wagtail_textract
1.0.0
هذه الحزمة لم تتم صيانتها، وليس لدينا أي خطط لصيانتها.
ننصحك باستخدامه كمثال، وربما نسخ الكود إلى مشروعك الخاص، ولكن لا تقم بتثبيت الحزمة.
هذه الحزمة مخصصة لاستبدال فئة مستند Wagtail بفئة تسمح بالبحث في محتويات ملف المستند باستخدام النص.
يمكن للنص استخراج النص من ملفات PDF وExcel وWord (من بين ملفات أخرى).
الحزمة مستوحاة من مشكلة "البحث: استخراج النص من المستندات" في Wagtail.
ستعمل المستندات كما كانت من قبل، باستثناء أن البحث عن المستندات في واجهة إدارة Wagtail سيجد أيضًا مصطلحات بحث في محتويات الملفات.
بعض لقطات الشاشة للتوضيح.
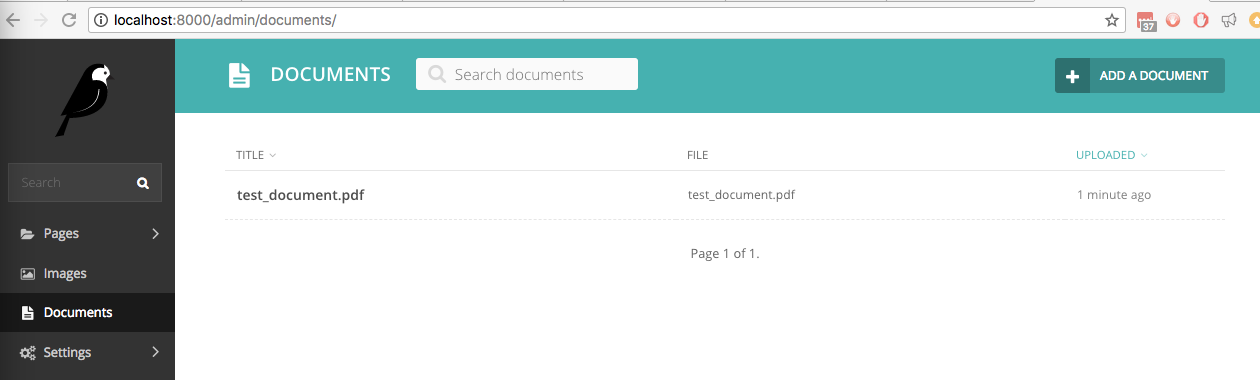
في موقعنا الجديد Wagtail المثبت عليه wagtail_textract ، قمنا بتحميل ملف يسمى test_document.pdf يتضمن نصًا مكتوبًا بخط اليد. تم إدراجه في واجهة الإدارة ضمن المستندات:
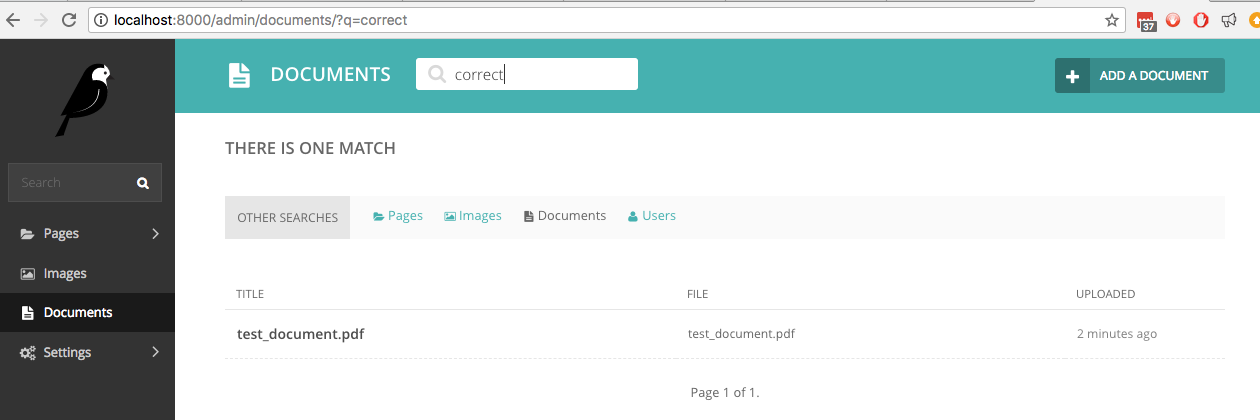
فإذا بحثنا الآن في المستندات عن كلمة correct وهي إحدى الكلمات المكتوبة بخط اليد فإن البحث المباشر يجدها:
والافتراض هو أن هذا البحث لا ينبغي أن يكون متاحًا فقط في واجهة إدارة Wagtail، ولكن أيضًا في عرض البحث العام، والذي نقدم له مثالًا برمجيًا.
نحن نستخدم هذه الحزمة في الإنتاج منذ أغسطس 2018 على https://nuffic.nl.
wagtail_textract إلى متطلباتك و/أو pip install wagtail_textractINSTALLED_APPS .WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" في إعدادات Django.ملاحظة: ستتلقى تحذيرًا بعدم التوافق أثناء تثبيت wagtail_texttract (تم تثبيت Wagtail 2.0.1):
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
لم نر هذا يؤدي إلى مشاكل، ولكن هذا شيء يجب أن نأخذه في الاعتبار.
من أجل جعل textract يستخدم Tesseract، والذي يحدث إذا لم يجد textract العادي أي نص، فأنت بحاجة إلى إضافة ملفات البيانات التي يمكن لـ Tesseract أن يبني عليها مطابقة الكلمات.
قم بإنشاء دليل tessdata في دليل المشروع الخاص بك، وقم بتنزيل اللغات التي تريدها.
يتم النسخ تلقائيًا بعد حفظ المستند، في منفذ تنفيذي asyncio لمنع حظر الاستجابة أثناء المعالجة.
لنسخ جميع المستندات الموجودة، قم بتشغيل أمر الإدارة::
./manage.py transcribe_documents
من الواضح أن هذا قد يستغرق وقتًا طويلاً.
فيما يلي مثال للتعليمات البرمجية لعرض البحث (خارج واجهة إدارة Wagtail) الذي يعرض نتائج الصفحة والمستند.
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) يجب أن يسمح القالب الخاص بك بالتعامل مع المستندات بشكل مختلف عن الصفحات، لأنه لا يمكنك إجراء pageurl result على المستند:
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} من أجل استخدام wagtail_texttract، يجب أن يقوم نموذج CustomizedDocument الخاص بك بنفس عمل مستند wagtail_texttract:
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] لاحظ أن الفئة الأولى للفئة الفرعية يجب أن تكون TranscriptionMixin ، لذا فإن save() الخاص بها له الأسبقية على الفئات الأصلية الأخرى.
لإجراء الاختبارات، قم بمراجعة هذا المستودع و:
make test
سيتم إنشاء تقرير التغطية في ./coverage_html_report/ .


