similarity
1.1.6
التشابه، حساب درجة التشابه بين السلاسل النصية، جافا مكتوبة.
التشابه، وهو عبارة عن مجموعة أدوات لحساب التشابه، يمكن استخدامه لحساب تشابه النص، وتحليل المشاعر، وما إلى ذلك، المكتوب بلغة Java.
التشابه هو إصدار Java لمجموعة أدوات حساب التشابه يتكون من سلسلة من الخوارزميات والهدف هو نشر طريقة حساب التشابه في معالجة اللغة الطبيعية. يتميز التشابه بخصائص الأدوات العملية، والأداء الفعال، والبنية الواضحة، والمجموعات الحديثة، وقابلية التخصيص.
يوفر التشابه الوظائف التالية:
حساب تشابه الكلمات
حساب تشابه العبارة
حساب تشابه الجمل
حساب تشابه الفقرة
كنكي يييوان
تحليل المشاعر
كلمات تقريبية
أثناء توفير وظائف غنية، تصر الوحدات الداخلية للتشابه على الاقتران المنخفض، وتصر النماذج على التحميل البطيء، وتصر القواميس على النشر بنص عادي. فهي سهلة الاستخدام وتساعد المستخدمين على تدريب مجموعاتهم الخاصة.
تقديم حزمة الجرة
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >مقدمة من غرادل:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}طول النص: دقة الكلمة
يوصى باستخدام تشابه سيلين: org.xm.Similarity.cilinSimilarity وهي طريقة لحساب التشابه تعتمد على المرادفات Cilin
مثال: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
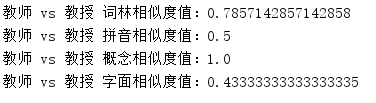
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
طول النص: دقة العبارة
يوصى باستخدام تشابه العبارة: org.xm.Similarity.phraseSimilarity ، وهي في الأساس طريقة لحساب تشابه عبارتين من خلال نفس الأحرف ومواضع نفس الأحرف.
مثال: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
طول النص: دقة الجملة
يوصى باستخدام تشابه الجملة في شكل الكلمات وترتيب الكلمات: org.xm.similarity.morphoSimilarity ، وهو أسلوب تشابه لا يأخذ في الاعتبار نفس النص حرفيًا لجملتين فحسب، بل يأخذ في الاعتبار أيضًا الترتيب الذي يظهر به النص نفسه.
مثال: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
طول النص: دقة الفقرة (فقرة، 25 حرفًا <طول(نص) <500 حرفًا)
يوصى باستخدام تشابه الجملة في ترتيب الكلمات على شكل كلمة: org.xm.similarity.text.CosineSimilarity ، وهي طريقة تأخذ في الاعتبار نفس النص في فقرتين، وترجيحه من خلال تجزئة الكلمات، وتكرار الكلمات، وأوزان جزء من الكلام، و يستخدم جيب التمام لحساب التشابه.
مثال: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875مثال: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}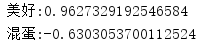
هذا المثال هو تحليل قطبية المشاعر الحبيبية للكلمات استنادًا إلى أشجار sememe. فيما يتعلق بتحليل المشاعر النصية، يوجد pytextclassifier، الذي يستخدم نماذج الشبكة العصبية العميقة وخوارزميات تصنيف SVM لتحقيق نتائج أفضل.
مثال: src/test/Java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

تدريب ناقل الكلمات Word2vec هو إصدار Java من أداة تدريب Word2vec Word2VEC_java. مجموعة التدريب هي رواية Tian Long Ba Bu، ويتم الحصول على المرادفات من خلال تنفيذ ناقل الكلمات. يمكن للمستخدمين تدريب مجموعة مخصصة أو استخدام ويكيبيديا الصينية لتدريب ناقلات الكلمات العالمية.
قياس تشابه النص

اتفاقية الترخيص هي ترخيص Apache 2.0، وهو مجاني للاستخدام التجاري. يرجى إرفاق رابط التشابه واتفاقية الترخيص بوصف المنتج.
لا يزال كود المشروع تقريبيًا للغاية. إذا كان لديك أي تحسينات على الكود، فنحن نرحب بإعادته إلى هذا المشروع قبل الإرسال، يرجى الانتباه إلى النقطتين التاليتين:
testيمكنك بعد ذلك تقديم العلاقات العامة.


