cherche
2.2.1
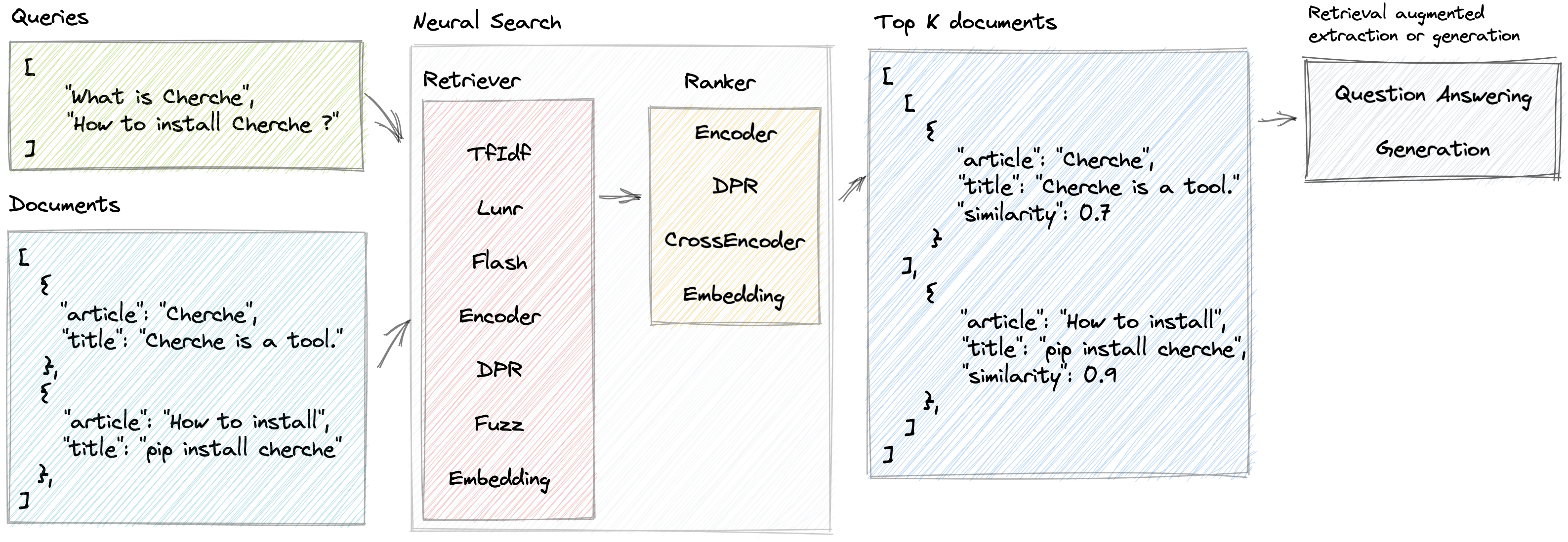
البحث العصبي

يمكّن Cherche من تطوير خط أنابيب بحث عصبي يستخدم المستردات ونماذج اللغة المدربة مسبقًا كمستردات ومصنفات. تكمن الميزة الأساسية لـ Cherche في قدرتها على بناء خطوط أنابيب شاملة. بالإضافة إلى ذلك، يعتبر Cherche مناسبًا تمامًا للبحث الدلالي دون الاتصال بالإنترنت نظرًا لتوافقه مع الحساب الدفعي.
فيما يلي بعض الميزات التي يقدمها Cherche:
عرض حي لمحرك بحث البرمجة اللغوية العصبية المدعوم من Cherche
لتثبيت Cherche لاستخدامه مع مسترد بسيط على وحدة المعالجة المركزية، مثل TfIdf، وFlash، وLunr، وFuzz، استخدم الأمر التالي:
pip install chercheلتثبيت Cherche للاستخدام مع أي مسترد دلالي أو مصنف على وحدة المعالجة المركزية، استخدم الأمر التالي:
pip install " cherche[cpu] "أخيرًا، إذا كنت تخطط لاستخدام أي مسترد دلالي أو مصنف على وحدة معالجة الرسومات، فاستخدم الأمر التالي:
pip install " cherche[gpu] "باتباع تعليمات التثبيت هذه، ستتمكن من استخدام Cherche مع المتطلبات المناسبة لاحتياجاتك.
الوثائق متاحة هنا. فهو يوفر تفاصيل حول المستردين والمصنفين وخطوط الأنابيب والأمثلة.
يسمح Cherche بالعثور على المستند الصحيح ضمن قائمة الكائنات. هنا مثال على الجسم.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]فيما يلي مثال على خط أنابيب بحث عصبي يتكون من TF-IDF الذي يسترد المستندات بسرعة، متبوعًا بنموذج التصنيف. يقوم نموذج التصنيف بفرز المستندات التي ينتجها المسترد بناءً على التشابه الدلالي بين الاستعلام والمستندات. يمكننا الاتصال بخط الأنابيب باستخدام قائمة الاستعلامات والحصول على المستندات ذات الصلة لكل استعلام.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]يمكننا تعيين الفهرس للمستندات للوصول إلى محتوياتها باستخدام خطوط الأنابيب:
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]يوفر Cherche أدوات استرداد تقوم بتصفية مستندات الإدخال بناءً على الاستعلام.
يوفر Cherche أدوات تصنيف تقوم بتصفية المستندات في مخرجات المستردين.
تتوافق مُصنفات Cherche مع نماذج SentenceTransformers المتوفرة على Hugging Face hub.
يوفر Cherche وحدات مخصصة للإجابة على الأسئلة. تتوافق هذه الوحدات مع نماذج Hugging Face المدربة مسبقًا ومدمجة بالكامل في خطوط أنابيب البحث العصبية.
تم إنشاء Cherche لصالح/بواسطة Renault وهو الآن متاح للجميع. نحن نرحب بجميع المساهمات.

مسترد Lunr عبارة عن غلاف حول Lunr.py. برنامج Flash Retriever عبارة عن غلاف حول FlashText. تعد أدوات تصنيف DPR وEncode وCrossEncoder عبارة عن أغلفة مخصصة لاستخدام نماذج SentenceTransformers المدربة مسبقًا في خط أنابيب البحث العصبي.
إذا كنت تستخدم cherche للحصول على نتائج لمنشورك العلمي، فيرجى الرجوع إلى ورقة SIGIR الخاصة بنا:
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}يتكون فريق Cherche dev من رافاييل سورتي وفرانسوا بول سيرفانت ونيكولاس بيزوزيرو وخوسيه جي مورينو. ؟


