SeekStorm
v0.11.0

SeekStorm عبارة عن مكتبة بحث عن النص الكامل مفتوحة المصدر، وخادم متعدد الإيجارات يتم تنفيذه في Rust .
بدأ التطوير في عام 2015، وفي الإنتاج منذ عام 2020، وميناء روست في عام 2023، ومفتوح المصدر في عام 2024، والعمل جارٍ.
SeekStorm هو برنامج مفتوح المصدر مرخص بموجب ترخيص Apache 2.0
منشورات المدونة: أصبح SeekStorm الآن مفتوح المصدر ويحصل SeekStorm على بحث متعدد الأوجه والبحث القرب الجغرافي وفرز النتائج
أنواع الاستعلام
أنواع النتائج
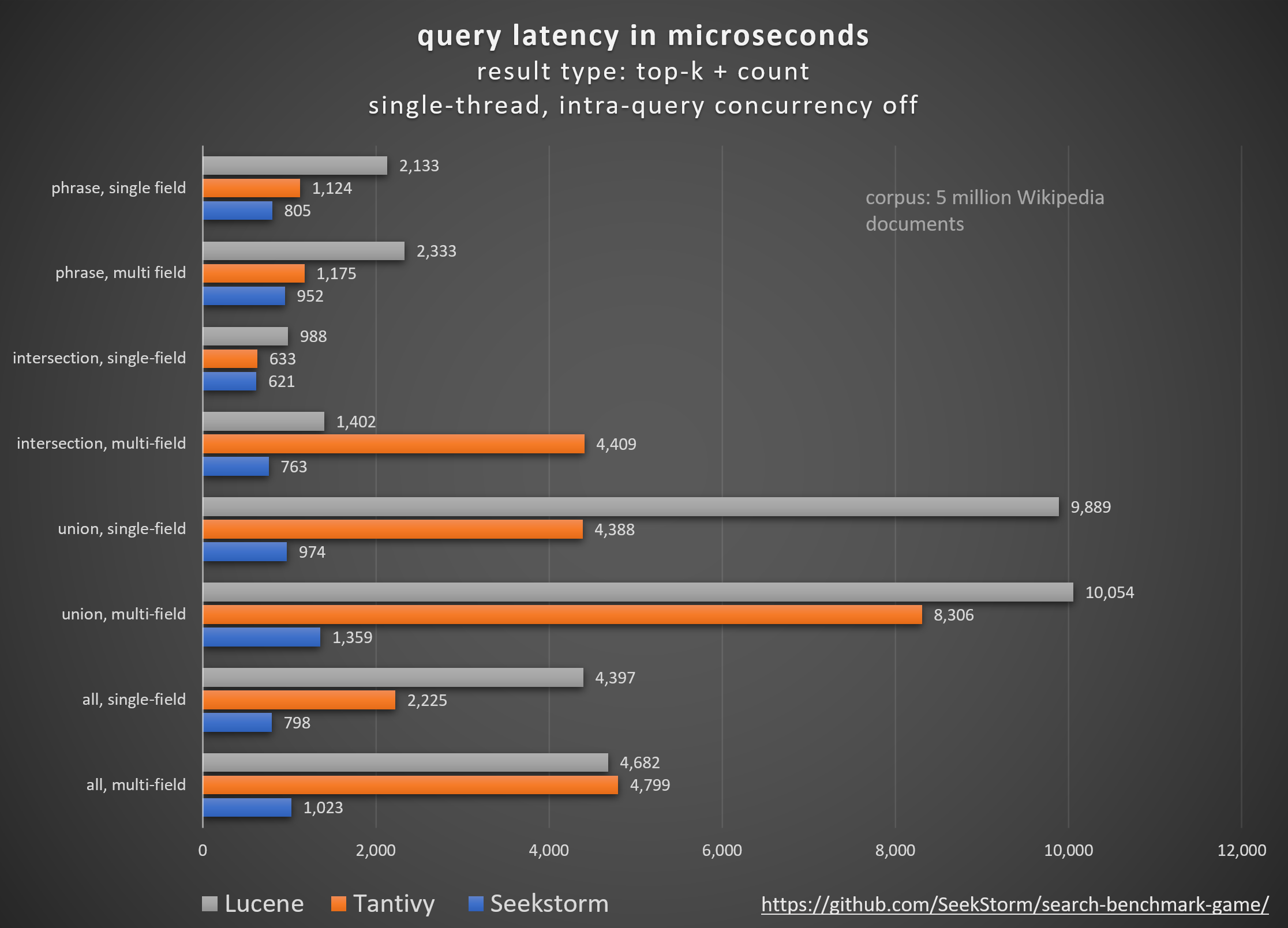
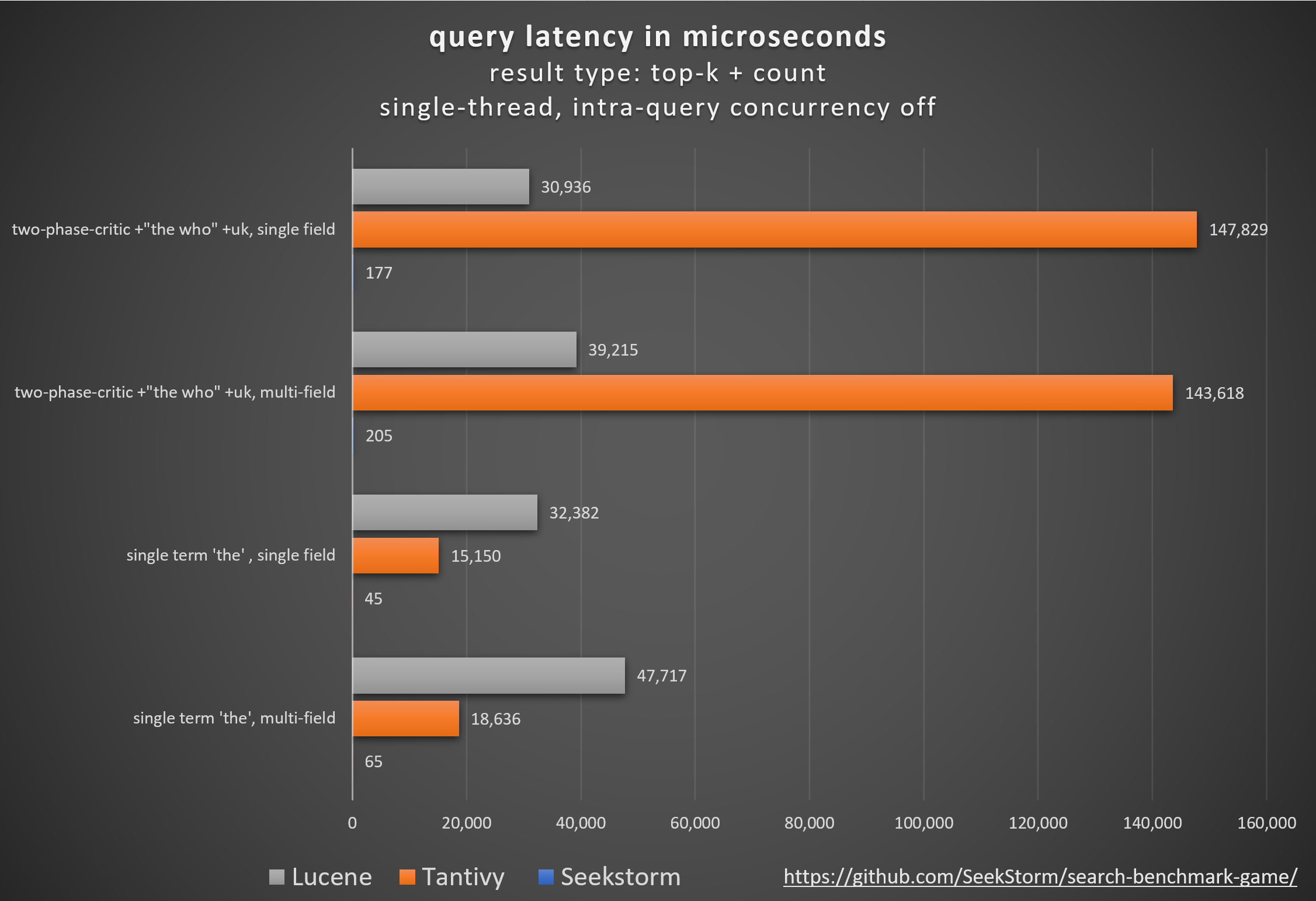
أداء
زمن وصول أقل، إنتاجية أعلى، تكلفة أقل واستهلاك للطاقة، خاصة. للاستعلامات متعددة المجالات والمتزامنة.
يضمن زمن الوصول المنخفض تجربة مستخدم سلسة ويمنع فقدان العملاء والإيرادات.
بينما يعتمد البعض على مسرعات الأجهزة الخاصة (FPGA/ASIC) أو المجموعات لتحسين الأداء،
تحقق SeekStorm دفعة مماثلة خوارزميًا على خادم سلعة واحد.
تناسق
لا يوجد زمن استجابة لا يمكن التنبؤ به للاستعلام أثناء وبعد الفهرسة ذات الحجم الكبير حيث أن SeekStorm لا يتطلب عمليات دمج شرائح كثيفة الاستخدام للموارد.
فترات استجابة مستقرة - لا توجد تكاليف بداية باردة بسبب التجميع في الوقت المناسب، ولا توجد تأخيرات غير متوقعة في جمع البيانات المهملة.
التحجيم
يحافظ على زمن وصول منخفض وإنتاجية عالية واستهلاك منخفض لذاكرة الوصول العشوائي حتى بالنسبة للمؤشرات ذات المليارات.
عدد غير محدود من الحقول وطول الحقل وحجم الفهرس.
الصلة
يوفر تصنيف القرب للمصطلح نتائج أكثر صلة مقارنة بـ BM25.
في الوقت الحالى
البحث الحقيقي في الوقت الفعلي، على عكس NRT: كل مستند مفهرس يمكن البحث فيه على الفور، حتى قبل وأثناء الالتزام.
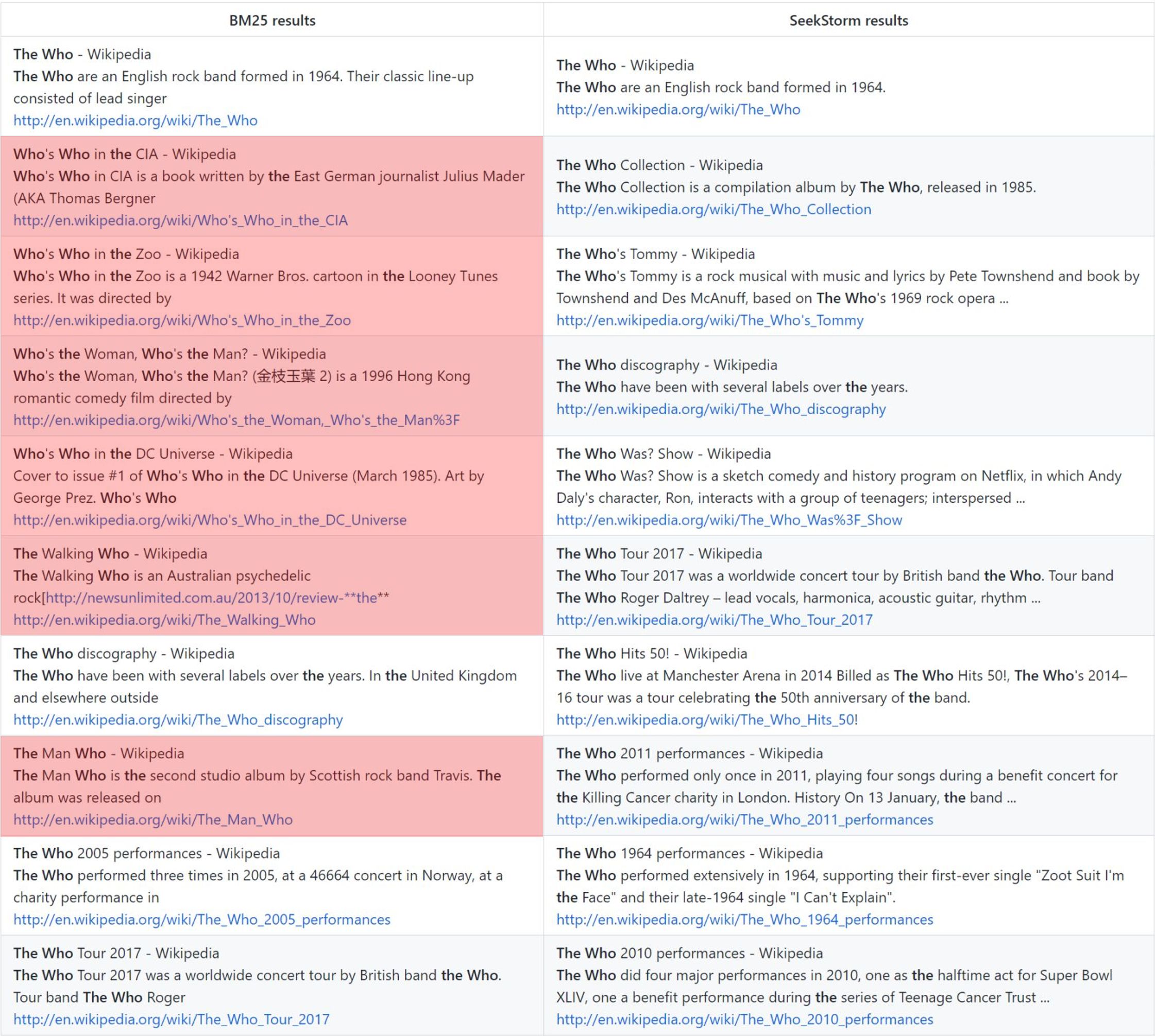
منظمة الصحة العالمية: تصنيف الفانيليا BM25 مقابل تصنيف القرب SeekStorm
المنهجية
مقارنة مكتبات محركات البحث مفتوحة المصدر المختلفة (البحث المعجمي BM25) باستخدام لعبة search_benchmark_game مفتوحة المصدر التي طورها Tantivy وJason Wolfe.
فوائد
نتائج قياس الأداء التفصيلية https://seekstorm.github.io/search-benchmark-game/
مستودع الكود المعياري https://github.com/SeekStorm/search-benchmark-game/
راجع منشورات مدونتنا للحصول على معلومات أكثر تفصيلاً: أصبح SeekStorm الآن مفتوح المصدر ويحصل SeekStorm على بحث متعدد الأوجه والبحث القرب الجغرافي وفرز النتائج
على الرغم مما تريد دورات الضجيج https://www.bitecode.dev/p/hype-cycles أن تصدقه، فإن البحث عن الكلمات الرئيسية لم يمت، لأن NoSQL لم تكن موت SQL.
يجب عليك الاحتفاظ بصندوق الأدوات، واختيار الأداة الأفضل لمهمتك التي بين يديك. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
يعد البحث بالكلمات الرئيسية مجرد مرشح لمجموعة من المستندات، حيث يقوم بإرجاع تلك التي تظهر فيها كلمات رئيسية معينة، وعادةً ما يتم دمجها مع مقياس تصنيف مثل BM25. وظيفة أساسية وجوهرية للغاية، ويصعب تنفيذها على نطاق واسع مع زمن استجابة منخفض. ونظرًا لأن الوظيفة أساسية للغاية، فهناك عدد غير محدود من حقول التطبيق. وهو مكون، ليتم استخدامه مع المكونات الأخرى. هناك حالات استخدام يمكن حلها بشكل أفضل اليوم من خلال البحث عن المتجهات وLLMs، ولكن بالنسبة للعديد من الكلمات الرئيسية، لا يزال البحث عن الكلمات الرئيسية هو الحل الأفضل. البحث عن الكلمات الرئيسية دقيق، وبدون خسارة، وسريع جدًا، مع توسع أفضل، وزمن وصول أفضل، وتكلفة أقل واستهلاك للطاقة. يعمل البحث المتجه مع التشابه الدلالي، ويعرض النتائج ضمن مسافة واحتمال معينين.
إذا كنت تبحث عن نتائج دقيقة مثل الأسماء الصحيحة، والأرقام، ولوحات الترخيص، وأسماء النطاقات، والعبارات (مثل اكتشاف الانتحال)، فإن البحث عن الكلمات الرئيسية هو صديقك. من ناحية أخرى، سيؤدي البحث المتجه إلى دفن النتيجة الدقيقة التي تبحث عنها من بين عدد لا يحصى من النتائج التي ترتبط بطريقة أو بأخرى لغويًا. في الوقت نفسه، إذا كنت لا تعرف المصطلحات الدقيقة، أو كنت مهتمًا بموضوع أوسع أو معنى أو مرادف، بغض النظر عن المصطلحات الدقيقة المستخدمة، فسوف يفشلك البحث عن الكلمات الرئيسية.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.يعد البحث المتجه مثاليًا إذا كنت لا تعرف مصطلحات الاستعلام الدقيقة، أو كنت مهتمًا بموضوع أوسع أو معنى أو مرادف، بغض النظر عن مصطلحات الاستعلام الدقيقة المستخدمة. ولكن إذا كنت تبحث عن مصطلحات دقيقة، مثل الأسماء الصحيحة والأرقام ولوحات الترخيص وأسماء النطاقات والعبارات (مثل اكتشاف الانتحال)، فيجب عليك دائمًا استخدام البحث بالكلمات الرئيسية. لن يؤدي البحث عن المتجهات إلا إلى دفن النتيجة الدقيقة التي تبحث عنها من بين عدد لا يحصى من النتائج المرتبطة بطريقة أو بأخرى. إنه يتمتع باستدعاء جيد، ولكن دقة منخفضة وزمن وصول أعلى. إنه عرضة للإيجابيات الكاذبة، على سبيل المثال، في اكتشاف الانتحال حيث يتم فقدان الكلمات الدقيقة وترتيب الكلمات.
يمكّنك بحث المتجهات من البحث ليس فقط عن نص مشابه، ولكن عن كل ما يمكن تحويله إلى متجه: النص والصور (التعرف على الوجوه وبصمات الأصابع) والصوت، ويمكّنك من القيام بأشياء سحرية مثل الملكة - المرأة + الرجل = الملك .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationلا يعد البحث المتجه بديلاً للبحث عن الكلمات الرئيسية، ولكنه إضافة تكميلية - من الأفضل استخدامه ضمن حل مختلط حيث يتم الجمع بين نقاط القوة في كلا النهجين. البحث عن الكلمات الرئيسية ليس قديمًا، ولكنه أثبت بمرور الوقت .
لقد قمنا (جزئيًا) بنقل قاعدة بيانات SeekStorm من C# إلى Rust
يعد الصدأ أمرًا رائعًا للتطبيقات ذات الأداء الحيوي التي تتعامل مع البيانات الضخمة و/أو العديد من المستخدمين المتزامنين. هل ستتألق الخوارزميات السريعة أكثر باستخدام لغة برمجة تهتم بالأداء؟
راجع ARCHITECTURE.md
cargo build --release
تحذير : تأكد من تعيين متغير البيئة MASTER_KEY_SECRET على سر، وإلا فسيتم اختراق مفاتيح API التي تم إنشاؤها.
https://docs.rs/seekstorm
بناء الوثائق
cargo doc --no-deps
الوصول إلى الوثائق محليا
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
أضف الصناديق المطلوبة لمشروعك
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;استخدم وقت تشغيل Rust غير المتزامن
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {إنشاء فهرس
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;فتح الفهرس (بدلاً من إنشاء فهرس)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; وثائق الفهرس
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; ارتكاب المستندات
index_arc . commit ( ) . await ;فهرس البحث
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;عرض النتائج
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}بحث متعدد الخيوط
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}ملف فهرس JSON بتنسيق JSON وJSON المحدد بسطر جديد وتنسيق JSON المتسلسل
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;فهرسة جميع ملفات PDF في الدليل والأدلة الفرعية
ingest وحدة التحكم): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;ملف فهرس PDF
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;فهرس بايت ملف PDF
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;الحصول على بايت ملف PDF
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;مؤشر واضح
index . clear_index ( ) ;حذف الفهرس
index . delete_index ( ) ;مؤشر الإغلاق
index . close_index ( ) ;سلسلة إصدار مكتبة Seestorm
let version= version ( ) ;
println ! ( "version {}" ,version ) ;يتم تعريف الأوجه في 3 أماكن مختلفة:
يتطلب الحد الأدنى من الأمثلة العملية للفهرسة والبحث متعدد الأوجه 60 سطرًا فقط من التعليمات البرمجية. لكن حل هذه المشكلة معًا من خلال التوثيق وحده قد يكون أمرًا شاقًا. ولهذا السبب نقدم مثالاً للبدء السريع هنا:
أضف الصناديق المطلوبة لمشروعك
cargo add seekstorm
cargo add tokio
cargo add serde_jsonإضافة إعلانات الاستخدام
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;استخدم وقت تشغيل Rust غير المتزامن
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {إنشاء فهرس
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;وثائق الفهرس
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; ارتكاب المستندات
index_arc . commit ( ) . await ;فهرس البحث
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;عرض النتائج
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}جوانب العرض
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;نهاية الوظيفة الرئيسية
Ok ( ( ) )
} برنامج تعليمي سريع خطوة بخطوة حول كيفية إنشاء محرك بحث ويكيبيديا من مجموعة ويكيبيديا باستخدام خادم SeekStorm في 5 خطوات سهلة.

تحميل برنامج SeekStorm
قم بتنزيل SeekStorm من مستودع GitHub
قم بفك الضغط في الدليل الذي تختاره، وافتحه في كود Visual Studio.
أو بدلا من ذلك
git clone https://github.com/SeekStorm/SeekStorm.git
بناء سيكستورم
تثبيت Rust (إن لم يكن موجودًا بعد): https://www.rust-lang.org/tools/install
في محطة Visual Studio Code اكتب:
cargo build --release
احصل على مجموعة ويكيبيديا
مجموعة ويكيبيديا الإنجليزية المُجهزة مسبقًا (5,032,105 مستند، 8,28 جيجابايت بعد فك الضغط). على الرغم من أن wiki-articles.json له امتداد JSON.، إلا أنه ليس ملف JSON صالحًا. إنه ملف نصي، حيث يحتوي كل سطر على كائن JSON مع سمات عنوان url والعنوان والنص. يُسمى التنسيق ndjson ("JSON المحدد بسطر جديد").
تحميل مجموعة ويكيبيديا
فك ضغط مجموعة ويكيبيديا.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
انقل ملف wiki-articles.json الذي تم فك ضغطه إلى دليل الإصدار
بدء تشغيل خادم SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
الفهرسة
اكتب "inest" في سطر الأوامر لخادم SeekStorm قيد التشغيل:
ingest
يؤدي هذا إلى إنشاء الفهرس التجريبي وفهرسة ملف ويكيبيديا المحلي.
ابدأ البحث داخل WebUI المضمن
افتح واجهة مستخدم الويب المضمنة في المتصفح: http://127.0.0.1
أدخل استعلامًا في مربع البحث
اختبار نقاط نهاية REST API
افتح src/seekstorm_server/test_api.rest في VSC مع ملحق VSC "Rest Client" لتنفيذ استدعاءات API وفحص الاستجابات
أمثلة على نقاط نهاية واجهة برمجة التطبيقات التفاعلية
قم بتعيين "مفتاح API الفردي" في test_api.rest على مفتاح API المعروض في وحدة تحكم الخادم عندما كتبت "index" أعلاه.
إزالة الفهرس التجريبي
اكتب "حذف" في سطر الأوامر لخادم SeekStorm قيد التشغيل:
delete
خادم الاغلاق
اكتب "إنهاء" في سطر الأوامر لخادم SeekStorm قيد التشغيل.
quit
تخصيص
هل تريد استخدام شيء مماثل لمشروعك الخاص؟ قم بإلقاء نظرة على وثائق الاستيعاب وواجهة مستخدم الويب.
برنامج تعليمي سريع خطوة بخطوة حول كيفية إنشاء محرك بحث PDF من دليل يحتوي على ملفات PDF باستخدام خادم SeekStorm.
اجعل جميع أوراقك العلمية، وكتبك الإلكترونية، وسيرتك الذاتية، وتقاريرك، وعقودك، ووثائقك، وأدلةك، وخطاباتك، وكشوف حساباتك المصرفية، وفواتيرك، ومذكرات التسليم قابلة للبحث فيها - في المنزل أو في مؤسستك.
بناء سيكستورم
تثبيت Rust (إن لم يكن موجودًا بعد): https://www.rust-lang.org/tools/install
في محطة Visual Studio Code اكتب:
cargo build --release
تحميل بي دي افيوم
قم بتنزيل مكتبة Pdfium ونسخها إلى نفس المجلد مثل الملف searchstorm_server.exe: https://github.com/bblanchon/pdfium-binaries
بدء تشغيل خادم SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
الفهرسة
اختر دليلاً يحتوي على ملفات PDF التي تريد فهرستها والبحث فيها، على سبيل المثال، مستنداتك أو دليل التنزيل.
اكتب "inest" في سطر الأوامر لخادم SeekStorm قيد التشغيل:
ingest C:UsersJohnDoeDownloads
يؤدي هذا إلى إنشاء pdf_index وفهرسة جميع ملفات PDF من الدليل المحدد، بما في ذلك الدلائل الفرعية.
ابدأ البحث داخل WebUI المضمن
افتح واجهة مستخدم الويب المضمنة في المتصفح: http://127.0.0.1
أدخل استعلامًا في مربع البحث
إزالة الفهرس التجريبي
اكتب "حذف" في سطر الأوامر لخادم SeekStorm قيد التشغيل:
delete
خادم الاغلاق
اكتب "إنهاء" في سطر الأوامر لخادم SeekStorm قيد التشغيل.
quit
البحث عن النص الكامل، 30 مليون منشور لأخبار القراصنة وصفحات الويب المرتبطة
DeepHN.org
لا يزال العرض التوضيحي لـ DeepHN يعتمد على قاعدة بيانات SeekStorm C#.
نقوم حاليًا بنقل جميع الميزات المفقودة المطلوبة.
انظر خريطة الطريق أدناه.
لم تكتمل ميزات منفذ Rust بعد. الميزات التالية يتم نقلها حاليًا.
ترقية
التحسينات
ميزات جديدة


