content dicovery platform gcp
1.0.0
يحتوي هذا المستودع على التعليمات البرمجية والأتمتة اللازمة لإنشاء منصة بسيطة لاكتشاف المحتوى مدعومة بنماذج VertexAI الأساسية. يجب أن يكون هذا النظام الأساسي قادرًا على التقاط محتوى المستندات (محرر مستندات Google في البداية)، ومع هذا المحتوى، يتم إنشاء ناقلات التضمينات ليتم تخزينها في قاعدة بيانات متجهة مدعومة بواسطة VertexAI Matching Engine، ويمكن استخدام هذه التضمينات لاحقًا لوضع سياق لسؤال عام للمستهلك الخارجي ومع يطلب هذا السياق إجابة لنموذج VertexAI الأساسي للحصول على إجابة.
يمكن فصل النظام الأساسي إلى 4 مكونات رئيسية، طبقة خدمة الوصول، وخط أنابيب التقاط المحتوى، وتخزين المحتوى، وLLMs. تتيح طبقة الخدمات للمستهلكين الخارجيين إرسال طلبات استيعاب المستندات ثم إرسال استفسارات حول المحتوى المضمن في المستندات التي تم استيعابها مسبقًا. يعد مسار التقاط المحتوى مسؤولاً عن التقاط محتوى المستند في NRT واستخراج التضمينات وتعيين تلك المضمنة بمحتوى حقيقي يمكن استخدامه لاحقًا لوضع أسئلة المستخدمين الخارجيين في سياق LLM. يتم فصل تخزين المحتوى إلى 3 أغراض مختلفة، ضبط LLM الدقيق ومطابقة التضمينات عبر الإنترنت والمحتوى المقسم، ويتم التعامل مع كل منها من خلال نظام تخزين متخصص والغرض العام هو تخزين المعلومات التي تحتاجها مكونات النظام الأساسي لتنفيذ عملية الاستيعاب والاستعلام يستخدم الحالات. أخيرًا وليس آخرًا، تستفيد المنصة من درجتي LLM متخصصتين لإنشاء عمليات تضمين في الوقت الفعلي من محتوى المستند الذي تم استيعابه وأخرى مسؤولة عن إنشاء الإجابات التي يطلبها مستخدمو النظام الأساسي.
يتم تنفيذ جميع المكونات الموضحة سابقًا باستخدام خدمات Google Cloud Platform المتاحة للعامة. لتعدادها: Cloud Build، وCloud Run، وCloud Dataflow، وCloud Pubsub، وCloud Storage، وCloud Bigtable، وVertex AI Matching Engine، ونماذج Vertex AI Fundational (التضمينات والنصوص)، جنبًا إلى جنب مع Google Docs وGoogle Drive كمعلومات للمحتوى. مصادر.
توضح الصورة التالية كيف تتفاعل المكونات المختلفة للهندسة المعمارية والتقنيات فيما بينها.
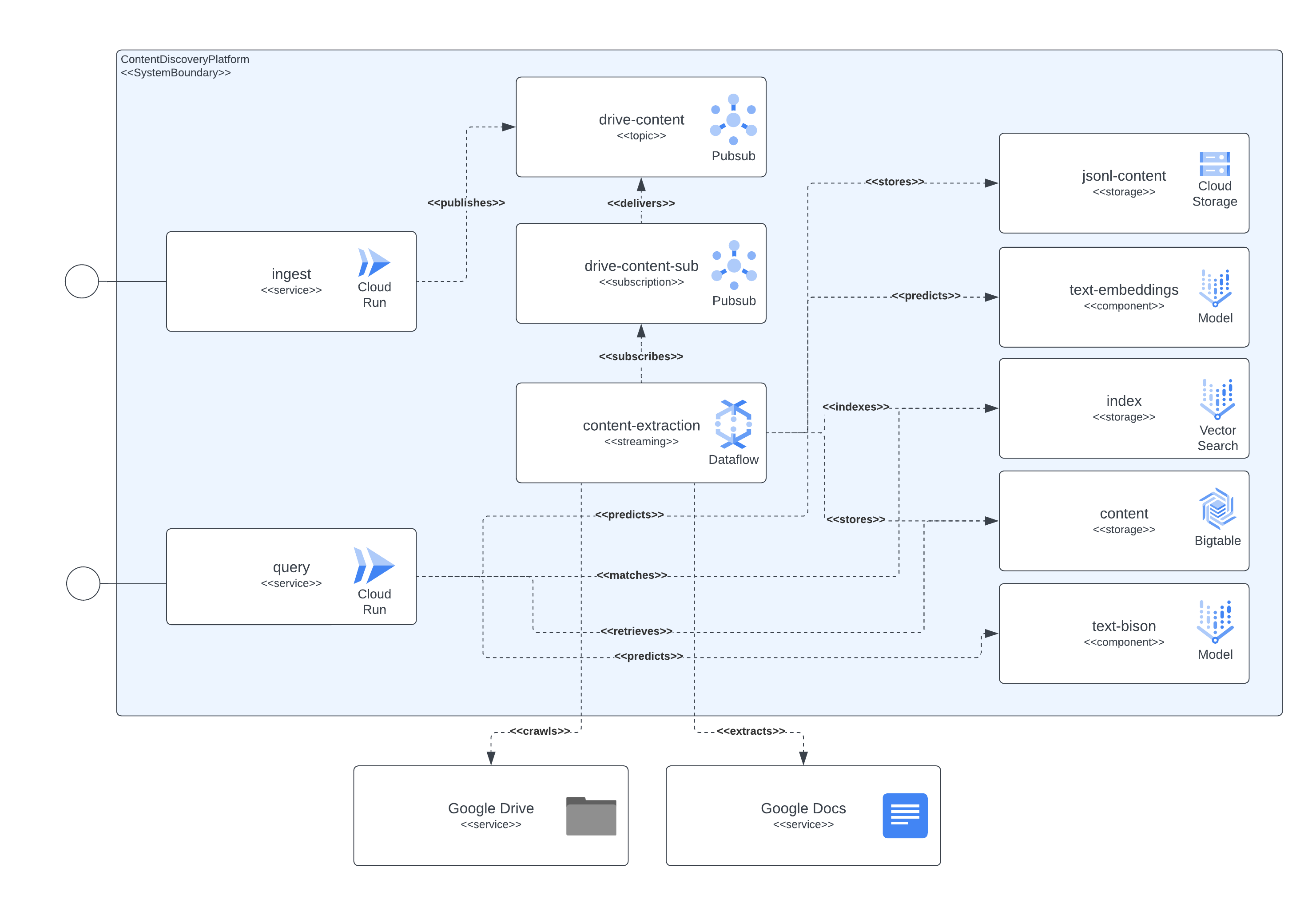
يستخدم هذا النظام الأساسي Terraform لإعداد جميع مكوناته. بالنسبة لأولئك الذين لا يتمتعون حاليًا بدعم أصلي، قمنا بإنشاء أغلفة null_resource، وهذه حلول بديلة جيدة ولكنها تميل إلى أن تكون ذات حواف خشنة جدًا، لذا كن على دراية بالأخطاء المحتملة.
يمكن أن يستغرق النشر الكامل اعتبارًا من اليوم (يونيو 2023) ما يصل إلى 90 دقيقة حتى يكتمل، والسبب الأكبر هو المكونات ذات الصلة بمحرك المطابقة والتي تستغرق معظم هذا الوقت ليتم إنشاؤها وإتاحتها بسهولة. مع مرور الوقت، سوف تتحسن أوقات التشغيل الممتدة هذه.
يجب أن يكون الإعداد قابلاً للتنفيذ من البرامج النصية المضمنة في المستودع.
هناك بعض المتطلبات التي يجب الوفاء بها لنشر هذه المنصة وهي:
لكي يتم نشر جميع المكونات في Google Cloud Platform، نحتاج إلى إنشاء بنية أساسية ونشر الخدمات وخطوط الأنابيب لاحقًا.
ولتحقيق ذلك، قمنا بتضمين البرنامج النصي start.sh الذي يقوم بشكل أساسي بتنسيق البرامج النصية الأخرى المضمنة لتحقيق هدف النشر الكامل.
لقد قمنا أيضًا بتضمين برنامج نصي cleanup.sh مسؤول عن تدمير البنية التحتية وتنظيف البيانات المجمعة.
في الحالات العادية، سيتم إنشاء مستندات Google Workspace في نفس المؤسسة التي تستضيف المشروع حيث يتم تشغيل مسار استيعاب المحتوى، ومن أجل منح الأذونات لتلك المستندات، قم بإضافة حساب الخدمة الذي يقوم بتشغيل المسار إلى المستندات، أو مجلد المستندات ، ينبغي أن يكون كافيا.
في حالة الحاجة إلى الوصول إلى المستندات أو المجلدات الموجودة خارج مؤسسة المشروع، يجب إكمال خطوة إضافية. بمجرد إعداد البنية الأساسية، ستقوم عملية النشر بطباعة تعليمات لمنح حساب الخدمة الذي يقوم بتشغيل أذونات مسار استخراج المحتوى لانتحال صفة الوصول إلى مستندات Google Workspace من خلال التفويض على مستوى النطاق. يمكن الاطلاع على المعلومات اللازمة لإكمال الخطوات هنا: https://developers.google.com/workspace/guides/create-credentials#Optional_set_up_domain-wide_delegation_for_a_service_account
يكشف الحل عن اثنين من الموارد من خلال GCP CloudRun وAPI Gateway، والتي يمكن استخدامها للتفاعل مع استيعاب المحتوى واستعلامات اكتشاف المحتوى. في جميع الأمثلة، نستخدم سلسلة <service-address> الرمزية، والتي يجب استبدالها بعنوان URL المقدم من CloudRun ( backend_service_url من مخرجات Terraform) أو بوابة API ( sevice_url من مخرجات Terraform) بعد اكتمال نشر الخدمة.
عند الحاجة إلى تفاعلات CORS، يمكن استخدام نقاط نهاية بوابة API عند البحث عن إكمال بروتوكول الاختبار المبدئي. لا يدعم CloudRun حاليًا أوامر OPTIONS غير المصادق عليها، ولكن تلك المسارات المعروضة من خلال API Gateway تدعمها.
هذه الخدمة قادرة على استيعاب البيانات من المستندات المستضافة في Google Drive أو الطلبات متعددة الأجزاء المضمنة ذاتيًا والتي تحتوي على معرف المستند ومحتوى المستند المشفر على أنه ثنائي.
يتم استيعاب Google Drive عن طريق إرسال طلب HTTP مماثل للمثال التالي
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' سيشير هذا الطلب إلى النظام الأساسي للحصول على المستند من url المقدم وفي حالة أن حساب الخدمة الذي يقوم بتشغيل العرض لديه أذونات الوصول إلى المستند، فسوف يستخرج المحتوى منه ويخزن المعلومات للفهرسة والاكتشاف والاسترجاع لاحقًا.
يمكن أن يحتوي الطلب على عنوان URL لمستند Google أو مجلد Google Drive، وفي الحالة الأخيرة، سيزحف العرض إلى المجلد لتتم معالجة المستندات. من الممكن أيضًا استخدام urls للخاصية التي تتوقع JSONArray من قيم string ، كل منها عنوان URL صالح لمستند Google.
في حالة الرغبة في تضمين محتوى مقالة أو مستند أو صفحة يمكن الوصول إليها محليًا بواسطة عميل استيعاب، فإن استخدام نقطة النهاية متعددة الأجزاء يجب أن يكون كافيًا لاستيعاب المستند. راجع أمر curl التالي كمثال، تتوقع الخدمة أن يتم تعيين حقل نموذج documentId لتحديد المحتوى وفهرسته بشكل موحد:
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartتعرض هذه الخدمة إمكانية الاستعلام لمستخدمي النظام الأساسي، عن طريق إرسال استعلامات نصية طبيعية إلى الخدمات وبالنظر إلى وجود فهارس محتوى بالفعل بعد استيعابها في النظام الأساسي، ستعود الخدمة بمعلومات ملخصة من خلال نموذج LLM.
يمكن أن يتم التفاعل مع الخدمة من خلال تبادل REST، على غرار تلك الخاصة بجزء العرض، كما هو موضح في المثال التالي.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}توجد حالة خاصة هنا، حيث لا توجد معلومات مخزنة حتى الآن لموضوع معين، إذا كان هذا الموضوع يقع ضمن مشهد Google Cloud Platform، فسيعمل النموذج كخبير نظرًا لأننا نقوم بإعداد مطالبة تشير إلى ذلك لطلب النموذج.
في حالة الرغبة في الحصول على نوع تبادل أكثر وعيًا بالسياق مع الخدمة، يجب توفير معرف الجلسة (خاصية sessionId في طلب JSON) للخدمة لاستخدامها كمفتاح تبادل محادثة. سيتم استخدام مفتاح المحادثة هذا لإعداد السياق الصحيح للنموذج (من خلال تلخيص التبادلات السابقة) وتتبع آخر 5 تبادلات (على الأقل). تجدر الإشارة أيضًا إلى أنه سيتم الاحتفاظ بسجل التبادل لمدة 24 ساعة، ويمكن تغيير ذلك كجزء من سياسات gc الخاصة بتخزين BigTable في النظام الأساسي.
التالي مثال لمحادثة واعية بالسياق:
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

