ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
مقدمة يوتيوب • دردشة ديسكورد • توثيق كامل
يعد تثبيت UStore أمرًا سهلاً للغاية، كما أن الاستخدام بسيط مثل dict Python.
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' لقد قمنا للتو بإنشاء قاعدة بيانات للمعاملات مضمنة في الذاكرة وأضفنا إدخالاً واحدًا في مجموعتها main . هل تفضل تلك البيانات الموجودة على القرص؟ تغيير سطر واحد.
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )هل تفضل الاتصال بخادم UStore البعيد؟ UStore يأتي مع واجهة Apache Arrow Flight RPC!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) هل تقوم بتخزين MultiDiGraph الشبيه بـ NetworkX؟ أو DataFrame مثل الباندا؟
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1قد تبدو استدعاءات الوظائف متطابقة، لكن التنفيذ الأساسي يمكن أن يعالج مئات تيرابايت من البيانات الموضوعة في مكان ما في الذاكرة الدائمة على جهاز بعيد.
هل يقوم شخص آخر بتحديث هذه المجموعات في نفس الوقت؟ قم بتجميع عملياتك لضمان الاتساق!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )حتى الآن قمنا بتغطية غيض من UStore فقط. يمكنك استخدامه ل...
ولكن يمكن لـ USstore المزيد. هنا الخريطة:
## الاستخدام الأساسي
ليس المقصود من UStore أن تكون قاعدة بيانات فحسب، بل أن تكون مجموعة أدوات "إنشاء قاعدة البيانات الخاصة بك" ومعيارًا مفتوحًا لقواعد بيانات NoSQL التي يحتمل أن تكون معاملات، مع تحديد الواجهات الثنائية ذات النسخة الصفرية لعمليات "الإنشاء والقراءة والتحديث والحذف"، أو CRUD للاختصار.
يمكن لعدد قليل من رؤوس C99 البسيطة ربط أي محرك تخزين أساسي تقريبًا بالعديد من برامج تشغيل اللغة عالية المستوى، مما يوسع دعمها لقيم السلسلة الثنائية إلى الرسوم البيانية ومستندات المخطط المرن وطرائق أخرى، بهدف استبدال MongoDB وNeo4J وPinecone وElasticSearch. مع نظام المعاملات ACID واحد.
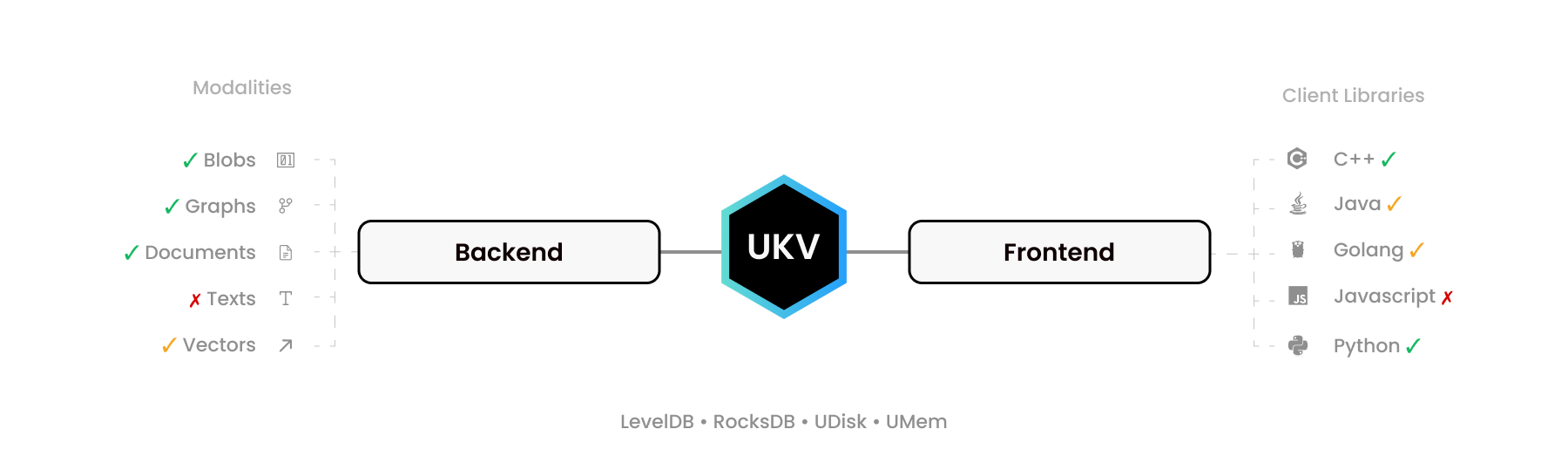
يوفر Redis، على سبيل المثال، أهدافًا مماثلة لـ RediSearch وRedisJSON وRedisGraph. يقوم UStore بذلك بشكل أفضل، مما يسمح لك بإضافة متاجر القيمة الرئيسية (KVS) المفضلة لديك، المضمنة أو المستقلة أو المقسمة، مثل FoundationDB، مما يضاعف وظائفه.
يمكن وضع الكائنات الثنائية الكبيرة داخل USore. سيختلف الأداء بشكل كبير اعتمادًا على التكنولوجيا الأساسية المستخدمة. ستكون مجموعة UCSet الموجودة في الذاكرة هي الأسرع، ولكنها الأقل ملاءمة للكائنات الأكبر حجمًا. يمكن لـ UDisk الثابت، عند تكوينه بشكل صحيح، أن يتجاوز نواة Linux تمامًا، بما في ذلك طبقة نظام الملفات، ويتعامل مباشرة مع أجهزة الكتلة.
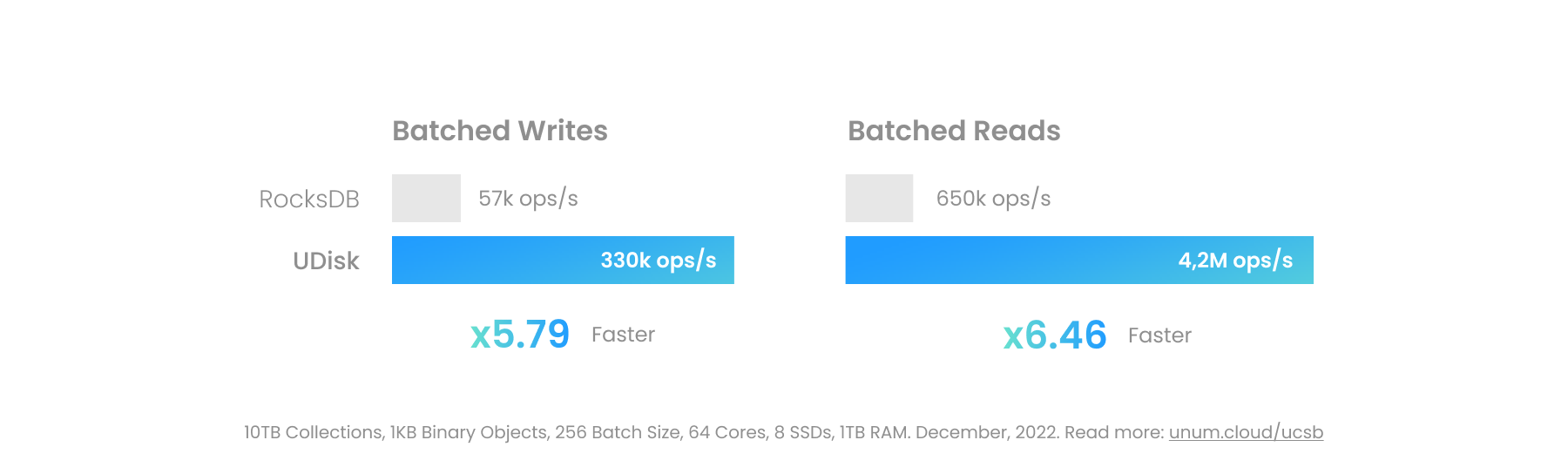
يمكن أن تتجاوز عمليات الإدخال والإخراج المستمرة الحديثة على الخوادم المتطورة 100 جيجابايت/ثانية لكل مقبس عندما تكون مبنية على برامج تشغيل مساحة المستخدم مثل SPDK. وهذا قريب من إنتاجية العالم الحقيقي لذاكرة الوصول العشوائي المتطورة ويفتح حالات استخدام جديدة وغير مألوفة لقواعد البيانات. يمكن للمرء الآن وضع ملف فيديو بحجم جيجابايت في قاعدة بيانات معاملات ACID، بجوار بيانات التعريف الخاصة به مباشرةً، بدلاً من استخدام مخزن كائنات منفصل، مثل MinIO.
JSON هو تنسيق المستندات الأكثر استخدامًا هذه الأيام. تدعم مجموعات مستندات UStore JSON، بالإضافة إلىMessagePack، وBSON، التي يستخدمها MongoDB.

لم يتوسع UStore أفقيًا بعد، ولكنه يوفر أداءً أعلى بكثير للعقدة الواحدة، ولديه قابلية توسع عمودية خطية تقريبًا على الأنظمة متعددة النواة بفضل مكتبات simdjson و yyjson مفتوحة المصدر. علاوة على ذلك، للتفاعل مع البيانات، لا تحتاج إلى لغة استعلام مخصصة مثل MQL. بدلاً من ذلك، نعطي الأولوية لمعايير RFC المفتوحة لتجنب أقفال البائعين:
تواجه قواعد بيانات Graph الحديثة، مثل Neo4J، أعباء عمل كبيرة. فهي تتطلب قدرًا كبيرًا جدًا من ذاكرة الوصول العشوائي (RAM)، وتقوم خوارزمياتها بمراقبة البيانات مدخلاً واحدًا في كل مرة. نحن نقوم بالتحسين على كلا الجبهتين:
توفر متاجر الميزات وقواعد بيانات المتجهات، مثل Pinecone وMilvus وUSearch فهارس مستقلة للبحث عن المتجهات. ينفذها UStore كطريقة منفصلة، على قدم المساواة مع المستندات والرسوم البيانية. سمات:
يبدو UStore لـ Python وC++ مختلفين تمامًا. يحاكي Python SDK مكتبات Python الأخرى - Pandas وNetworkX. وبالمثل، توفر مكتبة C++ الواجهة التي يتوقعها مطورو C++.
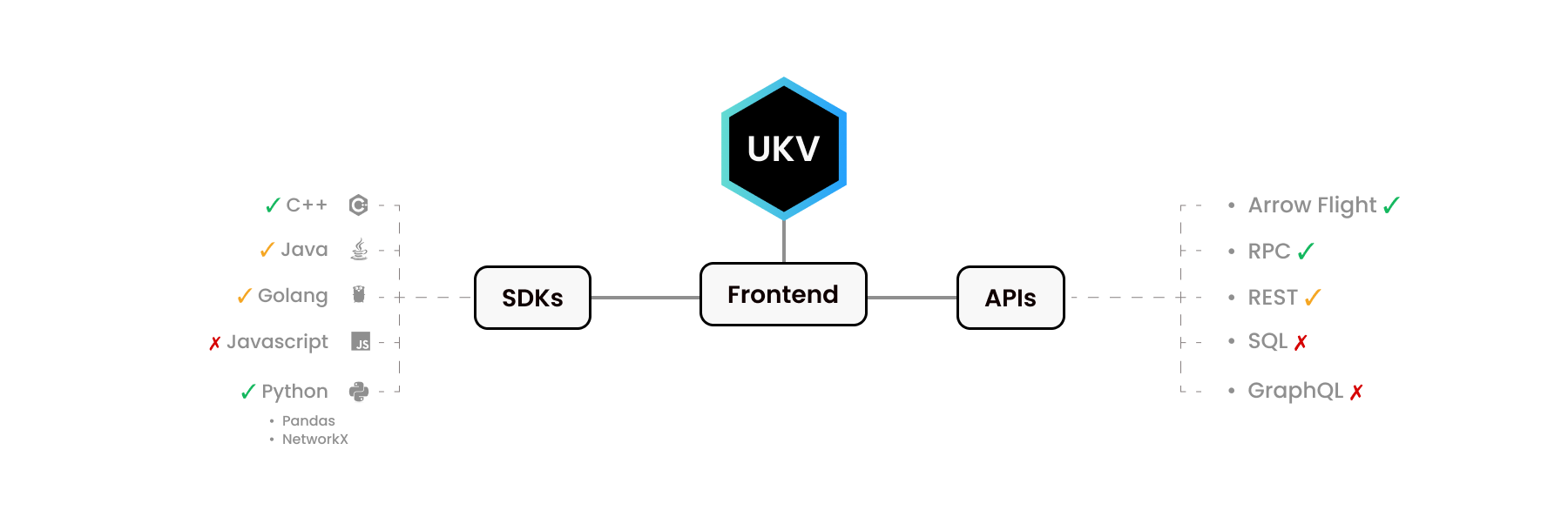
كما نعلم، يستخدم الناس لغات مختلفة لأغراض مختلفة. لا يتم تنفيذ بعض وظائف المستوى C لبعض اللغات. إما لأنه لم يكن هناك طلب عليه، أو لأننا لم نصل إليه بعد.
| اسم | صفقة | المجموعات | دفعات | المستندات | الرسوم البيانية | نسخ |
|---|---|---|---|---|---|---|
| معيار C99 | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| سي ++ SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| بايثون SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| جولانج SDK | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| جافا SDK | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| واجهة برمجة تطبيقات رحلة السهم | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
تحتوي بعض الواجهات الأمامية هنا على أنظمة بيئية كاملة حولها! على سبيل المثال، تمتلك Apache Arrow Flight API برامج تشغيل خاصة بها لـ C وC++ وC# وGo وJava وJavaScript وJulia وMATLAB وPython وR وRuby وRust.
يمكن استخدام المحركات التالية بالتبادل تقريبًا. تاريخيًا، كان LevelDB هو الأول. ثم قام RocksDB بتحسين الوظائف والأداء. وهي الآن بمثابة الأساس لنصف الشركات الناشئة في مجال إدارة قواعد البيانات (DBMS).
| مستوىDB | RocksDB | يوديسك | UCSet | |
|---|---|---|---|---|
| سرعة | 1x | 2x | 10x | 30x |
| مثابر | ✓ | ✓ | ✓ | ✗ |
| المعاملات | ✗ | ✓ | ✓ | ✓ |
| حظر دعم الجهاز | ✗ | ✗ | ✓ | ✗ |
| التشفير | ✗ | ✗ | ✓ | ✗ |
| الساعات | ✗ | ✓ | ✓ | ✓ |
| لقطات | ✓ | ✓ | ✓ | ✗ |
| أخذ العينات العشوائية | ✗ | ✗ | ✓ | ✓ |
| التعداد بالجملة | ✗ | ✗ | ✓ | ✓ |
| المجموعات المسماة | ✗ | ✓ | ✓ | ✓ |
| مفتوح المصدر | ✓ | ✓ | ✗ | ✓ |
| التوافق | أي | أي | لينكس | أي |
| معيل | جوجل | فيسبوك | واحد | واحد |
تم تصميم وصيانة كل من UCSet وUDisk بواسطة Unum. كلاهما مكتملان بالميزات، ولكن الميزة الأكثر أهمية التي توفرها بدائلنا هي الأداء. من السهل أن تكون سريعًا في الذاكرة. يمكن العثور على المنطق الأساسي لـ UCSet في مكتبة ucset ذات الرأس فقط.
كان تصميم UDisk بمثابة مسعى أكثر تحديًا لمدة 7 سنوات. لقد تضمن اختراع هياكل جديدة تشبه الشجرة، وتنفيذ تجاوز جزئي للنواة باستخدام io_uring ، وتجاوز كامل باستخدام SPDK ، وتسريع CUDA GPU، وحتى نظام ملفات داخلي مخصص. UDisk هو المحرك الأول الذي تم تصميمه من الصفر مع الأخذ في الاعتبار البنى المتوازية وتجاوز النواة .
الذرية مضمونة دائمًا. حتى في عمليات الكتابة غير المتعلقة بالمعاملات - إما أن تمر كافة التحديثات أو تفشل جميعها.
يتم تنفيذ الاتساق في أدق شكل ممكن - "التسلسل الصارم" مما يعني أن:
ومع ذلك، يمكن تعديل السلوك الافتراضي على مستوى عمليات محددة. لذلك، يمكن تمرير ::ustore_option_transaction_dont_watch_k إلى ustore_transaction_init() أو أي عملية قراءة/كتابة للمعاملات، للتحكم في عمليات التحقق من الاتساق أثناء التدريج.
| يقرأ | يكتب | |
|---|---|---|
| رأس | مسلسل صارم | مسلسل صارم |
| المعاملات على اللقطات | مسلسل | مسلسل صارم |
| المعاملات بدون لقطات | مسلسل صارم | مسلسل صارم |
| المعاملات بدون الساعات | مسلسل صارم | تسلسلي |
إذا كان هذا الموضوع جديدًا بالنسبة لك، فيرجى مراجعة مدونة Jepsen.io حول الاتساق.
| يقرأ | يكتب | |
|---|---|---|
| المعاملات على اللقطات | ✓ | ✓ |
| المعاملات بدون لقطات | ✗ | ✓ |
لا تنطبق المتانة على الأنظمة الموجودة في الذاكرة بحكم التعريف. في الأنظمة الهجينة أو المستمرة، نفضل تعطيله افتراضيًا. يفضل كل نظام إدارة قواعد بيانات يعتمد على KVS تقريبًا تنفيذ آلية المتانة الخاصة به. بل وأكثر من ذلك في قواعد البيانات الموزعة، حيث قد توجد ثلاثة سجلات منفصلة للكتابة المسبقة:
إذا كنت لا تزال بحاجة إلى المتانة، فسيقوم Flush بالكتابة على الالتزامات بعلامة اختيارية. في برنامج التشغيل C، يمكنك الاتصال بـ ustore_transaction_commit() باستخدام العلامة ::ustore_option_write_flush_k .
يتناسب نظام إدارة قواعد البيانات بالكامل مع صورة Docker أقل من 100 ميجابايت. قم بتشغيل البرنامج النصي التالي لسحب الحاوية وتشغيلها، وإظهار خادم Apache Arrow Flight على المنفذ 38709 . ستتواصل حزم SDK الخاصة بالعملاء أيضًا من خلال نفس المنفذ افتراضيًا.
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustoreيمكن استرداد ملف التكوين الافتراضي باستخدام:
cat /var/lib/ustore/config.jsonإن أبسط طريقة للاتصال والاختبار هي الأمر التالي:
python ...تتوفر صور UStore المعبأة مسبقًا على منصات متعددة:
لا تتردد في تسويق وإعادة توزيع UStore.
يعد ضبط قواعد البيانات فنًا بقدر ما هو علم. توفر مشاريع مثل RocksDB العشرات من المقابض لتحسين السلوك. نحن نسمح بإعادة توجيه ملفات التكوين المتخصصة إلى المحرك الأساسي.
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}لدينا أيضًا إجراء أبسط، والذي سيكون كافيًا لـ 80٪ من المستخدمين. يمكن توسيع ذلك لاستخدام أجهزة أو أدلة متعددة، أو لإعادة توجيه تكوين محرك متخصص.
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}يمكن أيضًا تكوين مجموعات قواعد البيانات باستخدام ملفات JSON.
اعتبارًا من الإصدار الحالي، يتم استخدام الأعداد الصحيحة الموقعة 64 بت. يسمح بمفاتيح فريدة في النطاق من [0, 2^63) . تتوفر إصدارات 128 بت باستخدام UUIDs، ولكن لا يُنصح بشدة باستخدام المفاتيح ذات الطول المتغير. لماذا ذلك؟
يؤدي استخدام المفاتيح ذات الطول المتغير إلى فرض قيود عديدة على تصميم متجر Key-Value. أولاً، يتضمن ذلك مقارنات بطيئة بين الشخصيات، مما يؤدي إلى قاتل الأداء على وحدات المعالجة المركزية الحديثة ذات السلمية الفائقة. ثانيًا، يفرض ربط المفاتيح والقيم على القرص لتقليل البيانات التعريفية المطلوبة للتنقل. وأخيرًا، فهو ينتهك رؤيتنا المنطقية البسيطة لـ KVS باعتبارها "مخصصًا مستمرًا للذاكرة"، مما يضع عليها قدرًا أكبر من المسؤولية.
النهج الموصى به للتعامل مع مفاتيح السلسلة هو:
سيؤدي هذا إلى نقطة تحويل واحدة من تمثيلات السلسلة إلى الأعداد الصحيحة وسيبقي معظم النظام سريعًا وواجهات المستوى C أبسط مما كان يمكن أن تكون عليه.
يمكننا فقط معالجة قيم 4 جيجا بايت أو أصغر اعتبارًا من الوقت الحالي. لماذا؟ إن مخازن القيمة الأساسية مخصصة عمومًا للعمليات عالية التردد. في كثير من الأحيان (آلاف المرات في الثانية)، يكون الوصول إلى ملفات بحجم 4 جيجابايت أو أكبر وتعديلها مستحيلًا على الأجهزة الحديثة. لذلك نحن نلتزم بالأنواع ذات الطول الأصغر، مما يجعل استخدام تمثيل Apache Arrow أسهل قليلاً ويسمح لـ KVS بضغط الفهارس بشكل أفضل.
خريطة طريق التطوير الخاصة بنا عامة ويتم استضافتها داخل مستودع GitHub. تشمل المهام القادمة ما يلي:
اقرأ خريطة الطريق الكاملة في مستنداتنا هنا.


