Interactive RAG
1.0.0
يُحدث الوكلاء ثورة في الطريقة التي نستفيد بها من النماذج اللغوية في اتخاذ القرار وأداء المهام. الوكلاء عبارة عن أنظمة تستخدم نماذج اللغة لاتخاذ القرارات وتنفيذ المهام. وهي مصممة للتعامل مع السيناريوهات المعقدة وتوفير المزيد من المرونة مقارنة بالطرق التقليدية. يمكن اعتبار الوكلاء بمثابة محركات التفكير التي تستفيد من نماذج اللغة لمعالجة المعلومات، واسترجاع البيانات ذات الصلة، واستيعاب (قطعة/تضمين) وإنشاء الاستجابات.
في المستقبل، سيلعب الوكلاء دورًا حيويًا في معالجة النص، وأتمتة المهام، وتحسين التفاعلات بين الإنسان والحاسوب مع تقدم النماذج اللغوية.
في هذا المثال، سنركز بشكل خاص على عوامل الاستفادة في الجيل المعزز للاسترجاع الديناميكي (RAG). باستخدام ActionWeaver وMongoDB Atlas، سيكون لديك القدرة على تعديل إستراتيجية RAG الخاصة بك في الوقت الفعلي من خلال تفاعلات المحادثة. سواء كان الأمر يتعلق بتحديد المزيد من القطع، أو زيادة حجم القطعة، أو تعديل المعلمات الأخرى، يمكنك ضبط نهج RAG الخاص بك لتحقيق جودة الاستجابة والدقة المطلوبة. يمكنك أيضًا إضافة/إزالة المصادر إلى قاعدة بيانات المتجهات الخاصة بك باستخدام اللغة الطبيعية!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
يعد تقطيع النص أمرًا رائعًا، ولكن كيف يمكنك تخزينه؟
التلخيص يوفر المساحة ويسرع الأمور، لكنه قد يفقد التفاصيل.
يعد تخزين البيانات الأولية دقيقًا، ولكنه ضخم، وأبطأ، و"صاخب".
إيجابيات التلخيص:
سلبيات التلخيص:
ما هو المناسب لك؟ ذلك يعتمد على احتياجاتك! يعتبر:
العرض التوضيحي 1
إنشاء بيئة بايثون جديدة
python3 -m venv envتفعيل بيئة بايثون الجديدة
source env/bin/activateتثبيت المتطلبات
pip3 install -r requirements.txtقم بتعيين المعلمات في params.py:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
قم بإنشاء فهرس بحث بالتعريف التالي
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}ضبط البيئة
export OPENAI_API_KEY=لتشغيل تطبيق RAG
env/bin/streamlit run rag/app.pyسيتم إلحاق معلومات السجل التي تم إنشاؤها بواسطة التطبيق إلى app.log.
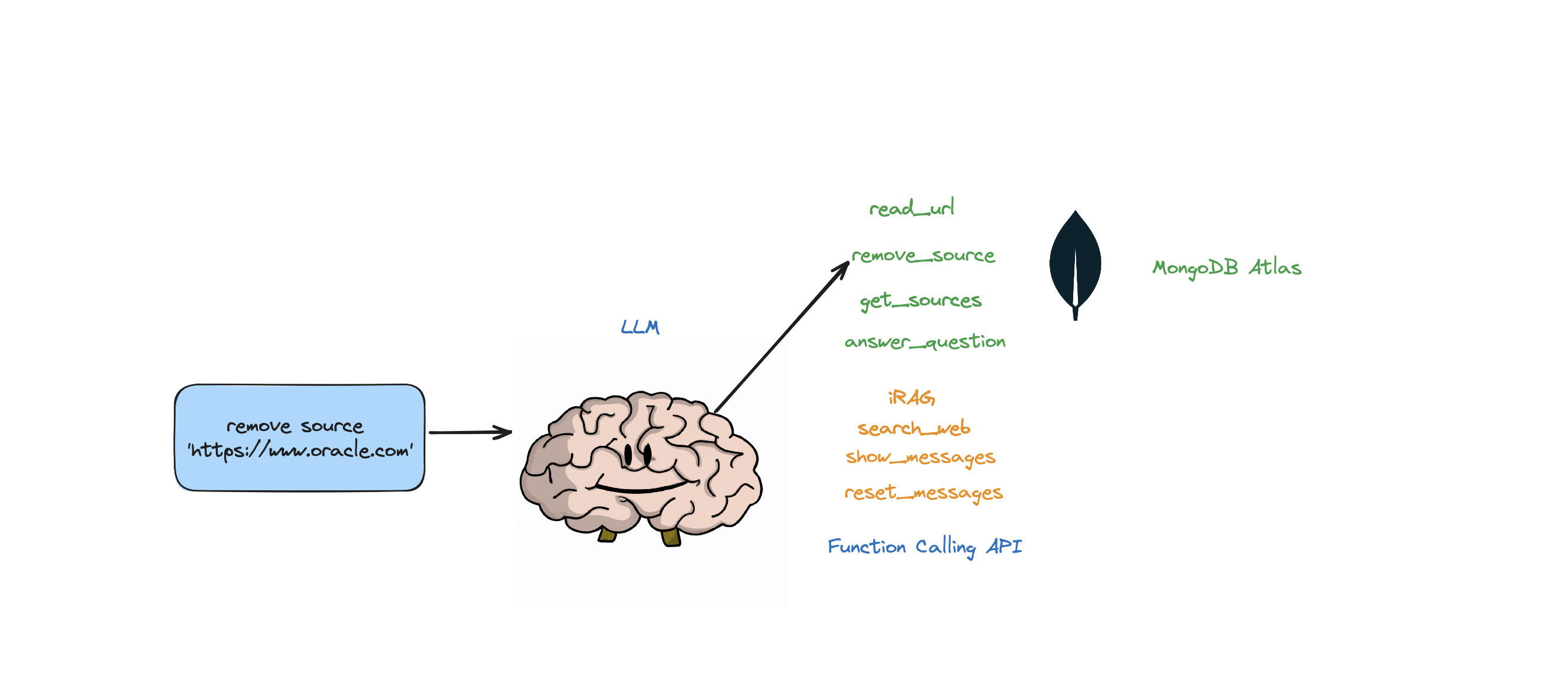
يدعم هذا الروبوت الإجراءات التالية: الإجابة على الأسئلة، والبحث في الويب، وقراءة عناوين URL، وإزالة المصادر، وسرد كافة المصادر، وإعادة تعيين الرسائل. كما أنه يدعم إجراءً يسمى iRAG والذي يتيح لك التحكم ديناميكيًا في إستراتيجية RAG الخاصة بوكيلك.
على سبيل المثال: "ضبط تكوين RAG على 3 مصادر وحجم القطعة 1250" => تكوين RAG الجديد: {'num_sources': 3، 'source_chunk_size': 1250، 'min_rel_score': 0، 'فريد': صحيح}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
إذا كان الروبوت غير قادر على تقديم إجابة للسؤال من البيانات المخزنة في متجر Atlas Vector، وإستراتيجية RAG الخاصة بك (عدد المصادر، حجم القطعة، min_rel_score، وما إلى ذلك)، فسوف يبدأ بحثًا على الويب للعثور على المعلومات ذات الصلة. يمكنك بعد ذلك توجيه الروبوت لقراءة تلك النتائج والتعلم منها.
إن RAG رائع وما إلى ذلك، لكن التوصل إلى "استراتيجية RAG" الصحيحة أمر صعب. سيكون لحجم القطعة وعدد المصادر الفريدة تأثير مباشر على الاستجابة الناتجة عن LLM.
في تطوير إستراتيجية RAG فعالة، تلعب عملية استيعاب مصادر الويب، والتقطيع، والتضمين، وحجم القطعة، وكمية المصادر المستخدمة أدوارًا حاسمة. يؤدي التقطيع إلى تقسيم نص الإدخال من أجل فهم أفضل، والتضمين يلتقط المعنى، ويؤثر عدد المصادر على تنوع الاستجابة. يعد العثور على التوازن الصحيح بين حجم القطعة وعدد المصادر أمرًا ضروريًا للحصول على استجابات دقيقة وذات صلة. يعد التجريب والضبط الدقيق ضروريين لتحديد الإعدادات المثلى.
قبل أن نتعمق في "الاسترجاع"، دعونا نتحدث أولاً عن "عملية الاستيعاب"
لماذا لديك عملية منفصلة "لاستيعاب" المحتوى الخاص بك في قاعدة بيانات المتجهات الخاصة بك؟ باستخدام سحر الوكلاء، يمكننا بسهولة إضافة محتوى جديد إلى قاعدة بيانات المتجهات.
هناك العديد من أنواع قواعد البيانات التي يمكنها تخزين هذه التضمينات، ولكل منها استخداماتها الخاصة. لكن بالنسبة للمهام التي تتضمن تطبيقات GenAI، أوصي بـ MongoDB.
فكر في MongoDB ككعكة يمكنك تناولها وتناولها معًا. يمنحك قوة لغته لإجراء الاستعلامات، لغة الاستعلام Mongo. ويتضمن أيضًا جميع الميزات الرائعة لـ MongoDB. علاوة على ذلك، فهو يتيح لك تخزين وحدات البناء هذه (تضمينات المتجهات) وإجراء العمليات الحسابية عليها، كل ذلك في مكان واحد. وهذا يجعل MongoDB Atlas متجرًا شاملاً لجميع احتياجات تضمين المتجهات الخاصة بك!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
باستخدام ActionWeaver، وهو برنامج مجمّع خفيف الوزن لواجهة برمجة تطبيقات استدعاء الوظائف، يمكننا إنشاء وكيل وكيل مستخدم يسترد المعلومات ذات الصلة ويستوعبها بكفاءة باستخدام MongoDB Atlas.
وكيل الوكيل هو وسيط يرسل طلبات العميل إلى خوادم أو موارد أخرى ثم يعيد الاستجابات.
يقدم هذا الوكيل البيانات للمستخدم بطريقة تفاعلية وقابلة للتخصيص، مما يعزز تجربة المستخدم الشاملة.
يحتوي UserProxyAgent على العديد من معلمات RAG التي يمكن تخصيصها، مثل chunk_size (على سبيل المثال 1000) و num_sources (على سبيل المثال 2) unique (على سبيل المثال True) و min_rel_score (على سبيل المثال 0.00).
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
فيما يلي بعض الفوائد الرئيسية التي أثرت على قرارنا باختيار ActionWeaver:
الوكيل هو في الأساس مجرد برنامج أو نظام كمبيوتر مصمم لإدراك بيئته واتخاذ القرارات وتحقيق أهداف محددة.
فكر في الوكيل باعتباره كيانًا برمجيًا يعرض درجة معينة من الاستقلالية وينفذ الإجراءات في بيئته نيابة عن مستخدمه أو مالكه، ولكن بطريقة مستقلة نسبيًا. ويتخذ مبادرات لتنفيذ الإجراءات بمفرده من خلال مناقشة خياراته لتحقيق هدفه (أهدافه). الفكرة الأساسية للوكلاء هي استخدام نموذج اللغة لاختيار سلسلة من الإجراءات التي يجب اتخاذها. على النقيض من السلاسل، حيث يتم ترميز سلسلة من الإجراءات في التعليمات البرمجية، يستخدم الوكلاء نموذج اللغة كمحرك منطقي لتحديد الإجراءات التي يجب اتخاذها وبأي ترتيب.
الإجراءات هي وظائف يمكن للوكيل استدعاءها. هناك نوعان من اعتبارات التصميم الهامة حول الإجراءات:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
بدون التفكير في كليهما، لن تتمكن من بناء وكيل عامل. إذا لم تمنح الوكيل حق الوصول إلى مجموعة الإجراءات الصحيحة، فلن يتمكن أبدًا من تحقيق الأهداف التي منحتها له. إذا لم تصف الإجراءات جيدًا، فلن يعرف الوكيل كيفية استخدامها بشكل صحيح.
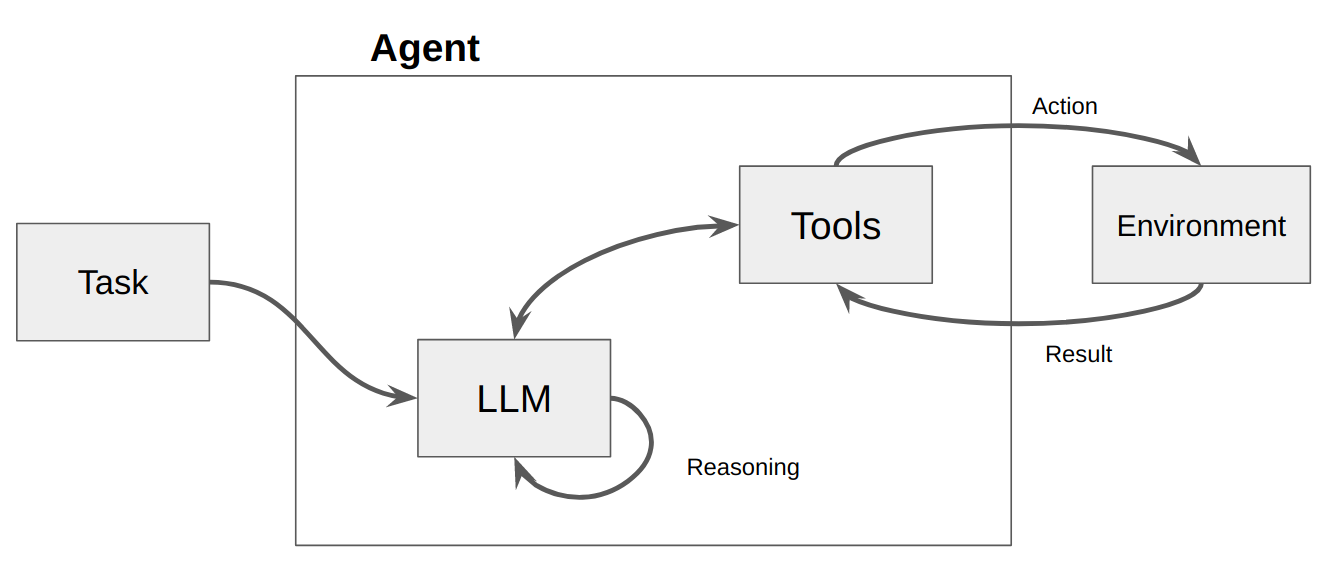
يتم بعد ذلك استدعاء LLM، مما يؤدي إما إلى الرد على المستخدم أو اتخاذ الإجراء (الإجراءات). إذا تقرر أن الاستجابة مطلوبة، فسيتم تمريرها إلى المستخدم، وتنتهي تلك الدورة. إذا تقرر أن الإجراء مطلوب، يتم اتخاذ هذا الإجراء، ويتم إجراء ملاحظة (نتيجة الإجراء). تتم إضافة هذا الإجراء والملاحظة المقابلة مرة أخرى إلى الموجه (نسمي ذلك "لوحة خدش الوكيل")، وتتم إعادة تعيين الحلقة، أي. يتم استدعاء LLM مرة أخرى (باستخدام لوحة مسودة الوكيل المحدثة).
في ActionWeaver، يمكننا التأثير على الحلقة بإضافة stop=True|False إلى الإجراء. إذا stop=True ، فسيقوم LLM بإرجاع مخرجات الوظيفة على الفور. سيؤدي هذا أيضًا إلى تقييد LLM من إجراء استدعاءات متعددة للوظائف. في هذا العرض التوضيحي سنستخدم فقط stop=True
يدعم ActionWeaver أيضًا التحكم في الحلقة الأكثر تعقيدًا باستخدام orch_expr(SelectOne[actions]) و orch_expr(RequireNext[actions]) ولكنني سأترك ذلك للجزء الثاني.
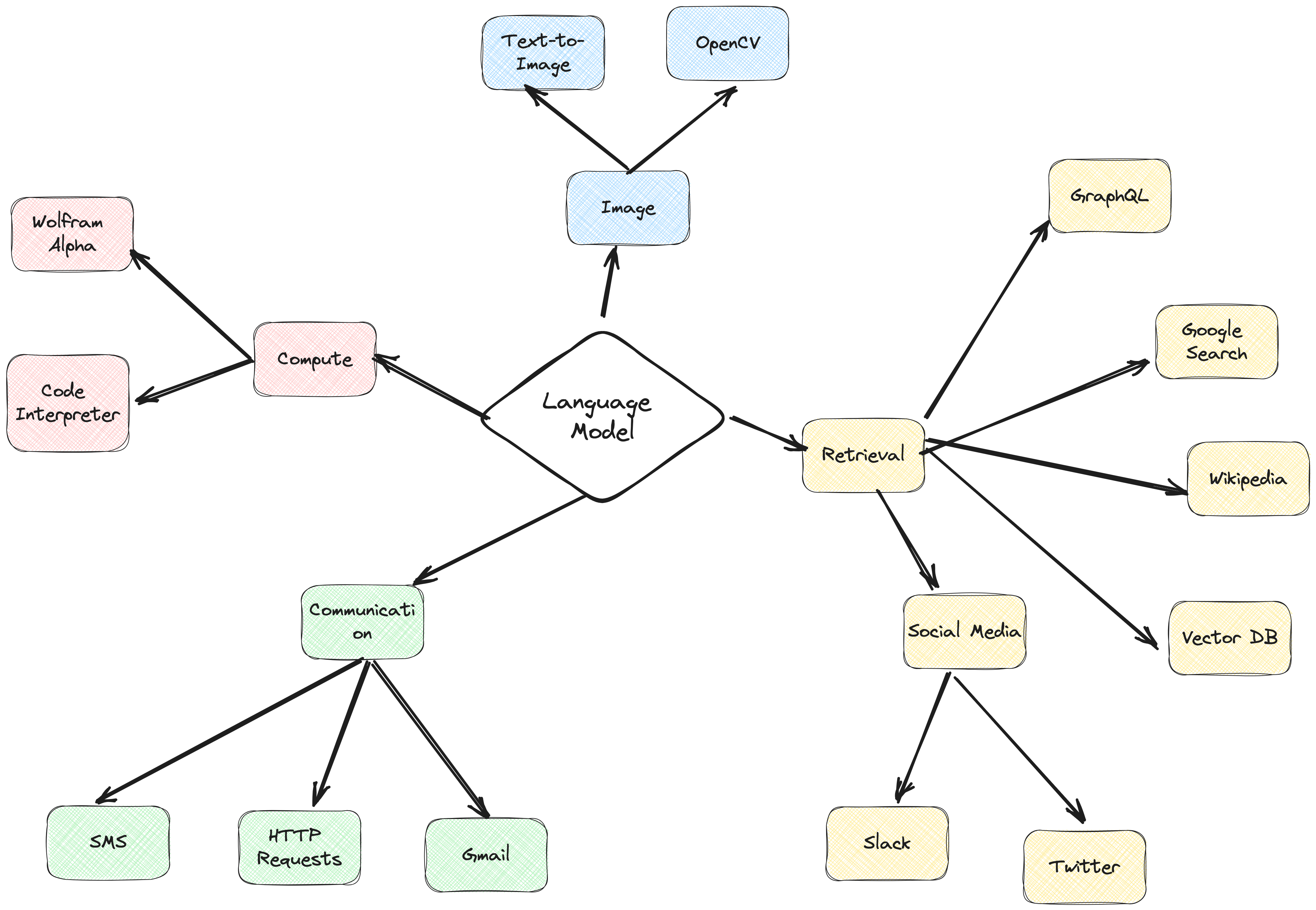
إطار عمل وكيل ActionWeaver هو إطار عمل لتطبيق الذكاء الاصطناعي يضع استدعاء الوظائف في جوهره. لقد تم تصميمه لتمكين الدمج السلس لأنظمة الحوسبة التقليدية مع قدرات التفكير القوية لنماذج نماذج اللغة. تم بناء ActionWeaver حول مفهوم استدعاء وظائف LLM، في حين أن الأطر الشائعة مثل Langchain وHaystack مبنية على مفهوم خطوط الأنابيب.

اقرأ المزيد على: https://thinhdanggroup.github.io/function-calling-openai/
يمكن للمطورين إرفاق أي وظيفة بايثون كأداة باستخدام ديكور بسيط. في المثال التالي، نقدم الإجراء get_sources_list، والذي سيتم استدعاؤه بواسطة OpenAI API.
يستخدم ActionWeaver توقيع الطريقة المزخرفة وسلسلة المستندات كوصف، ويمررها إلى واجهة برمجة تطبيقات وظيفة OpenAI.
يوفر ActionWeaver غلافًا خفيفًا يعتني بتحويل معلومات docstring/decorator إلى التنسيق الصحيح لـ OpenAI API.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True عند الإضافة إلى إجراء ما يعني أن LLM سيعيد مخرجات الوظيفة على الفور، ولكن هذا يقيد أيضًا LLM من إجراء استدعاءات متعددة للوظائف. على سبيل المثال، إذا سُئل عن الطقس في مدينة نيويورك وسان فرانسيسكو، فسيقوم النموذج باستدعاء وظيفتين منفصلتين بالتسلسل لكل مدينة. ومع ذلك، مع stop=True ، تتم مقاطعة هذه العملية بمجرد أن تقوم الوظيفة الأولى بإرجاع معلومات الطقس لمدينة نيويورك أو سان فرانسيسكو، اعتمادًا على المدينة التي تستعلم عنها أولاً.
للحصول على فهم أكثر تعمقًا لكيفية عمل هذا الروبوت تحت الغطاء، يرجى الرجوع إلى ملف bot.py. بالإضافة إلى ذلك، يمكنك استكشاف مستودع ActionWeaver لمزيد من التفاصيل.
يسمح إنشاء آثار الاستدلال للنموذج بتحفيز خطط العمل وتتبعها وتحديثها، وحتى التعامل مع الاستثناءات. يستخدم هذا المثال ReAct مع سلسلة الأفكار (CoT).
سلسلة الفكر
المنطق + العمل
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
تلعب كل من تقنيات سلسلة الفكر (CoT) وتقنيات المطالبة ReAct دورًا في هذه الأمثلة. وإليك الطريقة:
سلسلة الفكر (CoT) المطالبة:
رد الفعل المطالبة:
باختصار، يلعب كل من CoT وReAct دورًا حاسمًا في هذه الأمثلة. يمكّن CoT النموذج من التفكير خطوة بخطوة واختيار الإجراءات المناسبة، بينما تعمل ReAct على توسيع هذه الوظيفة من خلال السماح للنموذج بالتفاعل مع بيئته وتحديث خططه وفقًا لذلك. هذا المزيج من التفكير والعمل يجعل نماذج اللغة الكبيرة أكثر مرونة وتنوعًا، مما يمكنها من التعامل مع نطاق أوسع من المهام والمواقف.
لنبدأ بطرح سؤال على وكيلنا. في هذه الحالة، "ما هي المانجو؟" . أول شيء سيحدث هو أنه سيحاول "استدعاء" أي معلومات ذات صلة باستخدام تشابه تضمين المتجهات. سيقوم بعد ذلك بصياغة رد بالمحتوى الذي "استذكره"، أو سيقوم بإجراء بحث على الويب. نظرًا لأن قاعدة معارفنا فارغة حاليًا، نحتاج إلى إضافة بعض المصادر قبل أن نتمكن من صياغة الرد.
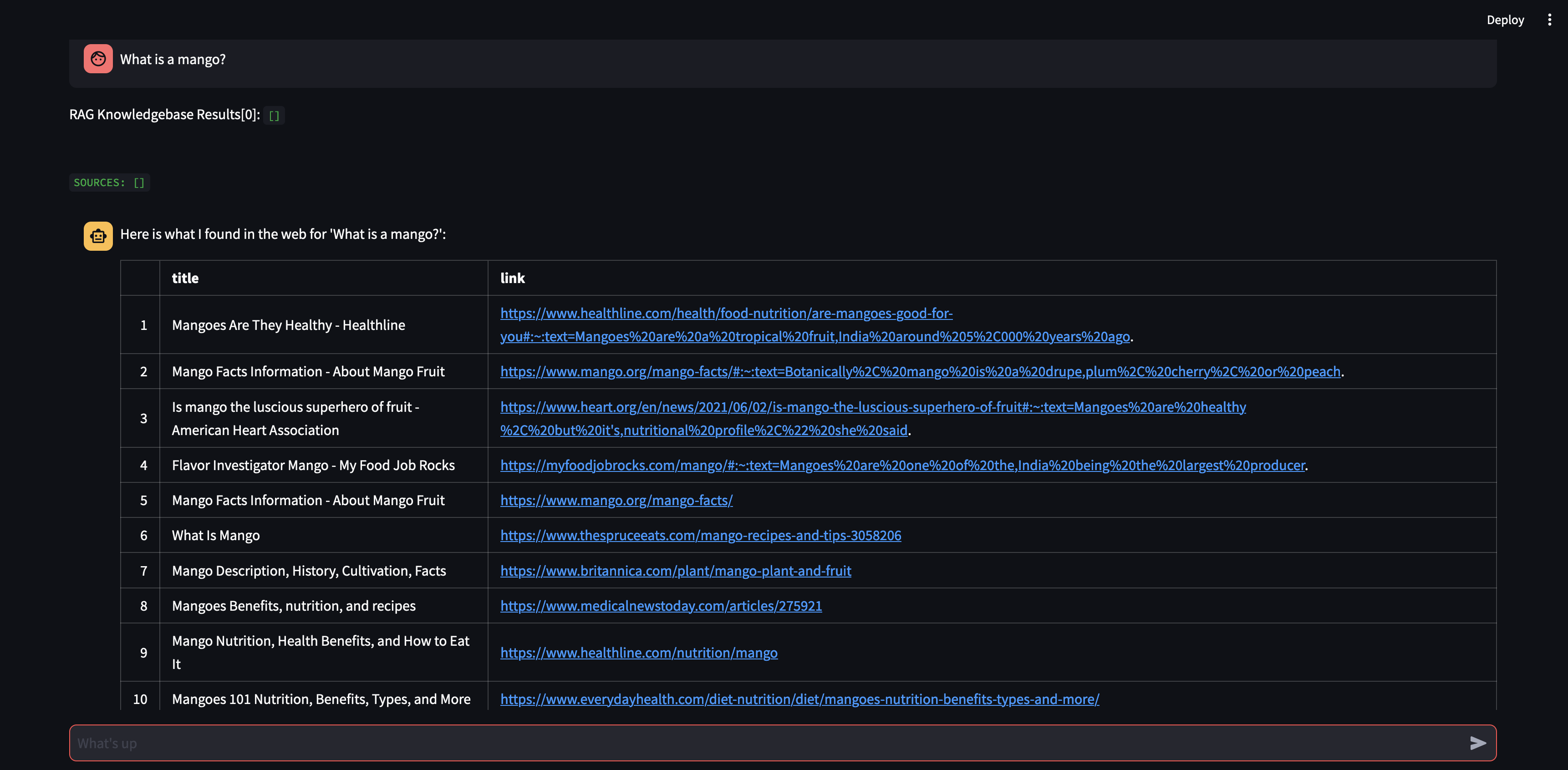
نظرًا لأن الروبوت غير قادر على تقديم إجابة باستخدام المحتوى الموجود في قاعدة بيانات المتجهات، فقد بدأ بحث Google للعثور على المعلومات ذات الصلة. يمكننا الآن أن نخبره بالمصادر التي يجب أن "يتعلمها". في هذه الحالة، سنطلب منه التعرف على المصدرين الأولين من نتائج البحث.
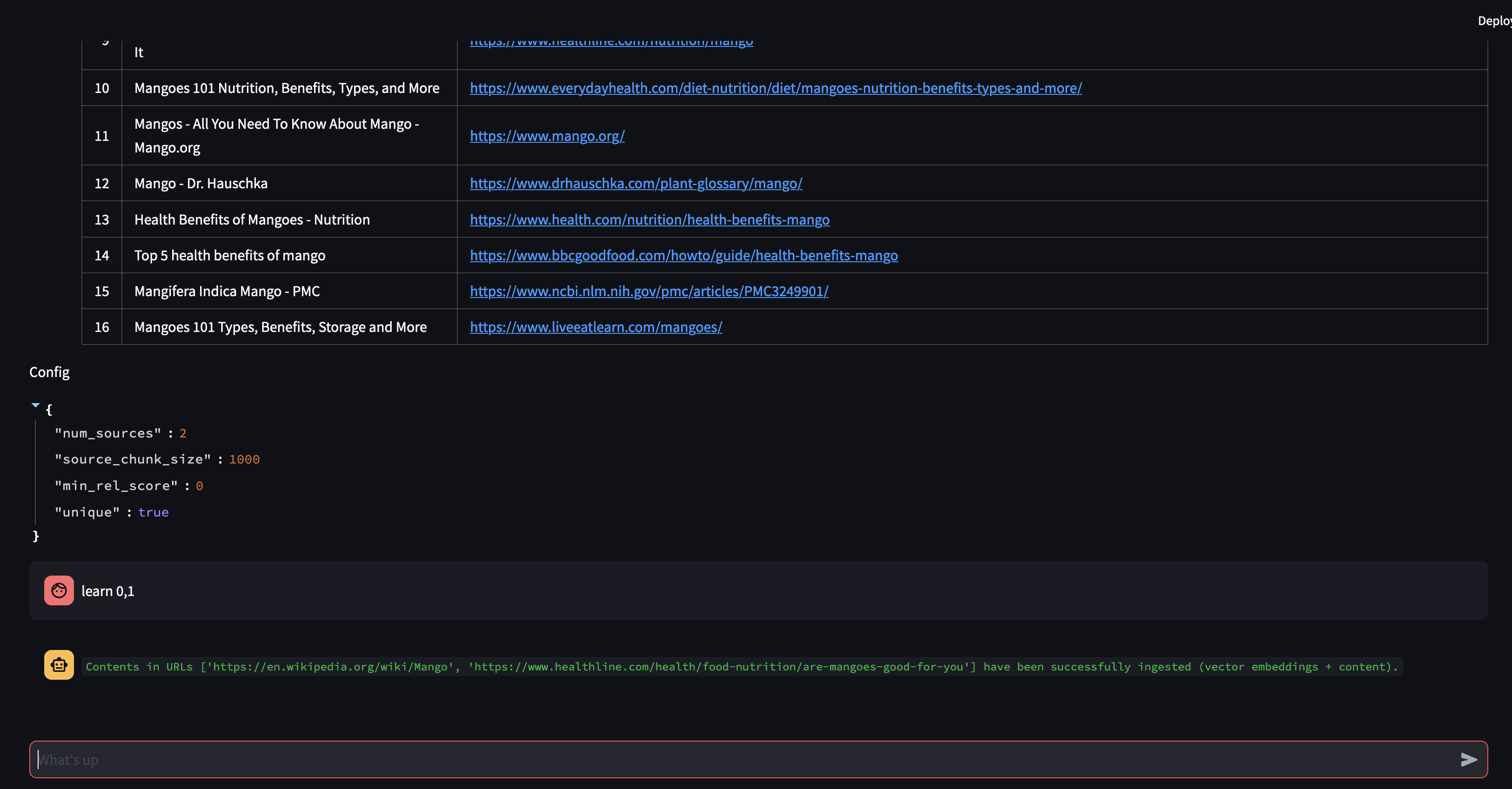
بعد ذلك، دعونا نعدل استراتيجية RAG! لنجعله يستخدم مصدرًا واحدًا فقط، ونجعله يستخدم حجمًا صغيرًا مكونًا من 500 حرف.
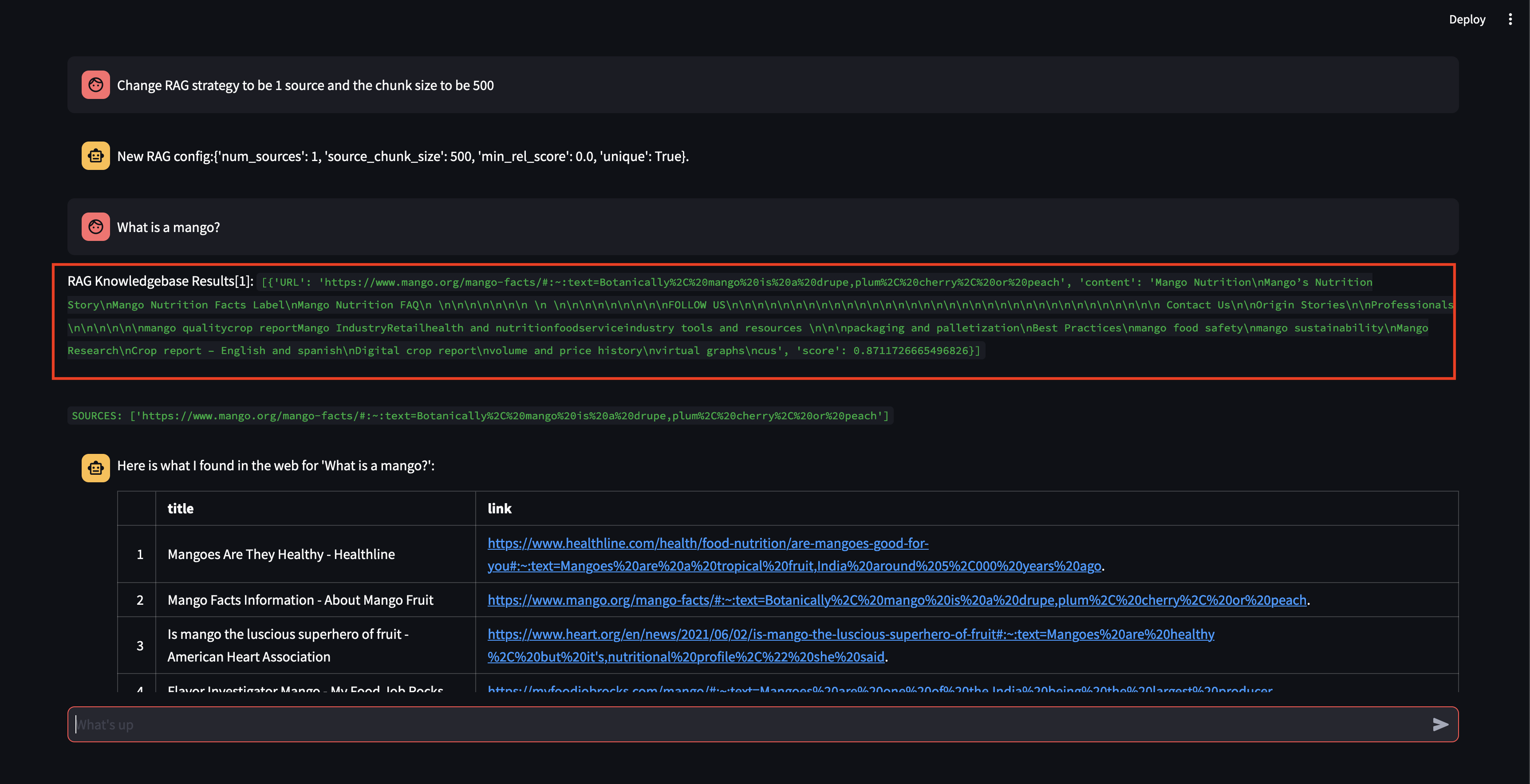
لاحظ أنه على الرغم من أنه كان قادرًا على استرداد جزء ما، مع درجة صلة عالية إلى حد ما، إلا أنه لم يكن قادرًا على إنشاء استجابة لأن حجم الجزء كان صغيرًا جدًا ولم يكن محتوى الجزء مناسبًا بدرجة كافية لصياغة استجابة. نظرًا لأنه لم يتمكن من إنشاء استجابة باستخدام الجزء الصغير، فقد أجرى بحثًا على الويب نيابة عن المستخدم.
دعونا نرى ما سيحدث إذا قمنا بزيادة حجم القطعة إلى 3000 حرف بدلاً من 500.
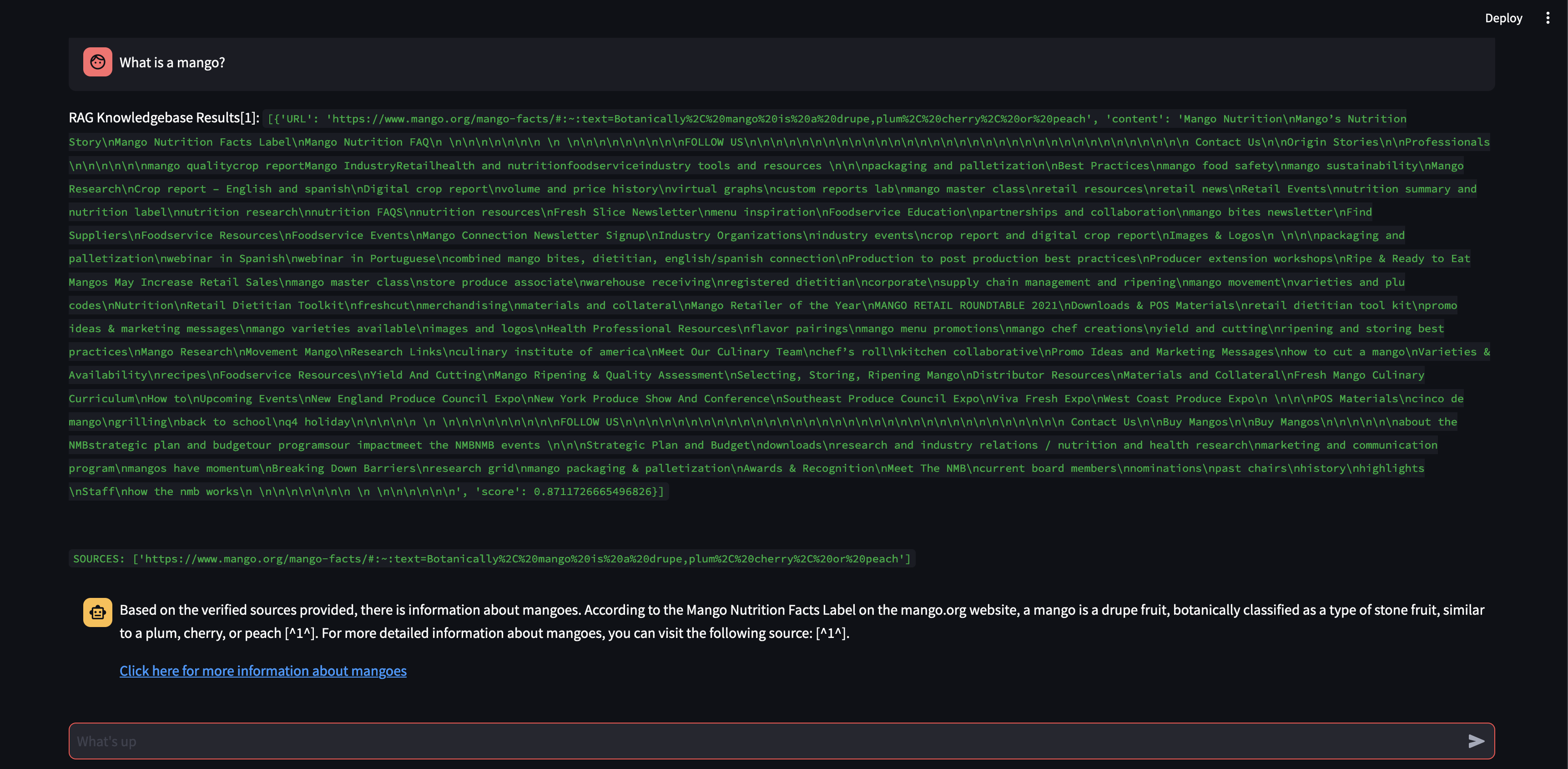
الآن، مع حجم أكبر للجزء، أصبح قادرًا على صياغة الاستجابة بدقة باستخدام المعرفة من قاعدة بيانات المتجهات!
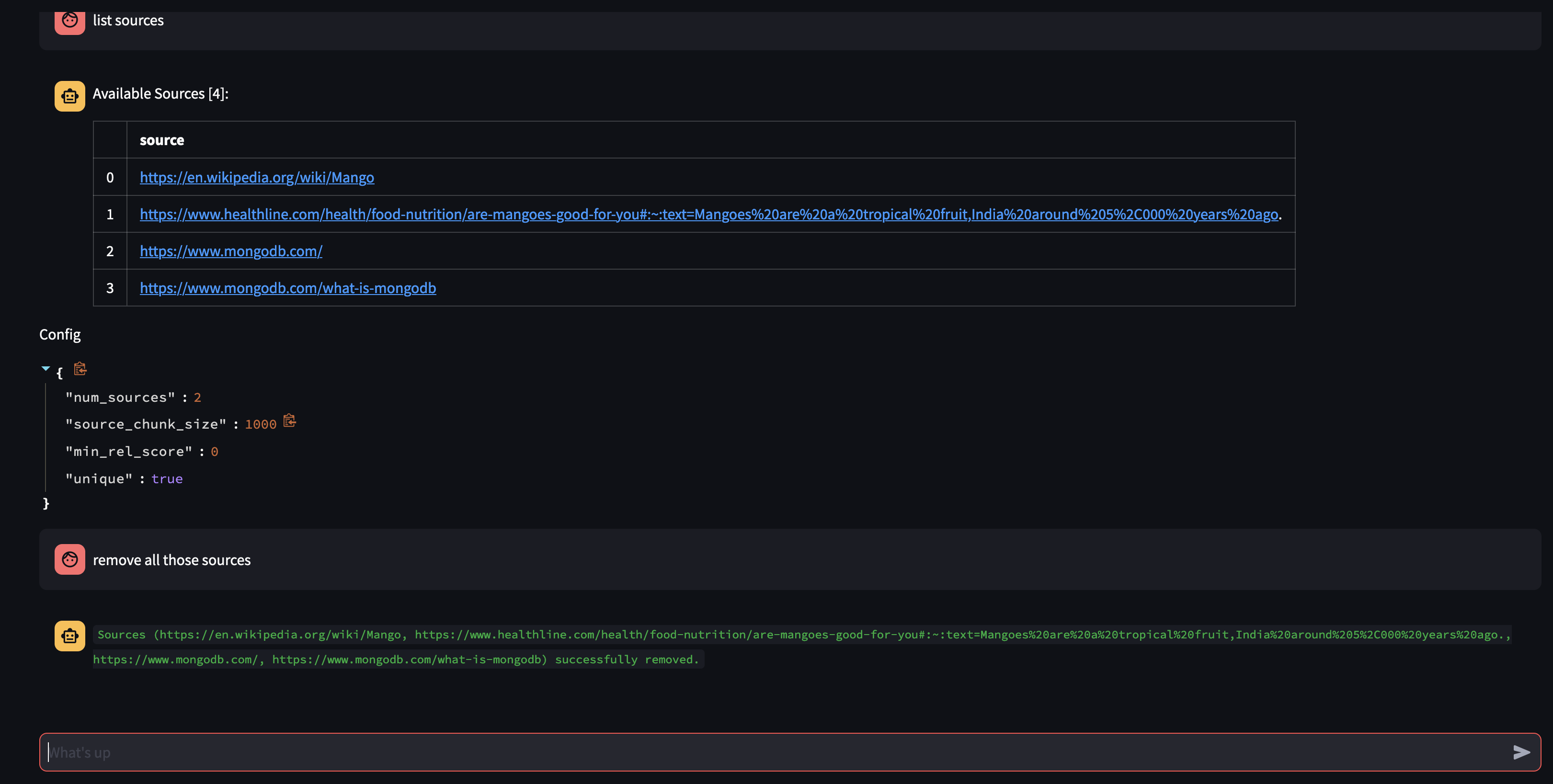
دعونا نرى ما هو متاح في قاعدة معارف الوكيل من خلال سؤاله: ما هي المصادر المتوفرة لديك في قاعدة معارفك؟
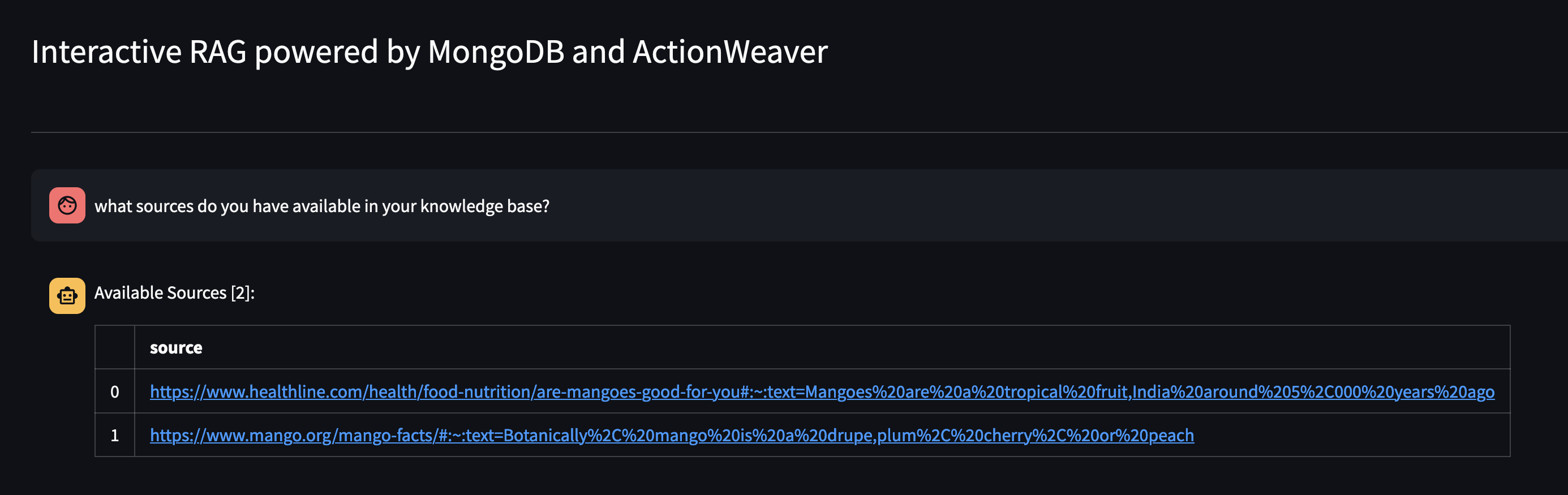
إذا كنت تريد إزالة مورد معين، فيمكنك القيام بشيء مثل:
USER: remove source 'https://www.oracle.com' from the knowledge base
لإزالة جميع المصادر الموجودة في المجموعة - يمكننا القيام بشيء مثل:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
قدم هذا العرض التوضيحي لمحة عن الأعمال الداخلية لوكيل الذكاء الاصطناعي لدينا، حيث أظهر قدرته على التعلم والرد على استفسارات المستخدم بطريقة تفاعلية. لقد شهدنا كيف تجمع بسلاسة قاعدة معارفها الداخلية مع البحث على الويب في الوقت الفعلي لتقديم معلومات شاملة ودقيقة. إن إمكانات هذه التكنولوجيا هائلة، وتمتد إلى ما هو أبعد من مجرد الإجابة على الأسئلة. لن يكون أي من هذا ممكنًا بدون سحر واجهة برمجة تطبيقات استدعاء الوظائف .
هذا مستوحى من https://github.com/TengHu/Interactive-RAG
نحن نرحب بمساهمات مجتمع المصادر المفتوحة.
ترخيص أباتشي 2.0


