aiwhispr
version 0.941
AIWhispr عبارة عن أداة بدون تعليمات برمجية منخفضة/منخفضة لأتمتة خطوط أنابيب تضمين المتجهات للبحث الدلالي. يقوم التكوين البسيط بتشغيل المسار لقراءة الملفات واستخراج النص وإنشاء تضمينات متجهة وتخزينها في قاعدة بيانات متجهة.
AIWhispr

يحتوي AIWhispr على موصلات لقواعد البيانات المتجهة التالية
1قدرانت
2 ميلفوس
3 ويفييت
4 حس الكتابة
5 مونغو دي بي
6 بوستجرس - PGVector
يرجى التأكد من تثبيت قاعدة بيانات المتجهات الخاصة بك وبدء تشغيلها.
يجب أن يكون متغير البيئة AIWHISPR_HOME_DIR هو المسار الكامل لدليل aiwhispr.
يمكن ضبط متغير البيئة AIWHISPR_LOG_LEVEL على DEBUG / INFO / WARNING / ERROR
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
تذكر إضافة متغيرات البيئة في البرنامج النصي لتسجيل الدخول الخاص بـ Shell
قم بتشغيل الأمر أدناه
$AIWHISPR_HOME/shell/install_python_packages.sh
إذا فشل تثبيت uwsgi، فتأكد من تثبيت gcc وpython-dev وpython3-dev.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
يأتي AIWhispr مع تطبيق مبسط لمساعدتك على البدء.
قم بتشغيل تطبيق Streamlit
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
يجب أن يؤدي هذا إلى تشغيل تطبيق مبسط على المنفذ الافتراضي 8501 وبدء جلسة على متصفح الويب الخاص بك
هناك 3 خطوات لتكوين مسار فهرسة المحتوى الخاص بك للبحث الدلالي.
1. قم بالتكوين لقراءة الملفات من موقع التخزين
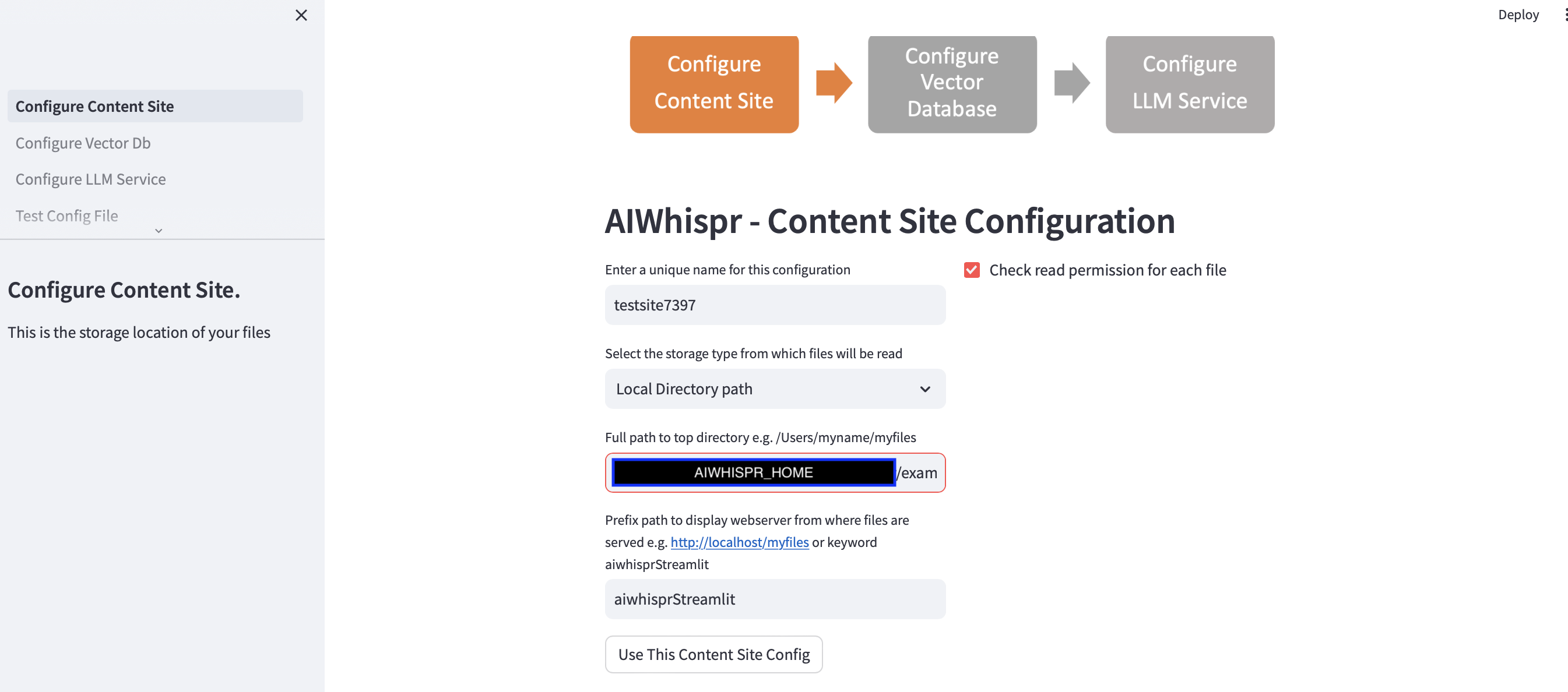
يمكنك متابعة التكوين الافتراضي من خلال النقر على الزر "استخدام تكوين موقع المحتوى هذا"
وانتقل إلى الخطوة التالية لتكوين اتصال قاعدة بيانات المتجهات.
سيقوم المثال الافتراضي بفهرسة القصص الإخبارية من بي بي سي للبحث الدلالي.
يفترض التطبيق المتدفق أنك تبدأ تكوينًا جديدًا وسيقوم بتعيين اسم تكوين عشوائي. يمكنك الكتابة فوق هذا لمنحه اسمًا أكثر وضوحًا. يجب أن يكون اسم التكوين فريدًا؛ ولا يمكن أن يحتوي على مسافة بيضاء أو أحرف خاصة.
سيقوم التكوين الافتراضي بقراءة المحتوى من مسار الدليل المحلي $AIWHISPR_HOME/examples/http/bbc
يحتوي هذا على أكثر من 2000 قصة إخبارية من بي بي سي والتي تم فهرستها للبحث الدلالي.
يمكنك اختيار قراءة المحتوى المخزن على AWS S3 وAzure Blob وGoogle Cloud Storage.
يتم استخدام تكوين مسار البادئة لإنشاء روابط ويب href لنتائج البحث. يمكنك الاستمرار باستخدام الكلمة الأساسية الافتراضية "aiwhisprStreamlit"
انقر فوق الزر "استخدام تكوين موقع المحتوى هذا" وانتقل إلى الخطوة التالية لتكوين اتصال قاعدة بيانات المتجهات بالنقر فوق "تكوين Vector Db" في الشريط الجانبي الأيسر.
2. تكوين ناقل ديسيبل
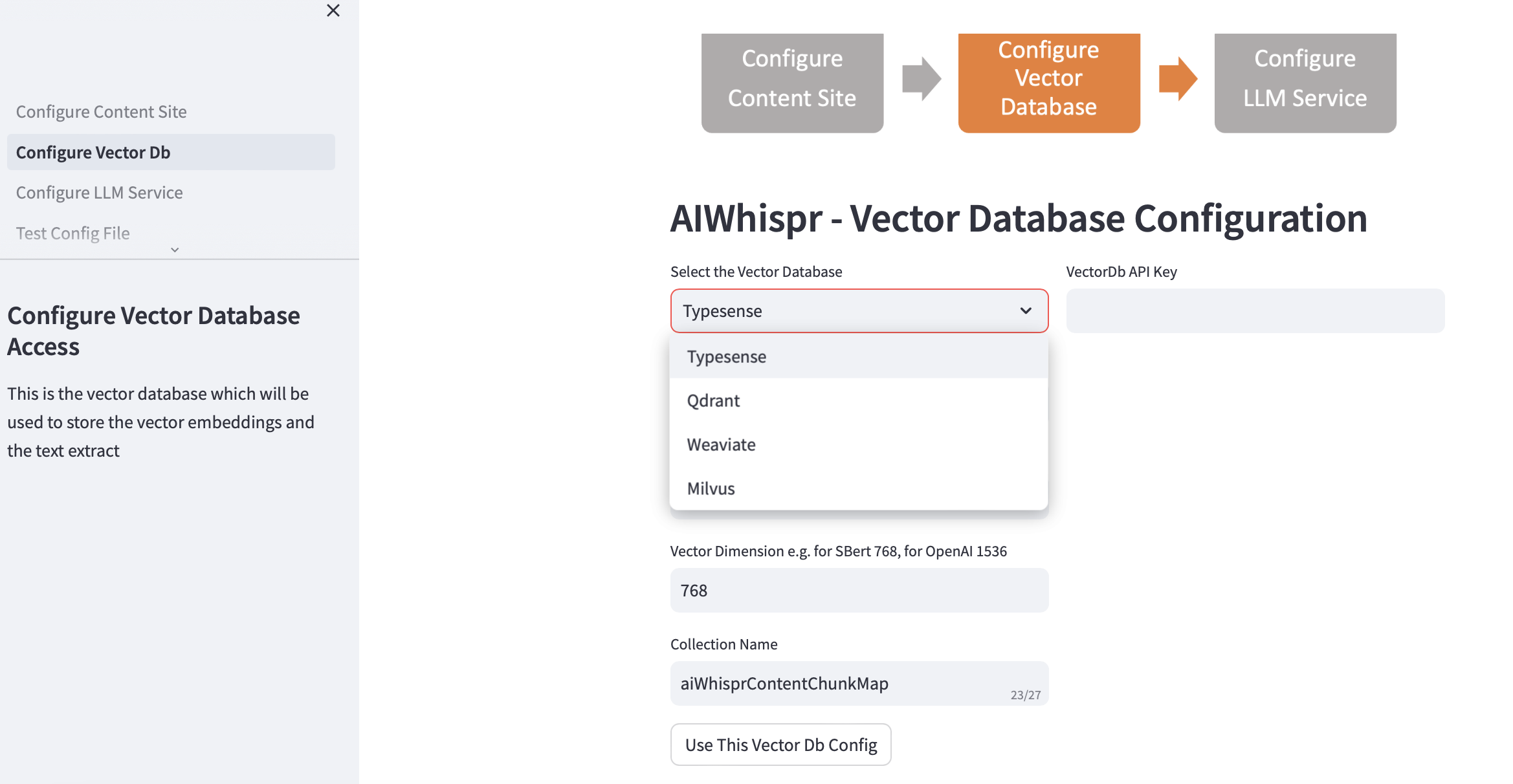
اختر Vectordb الخاص بك وقدم تفاصيل الاتصال.
عند اختيار قاعدة بيانات المتجهات، تتم تعبئة عنوان IP الخاص بـ Vector Db وأرقام المنافذ بناءً على عمليات التثبيت الافتراضية. يمكنك تغيير هذا بناءً على الإعداد الخاص بك.
يجب أن يتم تكوين قاعدة بيانات المتجهات الخاصة بك للمصادقة. في حالة Qdrant، Weaviate، Typesense، يلزم وجود مفتاح API. بالنسبة إلى Milvus، يجب تكوين معرف المستخدم وكلمة المرور.
يجب تحديد حجم البعد المتجه استنادًا إلى LLM الذي تخطط لاستخدامه لتشفير النص كتضمينات متجهة. مثال: بالنسبة لـ Open AI "text-embedding-ada-002" يجب تكوين هذا على أنه 1536، وهو حجم المتجه الذي يتم إرجاعه بواسطة خدمة تضمين OpenAI.
اسم المجموعة الافتراضي الذي تم إنشاؤه في قاعدة بيانات المتجهات هو aiwhisprContentChunkMap. يمكنك تحديد اسم مجموعتك الخاصة.
انقر فوق الزر "استخدام Vector Db Config" ثم انتقل إلى الخطوة التالية بالنقر فوق "تكوين خدمة LLM" في الشريط الجانبي الأيسر.
3. تكوين خدمة LLM
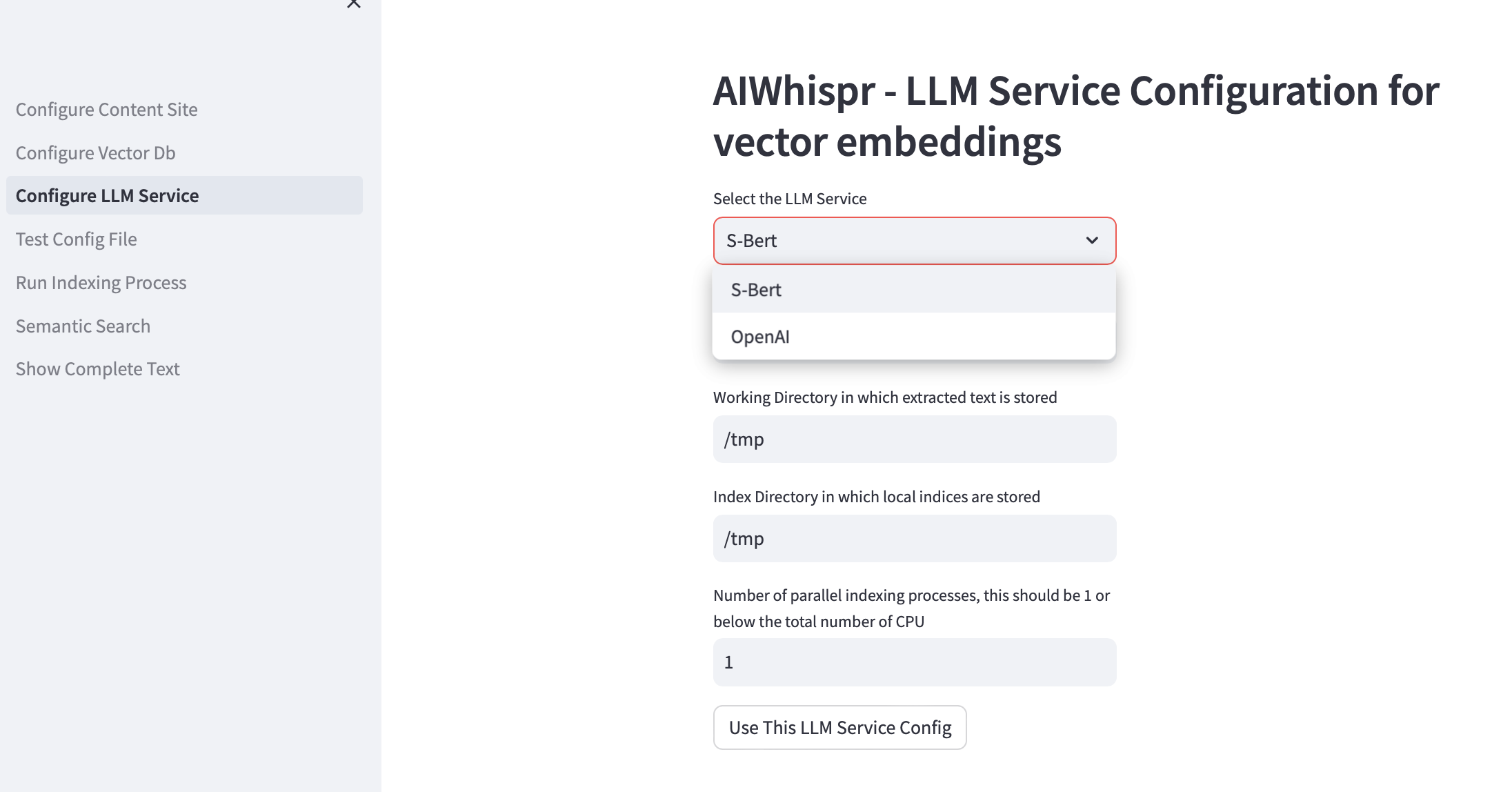
يمكنك اختيار إنشاء عمليات تضمين متجهة باستخدام نماذج Sbert المدربة مسبقًا والتي يتم تشغيلها محليًا أو استخدام OpenAI API.
بالنسبة لعائلة نماذج SBert، النموذج الافتراضي المستخدم هو all-mpnet-base-v2. يمكنك تحديد نموذج SBert آخر.
بالنسبة لـ OpenAI، نموذج التضمين الافتراضي هو text-embedding-ada-002
دليل العمل الافتراضي هو /tmp
دليل العمل هو الموقع الموجود على الجهاز المحلي والذي سيتم استخدامه كدليل عمل لمعالجة الملفات التي تتم قراءتها/تنزيلها من موقع التخزين الخاص بك. يتم بعد ذلك تقسيم النص المستخرج من مستنداتك إلى حجم أصغر، عادةً 700 كلمة، ثم يتم ترميزه بعد ذلك على شكل تضمينات متجهة. يتم استخدام دير العمل لتخزين أجزاء النص.
دليل الفهرسة المحلي الافتراضي هو /tmp
يمكنك تحديد مسار دليل محلي ثابت للعمل ودليل الفهرس.
يتم استخدام مؤشر الفهرس لتخزين قائمة فهرسة ملفات المحتوى التي يجب قراءتها. يدعم AIWhispr عمليات متعددة للفهرسة، وستستخدم كل عملية قائمة الفهرسة الخاصة بها مما يسمح لك بالاستفادة من وحدات المعالجة المركزية المتعددة على جهازك.
إذا كنت ترغب في الاستفادة من وحدات المعالجة المركزية المتعددة للفهرسة (قراءة المحتوى، وإنشاء تضمين المتجهات، وتخزينها في قاعدة بيانات المتجهات) ثم حدد ذلك في مربع الاختبار لعدد العمليات المتوازية. توصيتنا هي أن يكون هذا 1 أو الحد الأقصى (عدد وحدات المعالجة المركزية/ 2). مثال على جهاز 8 وحدة المعالجة المركزية (CPU) يجب ضبطه على 4. يستخدم AIWhispr المعالجة المتعددة لتجاوز قيود Python GIL.
انقر فوق "استخدام تكوين خدمة LLM هذا" لإنشاء الإصدار النهائي من ملف تكوين خط أنابيب تضمين المتجهات الخاص بك.
سيتم عرض محتويات ملف التكوين وموقعه على جهازك.
يمكنك اختبار هذا التكوين من خلال النقر على "اختبار ملف التكوين" في الشريط الجانبي الأيسر.
4. اختبار التكوين
يجب أن تشاهد الآن رسالة توضح موقع ملف تكوين خط أنابيب التضمين المتجه الخاص بك وزرًا "اختبار ملف التكوين"
سيؤدي النقر فوق الزر إلى بدء العملية التي ستختبر تكوين خط الأنابيب
من المفترض أن تشاهد رسالة "لا توجد أخطاء" في نهاية السجلات والتي تعلمك بإمكانية استخدام تكوين خط الأنابيب هذا.
انقر على "تشغيل عملية الفهرسة" في الشريط الجانبي الأيسر لبدء المسار.
5. تشغيل عملية الفهرسة
يجب أن تشاهد زر "بدء الفهرسة".
انقر على هذا الزر لبدء خط الأنابيب. يتم تحديث السجلات كل 15 ثانية.
يقوم المثال الافتراضي بفهرسة أكثر من 2000 قصة إخبارية لهيئة الإذاعة البريطانية (BBC) والتي تستغرق حوالي 20 دقيقة.
لا تنتقل بعيدًا عن هذه الصفحة أثناء تشغيل عملية الفهرسة، أي أثناء عرض حالة Streamlit "قيد التشغيل" في أعلى اليمين.
يمكنك أيضًا التحقق مما إذا كانت عملية الفهرسة قيد التشغيل باستخدام grep على جهازك.
ps -ef | grep python3 | grep index_content_site.py
6. البحث الدلالي
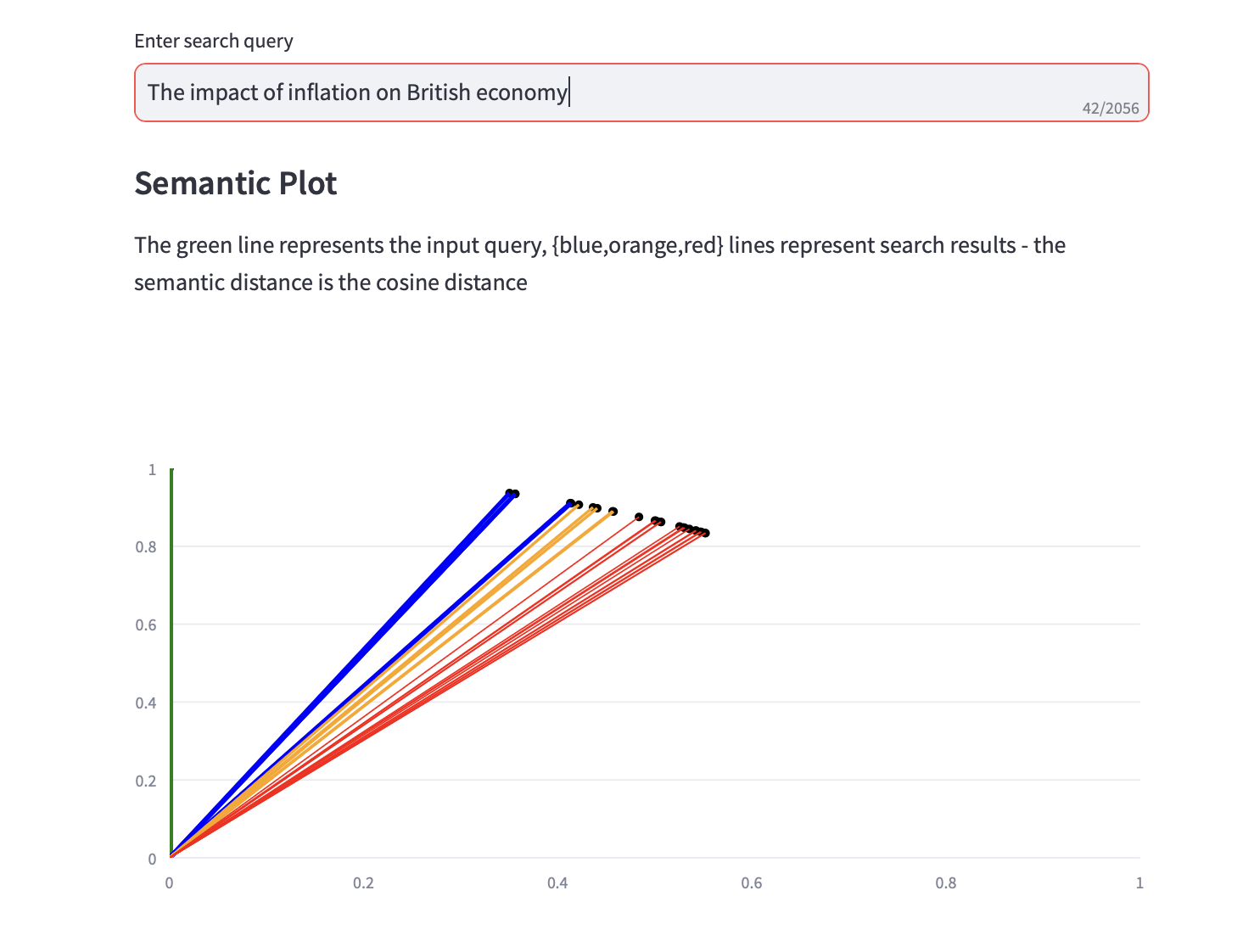
يمكنك الآن تشغيل استعلامات البحث الدلالي.
يتم أيضًا عرض مؤامرة دلالية تعرض مسافة جيب التمام، وأفضل 3 تحليلات PCA لنتائج البحث جنبًا إلى جنب مع نتائج البحث النصية.