط الرئيسية:
تجنب هذه الأساليب
@EqualsAndHashCode (الكيان: LombokDefaultBook ، الاختبار: LombokDefaultEqualsAndHashCodeTest )@EqualsAndHashCode مع المفتاح الأساسي فقط (الكيان: LombokIdBook ، الاختبار: LombokEqualsAndHashCodeWithIdOnlyTest )equals() و hashCode() (الكيان: DefaultBook ، الاختبار: DefaultEqualsAndHashCodeTest )equals() و hashCode() يحتوي فقط على معرف تم إنشاؤه بواسطة قاعدة البيانات (الكيان: IdBook ، الاختبار: IdEqualsAndHashCodeTest )تفضل هذه الأساليب
BusinessKeyBook ، الاختبار: BusinessKeyEqualsAndHashCodeTest )@NaturalId (الكيان: NaturalIdBook ، الاختبار: NaturalIdEqualsAndHashCodeTest )IdManBook ، الاختبار: IdManEqualsAndHashCodeTest )IdGenBook ، الاختبار: IdGenEqualsAndHashCodeTest ) 
LazyInitializationException عبر JOIN FETCHأنظر أيضا:
الوصف: عادة ، عندما نحصل على LazyInitializationException فإننا نميل إلى تعديل نوع الجلب من LAZY إلى EAGER . هذا سيء للغاية! هذه رائحة رمز. أفضل طريقة لتجنب هذا الاستثناء هي الاعتماد على JOIN FETCH (إذا كنت تخطط لتعديل الكيانات التي تم جلبها) أو JOIN + DTO (إذا كانت البيانات التي تم جلبها فقط قراءة). يتيح JOIN FETCH تهيئة الجمعيات مع كائناتها الأم باستخدام SELECT واحد. هذا مفيد بشكل خاص لجلب المجموعات المرتبطة.
هذا التطبيق هو مثال JOIN FETCH لتجنب LazyInitializationException .
النقاط الرئيسية:
Author Book في جمعية @OneToMany lazy-bidiviewsal)JOIN FETCH لجلب مؤلف بما في ذلك كتبهJOIN FETCH (أو JOIN ) لجلب كتاب بما في ذلك مؤلفه مثال الإخراج: 
الوصف: هذا مثال على الحذاء الربيعي استنادًا إلى المقالة التالية. هو تنفيذ وظيفي لمثال فلاد. يوصى بشدة بقراءة هذا المقال.
النقاط الرئيسية:
الوصف: هذا مثال التمهيد الربيعي يستغل الإسبات 5.2.10 القدرة على تأخير اكتساب الاتصال حسب الحاجة. بشكل افتراضي ، في الوضع المحلي للموارد ، يتم اتصال قاعدة البيانات مباشرة بعد استدعاء طريقة مشروحة باستخدام @Transactional . إذا كانت هذه الطريقة تحتوي على بعض المهام التي تستغرق وقتًا طويلاً قبل بيان SQL الأول ، فسيكون الاتصال مفتوحًا مقابل لا شيء. ولكن ، يتيح لنا Hibernate 5.2.10 تأخير عملية الاستحواذ على الاتصال حسب الحاجة. يعتمد هذا المثال على HikarICP كتجمع الاتصال الافتراضي لحذاء الربيع.
النقاط الرئيسية:
spring.datasource.hikari.auto-commit=false in application.propertiesspring.jpa.properties.hibernate.connection.provider_disables_autocommit=true in application.properties مثال الإخراج: 

hi/lo ملاحظة: إذا كانت الأنظمة الخارجية لتطبيقك بحاجة إلى إدراج صفوف في الجداول الخاصة بك ، فلا تعتمد على خوارزمية hi/lo لأنه ، في مثل هذه الحالات ، قد تسبب أخطاء ناتجة عن توليد معرفات مكررة. اعتمد على خوارزميات pooled أو pooled-lo (تحسينات hi/lo ).
الوصف: هذا مثال على الحذاء الربيعي لاستخدام خوارزمية hi/lo لإنشاء 1000 معرفات في 10 قاعدة بيانات قاعدة بيانات لتجميع 1000 إدراج على دفعات من 30.
النقاط الرئيسية:
SEQUENCE (على سبيل المثال ، في postgresql)hi/lo كما هو الحال في Author.java الكيان مثال الإخراج: 
| إذا كنت بحاجة إلى غوص عميق في وصفات الأداء المكشوفة في هذا المستودع ، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات الحذاء" | إذا كنت بحاجة إلى يد من نصائح ورسوم توضيحية لمشكلات أداء الثبات 100+ جافا ، فإن "دليل تصوير أداء جافا" يناسبك. |
|
|
@ManyToMany الوصف: هذا التطبيق هو دليل على مفهوم كيف يصحح تنفيذ جمعية @ManyToMany ثنائية الاتجاه من منظور الأداء.
النقاط الرئيسية:
mappedBySet لا ListCascadeType.PERSIST و CascadeType.MERGE ، ولكن تجنب CascadeType.REMOVE/ALL@ManyToMany كسول افتراضيًا ؛ احتفظ بها بهذه الطريقة!@NaturalId )) و/أو معرفات أنشأها قاعدة البيانات والتجاوز (على كلا الجانبين) بشكل صحيح equals() و hashCode() كما هو الحال هنا.toString() بحاجة إلى تجاوز ، فانتبه إلى إشراك فقط للسمات الأساسية التي يتم جلبها عندما يتم تحميل الكيان من قاعدة البياناتSet بدلاً من List في جمعيات @ManyToMany الوصف: هذا مثال على الحذاء الربيعي لإزالة الصفوف في حالة وجود ثنائي الاتجاه @ManyToMany باستخدام List ، على Set . الاستنتاج هو أن Set أفضل بكثير! هذا ينطبق على أحادي الاتجاه كذلك!
النقاط الرئيسية:
Set أكثر فعالية بكثير من List مثال الإخراج: 
log4jdbcالوصف: عرض تفاصيل الاستعلام عبر log4jdbc.
النقاط الرئيسية:
pom.xml ، أضف log4jdbc التبعية عينة الإخراج: 
الوصف: عرض المعلمات الربط/المستخرجة من البيان المعد عبر TRACE .
النقاط الرئيسية:
application.properties إضافة: logging.level.org.hibernate.type.descriptor.sql=TRACE عينة الإخراج: 
java.time.YearMonth Integer أو Date عبر مكتبة أنواع hibernate الوصف: أنواع السبات هي مجموعة من الأنواع الإضافية التي لا تدعمها افتراضيًا في Hibernate Core. أحد هذه الأنواع هو java.time.YearMonth . هذا هو تطبيق Boot Spring الذي يستخدم نوع Hibernate لتخزين هذا YearMonth في قاعدة بيانات MySQL كمعدل صحيح أو تاريخ.
النقاط الرئيسية:
pom.xml@TypeDef لرسم خريطة typeClass إلى defaultForType مثال الإخراج: 
ملاحظة : يمكن إجراء وظائف SQL في WHERE (وليس في الجزء SELECT ) من الاستعلام في JPA 2.1 عبر function() كما هو الحال هنا.
الوصف: قد تؤدي محاولة استخدام وظائف SQL (القياسية أو المحددة) في استعلامات JPQL إلى استثناءات إذا لم يتعرف عليها السبات ولا يمكنها تحليل استعلام JPQL. على سبيل المثال ، لا يتم التعرف على وظيفة MySQL ، concat_ws بواسطة السبات. هذا التطبيق هو تطبيق Boot Spring يعتمد على Hibernate 5.3 ، ويسجل وظيفة concat_ws عبر MetadataBuilderContributor وإبلاغ السبات به عن طريق ، metadata_builder_contributor الخاصية. يستخدم هذا المثال @Query و EntityManager أيضًا ، حتى تتمكن من رؤية حالتين للاستخدام.
النقاط الرئيسية:
MetadataBuilderContributor وتسجيل وظيفة mysql concat_wsMetadataBuilderContributor application.properties spring.jpa.properties.hibernate.metadata_builder_contributor مثال الإخراج: 
الوصف: هذا التطبيق عبارة عن عينة من التسجيل البطيء فقط عبر DataSource-Proxy . الاستعلام البطيء هو استعلام له وقت تنفيذ أكبر من عتبة محددة بالميلي ثانية.
النقاط الرئيسية:
pom.xml التبعية proxy dataSourceDataSourceDataSource عبر ProxyFactory وتنفيذ MethodInterceptorafterQuery() مثال الإخراج: 
SELECT COUNT Page<dto> الوصف: يجلب هذا التطبيق البيانات Page<dto> عبر ترقيم إزاحة الإذاعة الربيع. في معظم الأوقات ، فإن البيانات التي يجب أن تتم ترقيتها هي بيانات القراءة فقط . يجب أن يتم إحضار البيانات إلى الكيانات فقط إذا كنا نخطط لتعديل تلك البيانات ، وبالتالي ، فإن جلب البيانات القراءة فقط Page<entity> ليس من الأفضل لأنها قد تنتهي في عقوبة أداء كبيرة. يعد SELECT COUNT الذي تم تشغيله لحساب العدد الإجمالي للسجلات هو انبعاث فرعي SELECT الرئيسي. لذلك ، سيكون هناك قاعدة قاعدة بيانات واحدة بدلاً من اثنين (عادة ، هناك استعلام واحد مطلوب لجلب البيانات وواحد لحساب إجمالي عدد السجلات).
النقاط الرئيسية:
PagingAndSortingRepositoryList<dto>List<dto> والقابلة Pageable لإنشاء Page<dto>SELECT COUNT الفرعي List<dto> الوصف: يجلب هذا التطبيق البيانات List<dto> عبر ترقيم إزاحة التمهيد الربيعي. في معظم الأوقات ، فإن البيانات التي يجب أن تتم ترقيتها هي بيانات القراءة فقط . يجب أن يتم إحضار البيانات إلى الكيانات فقط إذا خططنا لتعديل تلك البيانات ، وبالتالي ، فإن جلب البيانات القراءة فقط List<entity> ليس من الأفضل لأنها قد تنتهي في عقوبة أداء كبيرة. يعد SELECT COUNT الذي تم تشغيله لحساب العدد الإجمالي للسجلات هو انبعاث فرعي SELECT الرئيسي. لذلك ، سيكون هناك قاعدة قاعدة بيانات واحدة بدلاً من اثنين (عادة ، هناك استعلام واحد مطلوب لجلب البيانات وواحد لحساب إجمالي عدد السجلات).
النقاط الرئيسية:
PagingAndSortingRepositoryList<dto> إذا كنت تستخدم spring-boot-starter-jdbc أو spring-boot-starter-data-jpa "مبتدئين" ، فستحصل تلقائيًا على التبعية على Hikaricp
ملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق الذي يقوم بإعداد hikaricp عبر التطبيق. application.properties فقط. تم إعداد jdbcUrl لقاعدة بيانات MySQL. لأغراض الاختبار ، يستخدم التطبيق خدمة ExecutorService لمحاكاة المستخدمين المتزامنين. تحقق من تقرير Hickaricp الذي يكشف عن حالة تجمع الاتصال.
النقاط الرئيسية:
application.properties spring.datasource.hikari.* عينة الإخراج: 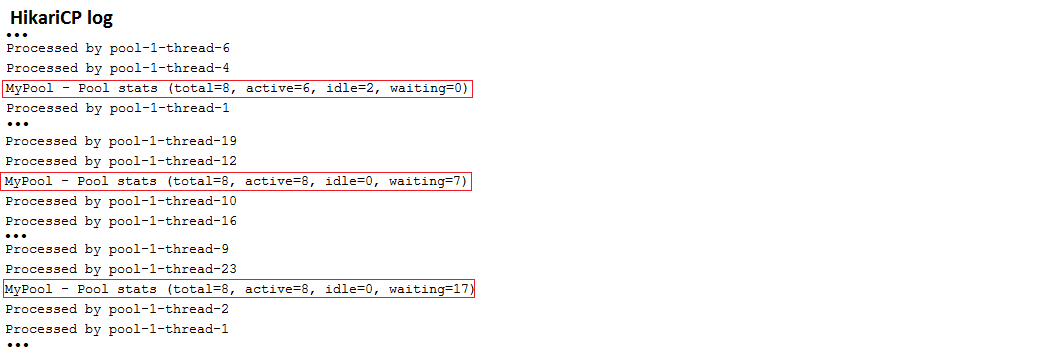
| إذا كنت بحاجة إلى غوص عميق في وصفات الأداء المكشوفة في هذا المستودع ، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات الحذاء" | إذا كنت بحاجة إلى يد من نصائح ورسوم توضيحية لمشكلات أداء الثبات 100+ جافا ، فإن "دليل تصوير أداء جافا" يناسبك. |
|
|
DataSourceBuilder إذا كنت تستخدم spring-boot-starter-jdbc أو spring-boot-starter-data-jpa "مبتدئين" ، فستحصل تلقائيًا على التبعية على Hikaricp
ملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق الذي يقوم بإعداد Hikaricp عبر DataSourceBuilder . تم إعداد jdbcUrl لقاعدة بيانات MySQL. لأغراض الاختبار ، يستخدم التطبيق خدمة ExecutorService لمحاكاة المستخدمين المتزامنين. تحقق من تقرير Hickaricp الذي يكشف عن حالة تجمع الاتصال.
النقاط الرئيسية:
application.properties ، قم بتكوين hikaricp عبر بادئة مخصصة ، على سبيل المثال ، app.datasource.*@Bean يعيد DataSource عينة الإخراج:
هذا التطبيق مفصل في هذه المقالة DZONE.
DataSourceBuilderملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق الذي يقوم بإعداد bonecp عبر DataSourceBuilder . تم إعداد jdbcUrl لقاعدة بيانات MySQL. لأغراض الاختبار ، يستخدم التطبيق خدمة ExecutorService لمحاكاة المستخدمين المتزامنين.
النقاط الرئيسية:
pom.xml أضف تبعية bonecpapplication.properties ، قم بتكوين bonecp عبر بادئة مخصصة ، على سبيل المثال ، app.datasource.*@Bean يعيد DataSource عينة الإخراج: 
DataSourceBuilderملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق إعداد ViburdBCP عبر DataSourceBuilder . تم إعداد jdbcUrl لقاعدة بيانات MySQL. لأغراض الاختبار ، يستخدم التطبيق خدمة ExecutorService لمحاكاة المستخدمين المتزامنين.
النقاط الرئيسية:
pom.xml أضف تبعية viburdbcpapplication.properties ، قم بتكوين viburdbcp عبر بادئة مخصصة ، على سبيل المثال ، app.datasource.*@Bean يعيد DataSource عينة الإخراج: 
DataSourceBuilderملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق إعداد C3P0 عبر DataSourceBuilder . تم إعداد jdbcUrl لقاعدة بيانات MySQL. لأغراض الاختبار ، يستخدم التطبيق خدمة ExecutorService لمحاكاة المستخدمين المتزامنين.
النقاط الرئيسية:
pom.xml أضف تبعية C3P0application.properties ، قم بتكوين C3P0 عبر بادئة مخصصة ، على سبيل المثال ، app.datasource.*@Bean يعيد DataSource عينة الإخراج: 
DataSourceBuilderملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق إعداد DBCP2 عبر DataSourceBuilder . تم إعداد jdbcUrl لقاعدة بيانات MySQL. لأغراض الاختبار ، يستخدم التطبيق خدمة ExecutorService لمحاكاة المستخدمين المتزامنين.
النقاط الرئيسية:
pom.xml أضف تبعية DBCP2application.properties ، قم بتكوين DBCP2 عبر بادئة مخصصة ، على سبيل المثال ، app.datasource.*@Bean يعيد DataSourceDataSourceBuilderملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق الذي يقوم بإعداد Tomcat عبر DataSourceBuilder . تم إعداد jdbcUrl لقاعدة بيانات MySQL. لأغراض الاختبار ، يستخدم التطبيق خدمة ExecutorService لمحاكاة المستخدمين المتزامنين.
النقاط الرئيسية:
pom.xml أضف تبعية tomcatapplication.properties ، قم بتكوين tomcat عبر بادئة مخصصة ، على سبيل المثال ، app.datasource.*@Bean يعيد DataSource عينة الإخراج: 
ملاحظة: تتكون أفضل طريقة لضبط معلمات تجمع الاتصال في استخدام Prowhy Pool by Vlad Mihalcea. عبر Flexy Pool ، يمكنك العثور على إعدادات Optim التي تحافظ على أداء تجمع الاتصال العالي.
الوصف: هذا تطبيق انطلاق يستخدم مصدرين للبيانات (قاعدتان من قواعد بيانات MySQL ، أحد authorsdb المسماة و One booksdb ) مع تجمعين للاتصال (كل قاعدة بيانات تستخدم مجموعة اتصال HikariCP الخاصة بها مع إعدادات مختلفة). استنادًا إلى العناصر المذكورة أعلاه ، من السهل جدًا تكوين تجمعين اتصال من مزورين مختلفين أيضًا.
النقاط الرئيسية:
app.datasource.ds1 application.properties app.datasource.ds2@Bean التي تُرجع أول DataSource وتميزها على أنها @Primary@Bean آخر يعيد DataSource الثانيEntityManagerFactory وأشير إلى الحزم للمسح الضوئي لكل منهماEntityManager في الحزم الصحيحة عينة الإخراج: 
ملاحظة : إذا كنت تريد تقديم واجهة برمجة تطبيقات بطلاقة دون تغيير المستوطنين ، ففكر في هذا العنصر.
الوصف: هذا تطبيق عينة يغير أساليب المستقلين من أجل تمكين واجهة برمجة تطبيقات بطلاقة.
النقاط الرئيسية:
this بدلاً من void في المستودعات مثال API بطلاقة: 
ملاحظة : إذا كنت تريد تقديم واجهة برمجة تطبيقات بطلاقة عن طريق تغيير المستوطنين ، ففكر في هذا العنصر.
الوصف: هذا هو تطبيق عينة يضيف في الكيانات طرقًا إضافية (على سبيل المثال ، من أجل setName ، نضيف name ) من أجل تمكين واجهة برمجة تطبيقات بطلاقة.
النقاط الرئيسية:
this بدلاً من void مثال API بطلاقة: 
| إذا كنت بحاجة إلى غوص عميق في وصفات الأداء المكشوفة في هذا المستودع ، فأنا متأكد من أنك ستحب كتابي "أفضل ممارسات ثبات الحذاء" | إذا كنت بحاجة إلى يد من نصائح ورسوم توضيحية لمشكلات أداء الثبات 100+ جافا ، فإن "دليل تصوير أداء جافا" يناسبك. |
|
|
Slice<T> findAll() على الأرجح هذا هو كل ما تريده: كيفية جلب Slice<entity> / Slice<dto> عبر fetchAll / fetchAllDto
بعض تطبيقات Slice<T> findAll() :
"SELECT e FROM " + entityClass.getSimpleName() + " e;"CriteriaBuilder بدلاً من SQL مشفرSort ، لذلك من الممكن نتائج الفرزSort Specification بيانات الربيعSort ، و LockModeType ، و QueryHints Specification بيانات الربيعPageable و/أو Specification من خلال توسيع SimpleJpaRepository من بيانات الربيع. بشكل أساسي ، هذا التنفيذ هو الوحيد الذي يرجع Page<T> بدلاً من Slice<T> ، لكنه لا يؤدي إلى SELECT COUNT الإضافي لأنه تم التخلص منه عن طريق تجاوز Page<T> readPage(...) من SimpleJpaRepository . العيب الرئيسي هو أنه من خلال الاحتفاظ Page<T> لا تعرف ما إذا كانت هناك صفحة التالية أو أن تكون هذه هي الأخيرة. ومع ذلك ، هناك حلول للحصول على هذا أيضًا. في هذا التنفيذ ، لا يمكنك ضبط تلميحات LockModeType أو الاستعلام. القصة : يوفر Spring Boot آلية ترحيل مدمجة تعتمد على الإزاحة التي تُرجع Page أو Slice . يمثل كل من واجهات برمجة التطبيقات هذه صفحة من البيانات وبعض البيانات الوصفية. الفرق الرئيسي هو أن Page تحتوي على إجمالي عدد السجلات ، في حين أن Slice لا يمكنها تحديد ما إذا كانت هناك صفحة أخرى متاحة. بالنسبة Page ، يوفر SPRING BOOT طريقة findAll() قادرة على أخذ وسيطات Pageable و/أو Specification أو Example . من أجل إنشاء Page تحتوي على العدد الإجمالي للسجلات ، تؤدي هذه الطريقة إلى قيام SELECT COUNT بالإعدام بجوار الاستعلام المستخدم لجلب بيانات الصفحة الحالية. يمكن أن يكون هذا عقوبة أداء حيث يتم تشغيل استعلام SELECT COUNT في كل مرة نطلب فيها صفحة. من أجل تجنب هذا الإطار الخارجي ، يوفر SPRING BOOT واجهة برمجة تطبيقات أكثر استرخاءً ، واجهة برمجة تطبيقات Slice . يؤدي استخدام Slice بدلاً من Page إلى إزالة الحاجة إلى استعلام SELECT COUNT الإضافي هذا وإرجاع الصفحة (السجلات) وبعض البيانات الوصفية دون إجمالي عدد السجلات. لذلك ، على الرغم من أن Slice لا يعرف إجمالي عدد السجلات ، إلا أنه لا يزال بإمكانه معرفة ما إذا كانت هناك صفحة أخرى متاحة بعد الصفحة الحالية أو هذه هي الصفحة الأخيرة. تكمن المشكلة في أن Slice تعمل بشكل جيد بالنسبة للاستعلامات التي تحتوي على SQL ، WHERE البند (بما في ذلك تلك التي تستخدم آلية منشئ الاستعلام المضمنة في بيانات الربيع) ، لكنها لا تعمل مع findAll() . ستظل هذه الطريقة تُرجع Page بدلاً من Slice ، وبالتالي يتم تشغيل استعلام SELECT COUNT Slice<T> findAll(...); .
الوصف: هذه مجموعة من تطبيقات العينات التي توفر إصدارات مختلفة من طريقة Slice<T> findAll(...) . لدينا من تطبيق الحد الأدنى يعتمد على استعلام متشددين على أنه: "SELECT e FROM " + entityClass.getSimpleName() + " e"; (هذه الوصفة) ، إلى تطبيق مخصص يدعم تلميحات الفرز والمواصفات ووضع القفل والاستعلام إلى تطبيق يعتمد على تمديد SimpleJpaRepository .
النقاط الرئيسية:
abstract تعرض طرق Slice<T> findAll(...) ( SlicePagingRepositoryImplementation )findAll() لإرجاع Slice<T> (أو Page<T> ، ولكن بدون العدد الإجمالي للعناصر)SliceImpl ( Slice<T> ) أو PageImpl ( Page<T> ) بدون إجمالي عدد العناصرreadSlice() جديدة أو تجاوز صفحة SimpleJpaRepository#readPage() لتجنب SELECT COUNTabstract Author.class AuthorRepositoryCOUNT(*) OVER وإرجاع List<dto> الوصف: عادةً ، في ترقيم ترقيم الأوفست ، هناك استعلام واحد مطلوب لجلب البيانات وواحد لحساب إجمالي عدد السجلات. ولكن ، يمكننا إحضار هذه المعلومات في قاعدة بيانات واحدة من خلال مسافة SELECT COUNT الفرعية المتداخلة في SELECT الرئيسي. والأفضل من ذلك ، بالنسبة لبائعي قواعد البيانات الذين يدعمون وظائف النوافذ ، هناك حل يعتمد على SELECT COUNT COUNT(*) OVER() كما في هذا التطبيق الذي يستخدم وظيفة النافذة هذه في استعلام أصلي مقابل MySQL 8. .
النقاط الرئيسية:
COUNT(*) OVER() مثال: 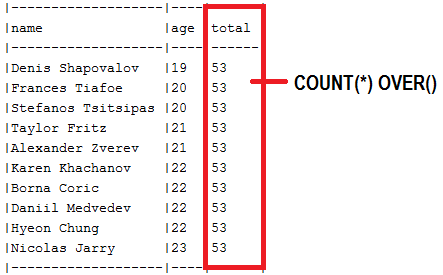
الوصف: عندما نعتمد على ترحيل الإزاحة ، لدينا عقوبة الأداء التي يسببها رمي سجلات N قبل الوصول إلى الإزاحة المطلوبة. أكبر n يؤدي إلى عقوبة أداء كبيرة. عندما يكون لدينا n كبير n من الأفضل الاعتماد على ترقيم مفاتيح التي تحافظ على وقت "ثابت" لمجموعات البيانات الكبيرة. من أجل فهم مدى سوء الإزاحة ، يرجى التحقق من هذه المقالة:
لقطة شاشة من تلك المقالة (ترقيم ترقيم الأمواج ): 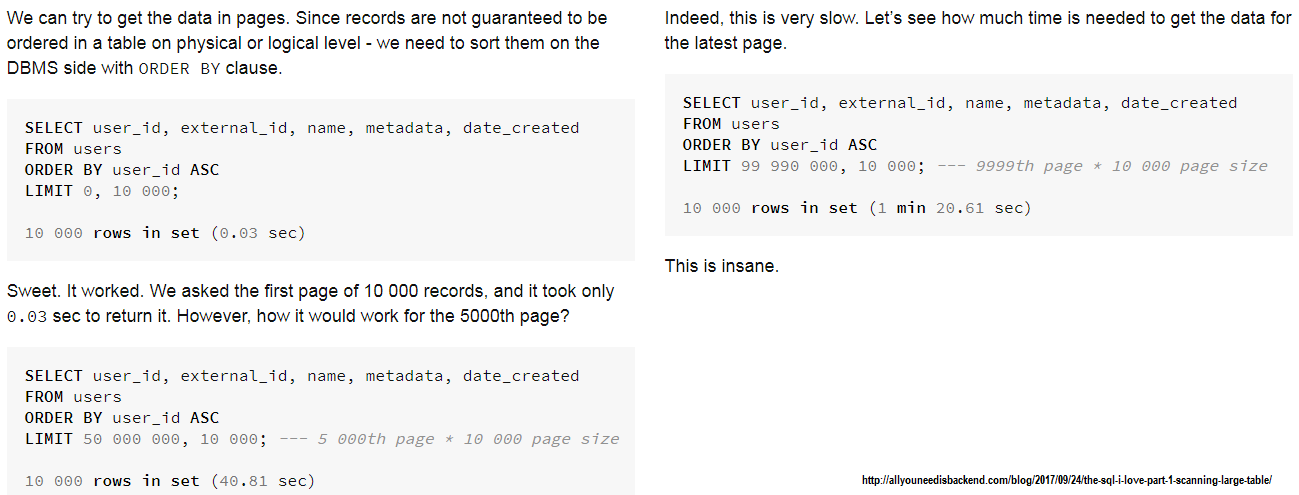
هل تحتاج إلى معرفة ما إذا كان هناك المزيد من السجلات؟
بطبيعته ، لا تستخدم KeySet SELECT COUNT لجلب عدد السجلات الإجمالية. ولكن ، مع القليل من القرص ، يمكننا بسهولة أن نقول ما إذا كان هناك المزيد من السجلات ، وبالتالي لإظهار زر النوع Next Page . بشكل رئيسي ، إذا كنت بحاجة إلى مثل هذا الشيء ، ففكر في هذا التطبيق الذي تم سرد ذروته أدناه:
public AuthorView fetchNextPage(long id, int limit) {
List<Author> authors = authorRepository.fetchAll(id, limit + 1);
if (authors.size() == (limit + 1)) {
authors.remove(authors.size() - 1);
return new AuthorView(authors, true);
}
return new AuthorView(authors, false);
}
أو ، مثل هذا (الاعتماد على طريقة Author.toString() ):
public Map<List<Author>, Boolean> fetchNextPage(long id, int limit) {
List<Author> authors = authorRepository.fetchAll(id, limit + 1);
if(authors.size() == (limit + 1)) {
authors.remove(authors.size() -1);
return Collections.singletonMap(authors, true);
}
return Collections.singletonMap(authors, false);
}
يمكن تنفيذ زر Previous Page بسهولة بناءً على السجل الأول.
النقاط الرئيسية:
id )WHERE ORDER BY الجمل من SQL الخاص بكالوصف: هذا مثال على ترقيم الإزاحة الإزاحة الحذاء الكلاسيكية. ومع ذلك ، لا ينصح باستخدام هذا النهج في الإنتاج بسبب عقوبات الأداء الموضحة بشكل أكبر.
عندما نعتمد على ترقيم ترقيم الأسعار ، لدينا عقوبة الأداء التي يسببها التخلص من سجلات N قبل الوصول إلى الإزاحة المطلوبة. أكبر n يؤدي إلى عقوبة أداء كبيرة. ركلة جزاء أخرى هي SELECT خارج المطلوب لحساب إجمالي عدد السجلات. من أجل فهم مدى سوء تعويض ترقيم ترقيم ترقيمها ، يرجى التحقق من هذه المقالة. لقطة شاشة من هذه المقالة أدناه: ومع ذلك ، ربما هذا المثال متطرف بعض الشيء. بالنسبة لمجموعات البيانات الصغيرة نسبيًا ، فإن ترقيم ترقيم الأوفست ليس سيئًا للغاية (إنه قريب من الأداء إلى تراجع مفاتيح المفاتيح ) ، وبما أن حذاء الربيع يوفر دعمًا مدمجًا لتراجع الأوفست عبر واجهة برمجة Page ، فمن السهل جدًا استخدامه. ومع ذلك ، بناءً على الحالة ، يمكننا تحسين ترقيم ترقيم الإزاحة قليلاً كما في الأمثلة التالية:
جلب صفحة Page :
COUNT(*) OVER Page<dto>COUNT(*) OVER Page<entity> عبر عمود إضافيSELECT COUNT Subser و Return Page<dto>SELECT COUNT Subquery و Return Page<entity> عبر عمود إضافيSELECT COUNT SUBSERY و RETRESE Page<projection> التي يقوم بها كيانات التعيين وإجمالي عدد السجلات عن طريق الإسقاط جلب صفحة List :
COUNT(*) OVER List<dto>COUNT(*) OVER List<entity> عبر عمود إضافيSELECT COUNT SUBSERIALE و List<dto>SELECT COUNT Subquery وقائمة الإرجاع List<entity> عبر عمود إضافيList<projection> SELECT COUNT SUBSERIALIRE SUBSIONولكن: إذا كان ترقيم ترقيم الإزاحة يسبب لك مشكلات في الأداء وقررت الذهاب مع تراجع Keyset ، فيرجى التحقق هنا (تراجع مفاتيح ).
النقاط الرئيسية لترقيم ترقيم الإزاحة الكلاسيكية:
PagingAndSortingRepositoryPage<entity>أمثلة على ترقيم ترقيم الإزاحة الكلاسيكية:
findAll(Pageable) دون الفرز:repository.findAll(PageRequest.of(page, size));findAll(Pageable) مع الفرز:repository.findAll(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "name")));Page<Author> findByName(String name, Pageable pageable);Page<Author> queryFirst10ByName(String name, Pageable pageable); الوصف: لنفترض أن لدينا علاقة واحدة إلى حد بين Author وكيانات Book . عندما ننقذ مؤلفًا ، نقوم بحفظ كتبه أيضًا بفضل متتالية/مستمر. We want to create a bunch of authors with books and save them in the database (eg, a MySQL database) using the batch technique. By default, this will result in batching each author and the books per author (one batch for the author and one batch for the books, another batch for the author and another batch for the books, and so on). In order to batch authors and books, we need to order inserts as in this application.
Key points: Beside all setting specific to batching inserts in MySQL, we need to set up in application.properties the following property: spring.jpa.properties.hibernate.order_inserts=true
Example without ordered inserts: 
Example with ordered inserts: 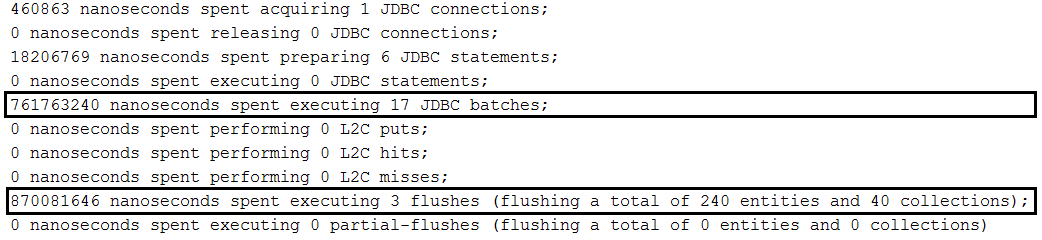
Implementations:
Description: Batch updates in MySQL.
النقاط الرئيسية:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL, statements get rewritten into a single string buffer and sent in a single request)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_updates=true to optimize the batching by ordering التحديثاتapplication.properties a setting for enabling batching for versioned entities during update and delete operations (entities that contains @Version for implicit optimistic locking); this setting is: spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true ; starting with Hibernate 5, this setting should be true by default Output example for single entity: 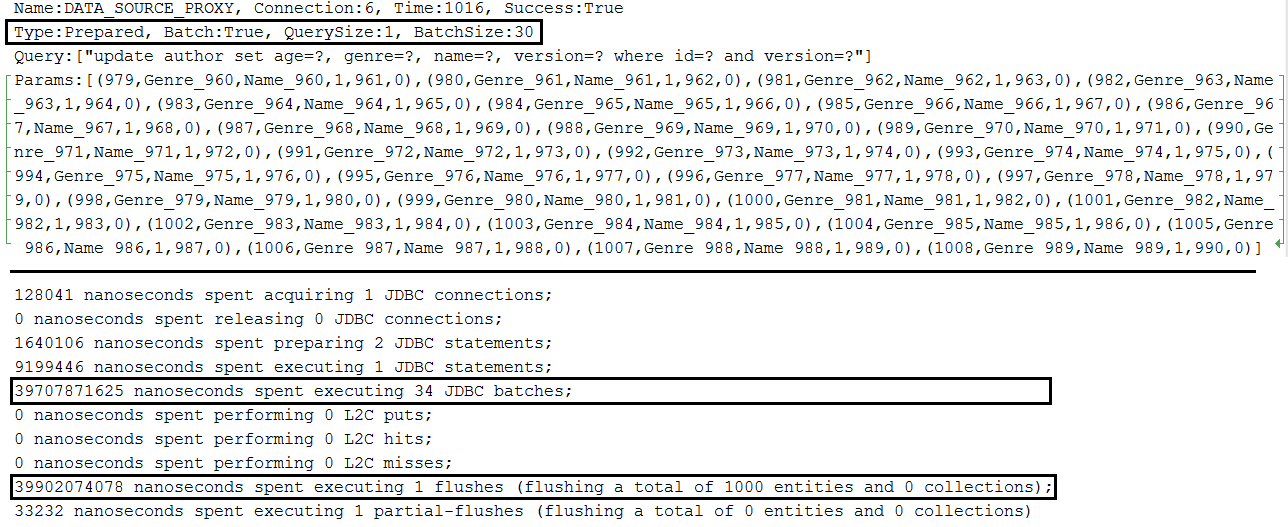
Output example for parent-child relationship: 
Description: Batch deletes that don't involve associations in MySQL.
Note: Spring deleteAllInBatch() and deleteInBatch() don't use delete batching and don't take advantage of automatic optimstic locking mechanism to prevent lost updates (eg, @Version is ignored). They rely on Query.executeUpdate() to trigger bulk operations. These operations are fast, but Hibernate doesn't know which entities are removed, therefore, the Persistence Context is not updated accordingly (it's up to you to flush (before delete) and close/clear (after delete) the Persistence Context accordingly to avoid issues created by unflushed (if any) or outdated (if any) entities). The first one ( deleteAllInBatch() ) simply triggers a delete from entity_name statement and is very useful for deleting all records. The second one ( deleteInBatch() ) triggers a delete from entity_name where id=? or id=? or id=? ... statement, therefore, is prone to cause issues if the generated DELETE statement exceedes the maximum accepted size. This issue can be controlled by deleting the data in chunks, relying on IN operator, and so on. Bulk operations are faster than batching which can be achieved via the deleteAll() , deleteAll(Iterable<? extends T> entities) or delete() method. Behind the scene, the two flavors of deleteAll() relies on delete() . The delete() / deleteAll() methods rely on EntityManager.remove() therefore the Persistence Context is synchronized accordingly. Moreover, if automatic optimstic locking mechanism (to prevent lost updates ) is enabled then it will be used.
Key points for regular delete batching:
deleteAll() , deleteAll(Iterable<? extends T> entities) or delete() methodapplication.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL, statements get rewritten into a single string buffer and sent in a single request)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))application.properties a setting for enabling batching for versioned entities during update and delete operations (entities that contains @Version for implicit optimistic locking); this setting is: spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true ; starting with Hibernate 5, this setting should be true by default Output example: 
Description: Batch deletes in MySQL via orphanRemoval=true .
Note: Spring deleteAllInBatch() and deleteInBatch() don't use delete batching and don't take advantage of cascading removal, orphanRemoval and automatic optimstic locking mechanism to prevent lost updates (eg, @Version is ignored). They rely on Query.executeUpdate() to trigger bulk operations. These operations are fast, but Hibernate doesn't know which entities are removed, therefore, the Persistence Context is not updated accordingly (it's up to you to flush (before delete) and close/clear (after delete) the Persistence Context accordingly to avoid issues created by unflushed (if any) or outdated (if any) entities). The first one ( deleteAllInBatch() ) simply triggers a delete from entity_name statement and is very useful for deleting all records. The second one ( deleteInBatch() ) triggers a delete from entity_name where id=? or id=? or id=? ... statement, therefore, is prone to cause issues if the generated DELETE statement exceedes the maximum accepted size. This issue can be controlled by deleting the data in chunks, relying on IN operator, and so on. Bulk operations are faster than batching which can be achieved via the deleteAll() , deleteAll(Iterable<? extends T> entities) or delete() method. Behind the scene, the two flavors of deleteAll() relies on delete() . The delete() / deleteAll() methods rely on EntityManager.remove() therefore the Persistence Context is synchronized accordingly. If automatic optimstic locking mechanism (to prevent lost updates ) is enabled then it will be used. Moreover, cascading removals and orphanRemoval works as well.
Key points for using deleteAll()/delete() :
Author entity and each author can have several Book ( one-to-many )orphanRemoval=true and CascadeType.ALLBook from the corresponding AuthororphanRemoval=true to enter into the scene; thanks to this setting, all disassociated books will be deleted; the generated DELETE statements are batched (if orphanRemoval is set to false , a bunch of updates will be executed instead of deletes)Author via the deleteAll() or delete() method (since we have dissaciated all Book , the Author deletion will take advantage of batching as well)ON DELETE CASCADE Description: Batch deletes in MySQL via ON DELETE CASCADE . Auto-generated database schema will contain the ON DELETE CASCADE directive.
Note: Spring deleteAllInBatch() and deleteInBatch() don't use delete batching and don't take advantage of cascading removal, orphanRemoval and automatic optimistic locking mechanism to prevent lost updates (eg, @Version is ignored), but both of them take advantage on ON DELETE CASCADE and are very efficient. They trigger bulk operations via Query.executeUpdate() , therefore, the Persistence Context is not synchronized accordingly (it's up to you to flush (before delete) and close/clear (after delete) the Persistence Context accordingly to avoid issues created by unflushed (if any) or outdated (if any) entities). The first one simply triggers a delete from entity_name statement, while the second one triggers a delete from entity_name where id=? or id=? or id=? ... إفادة. For delete in batches rely on deleteAll() , deleteAll(Iterable<? extends T> entities) or delete() method. Behind the scene, the two flavors of deleteAll() relies on delete() . Mixing batching with database automatic actions ( ON DELETE CASCADE ) will result in a partially synchronized Persistent Context.
النقاط الرئيسية:
Author entity and each author can have several Book ( one-to-many )orphanRemoval or set it to falseCascadeType.PERSIST and CascadeType.MERGE@OnDelete(action = OnDeleteAction.CASCADE) next to @OneToManyspring.jpa.properties.hibernate.dialect to org.hibernate.dialect.MySQL5InnoDBDialect (or, MySQL8Dialect )deleteFoo() methods that uses bulk and batching deletes as wellOutput example:

@NaturalId In Spring Boot Style Alternative implementation: In case that you want to avoid extending SimpleJpaRepository check this implementation.
Description: This is a SpringBoot application that maps a natural business key using Hibernate @NaturalId . This implementation allows us to use @NaturalId as it was provided by Spring.
النقاط الرئيسية:
Book ), mark the properties (business keys) that should act as natural IDs with @NaturalId ; commonly, there is a single such property, but multiple are suppored as well as here@NaturalId(mutable = false) and @Column(nullable = false, updatable = false, unique = true, ...)@NaturalId(mutable = true) and @Column(nullable = false, updatable = true, unique = true, ...)equals() and hashCode() using the natural id(s)@NoRepositoryBean interface ( NaturalRepository ) to define two methods, named findBySimpleNaturalId() and findByNaturalId()NaturalRepositoryImpl ) relying on Hibernate, Session , bySimpleNaturalId() and byNaturalId() methods@EnableJpaRepositories(repositoryBaseClass = NaturalRepositoryImpl.class) to register this implementation as the base classfindBySimpleNaturalId() or findByNaturalId()| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
Description: This is a Spring Boot application that uses P6Spy. P6Spy is a framework that enables database data to be seamlessly intercepted and logged with no code changes to the application.
النقاط الرئيسية:
pom.xml , add the P6Spy Maven dependencyapplication.properties , set up JDBC URL as, jdbc:p6spy:mysql://localhost:3306/db_usersapplication.properties , set up driver class name as, com.p6spy.engine.spy.P6SpyDriverspy.properties (this file contains P6Spy configurations); in this application, the logs will be outputed to console, but you can easy switch to a file; more details about P6Spy configurations can be found in documentation Output sample: 
OptimisticLockException Exception ( @Version ) Note: Optimistic locking mechanism via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occur, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
النقاط الرئيسية:
pom.xml , add the db-util dependencyOptimisticConcurrencyControlAspect bean@Transactional ) that is prone to throw (or that calls a method that is prone to throw (this method can be annotated with @Transactional )) an optimistic locking exception with @Retry(times = 10, on = OptimisticLockingFailureException.class) Output sample: 
OptimisticLockException Exception (Hibernate Version-less Optimistic Locking Mechanism)Note: Optimistic locking mechanism via Hibernate version-less doesn't work for detached entities (don't close the Persistent Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception (eg, in Spring Boot, OptimisticLockingFailureException ) via Hibernate version-less optimistic locking. When such exception occur, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
النقاط الرئيسية:
pom.xml , add the db-util library dependencyOptimisticConcurrencyControlAspect beanInventory ) with @DynamicUpdate and @OptimisticLocking(type = OptimisticLockType.DIRTY)@Transactional ) that is prone to throw (or that calls a method that is prone to throw (this method can be annotated with @Transactional )) an optimistic locking exception with @Retry(times = 10, on = OptimisticLockingFailureException.class)Note: You may also like to read the recipe, "How To Create DTO Via Spring Data Projections"
Description: This is an application sample that fetches only the needed columns from the database via Spring Data Projections (DTO) and enrich the result via virtual properties.
النقاط الرئيسية:
name and ageAuthorNameAge , use the @Value and Spring SpEL to point to a backing property from the domain model (in this case, the domain model property age is exposed via the virtual property years )AuthorNameAge , use the @Value and Spring SpEL to enrich the result with two virtual properties that don't have a match in the domain model (in this case, rank and books ) Output example: 
Description: Spring Data comes with the query creation mechanism for JPA that is capable to interpret a query method name and convert it into a SQL query in the proper dialect. This is possible as long as we respect the naming conventions of this mechanism. This is an application that exploit this mechanism to write queries that limit the result size. Basically, the name of the query method instructs Spring Data how to add the LIMIT (or similar clauses depending on the RDBMS) clause to the generated SQL queries.
النقاط الرئيسية:
AuthorRepository ) أمثلة:
- List<Author> findFirst5ByAge(int age);
- List<Author> findFirst5ByAgeGreaterThanEqual(int age);
- List<Author> findFirst5ByAgeLessThan(int age);
- List<Author> findFirst5ByAgeOrderByNameDesc(int age);
- List<Author> findFirst5ByGenreOrderByAgeAsc(String genre);
- List<Author> findFirst5ByAgeGreaterThanEqualOrderByNameAsc(int age);
- List<Author> findFirst5ByGenreAndAgeLessThanOrderByNameDesc(String genre, int age);
- List<AuthorDto> findFirst5ByOrderByAgeAsc();
- Page<Author> queryFirst10ByName(String name, Pageable p);
- Slice<Author> findFirst10ByName(String name, Pageable p);
The list of supported keywords is listed below: 
schema-*.sql In MySQL Note: As a rule, in real applications avoid generating schema via hibernate.ddl-auto or set it to validate . Use schema-*.sql file or better Flyway or Liquibase migration tools.
Description: This application is an example of using schema-*.sql to generate a schema(database) in MySQL.
النقاط الرئيسية:
application.properties , set the JDBC URL (eg, spring.datasource.url=jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=true )application.properties , disable DDL auto (just don't add explicitly the hibernate.ddl-auto setting)application.properties , instruct Spring Boot to initialize the schema from schema-mysql.sql fileschema-*.sql And Match Entities To Them Via @Table In MySQL Note: As a rule, in real applications avoid generating schema via hibernate.ddl-auto or set it to validate . Use schema-*.sql file or better Flyway or Liquibase .
Description: This application is an example of using schema-*.sql to generate two databases in MySQL. The databases are matched at entity mapping via @Table .
النقاط الرئيسية:
application.properties , set the JDBC URL without the database, eg, spring.datasource.url=jdbc:mysql://localhost:3306application.properties , disable DDL auto (just don't specify hibernate.ddl-auto )aaplication.properties , instruct Spring Boot to initialize the schema from schema-mysql.sql fileAuthor entity, specify that the corresponding table ( author ) is in the database authorsdb via @Table(schema="authorsdb")Book entity, specify that the corresponding table ( book ) is in the database booksdb via @Table(schema="booksdb")Output example:
Author results in the following SQL: insert into authorsdb.author (age, genre, name) values (?, ?, ?)Book results the following SQL: insert into booksdb.book (isbn, title) values (?, ?)Note: For web-applications, pagination should be the way to go, not streaming. But, if you choose streaming then keep in mind the golden rule: keep th result set as small as posible. Also, keep in mind that the Execution Plan might not be as efficient as when using SQL-level pagination.
Description: This application is an example of streaming the result set via Spring Data and MySQL. This example can be adopted for databases that fetches the entire result set in a single roundtrip causing performance penalties.
النقاط الرئيسية:
@Transactional(readOnly=true) )Integer.MIN_VALUE (recommended in MySQL))Statement fetch-size to Integer.MIN_VALUE , or add useCursorFetch=true to the JDBC URL and set Statement fetch-size to a positive integer (eg, 30)createDatabaseIfNotExist Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of migrating a MySQL database via Flyway when the database exists (it is created before migration via MySQL specific parameter, createDatabaseIfNotExist=true ).
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-autoapplication.properties , set the JDBC URL as follows: jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=trueclasspath:db/migrationV1.1__Description.sql , V1.2__Description.sql , ...spring.flyway.schemas Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of migrating a MySQL database when the database is created by Flyway via spring.flyway.schemas . In this case, the entities should be annotated with @Table(schema = "bookstoredb") or @Table(catalog = "bookstoredb") . Here, the database name is bookstoredb .
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-autoapplication.properties , set the JDBC URL as follows: jdbc:mysql://localhost:3306/application.properties , add spring.flyway.schemas=bookstoredb , where bookstoredb is the database that should be created by Flyway (feel free to add your own database name)@Table(schema/catalog = "bookstoredb")classpath:db/migrationV1.1__Description.sql , V1.2__Description.sql , ... Output of migration history example: 
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
Note: For production don't rely on hibernate.ddl-auto to create your schema. Remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of auto-creating and migrating schemas for MySQL and PostgreSQL. In addition, each data source uses its own HikariCP connection pool. In case of MySQL, where schema = database , we auto-create the schema ( authorsdb ) based on createDatabaseIfNotExist=true . In case of PostgreSQL, where a database can have multiple schemas, we use the default postgres database and auto-create in it the schema, booksdb . For this we rely on Flyway, which is capable to create a missing schema.
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , configure the JDBC URL for MySQL as, jdbc:mysql://localhost:3306/authorsdb?createDatabaseIfNotExist=true and for PostgreSQL as, jdbc:postgresql://localhost:5432/postgres?currentSchema=booksdbapplication.properties , set spring.flyway.enabled=false to disable default behaviorDataSource for MySQL and one for PostgreSQLFlywayDataSource for MySQL and one for PostgreSQLEntityManagerFactory for MySQL and one for PostgreSQLdbmigrationmysqldbmigrationpostgresql Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of auto-creating and migrating two schemas in PostgreSQL using Flyway. In addition, each data source uses its own HikariCP connection pool. In case of PostgreSQL, where a database can have multiple schemas, we use the default postgres database and auto-create two schemas, authors and books . For this we rely on Flyway, which is capable to create the missing schemas.
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , configure the JDBC URL for books as jdbc:postgresql://localhost:5432/postgres?currentSchema=books and for authors as jdbc:postgresql://localhost:5432/postgres?currentSchema=authorsapplication.properties , set spring.flyway.enabled=false to disable default behaviorDataSource , one for books and one for authorsFlywayDataSource , one for books and one for authorsEntityManagerFactory , one for books and one for authorsbooks , place the migration SQLs files in dbmigrationbooksauthors , place the migration SQLs files in dbmigrationauthorsJOIN FETCH an @ElementCollection Description: This application is an example applying JOIN FETCH to fetch an @ElementCollection .
النقاط الرئيسية:
@ElementCollection is loaded lazy, keep it lazyJOIN FETCH in the repository@Subselect ) in a Spring Boot Application Note: Consider using @Subselect only if using DTO, DTO and extra queries, or map a database view to an entity is not a solution.
Description: This application is an example of mapping an entity to a query via Hibernate, @Subselect . Mainly, we have two entities in a bidirectional one-to-many association. An Author has wrote several Book . The idea is to write a read-only query to fetch from Author only some fields (eg, DTO), but to have the posibility to call getBooks() and fetch the Book in a lazy manner as well. As you know, a classic DTO cannot be used, since such DTO is not managed and we cannot navigate the associations (don't support any managed associations to other entities). Via Hibernate @Subselect we can map a read-only and immutable entity to a query. This time, we can lazy navigate the associations.
النقاط الرئيسية:
Author (including association to Book )@Immutable since no write operations are allowed@Synchronize@Subselect to write the needed query, map an entity to an SQL queryDescription: This application is an example of using Hibernate soft deletes in a Spring Boot application.
النقاط الرئيسية:
abstract class BaseEntity with a field named deletedAuthor and Book entities) that should take advantage of soft deletes should extend BaseEntity@Where annotation like this: @Where(clause = "deleted = false")@SQLDelete annotation to trigger UPDATE SQLs in place of DELETE SQLs, as follows: @SQLDelete(sql = "UPDATE author SET deleted = true WHERE id = ?") Output example: 
DataSourceBuilder If you use the spring-boot-starter-jdbc or spring-boot-starter-data-jpa "starters", you automatically get a dependency to HikariCP
Note: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up HikariCP via DataSourceBuilder . The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users. Check the HickariCP report revealing the connection pool status.
النقاط الرئيسية:
@Bean that returns the DataSource programmaticallyDescription: Auditing is useful for maintaining history records. This can later help us in tracking user activities.
النقاط الرئيسية:
abstract base entity (eg, BaseEntity ) and annotate it with @MappedSuperclass and @EntityListeners({AuditingEntityListener.class})@CreatedDate protected LocalDateTime created;@LastModifiedDate protected LocalDateTime lastModified;@CreatedBy protected U createdBy;@LastModifiedBy protected U lastModifiedBy;@EnableJpaAuditing(auditorAwareRef = "auditorAware")AuditorAware (this is needed for persisting the user that performed the modification; use Spring Security to return the currently logged-in user)@Beanspring.jpa.hibernate.ddl-auto=create )Description: Auditing is useful for maintaining history records. This can later help us in tracking user activities.
النقاط الرئيسية:
@Audited@AuditTable to rename the table used for auditingValidityAuditStrategy for fast database reads, but slower writes (slower than the default DefaultAuditStrategy )Description: By default, the attributes of an entity are loaded eager (all at once). This application is an alternative to How To Use Hibernate Attribute Lazy Loading from here. This application uses a base class to isolate the attributes that should be loaded eagerly and subentities (entities that extends the base class) for isolating the attributes that should be loaded on demand.
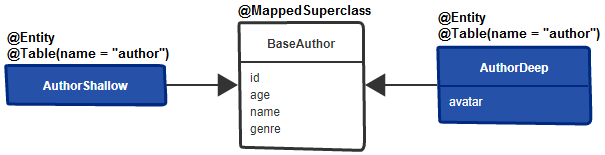
النقاط الرئيسية:
BaseAuthor , and annotate it with @MappedSuperclassAuthorShallow subentity of BaseAuthor and don't add any attribute in it (this will inherit the attributes from the superclass)AuthorDeep subentity of BaseAuthor and add to it the attributes that should be loaded on demand (eg, avatar )@Table(name = "author")AuthorShallowRepository and AuthorDeepRepositoryRun the following requests (via BookstoreController):
localhost:8080/authors/shallowlocalhost:8080/authors/deepCheck as well:
Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on constructor and Spring Data Query Builder Mechanism.
النقاط الرئيسية:
أنظر أيضا:
Dto Via Constructor Expression and JPQL
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
JOIN Description: Using JOIN is very useful for fetching DTOs (data that is never modified, not in the current or subsequent requests). For example, consider two entities, Author and Book in a lazy-bidirectional @OneToMany association. And, we want to fetch a subset of columns from the parent table ( author ) and a subset of columns from the child table ( book ). This job is a perfect fit for JOIN which can pick up columns from different tables and build a raw result set. This way we fetch only the needed data. Moreover, we may want to serve the result set in pages (eg, via LIMIT ). This application contains several approaches for accomplishing this task with offset pagination.
النقاط الرئيسية:
Page (with SELECT COUNT and COUNT(*) OVER() window function)Slice and ListDENSE_RANK() for avoiding the truncation of the result set (an author can be fetched with only a subset of his books)LEFT JOIN FETCHأنظر أيضا:
Description: Let's assume that we have two entities engaged in a one-to-many (or many-to-many) lazy bidirectional (or unidirectional) relationship (eg, Author has more Book ). And, we want to trigger a single SELECT that fetches all Author and the corresponding Book . This is a job for JOIN FETCH which is converted behind the scene into a INNER JOIN . Being an INNER JOIN , the SQL will return only Author that have Book . If we want to return all Author , including those that doesn't have Book , then we can rely on LEFT JOIN FETCH . Similar, we can fetch all Book , including those with no registered Author . This can be done via LEFT JOIN FETCH or LEFT JOIN .
النقاط الرئيسية:
Author and Book in a one-to-many lazy bidirectional relationship)LEFT JOIN FETCH to fetch all authors and books (fetch authors even if they don't have registered books)LEFT JOIN FETCH to fetch all books and authors (fetch books even if they don't have registered authors)JOIN VS. JOIN FETCHأنظر أيضا:
Description: This is an application meant to reveal the differences between JOIN and JOIN FETCH . The important thing to keep in mind is that, in case of LAZY fetching, JOIN will not be capable to initialize the associated collections along with their parent objects using a single SQL SELECT . On the other hand, JOIN FETCH is capable to accomplish this kind of task. But, don't underestimate JOIN , because JOIN is the proper choice when we need to combine/join the columns of two (or more) tables in the same query, but we don't need to initialize the associated collections on the returned entity (eg, very useful for fetching DTO).
النقاط الرئيسية:
Author and Book in a one-to-many lazy-bidirectional relationship)JOIN and JOIN FETCH to fetch an author including his booksJOIN to fetch a book (1)JOIN to fetch a book including its author (2)JOIN FETCH to fetch a book including its authorNotice that:
JOIN , fetching Book of Author requires additional SELECT statements being prone to N+1 performance penaltyJOIN (1), fetching Author of Book requires additional SELECT statements being prone to N+1 performance penaltyJOIN (2), fetching Author of Book works exactly as JOIN FETCH (requires a single SELECT )JOIN FETCH , fetching each Author of a Book requires a single SELECT Description: If, for some reason, you need an entity in your Spring projection (DTO), then this application shows you how to do it via an example. In this case, there are two entities, Author and Book , involved in a lazy bidirectional one-to-many association (it can be other association as well, or even no materialized association). And, we want to fetch in a Spring projection the authors as entities, Author , and the title of the books.
النقاط الرئيسية:
Author and Book in a one-to-many lazy bidirectional relationship)public Author getAuthor() and public String getTitle() Description: If, for some reason, you need an entity in your Spring projection (DTO), then this application shows you how to do it via an example. In this case, there are two entities, Author and Book , that have no materialized association between them, but, they share the genre attribute. We use this attribute to join authors with books via JPQL. And, we want to fetch in a Spring projection the authors as entities, Author , and the title of the books.
النقاط الرئيسية:
Author and Book )public Author getAuthor() and public String getTitle() Description: Let's assume that we have two entities, Author and Book . There is no materialized association between them, but, both entities shares an attribute named, genre . We want to use this attribute to join the tables corresponding to Author and Book , and fetch the result in a DTO. The result should contain the Author entity and only the title attribute from Book . Well, when you are in a scenario as here, it is strongly advisable to avoid fetching the DTO via constructor expression . This approach cannot fetch the data in a single SELECT , and is prone to N+1. Way better than this consists of using Spring projections, JPA Tuple or even Hibernate ResultTransformer . These approaches will fetch the data in a single SELECT . This application is a DON'T DO THIS example. Check the number of queries needed for fetching the data. In place, do it as here: Entity Inside Spring Projection (no association).
@ElementCollection Description: This application is an example of fetching a DTO that includes attributes from an @ElementCollection .
النقاط الرئيسية:
@ElementCollection is loaded lazy, keep it lazyJOIN in the repositorySet Of Associated Entities In @ManyToMany Association Via @OrderBy Description: In case of @ManyToMany association, we always should rely on Set (not on List ) for mapping the collection of associated entities (entities of the other parent-side). لماذا؟ Well, please see Prefer Set Instead of List in @ManyToMany Relationships. But, is well-known that HashSet doesn't have a predefined entry order of elements. If this is an issue then this application relies on @OrderBy which adds an ORDER BY clause in the SQL statement. The database will handle the ordering. Further, Hibernate will preserve the order via a LinkedHashSet .
This application uses two entities, Author and Book , involved in a lazy bidirectional many-to-many relationship. First, we fetch a Book by title. Further, we call getAuthors() to fetch the authors of this book. The fetched authors are ordered descending by name. The ordering is done by the database as a result of adding @OrderBy("name DESC") , and is preserved by Hibernate.
النقاط الرئيسية:
@OrderByHashSet , but doesn't provide consistency across all transition states (eg, transient state)LinkedHashSet instead of HashSet Note: Alternatively, we can use @OrderColumn . This gets materialized in an additional column in the junction table. This is needed for maintaining a permanent ordering of the related data.
Description: This is a sample application that shows how versioned ( @Version ) optimistic locking and detached entity works. Running the application will result in an optimistic locking specific exception (eg, the Spring Boot specific, OptimisticLockingFailureException ).
النقاط الرئيسية:
findById(1L) ; commit transaction and close the Persistence ContextfindById(1L) and update it; commit the transaction and close the Persistence Contextsave() and pass to it the detached entity; trying to merge ( EntityManager.merge() ) the entity will end up in an optimistic locking exception since the version of the detached and just loaded entity don't matchOptimisticLockException Shaped Via @Version Note: Optimistic locking via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. So, running the application should end up with a Spring specific ObjectOptimisticLockingFailureException exception.
النقاط الرئيسية:
@Transactional method used for updating data| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
TransactionTemplate After OptimisticLockException Exception ( @Version ) Note: Optimistic locking via @Version works for detached entities as well.
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occurs, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
النقاط الرئيسية:
pom.xml , add the db-util dependencyOptimisticConcurrencyControlAspect beanTransactionTemplateOptimisticLockException In Version-less Optimistic LockingNote: Version-less optimistic locking doesn't work for detached entities (do not close the Persistence Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. So, running the application should end up with a Spring specific ObjectOptimisticLockingFailureException exception.
النقاط الرئيسية:
@Transactional method used for updating dataTransactionTemplate After OptimisticLockException Shaped Via Hibernate Version-less Optimistic Locking MechanismNote: Version-less optimistic locking doesn't work for detached entities (do not close the Persistence Context).
Description: This is a Spring Boot application that simulates a scenario that leads to an optimistic locking exception. When such exception occur, the application retry the corresponding transaction via db-util library developed by Vlad Mihalcea.
النقاط الرئيسية:
pom.xml , add the db-util dependencyOptimisticConcurrencyControlAspect beanTransactionTemplateDescription: This is a sample application that shows how to take advantage of versioned optimistic locking and detached entities in HTTP long conversations. The climax consists of storing the detached entities across multiple HTTP requests. Commonly, this can be accomplished via HTTP session.
النقاط الرئيسية:
@Version@SessionAttributes for storing the detached entities Sample output (check the message caused by optimistic locking exception): 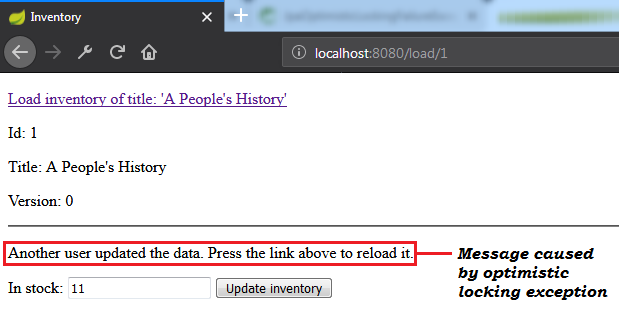
@Where Note: Rely on this approach only if you simply cannot use JOIN FETCH WHERE or @NamedEntityGraph .
Description: This application is a sample of using Hibernate @Where for filtering associations.
النقاط الرئيسية:
@Where(clause = "condition to be met") in entity (check the Author entity)Description: Batch inserts (in MySQL) in Spring Boot style.
النقاط الرئيسية:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=false Output example: 
COUNT(*) OVER And Return Page<entity> Via Extra Column Description: Typically, in offset pagination, there is one query needed for fetching the data and one for counting the total number of records. But, we can fetch this information in a single database rountrip via a SELECT COUNT subquery nested in the main SELECT . Even better, for databases vendors that support Window Functions there is a solution relying on COUNT(*) OVER() as in this application that uses this window function in a native query against MySQL 8. So, prefer this one instead of SELECT COUNT subquery.This application fetches data as Page<entity> via Spring Boot offset pagination, but, if the fetched data is read-only , then rely on Page<dto> as here.
النقاط الرئيسية:
PagingAndSortingRepository@Column(insertable = false, updatable = false)List<entity>List<entity> and Pageable to create a Page<entity>SELECT COUNT Subquery And Return List<entity> Via Extra Column Description: This application fetches data as List<entity> via Spring Boot offset pagination. The SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT . Therefore, there will be a single database roundtrip instead of two (typically, one query is needed for fetching the data and one for counting the total number of records).
النقاط الرئيسية:
PagingAndSortingRepositoryentity , add an extra column for representing the total number of records and annotate it as @Column(insertable = false, updatable = false)SELECT COUNT subquery) into a List<entity>SELECT COUNT Subquery And Return List<projection> That Maps Entities And The Total Number Of Records Via Projection Description: This application fetches data as List<projection> via Spring Boot offset pagination. The projection maps the entity and the total number of records. This information is fetched in a single database rountrip because the SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT . Therefore, there will be a single database roundtrip instead of two (typically, there is one query needed for fetching the data and one for counting the total number of records). Use this approch only if the fetched data is not read-only . Otherwise, prefer List<dto> as here.
النقاط الرئيسية:
PagingAndSortingRepositorySELECT COUNT subquery) into a List<projection>COUNT(*) OVER And Return List<entity> Via Extra Column Description: Typically, in offset pagination, there is one query needed for fetching the data and one for counting the total number of records. But, we can fetch this information in a single database rountrip via a SELECT COUNT subquery nested in the main SELECT . Even better, for databases vendors that support Window Functions there is a solution relying on COUNT(*) OVER() as in this application that uses this window function in a native query against MySQL 8. So, prefer this one instead of SELECT COUNT subquery.This application fetches data as List<entity> via Spring Boot offset pagination, but, if the fetched data is read-only , then rely on List<dto> as here.
النقاط الرئيسية:
PagingAndSortingRepositoryentity , add an extra column for representing the total number of records and annotate it as @Column(insertable = false, updatable = false)COUNT(*) OVER subquery) into a List<entity>| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
SELECT COUNT Subquery And Return Page<entity> Via Extra Column Description: This application fetches data as Page<entity> via Spring Boot offset pagination. Use this only if the fetched data will be modified. Otherwise, fetch Page<dto> as here. The SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT . Therefore, there will be a single database roundtrip instead of two (typically, there is one query needed for fetching the data and one for counting the total number of records).
النقاط الرئيسية:
PagingAndSortingRepository@Column(insertable = false, updatable = false)List<entity>List<entity> and Pageable to create a Page<entity>SELECT COUNT Subquery And Return Page<projection> That Maps Entities And The Total Number Of Records Via Projection Description: This application fetches data as Page<projection> via Spring Boot offset pagination. The projection maps the entity and the total number of records. This information is fetched in a single database rountrip because the SELECT COUNT triggered for counting the total number of records is a subquery of the main SELECT .
النقاط الرئيسية:
PagingAndSortingRepositoryList<projection>List<projection> and Pageable to create a Page<projection>COUNT(*) OVER And Return Page<dto> Description: Typically, in offset pagination, there is one query needed for fetching the data and one for counting the total number of records. But, we can fetch this information in a single database rountrip via a SELECT COUNT subquery nested in the main SELECT . Even better, for databases vendors that support Window Functions there is a solution relying on COUNT(*) OVER() as in this application that uses this window function in a native query against MySQL 8. So, prefer this one instead of SELECT COUNT subquery . This application return a Page<dto> .
النقاط الرئيسية:
PagingAndSortingRepositoryList<dto>List<dto> and Pageable to create a Page<dto> مثال:
Slice<entity> / Slice<dto> Via fetchAll / fetchAllDto Story : Spring Boot provides an offset based built-in paging mechanism that returns a Page or Slice . Each of these APIs represents a page of data and some metadata. The main difference is that Page contains the total number of records, while Slice can only tell if there is another page available. For Page , Spring Boot provides a findAll() method capable to take as arguments a Pageable and/or a Specification or Example . In order to create a Page that contains the total number of records, this method triggers an SELECT COUNT extra-query next to the query used to fetch the data of the current page . This can be a performance penalty since the SELECT COUNT query is triggered every time we request a page. In order to avoid this extra-query, Spring Boot provides a more relaxed API, the Slice API. Using Slice instead of Page removes the need of this extra SELECT COUNT query and returns the page (records) and some metadata without the total number of records. So, while Slice doesn't know the total number of records, it still can tell if there is another page available after the current one or this is the last page. The problem is that Slice work fine for queries containing the SQL, WHERE clause (including those that uses the query builder mechanism built into Spring Data), but it doesn't work for findAll() . This method will still return a Page instead of Slice therefore the SELECT COUNT query is triggered for Slice<T> findAll(...); .
Workaround: The trick is to simply define a method named fetchAll() that uses JPQL and Pageable to return Slice<entity> , and a method named fetchAllDto() that uses JPQL and Pageable as well to return Slice<dto> . So, avoid naming the method findAll() .
Usage example:
public Slice<Author> fetchNextSlice(int page, int size) {
return authorRepository.fetchAll(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "age")));
}
public Slice<AuthorDto> fetchNextSliceDto(int page, int size) {
return authorRepository.fetchAllDto(PageRequest.of(page, size, new Sort(Sort.Direction.ASC, "age")));
}

Description: This application is a proof of concept for using Spring Projections(DTO) and inclusive full joins written in native SQL (for MySQL).
النقاط الرئيسية:
Author and Book in a lazy bidirectional @OneToMany relationship)resources/data-mysql.sql )AuthorNameBookTitle.java )EhCache ) Description: This application is a sample of declaring an immutable entity. Moreover, the immutable entity will be stored in Second Level Cache via EhCache implementation.
Key points of declaring an immutable entity:
@Immutable (org.hibernate.annotations.Immutable)hibernate.cache.use_reference_entries configuration to trueDataSourceBuilder If you use the spring-boot-starter-jdbc or spring-boot-starter-data-jpa "starters", you automatically get a dependency to HikariCP
Note: The best way to tune the connection pool parameters consist in using Flexy Pool by Vlad Mihalcea. Via Flexy Pool you can find the optim settings that sustain high-performance of your connection pool.
Description: This is a kickoff application that set up HikariCP via DataSourceBuilder . The jdbcUrl is set up for a MySQL database. For testing purposes, the application uses an ExecutorService for simulating concurrent users. Check the HickariCP report revealing the connection pool status.
النقاط الرئيسية:
@Bean that returns the DataSource programmatically Output sample:
@NaturalIdCache For Skipping The Entity Identifier Retrieval Description: This is a SpringBoot - MySQL application that maps a natural business key using Hibernate @NaturalId . This implementation allows us to use @NaturalId as it was provided by Spring. Moreover, this application uses Second Level Cache ( EhCache ) and @NaturalIdCache for skipping the entity identifier retrieval from the database.
النقاط الرئيسية:
EhCache )@NaturalIdCache for caching natural ids@Cache(usage = CacheConcurrencyStrategy.READ_WRITE, region = "Book") for caching entites as well Output sample (for MySQL with IDENTITY generator, @NaturalIdCache and @Cache ): 
@PostLoad Description: This application is an example of calculating a non-persistent property of an entity based on the persistent entity attributes. In this case, we will use JPA, @PostLoad .
النقاط الرئيسية:
@Transient@PostLoad that calculates this non-persistent property based on the persistent entity attributes@Generated Description: This application is an example of calculating an entity persistent property at INSERT and/or UPDATE time via Hibernate, @Generated .
النقاط الرئيسية:
Calculate at INSERT time:
@Generated(value = GenerationTime.INSERT)@Column(insertable = false) Calculate at INSERT and UPDATE time:
@Generated(value = GenerationTime.ALWAYS)@Column(insertable = false, updatable = false)Further, apply:
Method 1:
columnDefinition element of @Column to specify as an SQL query expression the formula for calculating the persistent propertyMethod 2:
CREATE TABLE Note: In production, you should not rely on columnDefinition . You should disable hibernate.ddl-auto (by omitting it) or set it to validate , and add the SQL query expression in CREATE TABLE (in this application, check the discount column in CREATE TABLE , file schema-sql.sql ). Nevertheless, not even schema-sql.sql is ok in production. The best way is to rely on Flyway or Liquibase.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
@Formula Description: This application is an example of calculating a non-persistent property of an entity based on the persistent entity attributes. In this case, we will use Hibernate, @Formula .
النقاط الرئيسية:
@Transient@Formula@Formula add the SQL query expression that calculates this non-persistent property based on the persistent entity attributescreated , createdBy , lastModified And lastModifiedBy In Entities Via HibernateNote: The same thing can be obtained via Spring Data JPA auditing as here.
Description: This application is an example of adding in an entity the fields, created , createdBy , lastModified and lastModifiedBy via Hibernate support. These fields will be automatically generated/populated.
النقاط الرئيسية:
abstract class (eg, BaseEntity ) annotated with @MappedSuperclassabstract class, define a field named created and annotate it with the built-in @CreationTimestamp annotationabstract class, define a field named lastModified and annotate it with the built-in @UpdateTimestamp annotationabstract class, define a field named createdBy and annotate it with the @CreatedBy annotationabstract class, define a field named lastModifiedBy and annotate it with the @ModifiedBy annotation@CreatedBy annotation via AnnotationValueGeneration@ModifiedBy annotation via AnnotationValueGenerationcreated , createdBy , lastModified and lastModifiedBy will extend the BaseEntityschema-mysql.sql )Description: Auditing is useful for maintaining history records. This can later help us in tracking user activities.
النقاط الرئيسية:
@Audited@AuditTable to rename the table used for auditingValidityAuditStrategy for fast database reads, but slower writes (slower than the default DefaultAuditStrategy )spring.jpa.hibernate.ddl-auto or set it to validate for avoiding schema generated from JPA annotationsschema-mysql.sql and provide the SQL statements needed by Hibernate Enversspring.jpa.properties.org.hibernate.envers.default_catalog for MySQL or spring.jpa.properties.org.hibernate.envers.default_schema for the restDataSource Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is a kickoff for setting Flyway and MySQL DataSource programmatically.
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateDataSource and Flyway programmaticallypostgres And Schema public Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of migrating a PostgreSQL database via Flyway for the default database postgres and schema public .
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , set the JDBC URL as follows: jdbc:postgresql://localhost:5432/postgresclasspath:db/migrationV1.1__Description.sql , V1.2__Description.sql , ...postgres And Schema Created Via spring.flyway.schemas Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of migrating a schema ( bookstore ) created by Flyway via spring.flyway.schemas in the default postgres database. In this case, the entities should be annotated with @Table(schema = "bookstore") .
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , set the JDBC URL as follows: jdbc:postgresql://localhost:5432/postgresapplication.properties , add spring.flyway.schemas=bookstore , where bookstore is the schema that should be created by Flyway in the postgres database (feel free to add your own database name)@Table(schema = "bookstore")classpath:db/migrationV1.1__Description.sql , V1.2__Description.sql , ...DataSource Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is a kickoff for setting Flyway and PostgreSQL DataSource programmatically.
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateDataSource and Flyway programmatically Note: For production, don't rely on hibernate.ddl-auto (or counterparts) to export schema DDL to the database. Simply remove (disable) hibernate.ddl-auto or set it to validate . Rely on Flyway or Liquibase.
Description: This application is an example of auto-creating and migrating two databases in MySQL using Flyway. In addition, each data source uses its own HikariCP connection pool. In case of MySQL, where a database is the same thing with schema, we create two databases, authorsdb and booksdb .
النقاط الرئيسية:
pom.xml , add the Flyway dependencyspring.jpa.hibernate.ddl-auto or set it to validateapplication.properties , configure the JDBC URL for booksdb as jdbc:mysql://localhost:3306/booksdb?createDatabaseIfNotExist=true and for authorsdb as jdbc:mysql://localhost:3306/authorsdb?createDatabaseIfNotExist=trueapplication.properties , set spring.flyway.enabled=false to disable default behaviorDataSource , one for booksdb and one for authorsdbFlywayDataSource , one for booksdb and one for authorsdbEntityManagerFactory , one for booksdb and one for authorsdbbooksdb , place the migration SQLs files in dbmigrationbooksdbauthorsdb , place the migration SQLs files in dbmigrationauthorsdbhi/lo Algorithm And External Systems Issue Description: This is a Spring Boot sample that exemplifies how the hi/lo algorithm may cause issues when the database is used by external systems as well. Such systems can safely generate non-duplicated identifiers (eg, for inserting new records) only if they know about the hi/lo presence and its internal work. So, better rely on pooled or pooled-lo algorithm which doesn't cause such issues.
النقاط الرئيسية:
SEQUENCE generator type (eg, in PostgreSQL)hi/lo algorithm as in Author.java entityhi/loNEXTVAL('hilo_sequence') and is not aware of hi/lo presence and/or behavior) Output sample: Running this application should result in the following error:
ERROR: duplicate key value violates unique constraint "author_pkey"
Detail: Key (id)=(2) already exists.
pooled Algorithm Note: Rely on pooled-lo or pooled especially if, beside your application, external systems needs to insert rows in your tables. Don't rely on hi/lo since, in such cases, it may cause errors resulted from generating duplicated identifiers.
Description: This is a Spring Boot example of using the pooled algorithm. The pooled is an optimization of hi/lo . This algorithm fetched from the database the current sequence value as the top boundary identifier (the current sequence value is computed as the previous sequence value + increment_size ). This way, the application will use in-memory identifiers generated between the previous top boundary exclusive (aka, lowest boundary) and the current top boundary inclusive.
Key points:
SEQUENCE generator type (eg, in PostgreSQL)pooled algorithm as in Author.java entitypooledNEXTVAL('hilo_sequence') and is not aware of pooled presence and/or behavior) Conclusion: In contrast to the classical hi/lo algorithm, the Hibernate pooled algorithm doesn't cause issues to external systems that wants to interact with our tables. In other words, external systems can concurrently insert rows in the tables relying on pooled algorithm. Nevertheless, old versions of Hibernate can raise exceptions caused by INSERT statements triggered by external systems that uses the lowest boundary as identifier. This is a good reason to update to Hibernate latest versions (eg, Hibernate 5.x), which have fixed this issue.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
pooled-lo Algorithm Note: Rely on pooled-lo or pooled especially if, beside your application, external systems needs to insert rows in your tables. Don't rely on hi/lo since, in such cases, it may cause errors resulted from generating duplicated identifiers.
Description: This is a Spring Boot example of using the pooled-lo algorithm. The pooled-lo is an optimization of hi/lo similar with pooled . Only that, the strategy of this algorithm fetches from the database the current sequence value and use it as the in-memory lowest boundary identifier. The number of in-memory generated identifiers is equal to increment_size .
Key points:
SEQUENCE generator type (eg, in PostgreSQL)pooled-lo algorithm as in Author.java entitypooled-loNEXTVAL('hilo_sequence') and is not aware of pooled-lo presence and/or behavior)@BatchSize Description: This application uses Hibernate specific @BatchSize at class/entity-level and collection-level. Consider Author and Book entities invovled in a bidirectional-lazy @OneToMany association.
First use case fetches all Author entities via a SELECT query. Further, calling the getBooks() method of the first Author entity will trigger another SELECT query that initializes the collections of the first three Author entities returned by the previous SELECT query. This is the effect of @BatchSize at Author 's collection-level.
Second use case fetches all Book entities via a SELECT query. Further, calling the getAuthor() method of the first Book entity will trigger another SELECT query that initializes the authors of the first three Book entities returned by the previous SELECT query. This is the effect of @BatchSize at Author class-level.
Note: Fetching associated collections in the same query with their parent can be done via JOIN FETCH or entity graphs as well. Fetching children with their parents in the same query can be done via JOIN FETCH , entity graphs and JOIN as well.
Key points:
Author and Book are in a lazy relationship (eg, @OneToMany bidirectional relationship)Author entity is annotated with @BatchSize(size = 3)Author 's collection is annotated with @BatchSize(size = 3)@NamedEntityGraph ) In Spring Boot Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. . More details here.
Description: This is a sample application of using entity graphs in Spring Boot.
Key points:
Author and Book , involved in a lazy bidirectional @OneToMany associationAuthor entity use the @NamedEntityGraph to define the entity graph (eg, load in a single SELECT the authors and the associatated books)AuthorRepositry rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous step Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. . More details here.
Description: This is a sample application of using entity sub-graphs in Spring Boot. There is one example based on @NamedSubgraph and one based on the dot notation (.) in an ad-hoc entity graph .
Key points:
Author , Book and Publisher ( Author and Book are involved in a lazy bidirectional @OneToMany relationship, Book and Publisher are also involved in a lazy bidirectional @OneToMany relationship; between Author and Publisher there is no relationship) Using @NamedSubgraph
Author entity define an entity graph via @NamedEntityGraph ; load the authors and the associatated books and use @NamedSubgraph to define a sub-graph for loading the publishers associated with these booksAuthorRepository rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous stepUsing the dot notation (.)
PublisherRepository define an ad-hoc entity graph that fetches all publishers with associated books, and further, the authors associated with these books (eg, @EntityGraph(attributePaths = {"books.author"}) . Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. . More details here.
Description: This is a sample application of defining ad-hoc entity graphs in Spring Boot.
النقاط الرئيسية:
Author and Book , involved in a lazy bidirectional @OneToMany relationshipSELECT the authors and the associatated booksAuthorRepository rely on Spring @EntityGraph(attributePaths = {"books"}) annotation to indicate the ad-hoc entity graph@Basic Attributes In Hibernate And Spring Boot Note: In a nutshell, entity graphs (aka, fetch plans ) is a feature introduced in JPA 2.1 that help us to improve the performance of loading entities. Mainly, we specify the entity's related associations and basic fields that should be loaded in a single SELECT statement. We can define multiple entity graphs for the same entity and chain any number of entities and even use sub-graphs to create complex fetch plans . To override the current FetchType semantics there are properties that can be set:
Fetch Graph (default), javax.persistence.fetchgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated as FetchType.LAZY regardless of the default/explicit FetchType .
Load Graph , javax.persistence.loadgraph
The attributes present in attributeNodes are treated as FetchType.EAGER . The remaining attributes are treated according to their specified or default FetchType .
Nevertheless, the JPA specs doesn't apply in Hibernate for the basic ( @Basic ) attributes. In other words, by default, attributes are annotated with @Basic which rely on the default fetch policy. The default fetch policy is FetchType.EAGER . These attributes are also loaded in case of fetch graph even if they are not explicitly specified via @NamedAttributeNode . Annotating the basic attributes that should not be fetched with @Basic(fetch = FetchType.LAZY) it is not enough. Both, fetch graph and load graph will ignore these settings as long as we don't add bytecode enhancement as well.
The main drawback consists of the fact the these basic attributes are fetched LAZY by all other queries (eg, findById() ) not only by the queries using the entity graph, and most probably, you will not want this behavior.
Description: This is a sample application of using entity graphs with @Basic attributes in Spring Boot.
Key points:
Author and Book , involved in a lazy bidirectional @OneToMany associationAuthor entity use the @NamedEntityGraph to define the entity graph (eg, load the authors names (only the name basic attribute; ignore the rest) and the associatated books)@Basic(fetch = FetchType.LAZY)AuthorRepository rely on Spring @EntityGraph annotation to indicate the entity graph defined at the previous stepSoftDeleteRepository In Spring Boot ApplicationNote: Spring Data built-in support for soft deletes is discussed in DATAJPA-307.
Description: This application is an example of implementing soft deletes in Spring Data style via a repository named, SoftDeleteRepository .
Key points:
abstract class, BaseEntity , annotated with @MappedSuperclassBaseEntity define a flag-field named deleted (default this field to false or in other words, not deleted)BaseEntity classs@NoRepositoryBean named SoftDeleteRepository and extend JpaRepositorySoftDeleteRepository Output example:
SKIP_LOCKED In MySQL 8 Description: This application is an example of how to implement concurrent table based queue via SKIP_LOCKED in MySQL 8. SKIP_LOCKED can skip over locks achieved by other concurrent transactions, therefore is a great choice for implementing job queues. In this application, we run two concurrent transactions. The first transaction will lock the records with ids 1, 2 and 3. The second transaction will skip the records with ids 1, 2 and 3 and will lock the records with ids 4, 5 and 6.
Key points:
Book entity)BookRepository setup @Lock(LockModeType.PESSIMISTIC_WRITE)BookRepository use @QueryHint to setup javax.persistence.lock.timeout to SKIP_LOCKEDorg.hibernate.dialect.MySQL8Dialect dialectSKIP_LOCKEDSKIP_LOCKED In PostgreSQL Description: This application is an example of how to implement concurrent table based queue via SKIP_LOCKED in PostgreSQL. SKIP_LOCKED can skip over locks achieved by other concurrent transactions, therefore is a great choice for implementing job queues. In this application, we run two concurrent transactions. The first transaction will lock the records with ids 1, 2 and 3. The second transaction will skip the records with ids 1, 2 and 3 and will lock the records with ids 4, 5 and 6.
Key points:
Book entity)BookRepository setup @Lock(LockModeType.PESSIMISTIC_WRITE)BookRepository use @QueryHint to setup javax.persistence.lock.timeout to SKIP_LOCKEDorg.hibernate.dialect.PostgreSQL95Dialect dialectSKIP_LOCKEDJOINED Description: This application is a sample of JPA Join Table inheritance strategy ( JOINED )
Key points:
@Inheritance(strategy=InheritanceType.JOINED)@PrimaryKeyJoinColumn| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
TABLE_PER_CLASS Description: This application is a sample of JPA Table-per-class inheritance strategy ( TABLE_PER_CLASS )
Key points:
IDENTITY generator@Inheritance(strategy=InheritanceType.TABLE_PER_CLASS)@MappedSuperclass Description: This application is a sample of using the JPA @MappedSuperclass .
النقاط الرئيسية:
abstract , and is annotated with @MappedSuperclass@MappedSuperclass is the proper alternative to the JPA table-per-class inheritance strategyNote: Hibernate5Module is an add-on module for Jackson JSON processor which handles Hibernate datatypes; and specifically aspects of lazy-loading .
Description: By default, in Spring Boot, the Open Session in View anti-pattern is enabled. Now, imagine a lazy relationship (eg, @OneToMany ) between two entities, Author and Book (an author has associated more books). Next, a REST controller endpoint fetches an Author without the associated Book . But, the View (more precisely, Jackson), forces the lazy loading of the associated Book as well. Since OSIV will supply the already opened Session , the Proxy initializations take place successfully.
Of course, the correct decision is to disable OSIV by setting it to false , but this will not stop Jackson to try to force the lazy initialization of the associated Book entities. Running the code again will result in an exception of type: Could not write JSON: failed to lazily initialize a collection of role: com.bookstore.entity.Author.books, could not initialize proxy - no Session; nested exception is com.fasterxml.jackson.databind.JsonMappingException: failed to lazily initialize a collection of role: com.bookstore.entity.Author.books, could not initialize proxy - no Session .
Well, among the Hibernate5Module features we have support for dealing with this aspect of lazy loading and eliminate this exception. Even if OSIV will continue to be enabled (not recommended), Jackson will not use the Session opened via OSIV.
Key points:
pom.xml@Bean that returns an instance of Hibernate5ModuleAuthor bean with @JsonInclude(Include.NON_EMPTY) to exclude null or what is considered empty from the returned JSON Note: The presence of Hibernate5Module instructs Jackson to initialize the lazy associations with default values (eg, a lazy associated collection will be initialized with null ). Hibernate5Module doesn't work for lazy loaded attributes. For such case consider this item.
profileSQL=true In MySQL Description: View the prepared statement binding parameters via profileSQL=true in MySQL.
Key points:
application.properties append logger=Slf4JLogger&profileSQL=true to the JDBC URL (eg, jdbc:mysql://localhost:3306/bookstoredb?createDatabaseIfNotExist=true&logger=Slf4JLogger&profileSQL=true ) Output sample: 
Description: This application is an example of shuffling small results sets. DO NOT USE this technique for large results sets, since is extremely expensive.
Key points:
SELECT query and append to it ORDER BY RAND()RAND() (eg, in PostgreSQL is random() ) Description: Commonly, deleting a parent and the associated children via CascadeType.REMOVE and/or orphanRemoval=true involved several SQL statements (eg, each child is deleted in a dedicated DELETE statement). When the number of entities is significant, this is far from being efficient, therefore other approaches should be employed.
Consider Author and Book in a bidirectional-lazy @OneToMany association. This application exposes the best way to delete the parent(s) and the associated children in four scenarios listed below. These approaches relies on bulk deletions, therefore they are not useful if you want the deletions to take advantage of automatic optimistic locking mechanisms (eg, via @Version ):
Best way to delete author(s) and the associated books via bulk deletions when:
Author is in Persistent Context, no BookAuthor are in the Persistent Context, no BookAuthor and the associated Book are in Persistent ContextAuthor or Book is in Persistent Context Note: The most efficient way to delete all entities via a bulk deletion can be done via the built-in deleteAllInBatch() .
Description: Bulk operations (updates and deletes) are faster than batching, can benefit from indexing, but they have three main drawbacks:
@Version is ignored), therefore the lost updates are not prevented (it is advisable to signal these updates by explicitly incrementing version (if any is present))CascadeType.REMOVE ) and orphanRemoval This application provides examples of bulk updates for Author and Book entities (between Author and Book there is a bidirectional lazy @OneToMany association). Both, Author and Book , has a version field.
@OneToMany And Prefer Bidirectional @OneToMany Relationship Description: As a rule of thumb, unidirectional @OneToMany association is less efficient than the bidirectional @OneToMany or the unidirectional @ManyToOne associations. This application is a sample that exposes the DML statements generated for reads, writes and removal operations when the unidirectional @OneToMany mapping is used.
Key points:
@OneToMany is less efficient than bidirectional @OneToMany association@OrderColumn come with some optimizations for removal operations but is still less efficient than bidirectional @OneToMany association@JoinColumn eliminates the junction table but is still less efficient than bidirectional @OneToMany associationSet instead of List or bidirectional @OneToMany with @JoinColumn relationship (eg, @ManyToOne @JoinColumn(name = "author_id", updatable = false, insertable = false) ) still performs worse than bidirectional @OneToMany associationWHERE / HAVING Clause Description: This application is an example of using subqueries in JPQL WHERE clause (you can easily use it in HAVING clause as well).
Key points:
Keep in mind that subqueries and joins queries may or may not be semantically equivalent (joins may returns duplicates that can be removed via DISTINCT ).
Even if the Execution Plan is specific to the database, historically speaking joins are faster than subqueries among different databases, but this is not a rule (eg, the amount of data may significantly influence the results). Of course, do not conclude that subqueries are just a replacement for joins that doesn't deserve attention. Tuning subqueries can increases their performance as well, but this is an SQL wide topic. So, benchmark! Benchmark! Benchmark!
As a rule of thumb, prefer subqueries only if you cannot use joins, or if you can prove that they are faster than the alternative joins.
WHERE Part Of JPQL Query And JPA 2.1 Note: Using SQL functions in SELECT part (not in WHERE part) of the query can be done as here.
Description: Starting with JPA 2.1, a JPQL query can call SQL functions in the WHERE part via function() . This application is an example of calling the MySQL, concat_ws function, but user defined (custom) functions can be used as well.
Key points:
function()| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
Description: This application is an example of calling a MySQL stored procedure that returns a value (eg, an Integer ).
النقاط الرئيسية:
@NamedStoredProcedureQuery to shape the stored procedure in the entity@Procedure in repository Description: This application is an example of calling a MySQL stored procedure that returns a result set. The application fetches entities (eg, List<Author> ) and DTO (eg, List<AuthorDto> ).
Key points:
EntiyManager since Spring Data @Procedure will not workDescription: This application is an example of calling a MySQL stored procedure that returns a result set (entity or DTO) via a native query.
Key points:
@Query(value = "{CALL FETCH_AUTHOR_BY_GENRE (:p_genre)}", nativeQuery = true)JdbcTemplate Note: Most probably you'll like to process the result set via BeanPropertyRowMapper as here. This is less verbose than the approach used here. Nevertheless, this approach is useful to understand how the result set looks like.
Description: This application is an example of calling a MySQL stored procedure that returns a result set via JdbcTemplate .
Key points:
JdbcTemplate and SimpleJdbcCallDescription: This application is an example of retrieving the database auto-generated primary keys.
Key points:
getId()JdbcTemplateSimpleJdbcInsert Description: A Hibernate proxy can be useful when a child entity can be persisted with a reference to its parent ( @ManyToOne or @OneToOne association). In such cases, fetching the parent entity from the database (execute the SELECT statement) is a performance penalty and a pointless action. Hibernate can set the underlying foreign key value for an uninitialized proxy. This topic is discussed here.
A proxy can be unproxied via Hibernate.unproxy() . This method is available starting with Hibernate 5.2.10.
النقاط الرئيسية:
JpaRepository#getOne()Hibernate.unproxy()Boolean To Yes/No Via AttributeConverter Description: This application is an example of converting a Boolean to Yes / No strings via AttributeConverter . This kind of conversions are needed when we deal with legacy databases that connot be changed. In this case, the legacy database stores the booleans as Yes / No .
Key points:
AttributeConverter@OManyToOne Note: The @ManyToOne association maps exactly to the one-to-many table relationship. The underlying foreign key is under child-side control in unidirectional or bidirectional relationship.
Description: This application shows that using only @ManyToOne is quite efficient. On the other hand, using only @OneToMany is far away from being efficient. Always, prefer bidirectional @OneToMany or unidirectional @ManyToOne . Consider two entities, Author and Book in a unidirectional @ManyToOne relationship.
Key points:
JOIN FETCH And Pageable Pagination Description: Trying to combine JOIN FETCH / LEFT JOIN FETCH and Pageable results in an exception of type org.hibernate.QueryException: query specified join fetching, but the owner of the fetched association was not present in the select list . This application is a sample of how to avoid this exception.
Key points:
countQuery Note: Fixing the above exception will lead to an warning of type HHH000104, firstResult / maxResults specified with collection fetch; applying in memory! . If this warning is a performance issue, and most probably it is, then follow by reading here.
Description: HHH000104 is a Hibernate warning that tell us that pagination of a result set is tacking place in memory. For example, consider the Author and Book entities in a lazy-bidirectional @OneToMany association and the following query:
@Transactional
@Query(value = "SELECT a FROM Author a LEFT JOIN FETCH a.books WHERE a.genre = ?1",
countQuery = "SELECT COUNT(a) FROM Author a WHERE a.genre = ?1")
Page<Author> fetchWithBooksByGenre(String genre, Pageable pageable);
Calling fetchWithBooksByGenre() works fine only that the following warning is signaled: HHH000104: firstResult / maxResults specified with collection fetch; applying in memory! Obviously, having pagination in memory cannot be good from performance perspective. This application implement a solution for moving pagination at database-level.
Key points:
Page of entities in read-write or read-only modeSlice or List of entities in read-write or read-only mode| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
@Transactional(readOnly=true) Actually Do Description: This application is meant to reveal what is the difference between @Transactional(readOnly = false) and @Transactional(readOnly = true) . In a nuthsell, readOnly = false (default) fetches entites in read-write mode (managed). Before Spring 5.1, readOnly = true just set FlushType.MANUAL/NEVER , therefore the automatic dirty checking mechanism will not take action since there is no flush. In other words, Hibernate keep in the Persistent Context the fetched entities and the hydrated (loaded) state. By comparing the entity state with the hydrated state, the dirty checking mechanism can decide to trigger UPDATE statements in our behalf. But, the dirty checking mechanism take place at flush time, therefore, without a flush, the hydrated state is kept in Persistent Context for nothing, representing a performance penalty. Starting with Spring 5.1, the read-only mode is propagated to Hibernate, therefore the hydrated state is discarded immediately after loading the entities. Even if the read-only mode discards the hydrated state the entities are still loaded in the Persistent Context, therefore, for read-only data, relying on DTO (Spring projection) is better.
Key points:
readOnly = false load data in read-write mode (managed)readOnly = true discard the hydrated state (starting with Spring 5.1)Description: This application is an example of getting the current database transaction id in MySQL. Only read-write database transactions gets an id in MySQL. Every database has a specific query for getting the transaction id. Here it is a list of these queries.
Key points:
SELECT tx.trx_id FROM information_schema.innodb_trx tx WHERE tx.trx_mysql_thread_id = connection_id() Description: This application is a sample of inspecting the Persistent Context content via org.hibernate.engine.spi.PersistenceContext .
Key points:
SharedSessionContractImplementorPersistenceContext API Description: This application is an example of using the Hibernate SPI, org.hibernate.integrator.spi.Integrator for extracting tables metadata.
النقاط الرئيسية:
org.hibernate.integrator.spi.Integrator and override integrate() method to return metadata.getDatabase()Integrator via LocalContainerEntityManagerFactoryBean@ManyToOne Relationship To A SQL Query Via The Hibernate @JoinFormula Description: This application is an example of mapping the JPA @ManyToOne relationship to a SQL query via the Hibernate @JoinFormula annotation. We start with two entities, Author and Book , involved in a unidirectional @ManyToOne relationship. Each book has a price. While we fetch a book by id (let's call it book A ), we want to fetch another book B of the same author whose price is the next smaller price in comparison with book A price.
Key points:
B is done via @JoinFormulaDescription: This application is an example of fetching a read-only MySQL database view in a JPA immutable entity.
Key points:
data-mysql.sql fileGenreAndTitleView.javaDescription: This application is an example of updating, inserting and deleting data in a MySQL database view. Every update/insert/delete will automatically update the contents of the underlying table(s).
Key points:
data-mysql.sql fileWITH CHECK OPTION Description: This application is an example of preventing inserts/updates of a MySQL view that are not visible through this view via WITH CHECK OPTION . In other words, whenever you insert or update a row of the base tables through a view, MySQL ensures that the this operation is conformed with the definition of the view.
Key points:
WITH CHECK OPTION to the viewjava.sql.SQLException: CHECK OPTION failed 'bookstoredb.author_anthology_view Description: This application is an example of assigning a database temporary sequence of values to rows via the window function, ROW_NUMBER() . This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
ROW_NUMBER() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by ROW_NUMBER as wellROW_NUMBER() window function Output sample: 
Description: This application is an example of finding top N rows of every group.
Key points:
ROW_NUMBER() window function Output sample: 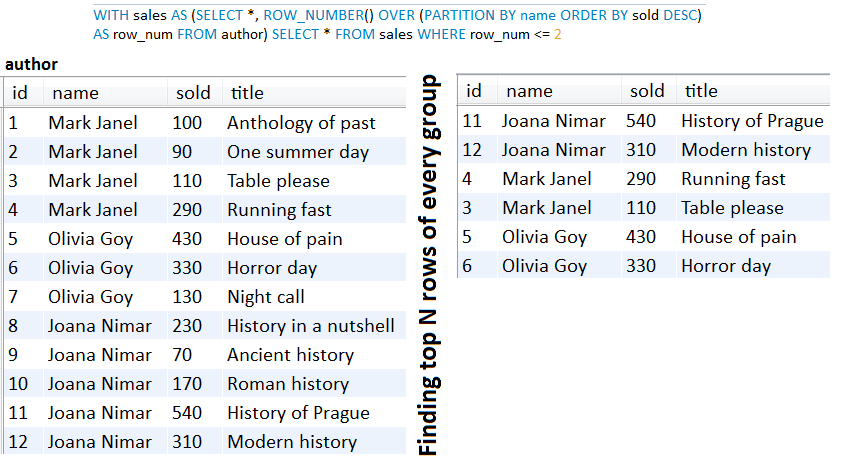
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
ROW_NUMBER() Window Function Description: This application is an example of using ROW_NUMBER() (and COUNT(*) OVER() for counting all elements) window function to implement pagination.
Key points:
ROW_NUMBER()Page or Slice , we return it as List , therefore Pageable is not used@Transactional annotation is being ignored Description: This application is an example of fixing the case when @Transactional annotation is ignored. Most of the time, this annotation is ignored in the following scenarios:
@Transactional was added to a private , protected or package-protected method@Transactional was added to a method defined in the same class where it is invokedالنقاط الرئيسية:
@Transactional methods therepublic@Transactional methods from other services Description: This is a Spring Boot example of using the hi/lo algorithm and a custom implementation of SequenceStyleGenerator for generating custom sequence IDs (eg, A-0000000001 , A-0000000002 , ...).
Key points:
SequenceStyleGenerator and override the configure() and generate() methodsClob And Blob To byte[] And String Description: This application is an example of mapping Clob and Blob as byte[] and String .
Key points:
LOB Locators Clob And Blob Description: This application is an example of mapping to JDBC's LOB locators Clob and Blob .
النقاط الرئيسية:
SINGLE_TABLE Inheritance Hierarchy Description: This application is a sample of fetching a certain subclass from a SINGLE_TABLE inheritance hierarchy. This is useful when the dedicated repository of the subclass doesn't automatically add in the WHERE clause a dtype based condition for fetching only the needed subclass.
Key points:
WHERE clause a TYPE check@NaturalId Description: This is a SpringBoot application that defines a @ManyToOne relationship that doesn't reference a primary key column. It references a Hibernate @NaturalId column.
Key points:
@JoinColumn(referencedColumnName = "natural_id_column")Specification Description: This application is an example of implementing an advanced search via Specification API. Mainly, you can give the search filters to a generic Specification and fetch the result set. Pagination is supported as well. You can chain expressions via logical AND and OR to create compound filters. Nevertheless, there is room for extensions to add brackets support (eg, (x AND y) OR (x AND z) ), more operations, conditions parser and so on and forth.
Key points:
SpecificationSpecification Query Fetch Joins Description: This application contains two examples of how to define JOIN in Specification to emulate JPQL join-fetch operations.
النقاط الرئيسية:
SELECT statements and the pagination is done in memory (very bad!)SELECT statements but the pagination is done in the databaseJOIN is defined in a Specification implementationNote: You may also like to read the recipe, "How To Enrich DTO With Virtual Properties Via Spring Projections"
Description: Fetch only the needed data from the database via Spring Data Projections (DTO). The projection interface is defined as a static interface (can be non- static as well) in the repository interface.
Key points:
List<projection>LIMIT ) - here, we can use query builder mechanism built into Spring Data repository infrastructureNote: Using projections is not limited to use query builder mechanism built into Spring Data repository infrastructure. We can fetch projections via JPQL or native queries as well. For example, in this application we use a JPQL.
Output example (select first 2 rows; select only "name" and "age"):
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
Description: Consider an entity named Review . This entity defines three @ManyToOne relationships to Book , Article and Magazine . A review can be associated with either a book, a magazine or an article. To validate this constraint, we can rely on Bean Validation as in this application.
Key points:
null@JustOneOfMany ) added at class-level to the Review entityTRIGGER ) Description: This application uses EnumType.ORDINAL and EnumType.STRING for mapping Java enum type to database. As a rule of thumb, strive to keep the data types as small as possible (eg, for EnumType.ORDINAL use TINYINT/SMALLINT , while for EnumType.STRING use VARCHAR(max_needed_bytes) ). Relying on EnumType.ORDINAL should be more efficient but is less expressive than EnumType.STRING .
Key points:
EnumType.ORDINAL set @Column(columnDefinition = "TINYINT") )enum To Database Via AttributeConverter Description: This application maps a Java enum via AttributeConverter . In other words, it maps the enum values HORROR , ANTHOLOGY and HISTORY to the integers 1 , 2 and 3 and viceversa. This allows us to set the column type as TINYINT/SMALLINT which is less space-consuming than VARCHAR(9) needed in this case.
Key points:
AttributeConverter@Converter the corresponding entity fieldenum To PostgreSQL enum Type Description: This application maps a Java enum type to PostgreSQL enum type.
Key points:
EnumTypeEnumType via package-info.java@Typeenum To PostgreSQL enum Type Via Hibernate Types Library Description: This application maps a Java enum type to PostgreSQL enum type via Hibernate Types library.
Key points:
pom.xml@TypeDef to specify the needed type class@Type Description: Hibernate Types is a library of extra types not supported by Hibernate Core by default. This is a Spring Boot application that uses this library to persist JSON data (JSON Java Object ) in a MySQL json column and for querying JSON data from the MySQL json column to JSON Java Object . Updates are supported as well.
Key points:
pom.xml@TypeDef to map typeClass to JsonStringType Description: Hibernate Types is a library of extra types not supported by Hibernate Core by default. This is a Spring Boot application that uses this library to persist JSON data (JSON Java Object ) in a PostgreSQL json column and for querying JSON data from the PostgreSQL json column to JSON Java Object . Updates are supported as well.
النقاط الرئيسية:
pom.xml@TypeDef to map typeClass to JsonBinaryTypeOPTIMISTIC_FORCE_INCREMENT Description: This application is a sample of how OPTIMISTIC_FORCE_INCREMENT works in MySQL. This is useful when you want to increment the version of the locked entity even if this entity was not modified. Via OPTIMISTIC_FORCE_INCREMENT the version is updated (incremented) at the end of the currently running transaction.
Key points:
Chapter (which uses @Version )Modification entityModification (child-side) and Chapter (parent-side) there is a lazy unidirectional @ManyToOne associationINSERT statement against the modification table, therefore the chapter table will not be modified by editorsChapter entity version is needed to ensure that modifications are applied sequentially (the author and editor are notified if a modificaton was added since the chapter copy was loaded)version is forcibly increased at each modification (this is materialized in an UPDATE triggered against the chapter table at the end of the currently running transaction)OPTIMISTIC_FORCE_INCREMENT in the corresponding repositoryObjectOptimisticLockingFailureExceptionPESSIMISTIC_FORCE_INCREMENT Description: This application is a sample of how PESSIMISTIC_FORCE_INCREMENT works in MySQL. This is useful when you want to increment the version of the locked entity even if this entity was not modified. Via PESSIMISTIC_FORCE_INCREMENT the version is updated (incremented) immediately (the entity version update is guaranteed to succeed immediately after acquiring the row-level lock). The incrementation takes place before the entity is returned to the data access layer.
Key points:
Chapter (which uses @Version )Modification entityModification (child-side) and Chapter (parent-side) there is a lazy unidirectional @ManyToOne associationINSERT statement against the modification table, therefore the chapter table will not be modified by editorsChapter entity version is needed to ensure that modifications are applied sequentially (each editor is notified if a modificaton was added since his chapter copy was loaded and he must re-load the chapter)version is forcibly increased at each modification (this is materialized in an UPDATE triggered against the chapter table immediately after aquiring the row-level lock)PESSIMISTIC_FORCE_INCREMENT in the corresponding repositoryOptimisticLockException and one that will lead to QueryTimeoutException Note: Pay attention to the MySQL dialect: MySQL5Dialect (MyISAM) doesn't support row-level locking, MySQL5InnoDBDialect (InnoDB) acquires row-level lock via FOR UPDATE (timeout can be set), MySQL8Dialect (InnoDB) acquires row-level lock via FOR UPDATE NOWAIT .
PESSIMISTIC_READ And PESSIMISTIC_WRITE Works In MySQL Description: This application is an example of using PESSIMISTIC_READ and PESSIMISTIC_WRITE in MySQL. In a nutshell, each database system defines its own syntax for acquiring shared and exclusive locks and not all databases support both types of locks. Depending on Dialect , the syntax can vary for the same database as well (Hibernate relies on Dialect for chosing the proper syntax). In MySQL, MySQL5Dialect doesn't support locking, while InnoDB engine ( MySQL5InnoDBDialect and MySQL8Dialect ) supports shared and exclusive locks as expected.
Key points:
@Lock(LockModeType.PESSIMISTIC_READ) and @Lock(LockModeType.PESSIMISTIC_WRITE) on query-levelTransactionTemplate to trigger two concurrent transactions that read and write the same row| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
PESSIMISTIC_WRITE Works With UPDATE / INSERT And DELETE Operations Description: This application is an example of triggering UPDATE , INSERT and DELETE operations in the context of PESSIMISTIC_WRITE locking against MySQL. While UPDATE and DELETE are blocked until the exclusive lock is released, INSERT depends on the transaction isolation level. Typically, even with exclusive locks, inserts are possible (eg, in PostgreSQL). In MySQL, for the default isolation level, REPEATABLE READ , inserts are prevented against a range of locked entries, but, if we switch to READ_COMMITTED , then MySQL acts as PostgreSQL as well.
Key points:
SELECT with PESSIMISTIC_WRITE to acquire an exclusive lockUPDATE , INSERT or DELETE on the rows locked by Transaction AUPDATE , DELETE and INSERT + REPEATABLE_READ , Transaction B is blocked until it timeouts or Transaction A releases the exclusive lockINSERT + READ_COMMITTED , Transaction B can insert in the range of rows locked by Transaction A even if Transaction A is holding an exclusive lock on this range Note: Do not test transaction timeout via Thread.sleep() ! This is not working! Rely on two transactions and exclusive locks or even better rely on SQL sleep functions (eg, MySQL, SELECT SLEEP(n) seconds, PostgreSQL, SELECT PG_SLEEP(n) seconds). Most RDBMS supports a sleep function flavor.
Description: This application contains several approaches for setting a timeout period for a transaction or query. The timeout is signaled by a specific timeout exception (eg, .QueryTimeoutException ). After timeout, the transaction is rolled back. You can see this in the database (visually or query) and on log via a message of type: Initiating transaction rollback; Rolling back JPA transaction on EntityManager [SessionImpl(... <open>)] .
Key points:
spring.transaction.default-timeout in seconds (see, application.properties )@Transactional(timeout = n) in secondsjavax.persistence.query.timeout hint in millisecondsorg.hibernate.timeout hint in seconds Note: If you are using TransactionTemplate then the timeout can be set via TransactionTemplate.setTimeout(n) in seconds.
@Embeddable Description: This application is a proof of concept of how to define a composite key via @Embeddable and @EmbeddedId . This application uses two entities, Author and Book involved in a lazy bidirectional @OneToMany association. The identifier of Author is composed by name and age via AuthorId class. The identifier of Book is just a regular auto-generated numeric value.
Key points:
AuthorId ) is publicSerializableequals() and hashCode()@IdClass Description: This application is a proof of concept of how to define a composite key via @IdClass . This application uses two entities, Author and Book involved in a lazy bidirectional @OneToMany association. The identifier of Author is composed by name and age via AuthorId class. The identifier of Book is just a typical auto-generated numeric value.
Key points:
AuthorId ) is publicSerializableequals() and hashCode() Note : The @IdClass can be useful when we cannot modify the compsite key class. Otherwise, rely on @Embeddable .
@Embeddable Composite Primary Key Description: This application is a proof of concept of how to define a relationship in an @Embeddable composite key. The composite key is AuthorId and it belongs to the Author class.
Key points:
AuthorId ) is publicSerializableequals() and hashCode() Description: This is a SpringBoot application that loads multiple entities by id via a @Query based on the IN operator and via the Hibernate 5 MultiIdentifierLoadAccess interface.
Key points:
IN operator in a @Query simply add the query in the proper repositoryMultiIdentifierLoadAccess in Spring Data style provide the proper implementationMultiIdentifierLoadAccess implementation allows us to load entities by multiple ids in batches and by inspecting or not the current Persistent Context (by default, the Persistent Context is not inspected to see if the entities are already loaded or not) Description: This application is a sample of fetching all attributes of an entity ( Author ) as a Spring projection (DTO). Commonly, a DTO contains a subset of attributes, but, sometimes we need to fetch the whole entity as a DTO. In such cases, we have to pay attention to the chosen approach. Choosing wisely can spare us from performance penalties.
Key points:
List<Object[]> or List<AuthorDto> via a JPQL of type SELECT a FROM Author a WILL fetch the result set as entities in Persistent Context as well - avoid this approachList<Object[]> or List<AuthorDto> via a JPQL of type SELECT a.id AS id, a.name AS name, ... FROM Author a will NOT fetch the result set in Persistent Context - this is efficientList<Object[]> or List<AuthorDto> via a native SQL of type SELECT id, name, age, ... FROM author will NOT fetch the result set in Persistent Context - but, this approach is pretty slowList<Object[]> via Spring Data query builder mechanism WILL fetch the result set in Persistent Context - avoid this approachList<AuthorDto> via Spring Data query builder mechanism will NOT fetch the result set in Persistent ContextfindAll() method) should be considered after JPQL with explicit list of columns to be fetched and query builder mechanism@ManyToOne Or @OneToOne Associations Description: This application fetches a Spring projection including the @ManyToOne association via different approaches. It can be easily adapted for @OneToOne association as well.
Key points:
Description: This application inspect the Persistent Context content during fetching Spring projections that includes collections of associations. In this case, we focus on a @OneToMany association. Mainly, we want to fetch only some attributes from the parent-side and some attributes from the child-side.
Description: This application is a sample of reusing an interface-based Spring projection. This is useful to avoid defining multiple interface-based Spring projections in order to cover a range of queries that fetches different subsets of fields.
Key points:
@JsonInclude(JsonInclude.Include.NON_DEFAULT) annotation to avoid serialization of default fields (eg, fields that are not available in the current projection and are null - these fields haven't been fetched in the current query)null fields)| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
Description: This application is a sample of using dynamic Spring projections.
Key points:
<T> List<T> findByGenre(String genre, Class<T> type); ) Description: This application is a sample of batching inserts via EntityManager in MySQL. This way you can easily control the flush() and clear() cycles of the Persistence Context (1st Level Cache) inside the current transaction. This is not possible via Spring Boot, saveAll(Iterable<S> entities) , since this method executes a single flush per transaction. Another advantage is that you can call persist() instead of merge() - this is used behind the scene by the SpringBoot saveAll(Iterable<S> entities) and save(S entity) .
Moreover, this example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=false Output example:
Description: This is a Spring Boot application that reads a relatively big JSON file (200000+ lines) and inserts its content in MySQL via batching using ForkJoinPool , JdbcTemplate and HikariCP.
Key points:
json typeListrewriteBatchedStatements=true -> this setting will force sending the batched statements in a single request;cachePrepStmts=true -> enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disableduseServerPrepStmts=true -> this way you switch to server-side prepared statements (may lead to signnificant performance boost); moreover, you avoid the PreparedStatement to be emulated at the JDBC Driver level;...?cachePrepStmts=true&useServerPrepStmts=true&rewriteBatchedStatements=true&createDatabaseIfNotExist=trueStopWatch to measure the time needed to transfer the file into the databasecitylots.zip in the current location; this is the big JSON file collected from Internet;DatasourceProxyBeanPostProcessor.java component by uncomment the line, // @Component ; This is needed because this application relies on DataSource-Proxy (for details, see the following item)CompletableFuture Description: This application is a sample of using CompletableFuture for batching inserts. This CompletableFuture uses an Executor that has the number of threads equal with the number of your computer cores. Usage is in Spring style.
Description: Let's suppose that we have a one-to-many relationship between Author and Book entities. When we save an author, we save his books as well thanks to cascading all/persist. We want to create a bunch of authors with books and save them in the database (eg, a MySQL database) using the batch technique. By default, this will result in batching each author and the books per author (one batch for the author and one batch for the books, another batch for the author and another batch for the books, and so on). In order to batch authors and books, we need to order inserts as in this application.
Moreover, this example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
النقاط الرئيسية:
application.properties the following property: spring.jpa.properties.hibernate.order_inserts=true Example without ordered inserts:
Example with ordered inserts:
Description: Batch inserts (in MySQL) in Spring Boot style. This example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches.
Key points:
application.properties set spring.jpa.properties.hibernate.jdbc.batch_sizeapplication.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledspring.jpa.properties.hibernate.cache.use_second_level_cache=false Output example:
IN Clause Parameter Padding Description: This application is an example of using Hibernate IN cluase parameter padding. This way we can reduce the number of Execution Plans. Mainly, Hibernate is padding parameters as follows:
Key points:
application.properties set spring.jpa.properties.hibernate.query.in_clause_parameter_padding=trueDescription: Fetch only the needed data from the database via Spring Data Projections (DTO). In this case, via class-based projections.
Key points:
equals() and hashCode() only for the columns that should be fetched from the databaseList<projection>LIMIT )Note: Using projections is not limited to use query builder mechanism built into Spring Data repository infrastructure. We can fetch projections via JPQL or native queries as well. For example, in this application we use a JPQL.
Output example (select first 2 rows; select only "name" and "age"):
Description: Batch inserts via Hibernate session-level batching (Hibernate 5.2 or higher) in MySQL. This example commits the database transaction after each batch excecution. This way we avoid long-running transactions and, in case of a failure, we rollback only the failed batch and don't lose the previous batches. For each batch, the Persistent Context is flushed and cleared, therefore we maintain a thin Persistent Context. This way the code is not prone to memory errors and performance penalties caused by slow flushes.
Key points:
application.properties set spring.jpa.properties.hibernate.generate_statistics (just to check that batching is working)application.properties set JDBC URL with rewriteBatchedStatements=true (optimization for MySQL)application.properties set JDBC URL with cachePrepStmts=true (enable caching and is useful if you decide to set prepStmtCacheSize , prepStmtCacheSqlLimit , etc as well; without this setting the cache is disabled)application.properties set JDBC URL with useServerPrepStmts=true (this way you switch to server-side prepared statements (may lead to signnificant performance boost))spring.jpa.properties.hibernate.order_inserts=true to optimize the batching by ordering insertsIDENTITY will cause insert batching to be disabledSession is obtained by un-wrapping it via EntityManager#unwrap(Session.class)Session#setJdbcBatchSize(Integer size) and get via Session#getJdbcBatchSize()spring.jpa.properties.hibernate.cache.use_second_level_cache=false Output example:
Description: This application highlights the difference betweeen loading entities in read-write vs. read-only mode. If you plan to modify the entities in a future Persistent Context then fetch them as read-only in the current Persistent Context.
Key points:
Note: If you never plan to modify the fetched result set then use DTO (eg, Spring projection), not read-only entities.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
Note: Domain events should be used with extra-caution! The best practices for using them are revealed in my book, Spring Boot Persistence Best Practices.
Description: Starting with Spring Data Ingalls release publishing domain events by aggregate roots becomes easier. Entities managed by repositories are aggregate roots. In a Domain-Driven Design application, these aggregate roots usually publish domain events. Spring Data provides an annotation @DomainEvents you can use on a method of your aggregate root to make that publication as easy as possible. A method annotated with @DomainEvents is automatically invoked by Spring Data whenever an entity is saved using the right repository. Moreover, Spring Data provides the @AfterDomainEventsPublication annotation to indicate the method that should be automatically called for clearing events after publication. Spring Data Commons comes with a convenient template base class ( AbstractAggregateRoot ) to help to register domain events and is using the publication mechanism implied by @DomainEvents and @AfterDomainEventsPublication . The events are registered by calling the AbstractAggregateRoot.registerEvent() method. The registered domain events are published if we call one of the save methods (eg, save() ) of the Spring Data repository and cleared after publication.
This is a sample application that relies on AbstractAggregateRoot and its registerEvent() method. We have two entities, Book and BookReview involved in a lazy-bidirectional @OneToMany association. A new book review is saved in CHECK status and a CheckReviewEvent is published. This event handler is responsible to check the review grammar, content, etc and switch the review status from CHECK to ACCEPT or REJECT and propagate the new status to the database. So, this event is registered before saving the book review in CHECK status and is published automatically after we call the BookReviewRepository.save() method. After publication, the event is cleared.
Key points:
AbstractAggregateRoot and provide a method for registering eventsCheckReviewEvent ), but more can be registeredCheckReviewEventHandler in an asynchronous manner via @AsyncDescription: This application is an example of testing the Hibernate Query Plan Cache (QPC). Hibernate QPC is enabled by default and, for entity queries (JPQL and Criteria API), the QPC has a size of 2048, while for native queries it has a size of 128. Pay attention to alter these values to accommodate all queries executed by your طلب. If the number of exectued queries is higher than the QPC size (especially for entity queries) then you will start to experiment performance penalties caused by entity compilation time added for each query execution.
In this application, you can adjust the QPC size in application.properties . Mainly, there are 2 JPQL queries and a QPC of size 2. Switching from size 2 to size 1 will cause the compilation of one JPQL query at each execution. Measuring the times for 5000 executions using a QPC of size 2, respectively 1 reveals the importance of QPC in terms of time.
Key points:
hibernate.query.plan_cache_max_sizehibernate.query.plan_parameter_metadata_max_sizeDescription: This is a SpringBoot application that enables Hibernate Second Level Cache and EhCache provider. It contains an example of caching entities and an example of caching a query result.
النقاط الرئيسية:
EhCache )@CacheHINT_CACHEABLE Description: This is a SpringBoot application representing a kickoff application for Spring Boot caching and EhCache .
Key points:
EhCacheSqlResultSetMapping And NamedNativeQuery Note: If you want to rely on the {EntityName}.{RepositoryMethodName} naming convention for simply creating in the repository interface methods with the same name as of native named query then skip this application and check this one.
Description: This is a sample application of using SqlResultSetMapping , NamedNativeQuery and EntityResult for fetching single entity and multiple entities as List<Object[]> .
Key points:
SqlResultSetMapping , NamedNativeQuery and EntityResult Description: This is a SpringBoot application that loads multiple entities by id via a @Query based on the IN operator and via Specification .
Key points:
IN operator in a @Query simply add the query in the proper repositorySpecification rely on javax.persistence.criteria.Root.in()ResultTransformer Description: Fetching more read-only data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]> and most probably you will need to represent it as a List<ParentDto> , where a ParentDto instance has a List<ChildDto> . For such cases, we can rely on a custom Hibernate ResultTransformer . This application is a sample of writing a custom ResultTransformer .
Key points:
ResultTransformer interface Description: Is a common scenario to have a big List and to need to chunk it in multiple smaller List of given size. For example, if we want to employee a concurrent batch implementation we need to give to each thread a sublist of items. Chunking a list can be done via Google Guava, Lists.partition(List list, int size) method or Apache Commons Collections, ListUtils.partition(List list, int size) method. But, it can be implemented in plain Java as well. This application exposes 6 ways to do it. The trade-off is between the speed of implementation and speed of execution. For example, while the implementation relying on grouping collector is not performing very well, it is quite simple and fast to write it.
النقاط الرئيسية:
Chunk.java class which relies on the built-in List.subList() method Time-performance trend graphic for chunking 500, 1_000_000, 10_000_000 and 20_000_000 items in lists of 5 items: 
Description: Consider the Book and Chapter entities. A book has a maximum accepted number of pages ( book_pages ) and the author should not exceed this number. When a chapter is ready for review, the author is submitting it. At this point, the publisher should check that the currently total number of pages doesn't exceed the allowed book_pages :
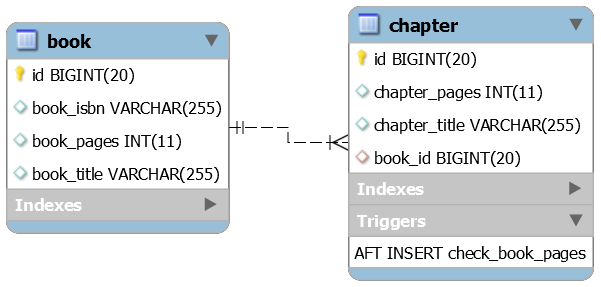
This kind of checks or constraints are easy to implement via database triggers. This application relies on a MySQL trigger to empower our complex contraint ( check_book_pages ).
النقاط الرئيسية:
AFTER INSERT OR AFTER UPDATE ) Description: This application is an example of using Spring Data Query By Example (QBE) to check if a transient entity exists in the database. Consider the Book entity and a Spring controller that exposes an endpoint as: public String checkBook(@Validated @ModelAttribute Book book, ...) . Beside writting an explicit JPQL, we can rely on Spring Data Query Builder mechanism or, even better, on Query By Example (QBE) API. In this context, QBE API is quite useful if the entity has a significant number of attributes and:
Key points:
BookRepository extends QueryByExampleExecutor<S extends T> boolean exists(Example<S> exmpl) with the proper probe (an entity instance populated with the desired fields values)ExampleMatcher which defines the details on how to match particular fields Note: Do not conclude that Query By Example (QBE) defines only the exists() method. Check out all methods here.
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
@Transactional Description: This application is meant to highlight that the best place to use @Transactional for user defined query-methods is in repository interface, and afterwards, depending on situation, on service-methods level.
Key points:
JOINED Inheritance Strategy And Visitor Design Pattern Description: This application is an example of using JPA JOINED inheritance strategy and Visitor pattern.
Key points:
JOINED Inheritance Strategy And Strategy Design Pattern Description: This application is an example of using JPA JOINED inheritance strategy and Strategy pattern.
Key points:
Description: This folder holds several applications that shows how each Spring transaction propagation works.
Key points:
GenerationType.AUTO And UUID Identifiers Description: This application is an example of using the JPA GenerationType.AUTO for assigning automatically UUID identifiers.
Key points:
BINARY(16) columnDescription: This application is an example of manually assigning UUID identifiers.
Key points:
BINARY(16) columnuuid2 For Generating UUID Identifiers Description: This application is an example of using the Hibernate RFC 4122 compliant UUID generator, uuid2 .
Key points:
BINARY(16) columnDescription: This Spring Boot application is a sample that reveals how Hibernate session-level repeatable reads works. Persistence Context guarantees session-level repeatable reads. Check out how it works.
النقاط الرئيسية:
TransactionTemplateNote: For a detailed explanation of this application consider my book, Spring Boot Persistence Best Practices
hibernate.enable_lazy_load_no_trans Description: This application is an example of using Hibernate-specific hibernate.enable_lazy_load_no_trans . Check out the application log to see how transactions and database connections are used.
Key points:
hibernate.enable_lazy_load_no_trans Description: This application is an example of cloning entities. The best way to achieve this goal relies on copy-constructors. This way we can control what we copy. Here we use a bidirectional-lazy @ManyToMany association between Author and Book .
Key points:
Author (only the genre ) and associate the corresponding booksAuthor (only the genre ) and clone the books as well| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
UPDATE Statement Only The Modified Columns Via Hibernate @DynamicUpdate Description: This application is an example of using the Hibernate-specific, @DynamicUpdate . By default, even if we modify only a subset of columns, the triggered UPDATE statements will include all columns. By simply annotating the corresponding entity at class-level with @DynamicUpdate the generated UPDATE statement will include only the modified columns.
Key points:
UPDATE for different subsets of columns via JDBC statements caching (each triggered UPDATE string will be cached and reused accordingly)Description: This application is an example of logging execution time for a repository query-method.
Key points:
RepositoryProfiler ) Description: This application is an example of using the TransactionSynchronizationAdapter for overriding beforeCommit() , beforeCompletion() , afterCommit() and afterCompletion() callbacks globally (application-level) and at method-level.
النقاط الرئيسية:
TransactionProfiler )TransactionSynchronizationManager.registerSynchronization()SqlResultSetMapping And NamedNativeQuery Using {EntityName}.{RepositoryMethodName} Naming Convention Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on SqlResultSetMapping , NamedNativeQuery and the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
Key points:
SqlResultSetMapping , NamedNativeQuerySqlResultSetMapping And NamedNativeQuery Using {EntityName}.{RepositoryMethodName} Naming Convention Description: This is a sample application of using SqlResultSetMapping , NamedNativeQuery and EntityResult for fetching single entity and multiple entities as List<Object[]> . In this application we rely on the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
Key points:
SqlResultSetMapping , NamedNativeQuery and EntityResult@NamedQuery And Spring Projection (DTO) Description: This application is an example of combining JPA named queries @NamedQuery and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
Key points:
@NamedNativeQuery And Spring Projection (DTO) Description: This application is an example of combining JPA named native queries @NamedNativeQuery and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
Key points:
Description: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. Spring Data allows us to write our named (native) queries in a typical *.properties file inside the META-INF folder of your classpath. This way, we avoid modifying our entities. This application shows you how to do it.
Warning: Cannot use native queries with dynamic sorting ( Sort ). Nevertheless, using Sort in named queries works fine. Moreover, using Sort in Pageable works fine for both, named queries and named native queries. At least this is how it behave in Spring Boot 2.2.2. From this point of view, this approach is better than using @NamedQuery / @NamedNativeQuery or orm.xml file.
Key points:
META-INF/jpa-named-queries.properties{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementationorm.xml File Description: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. Spring Data allows us to write our named (native) queries in a typical orm.xml file inside the META-INF folder of your classpath. This way, we avoid modifying our entities. This application shows you how to do it.
Warning: Pay attention that, via this approach, we cannot use named (native) queries with dynamic sorting ( Sort ). Using Sort in Pageable is ignored, therefore you need to explicitly add ORDER BY in the queries. At least this is how it behave in Spring Boot 2.2.2. A better approach relies on using a properties file for listing the named (native) queries. In this case, dynamic Sort works for named queries, but not for named native queries. Using Sort in Pageable works as expected in named (native) queries.
النقاط الرئيسية:
META-INF/orm.xml{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementation Description: JPA named (native) queries are commonly written via @NamedQuery and @NamedNativeQuery annotations in entity classes. This application shows you how to do it.
Warning: Pay attention that, via this approach, we cannot use named (native) queries with dynamic sorting ( Sort ). Using Sort in Pageable is ignored, therefore you need to explicitly add ORDER BY in the queries. At least this is how it behave in Spring Boot 2.2.2. A better approach relies on using a properties file for listing the named (native) queries. In this case, dynamic Sort works for named queries, but not for named native queries. Using Sort in Pageable works as expected in named (native) queries. And, you don't need to modify/pollute entitites with the above annotations.
Key points:
@NamedQuery and @NamedNativeQuery annotations in entity classes{EntityName}.{RepositoryMethodName} naming convention for a quick and slim implementationSort and Pageable| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
Description: This application is an example of combining JPA named queries listed in a properties file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
Key points:
jpa-named-queries.properties ) in a folder named META-INF the application classpath Description: This application is an example of combining JPA named native queries listed in a properties file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
Key points:
jpa-named-queries.properties ) in a folder named META-INF the application classpathorm.xml File And Spring Projection (DTO) Description: This application is an example of combining JPA named queries listed in orm.xml file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named query.
Key points:
orm.xml file in a folder named META-INF the application classpathorm.xml File And Spring Projection (DTO) Description: This application is an example of combining JPA named native queries listed in orm.xml file and Spring projections (DTO). For queries names we use the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of named native query.
Key points:
orm.xml file in a folder named META-INF the application classpathorm.xml Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on named native queries and result set mapping via orm.xml and the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
Key points:
<named-native-query/> and <sql-result-set-mapping/> to map the native query to AuthorDto class
Description: This application is a proof of concept for using Spring Projections(DTO) and cross joins written via JPQL and native SQL (for MySQL).
Key points:
Book and Formatresources/data-mysql.sql )BookTitleAndFormatType.java )JdbcTemplate And BeanPropertyRowMapper Description: This application is an example of calling a MySQL stored procedure that returns a result set via JdbcTemplate and BeanPropertyRowMapper .
Key points:
JdbcTemplate , SimpleJdbcCall and BeanPropertyRowMapper@EntityListeners Description: This application is a sample of using the JPA @MappedSuperclass and @EntityListeners with JPA callbacks.
Key points:
Book , is not an entity, it can be abstract , and is annotated with @MappedSuperclass and @EntityListeners(BookListener.class)BookListener defines JPA callbacks (eg, @PrePersist )Book is persisted, loaded, updated, etc the corresponding JPA callbacks are called@Fetch(FetchMode.JOIN) May Causes N+1 Issues Advice: Always evaluate JOIN FETCH and entities graphs before deciding to use FetchMode.JOIN . The FetchMode.JOIN fetch mode always triggers an EAGER load so the children are loaded when the parents are. Beside this drawback, FetchMode.JOIN may return duplicate results. You'll have to remove the duplicates yourself (eg storing the result in a Set ). But, if you decide to go with FetchMode.JOIN at least pay attention to avoid N+1 issues discussed below.
Note: Let's assume three entities, Author , Book and Publisher . Between Author and Book there is a bidirectional-lazy @OneToMany association. Between Author and Publisher there is a unidirectional-lazy @ManyToOne . Between Book and Publisher there is no association.
Now, we want to fetch a book by id ( BookRepository#findById() ), including its author, and the author's publisher. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN) works as expected. Using JOIN FETCH or entity graph is also working as expected.
Next, we want to fetch all books ( BookRepository#findAll() ), including their authors, and the authors publishers. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN) will cause N+1 issues. It will not trigger the expected JOIN . In this case, using JOIN FETCH or entity graph should be used.
Key points:
@Fetch(FetchMode.JOIN) doesn't work for query-methods@Fetch(FetchMode.JOIN) works in cases that fetches the entity by id (primary key) like using EntityManager#find() , Spring Data, findById() , findOne() .RANK() Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, RANK() . This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
RANK() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by RANK() as wellRANK() window function Output sample: 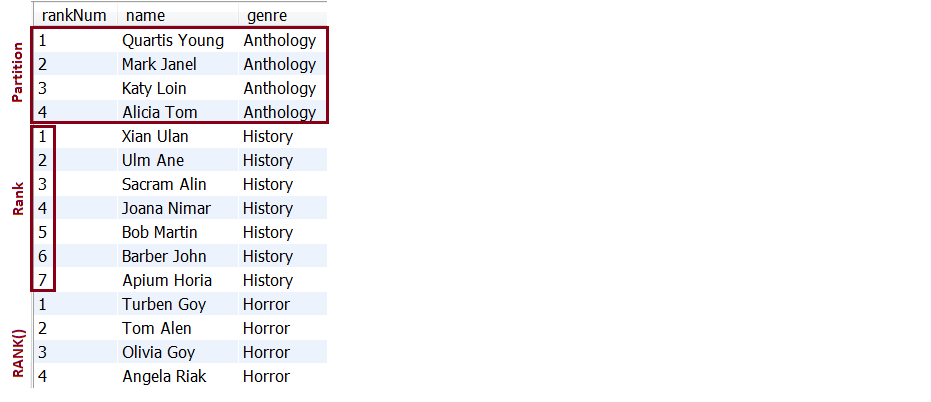
| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
DENSE_RANK() Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, DENSE_RANK() . In comparison with the RANK() window function, DENSE_RANK() avoid gaps within partition. This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
DENSE_RANK() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by DENSE_RANK() as wellDENSE_RANK() window function Output sample: 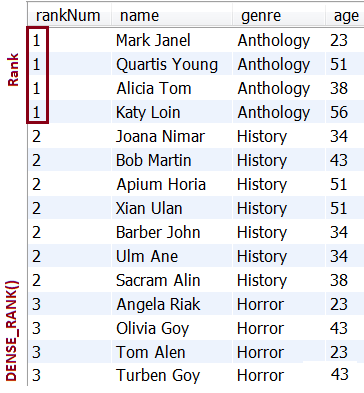
NTILE(N) Description: This application is an example of distributing the number of rows in the specified (N) number of groups via the window function, NTILE(N) . This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
NTILE() (you will use it internally, in the query, usually in the WHERE clause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated by NTILE() as wellNTILE() window function Output sample: 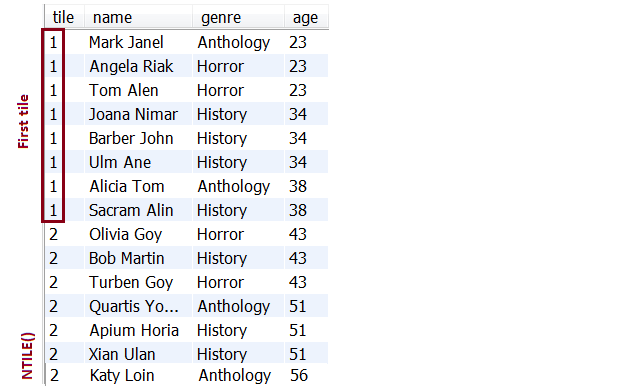
Description: Spring Data comes with the Query Builder mechanism for JPA that is capable to interpret a query method name (known as a derived query) and convert it into a SQL query in the proper dialect. This is possible as long as we respect the naming conventions of this mechanism. Beside the well-known query of type find... , Spring Data supports derived count queries and derived delete queries.
Key points:
count... (eg, long countByGenre(String genre) ) - Spring Data will generate a SELECT COUNT(...) FROM ... querydelete... or remove... and returns long (eg, long deleteByGenre(String genre) ) - Spring Data will trigger first a SELECT to fetch entities in the Persistence Context, and, afterwards, it triggers a DELETE for each entity that must be deleteddelete... or remove... and returns List<entity> (eg, List<Author> removeByGenre(String genre) ) - Spring Data will trigger first a SELECT to fetch entities in the Persistence Context, and, afterwards, it triggers a DELETE for each entity that must be deletedDescription: Property expressions can refer to a direct property of the managed entity. However, you can also define constraints by traversing nested properties. This application is a sample of traversing nested properties for fetching entities and DTOs.
Key points:
Author has several Book and each book has several Review (between Author and Book there is a bidirectional-lazy @oneToMany association, and, between Book and Review there is also a bidirectional-lazy @OneToMany association)Review and we want to know the Author of the Book that has received this ReviewAuthorRepository the following query that will be processed by the Spring Data Query Builder mechanism: Author findByBooksReviews(Review review);SELECT with two LEFT JOINbooks.reviews . The algorithm starts by interpreting the entire part ( BooksReviews ) as the property and checks the domain class for a property with that name (uncapitalized). If the algorithm succeeds, it uses that property. If not, the algorithm splits up the source at the camel case parts from the right side into a head and a tail and tries to find the corresponding property — in our example, Books and Reviews . If the algorithm finds a property with that head, it takes the tail and continues building the tree down from there, splitting the tail up in the way just described. If the first split does not match, the algorithm moves the split point to the left and continues.Author class has an booksReview property as well. The algorithm would match in the first split round already, choose the wrong property, and fail (as the type of booksReview probably has no code property). To resolve this ambiguity you can use _ inside your method name to manually define traversal points. So our method name would be as follows: Author findByBooks_Reviews(Review review);Note: Fetching read-only data should be done via DTO, not managed entities. But, there is no tragedy to fetch read-only entities in a context as follows:
@Transactional(readOnly = true)Under these circumstances, let's tackle a common case that I saw quite a lot. There is even an SO answer about it (don't do this):

Description: Let's assume that Author and Book are involved in a bidirectional-lazy @OneToMany association. Imagine an user that loads a certain Author (without the associated Book ). The user may be interested or not in the Book , therefore, we don't load them with the Author . If the user is interested in the Book then he will click a button of type, View books . Now, we have to return the List<Book> associated to this Author .
So, at first request (query), we fetch an Author . The Author is detached. At second request (query), we want to load the Book associated to this Author . But, we don't want to load the Author again (for example, we don't care about lost updates of Author ), we just want to load the associated Book in a single SELECT . A common (not recommended) approach is to load the Author again (eg, via findById(author.getId()) ) and call the author.getBooks() . But, this end up in two SELECT statements. One SELECT for loading the Author , and another SELECT after we force the collection initialization. We force collection initialization because it will not be initialize if we simply return it. In order to trigger the collection initialization the developer call books.size() or he rely on Hibernate.initialize(books); .
But, we can avoid such solution by relying on an explicit JPQL or Query Builder property expressions. This way, there will be a single SELECT and no need to call size() or Hibernate.initialize();
Key points:
This item is detailed in my book, Spring Boot Persistence Best Practices.
Description: Behind the built-in Spring Data save() there is a call of EntityManager#persist() or EntityManager#merge() . It is important to know this aspect in several cases. Among this cases, we have the entity update case (simple update or update batching).
Consider Author and Book involved in a bidirectional-lazy @OneToMany association. And, we load an Author , detach it, update it in the detached state, and save it to the database via save() method. Calling save() will come with the following two issues resulting from calling merge() behind the scene:
SELECT (merge) and one UPDATESELECT will contain a LEFT OUTER JOIN to fetch the associated Book as well (we don't need the books!) How about triggering only the UPDATE instead of this? The solution relies on calling Session#update() . Calling Session.update() requires to unwrap the Session via entityManager.unwrap(Session.class) .
Key points:
Session.update() will trigger only the UPDATE (there is no SELECT )Session.update() works with versioned optimistic locking mechanism as well (so, lost updates are prevented)Streamable Description: This application is a sample of fetching Streamable<entity> and Streamable<dto> . But, more important, this application contains three examples of how to not use Streamable . It is very tempting and comfortable to fetch a Streamable result set and chop it via filter() , map() , flatMap() , and so on until we obtain only the needed data instead of writing a query (eg, JPQL) that fetches exactly the needed result set from the database. Mainly, we just throw away some of the fetched data to keep only the needed data. But, is not advisable to follow such practices because fetching more data than needed can cause significant performance penalties.
Moreover, pay attention to combining two or more Streamable via the and() method. The returned result may be different from what you are expecting to see. Each Streamable produces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values).
Key points:
map() )filter() )Streamable via and() ; each Streamable produces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values)Streamable Wrapper TypesDescription: A common practice consists of exposing dedicated wrappers types for collections resulted after mapping a query result set. This way, on a single query execution, the API can return multiple results. After we call a query-method that return a collection, we can pass it to a wrapper class by manually instantiation of that wrapper-class. But, we can avoid the manually instantiation if the code respects the following key points.
Key points:
Streamablestatic factory method named of(…) or valueOf(…) taking Streamable as argumentDescription: JPA 2.1 come with schema generation features. This feature can setup the database or export the generated commands to a file. The parameters that we should set are:
spring.jpa.properties.javax.persistence.schema-generation.database.action : Instructs the persistence provider how to setup the database. Possible values include: none , create , drop-and-create , drop
javax.persistence.schema-generation.scripts.action : Instruct the persistence provider which scripts to create. Possible values include: none , create , drop-and-create , drop .
javax.persistence.schema-generation.scripts.create-target : Indicate the target location of the create script generated by the persistence provider. This can be as a file URL or a java.IO.Writer .
javax.persistence.schema-generation.scripts.drop-target : Indicate the target location of the drop script generated by the persistence provider. This can be as a file URL or a java.IO.Writer .
Moreover, we can instruct the persistence provider to load data from a file into the database via: spring.jpa.properties.javax.persistence.sql-load-script-source . The value of this property represents the file location and it can be a file URL or a java.IO.Writer .
Key points:
application.properties Description: Sometimes, we need to write in repositories certain query-methods that return a Map instead of a List or a Set . For example, when we need a Map<Id, Entity> or we use GROUP BY and we need a Map<Group, Count> . This application shows you how to do it via default methods directly in repository.
Key points:
default methods and Collectors.toMap() Description: Consider one of the JPA inheritance strategies (eg, JOINED ). Handling entities inheritance With Spring Data repositories can be done as follows:
Description: This application is a sample of logging only slow queries via Hibernate 5.4.5, hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS property. A slow query is a query that has an execution time bigger than a specificed threshold in milliseconds.
Key points:
application.properties add hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS Output example: 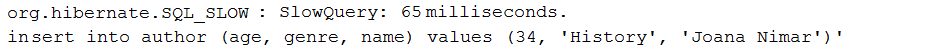
Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on JDK14 Records feature and Spring Data Query Builder Mechanism.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points: Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on JDK 14 Records, Constructor Expression and JPQL.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
ResultTransformer Description: Fetching more read-only data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]> and most probably you will need to represent it as a List<ParentDto> , where a ParentDto instance has a List<ChildDto> . For such cases, we can rely on a custom Hibernate ResultTransformer . This application is a sample of writing a custom ResultTransformer .
As DTO, we rely on JDK 14 Records. From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
AuthorDto and BookDtoResultTransformer interfaceJdbcTemplate And ResultSetExtractor Description: Fetching more data than needed is prone to performance penalities. Using DTO allows us to extract only the needed data. In this application we rely on JDK14 Records feature, JdbcTemplate and ResultSetExtractor .
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
AuthorDto and BookDtoJdbcTemplate and ResultSetExtractorDescription: This application is a sample of using dynamic Spring projections via DTO classes.
Key points:
<T> List<T> findByGenre(String genre, Class<T> type); )| If you need a deep dive into the performance recipes exposed in this repository then I am sure that you will love my book "Spring Boot Persistence Best Practices" | If you need a hand of tips and illustrations of 100+ Java persistence performance issues then "Java Persistence Performance Illustrated Guide" is for you. |
|
|
CompletableFuture And Return List<S> Description: This application is a sample of using CompletableFuture for batching inserts. This CompletableFuture uses an Executor that has the number of threads equal with the number of your computer cores. Usage is in Spring style. It returns List<S> :
CompletableFuture And Return List<S> (1)CompletableFuture And Return List<S> (2) Description: This application is an example of causing a database deadlock in MySQL. This application produces an exception of type: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction . However, the database will retry until transaction (A) succeeds.
Key points:
SELECT with PESSIMISTIC_WRITE to acquire an exclusive lock to table authorauthor genre with success and sleeps for 10sSELECT with PESSIMISTIC_WRITE to acquire an exclusive lock to table bookbook title with success and sleeps for 10s Description: This application is a proof of concept of how to define a composite key having an explicit part ( name ) and a generated part ( authorId via SEQUENCE generator).
Key points:
@IdClass Description: Sometimes we need to intercept the generated SQL that originates from Spring Data, EntityManager , Criteria API, JdbcTemplate and so on. This can be done as in this sample application. After interception, you can log, modify or even return a brand new SQL that will be executed in the end.
Key points:
StatementInspector SPIapplication.properties via spring.jpa.properties.hibernate.session_factory.statement_inspector281. Force inline params in Criteria API
NOTE Use this with high precaution since you open the gate for SQL injections.
Description: Sometimes we need to force inline params in Criteria API. By default, numeric parameters are inlined, but string parameters are not.
Key points:
application.properties the setting spring.jpa.properties.hibernate.criteria.literal_handling_mode as inlineDescription: Arthur Gavlyukovskiy provide a suite of Spring Boot starters for quickly integrate P6Spy, Datasource Proxy, and FlexyPool. In this example, we add Datasource Proxy, but please consider this for more details.
Key points:
pom.xml , add the datasource-proxy-spring-boot-starter starterapplication.properties enable DEBUG level for loggingDescription: This application is an example of using Java records as embeddable. This is available starting with Hibernate 6.0, but it was refined to be more accessible and easy to use in Hibernate 6.2
Key points:
Contact )Author ) via @EmbeddedAuthorDto )



