genai_robotics
1.0.0
يحتوي هذا المستودع على إعداد تجريبي مراعٍ للخصوصية للاستفادة من أساليب الذكاء الاصطناعي التوليدية في التحكم في الروبوتات. من خلال الحل المقدم هنا، يمكن للمستخدم تحديد الإجراءات بحرية عن طريق الصوت والتي يتم ترجمتها إلى خطط يمكن للفراغ الآلي تنفيذها في بيئة عالم مفتوح يتم مراقبتها بواسطة الكاميرا.
المزايا الأساسية للطرق المقدمة هنا هي:
تم تطوير النظام في هاكاثون مدته 3 أيام كتمرين تعليمي وإثبات لمفهوم أن أدوات الذكاء الاصطناعي الحديثة يمكنها تقليل وقت تطوير حلول التحكم في الروبوتات بشكل كبير.
لاستخدام جميع ميزات هذا المستودع، إليك ما يجب أن يكون لديك:
للبدء، اتبع الخطوات التالية:
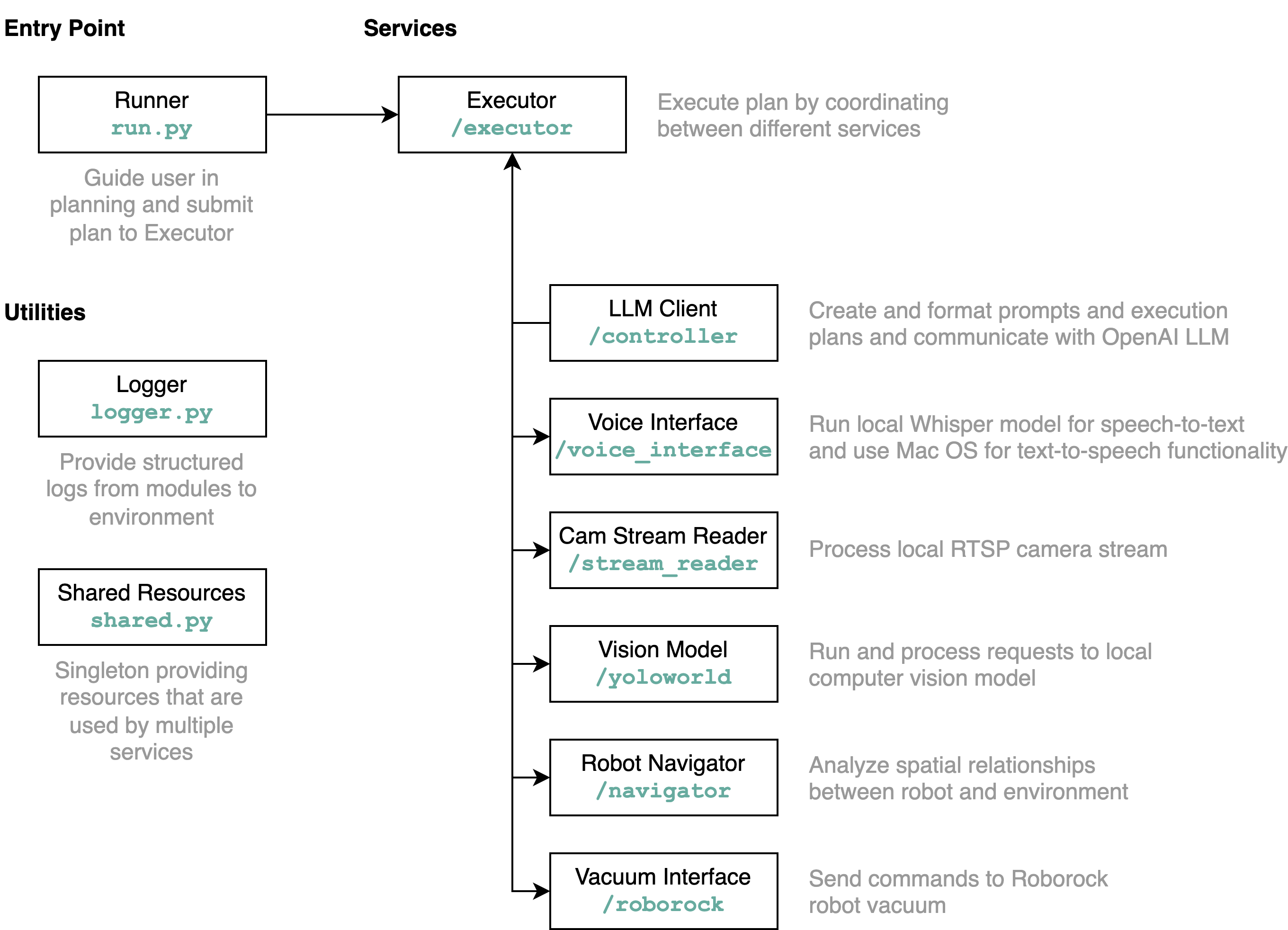
requirements.txt في بيئة Python (الخصيتين مع Python 3.11)src/config.template.toml إلى config.toml . بالنسبة لجميع الخطوات أدناه، أدخل بيانات الاعتماد المكتسبة في config.tomlpython-roborock .src/run.py لتشغيل سير العمل. أفضل طريقة لفهم ما يفعله هذا المستودع بالتفصيل وكيفية تفاعل العناصر هي من خلال مخطط معماري:
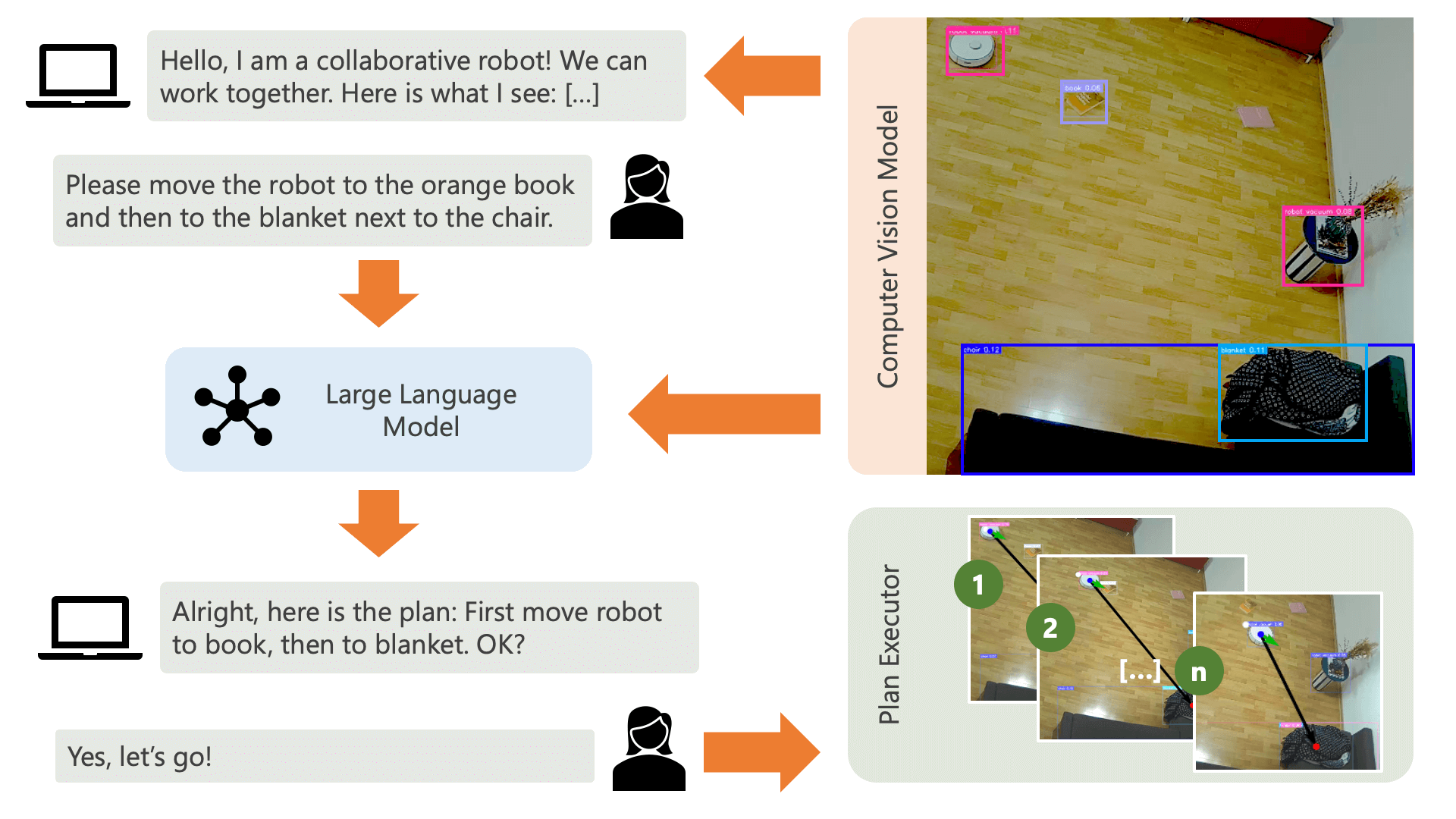
عند تشغيل ملف run.py كما هو موضح أعلاه، إليك ما يحدث وكيف يعمل:
يرحب النظام بالمستخدم برسالة صوتية ويتوقع منه أن يخبر النظام بما يريد القيام به. على سبيل المثال، قد يرغب المستخدم في أن يلتقط الروبوت القهوة من شخص يجلس على كرسي أصفر وينقلها إلى شخص آخر يجلس على أريكة سوداء. سيقوم النظام بعد ذلك بإنشاء خطة لتنفيذ هذه الإجراءات.
ما الذي يحتاجه النظام لفهم كيف يمكنه تحقيق ما يريد المستخدم القيام به؟ يجب أن يكون النظام على دراية ببيئته والإجراءات التي يمكن تنفيذها في هذه البيئة. هنا، نستخدم نموذج رؤية الكمبيوتر مع اكتشاف الكائنات لتوفير معلومات حول البيئة للنظام. يمكن للمكنسة الكهربائية نفسها تنفيذ 3 إجراءات بسيطة: التحرك للأمام، والدوران، وعدم القيام بأي شيء. هناك إجراء آخر في البيئة ينتظر قيام المستخدم بتنفيذ إجراء معين.
لتجنب الارتباك من جانب المستخدم، من المهم أن يعرف المستخدم كيف ينظر الذكاء الاصطناعي إلى بيئته. على سبيل المثال، إذا لم يتم التعرف على كائن ما بواسطة نموذج رؤية الكمبيوتر، فلن يتمكن الذكاء الاصطناعي من تضمينه في الخطة. ومن المهم أيضًا أن يدرك المستخدم أن هناك حالة من عدم اليقين فيما يتعلق بالتعرف على النماذج. باستخدام نموذج اللغة الكبير GPT-4o الخاص بـ OpenAI مع موجه الوصف، يأتي النظام بشرح لبيئته ويقرأه للمستخدم قبل أن يسأل المستخدم عما يريد من النظام أن يفعله.
وبالنظر إلى معلومات البيئة ومدخلات المستخدم فيما يتعلق بما يريدون القيام به، يمكن للنظام بعد ذلك التوصل إلى خطة. هنا، نطلب من LLM التوصل إلى خطة، بالنظر إلى مدخلات المستخدم ووصف البيئة. يمكنك العثور على قالب المطالبة في دليل controller . الحيلة المثيرة هنا هي أن LLM لا يدرك بيئته إلا من خلال جدولين يتم إنشاؤهما من مخرجات نموذج رؤية الكمبيوتر. هنا مثال:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
بمجرد قيام LLM بمعالجة موجه التخطيط، فإنه ينتج شيئين: المنطق والخطة. قبل أن يتابع النظام تنفيذ الخطة، سيستخدم موجه الشرح لإنشاء ملخص قصير للخطة بغرض الحصول على تأكيد من المستخدم بأن الخطة تتطابق مع ما طلب القيام به. وهذا يتماشى مع روح نهج الإنسان في الحلقة حيث نعمل من وجهة نظر مفادها أنه في بيئة مادية حقيقية ومفتوحة، من المحتمل أن يتعرض الناس للأذى بسبب تصرفات الذكاء الاصطناعي، لذلك فمن المعقول أن نطلب المساعدة البشرية ردود الفعل قبل أن يشرع الذكاء الاصطناعي في تنفيذ أي خطة توصل إليها بنفسه.
بمجرد تأكيد المستخدم، يشرع النظام في تنفيذ الخطة. قد تبدو مثل هذه الخطة، كما تم إنشاؤها بواسطة LLM، كما يلي:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] باستخدام executor ، يقوم النظام بتنفيذ الخطة خطوة بخطوة. لتقليل أي وقت مطلوب للإعداد، يتبع التحكم في الروبوت خوارزمية بسيطة وغير دقيقة ولكنها فعالة:
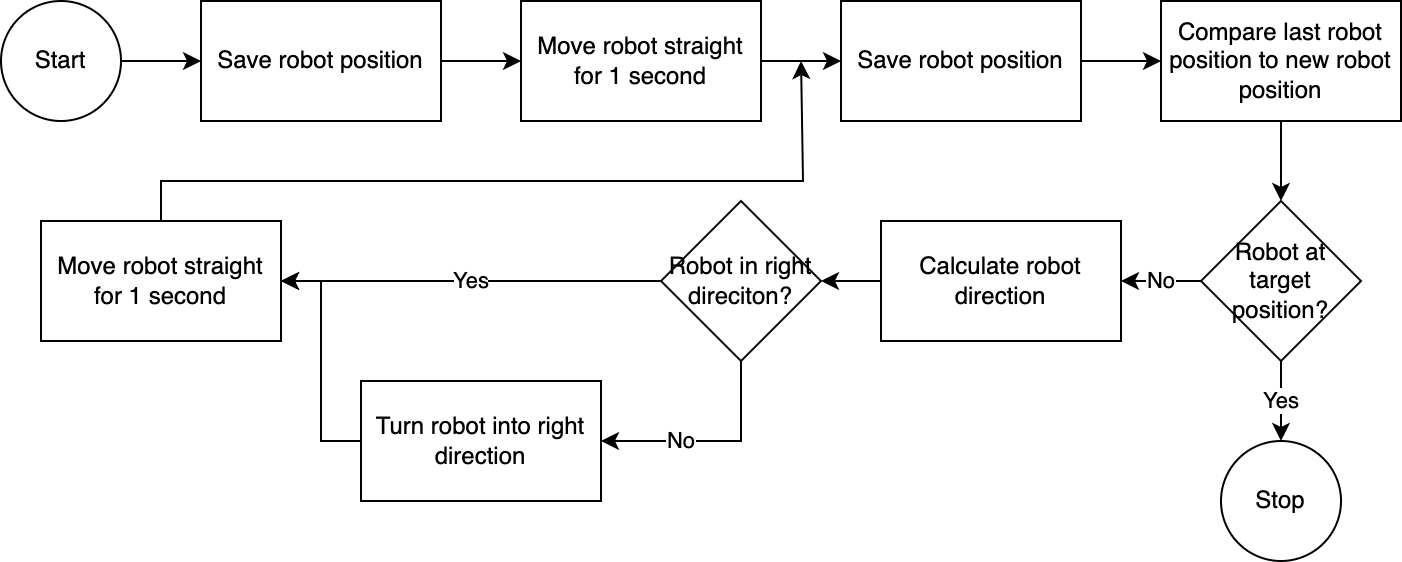
يقوم نظام الرؤية الحاسوبية بتقييم موضع الروبوت. من خلال التعليمات البرمجية الموجودة في وحدة navigator ، يتم تحليل ومقارنة موقع الروبوت بالنسبة إلى موضع الهدف ونسبة إلى آخر موضع معروف له. هذا النهج غير مثالي لأنه لا يتم أخذ موضع الكاميرا وتشويه العدسة في الاعتبار. الزوايا المقاسة من خلال هذا النهج غير دقيقة. ومع ذلك، نظرًا لأن النظام تكراري، يتم تعويض الأخطاء بشكل متكرر. ومع ذلك، تجدر الإشارة إلى أن هذا يأتي على حساب السرعة. النظام بطيء، حيث يستغرق وقتًا لتحليل الصورة وحساب المسار وإبلاغ الروبوت بالخطوات التالية التي يجب اتخاذها.
بمجرد وصول الروبوت إلى موضعه المستهدف، يتابع المنفذ الخطوة التالية من الخطة. بالنسبة للإجراءات التي تتضمن إدخال المستخدم، سيستخدم المنفذ وظيفة تحويل النص إلى كلام وتحويل الكلام إلى نص للتفاعل مع المستخدم.
في هذا النظام، نستخدم في الغالب الخدمات التي تعمل على جهاز محلي أو شبكة محلية. الاستثناء هو GPT-4o. نرسل بيانات نصية إلى نموذج OpenAI عبر الإنترنت. تتضمن البيانات النصية مدخلات المستخدم المكتوبة وجدول الكائنات التي تم التعرف عليها. السبب الوحيد الذي يجعلنا نستخدم GPT-4o هنا هو أن هذا أحد أفضل النماذج المتاحة في وقت الهاكاثون - يمكننا أيضًا تشغيل LLM محلي ثم العمل بشكل كامل دون الاتصال بالإنترنت، مع الحفاظ على الخصوصية بين التدفق الكامل العمليات.
تم إنتاج نموذج رؤية الكمبيوتر المتضمن في هذا المستودع بواسطة نموذج YOLO-World في مساحة HuggingFace مع المطالبة التالية: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human . إذا كنت ترغب في التعرف على كائنات إضافية، فيرجى ضبط المطالبة وتنزيل نموذج ONNX من خلال هذه المساحة. يمكنك بعد ذلك استبدال النموذج في دليل src/yoloworld/models/rev0 .
لاحظ أنه لاستخراج النموذج بشكل صحيح، تحتاج إلى تغيير الحد الأقصى لعدد المربعات ومعلمات عتبة النتيجة يدويًا في مساحة HuggingFace قبل تصدير النموذج.
يمكنك معرفة المزيد عن نموذج YOLO-World المثير الذي تم بناؤه على رأس التطورات الحديثة في نمذجة لغة الرؤية على موقع YOLO-World الإلكتروني.
تم نشر هذا المشروع بموجب ترخيص MIT.
لا تتم مراقبة هذا المستودع بشكل نشط وليس هناك نية لتنميته - فهو أولاً وقبل كل شيء تمرين تعليمي. ومع ذلك، إذا شعرت بالإلهام، فلا تتردد في المساهمة في المشروع عبر فتح إصدار GitHub أو طلب السحب.


