sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
المشرف: jcudit و lsgos
يستمر المشروع حتى (YYYY-MM-DD) على الأقل: 2023-03-14
هذا مثال على كيفية استخدام Cohere API لإنشاء محرك بحث دلالي بسيط. ليس المقصود منه أن يكون جاهزًا للإنتاج أو التوسع بكفاءة (على الرغم من إمكانية تكييفه لتحقيق هذه الغايات)، ولكنه يعمل بدلاً من ذلك على إظهار سهولة إنتاج محرك بحث مدعوم بالتمثيلات التي تنتجها نماذج اللغات الكبيرة (LLMs) الخاصة بـ Cohere.
خوارزمية البحث المستخدمة هنا بسيطة إلى حد ما: فهي ببساطة تعثر على الفقرة الأكثر تطابقًا مع تمثيل السؤال، وذلك باستخدام نقطة النهاية co.embed . سيتم شرح ذلك بمزيد من التفصيل أدناه، ولكن هنا رسم تخطيطي بسيط لما يحدث. نقوم أولاً بتقسيم نص الإدخال إلى سلسلة من الفقرات، وتخزين عناوينها في الإدخال في قائمة وإنشاء تضمين متجه لكل فقرة باستخدام co.embed :
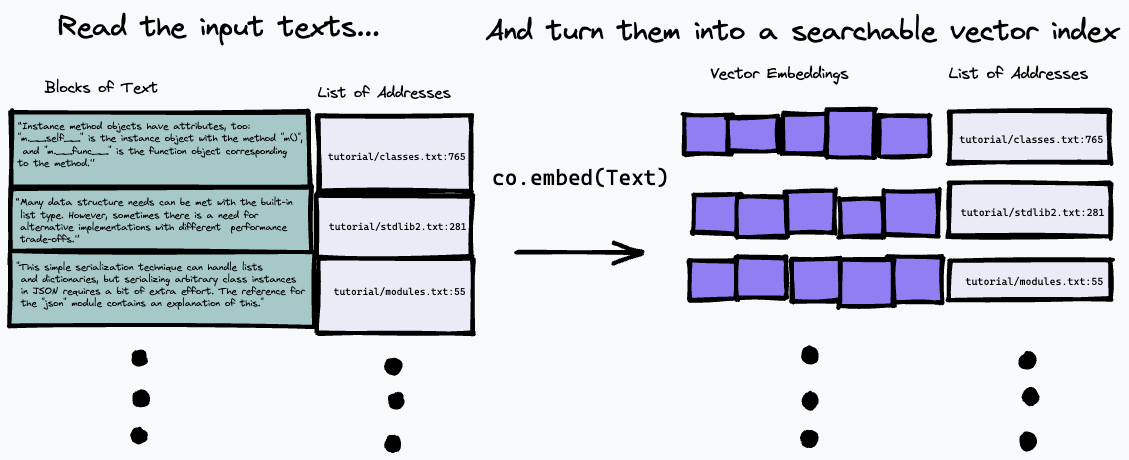
بعد ذلك، يمكننا الاستعلام عن فهرسنا عن طريق تضمين الاستعلام النصي، والعثور على الفقرات في النص المصدر التي لها أقرب تطابق باستخدام بعض مقاييس تشابه المتجهات (استخدمنا تشابه جيب التمام): 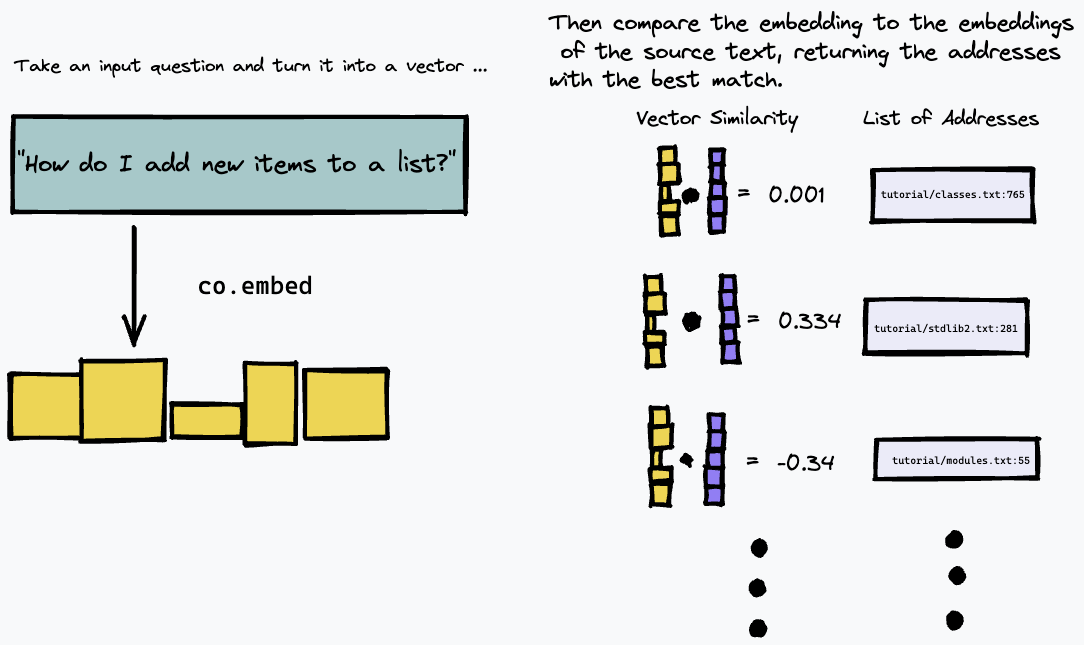
ونتيجة لذلك، فإنه يعمل بشكل أفضل مع المصادر النصية حيث من المحتمل أن يتم تقديم الإجابة على سؤال معين من خلال فقرة محددة في النص، مثل الوثائق الفنية أو مواقع الويكي الداخلية التي يتم تنظيمها كقائمة من التعليمات أو الحقائق الملموسة. فهو لا يعمل بشكل جيد تقريبًا، على سبيل المثال، في الإجابة على الأسئلة المتعلقة بالنص الحر مثل الروايات حيث قد تتوزع المعلومات على عدة فقرات؛ ستحتاج إلى استخدام طريقة مختلفة لفهرسة النص لهذا الغرض.
على سبيل المثال، يقوم هذا المستودع ببناء محرك بحث دلالي بسيط على النسخة النصية لأحدث وثائق بايثون.
لتثبيت متطلبات بايثون، تأكد من تثبيت الشعر وتشغيله:
# install python deps
poetry installيجب أن يكون لديك أيضًا عامل إرساء مثبتًا. في نظام التشغيل OS X، إذا كنت تستخدم برنامج homebrew، فنوصي بتشغيله
brew install --cask dockerقبل تشغيل docker (على سبيل المثال، لتشغيل خادمنا) لأول مرة على OS X، افتح تطبيق Docker وامنحه الامتيازات التي يحتاجها للتشغيل على نظامك.
ستحتاج أيضًا إلى الحصول على مفتاح Cohere API في COHERE_TOKEN . احصل على واحدة من منصة Cohere (أنشئ حسابًا إذا لزم الأمر)، واكتبها في بيئتك
export COHERE_TOKEN= < MY_API_KEY > (حيث <MY_API_KEY> هو المفتاح الذي حصلت عليه، بدون الأقواس <...> ).
وبدلاً من ذلك، يمكنك تمرير COHERE_TOKEN=<MY_API_KEY> كوسيطة إضافية لأي أمر make أدناه.
اتبع هذه الخطوات لإنشاء فهرس دلالي لمجموعة مستنداتك أولاً. تنتج هذه الخطوات فهرسًا دلاليًا لمستندات بايثون الرسمية، ولكن يمكن تكييفها لمجموعات البيانات العشوائية.
أولاً، قم بتنزيل مستند python عن طريق تشغيل أحد الأوامر التالية.
إذا كنت تريد أن تبدأ بسرعة، اركض
make download-python-docs-smallلتقييد مجموعة المستندات بالبرنامج التعليمي لبايثون. نوصي بالقيام بذلك فقط لإجراء اختبار سريع، حيث أن النتائج ستكون محدودة للغاية .
إذا كنت تريد اختبار محرك البحث عبر وثائق بايثون بأكملها، فقم بتشغيل
make download-python-docsلكن عليك أن تدرك أن إنتاج التضمينات سيستغرق ساعات (على الرغم من أن هذا يجب أن يتم مرة واحدة فقط).
وبدلاً من ذلك، إذا كنت تريد تجربة النص الخاص بك، فما عليك سوى تنزيله كملفات .txt إلى دليل يسمى txt/ في هذا المستودع.
بمجرد حصولك على بعض النص، نحتاج إلى معالجته في فهرس بحث للتضمينات والعناوين.
يمكن القيام بذلك باستخدام الأمر
make embeddings بافتراض أن النص المستهدف موجود ضمن الدليل ./txt/ .
سيقوم الأمر بالبحث في الدليل ./txt/ بشكل متكرر عن الملفات ذات الامتداد .txt ، وإنشاء قاعدة بيانات بسيطة للتضمينات واسم الملف ورقم السطر لكل فقرة.
تحذير: إذا كان لديك الكثير من النصوص للبحث فيها، فقد يستغرق ذلك بعض الوقت للانتهاء!
بمجرد إنشاء ملف embeddings.npz ، يمكنك استخدام الأمر التالي لإنشاء صورة عامل إرساء والتي ستخدم تطبيق REST بسيطًا للسماح لك بالاستعلام عن قاعدة البيانات التي أنشأتها:
make buildيمكنك بعد ذلك بدء تشغيل الخادم باستخدام
make runيعد هذا مبالغة بعض الشيء بالنسبة لمثال بسيط، ولكنه مصمم ليعكس حقيقة أن إنشاء فهرس لمجموعة كبيرة من النص يكون بطيئًا نسبيًا، ويضمن أن الاستعلام عن المحرك سريع.
إذا كنت ترغب في استخدام هذا المشروع ككتلة بناء لتطبيق حقيقي، فمن المحتمل أنك سوف ترغب في الحفاظ على قاعدة بياناتك الخاصة بتضمين النص في بنية الخادم والاستعلام عنها باستخدام عميل خفيف الوزن. يعني تجميع الخادم كتطبيق عامل إرساء أنه من السهل جدًا تحويله إلى تطبيق "حقيقي" من خلال نشره على خدمة سحابية.
إذا قمت بفتح نافذة طرفية جديدة لأي من الخيارات أدناه، فتذكر تشغيلها
export COHERE_TOKEN= < MY_API_KEY > الخيار الأسهل إلى حد بعيد هو تشغيل البرنامج النصي المساعد الخاص بنا:
scripts/ask.sh " My query here "للاستعلام عن قاعدة البيانات. يأخذ البرنامج النصي وسيطة ثانية اختيارية تحدد عدد النتائج المطلوبة.
ينبثق البرنامج النصي بواجهة vim معدلة، بالأوامر التالية:
q للخروج.سيُظهر لك الجزء العلوي الموضع في المستند حيث تم العثور على النتيجة.
بمجرد تشغيل الخادم، يمكنك الاستعلام عنه باستخدام واجهة برمجة تطبيقات REST البسيطة. يمكنك استكشاف واجهة برمجة التطبيقات مباشرة بالانتقال إلى /docs#/default/search_search_post هنا. إنها واجهة برمجة تطبيقات JSON REST بسيطة؛ إليك كيف يمكنك طرح استعلام باستخدام curl :
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
سيؤدي هذا إلى إرجاع قائمة JSON بطول num_results ، كل منها يحتوي على اسم الملف ورقم السطر ( doc_url و block_url ) للكتل التي كانت أقرب تطابق دلالي لاستعلامك. ولكن ربما تريد في الواقع قراءة جزء من الملفات الذي يمثل أفضل إجابة.
نظرًا لأننا نبحث في الملفات النصية المحلية، فمن الأسهل في الواقع تحليل المخرجات باستخدام أدوات سطر الأوامر؛ استخدم نص بايثون المتوفر utils/query_server.py للاستعلام عنه في سطر الأوامر. يطبع query_server.py النتائج بالتنسيق القياسي file_name:line_number: حتى نتمكن من تصفح النتائج الفعلية بطريقة لطيفة من خلال الاستفادة من وضع الإصلاح السريع لـ vim .
بافتراض أن لديك vim على جهازك، يمكنك ذلك ببساطة
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
لجعل vim يفتح الملفات النصية المفهرسة في المواقع التي يتم إرجاعها بواسطة خوارزمية البحث. (استخدم :qall لإغلاق النافذة ومتصفح الإصلاح السريع). يمكنك التنقل بين النتائج التي تم إرجاعها باستخدام :cn و :cp . النتائج ليست مثالية. إنه بحث دلالي، لذا تتوقع أن تكون المطابقة غامضة بعض الشيء. على الرغم من ذلك، غالبًا ما أجد أنه يمكنك الحصول على إجابة لسؤالك في النتائج القليلة الأولى، ويتيح لك استخدام واجهة برمجة تطبيقات Cohere التعبير عن سؤالك باللغة الطبيعية، ويتيح لك إنشاء محرك بحث فعال بشكل مدهش في بضعة أسطر فقط من التعليمات البرمجية.
بعض الاستعلامات التي يسهل تجربتها في حالة مستندات python والتي تُظهر أن البحث يعمل بشكل جيد على الأسئلة العامة باللغة الطبيعية هي:
How do I put new items in a list? (لاحظ أن هذا السؤال يتجنب استخدام الكلمة الأساسية "إلحاق"، ولا يتطابق تمامًا مع الطريقة التي تشرح بها المستندات الإلحاق (يقولون إنها تستخدم لإضافة عناصر جديدة إلى نهاية القائمة). لكن البحث الدلالي يكتشف بشكل صحيح أن لا تزال الفقرة ذات الصلة هي الأفضل.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (لاحظ بالنسبة لهذا السؤال، أن النتيجة الأولى بالنسبة لي هي الأسئلة الشائعة حول هذا الموضوع بالتحديد، ولكن مع سؤال بصياغة مختلفة. ومع ذلك، نظرًا لأنه بحث دلالي، فإن الخوارزمية الخاصة بنا تختار بشكل صحيح النتيجة التي تطابق المعنى، وليس فقط صياغة استفسارنا)How do I remove an item from a set?How do list comprehensions work? يستخدم هذا الريبو استراتيجية بسيطة جدًا لفهرسة المستند والبحث عن أفضل تطابق. أولاً، يقوم بتقسيم كل مستند إلى فقرات أو "كتل". بعد ذلك، فإنه يستدعي co.embed في كل فقرة، من أجل إنشاء تضمين متجه باستخدام نموذج اللغة الخاص بـ Cohere. ثم يقوم بعد ذلك بتخزين كل متجه تضمين، جنبًا إلى جنب مع المستند المقابل ورقم السطر للفقرة، في مصفوفة بسيطة باعتبارها "قاعدة بيانات".
من أجل إجراء البحث فعليًا، نستخدم مكتبة بحث التشابه FAISS. عندما نحصل على استعلام، نستخدم نفس استدعاء Cohere API لتضمين الاستعلام. ثم نستخدم FAISS للعثور على القمة
إذا كان لديك أي أسئلة أو تعليقات، يرجى تقديم مشكلة أو التواصل معنا على Discord.
إذا كنت ترغب في المساهمة في هذا المشروع، يرجى قراءة CONTRIBUTORS.md في هذا المستودع، والتوقيع على اتفاقية ترخيص المساهم قبل تقديم أي طلبات سحب. سيتم إنشاء رابط للتوقيع على Cohere CLA في المرة الأولى التي تقوم فيها بتقديم طلب سحب إلى مستودع Cohere.
لدى Toy Semantic Search ترخيص MIT، كما هو موجود في ملف الترخيص.


