elastic_transformers
1.0.0
البحث المرن الدلالي مع محولات الجملة. سوف نستخدم قوة المرونة وسحر BERT لفهرسة مليون مقالة وإجراء بحث معجمي ودلالي عليها.
والغرض من ذلك هو توفير طريقة سهلة الاستخدام لإعداد Elasticsearch الخاص بك مع أحدث الإمكانيات للتضمين السياقي/البحث الدلالي باستخدام محولات البرمجة اللغوية العصبية.
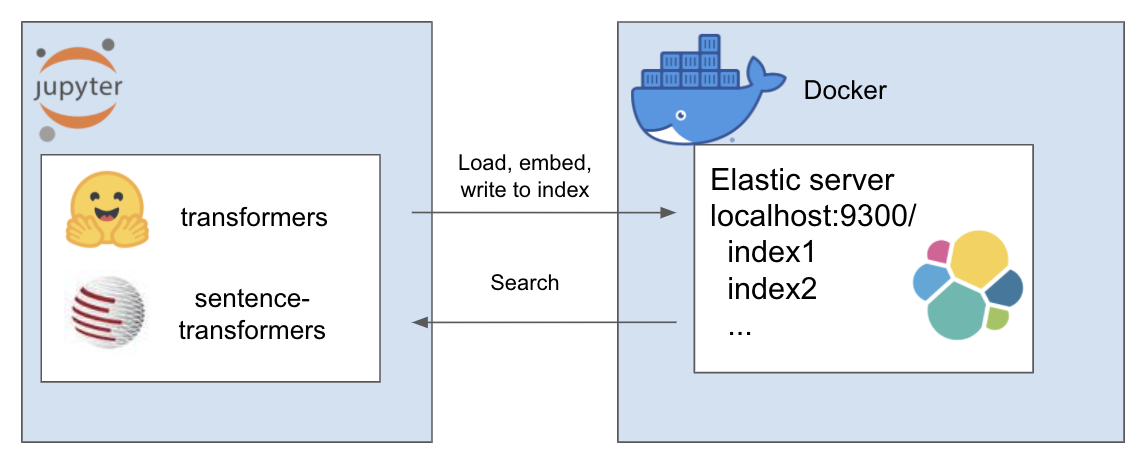
الإعداد أعلاه يعمل على النحو التالي
البيئة الخاصة بي تسمى et وأنا أستخدم conda لهذا الغرض. التنقل داخل دليل المشروع
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtفي هذا البرنامج التعليمي، أستخدم A Million News Headlines بواسطة Rohk وأضعه في مجلد البيانات داخل دليل المشروع.
elastic_transformers/
├── data/
ستجد أن الخطوات مجردة تمامًا بحيث يمكنك أيضًا القيام بذلك باستخدام مجموعة البيانات التي تختارها
اتبع الإرشادات الخاصة بإعداد Elastic مع Docker من صفحة Elastic هنا. بالنسبة لهذا البرنامج التعليمي، ما عليك سوى تنفيذ الخطوتين:
يقدم الريبو فئة ElasiticTransformers. أدوات مساعدة تساعد في إنشاء مؤشرات Elasticsearch وفهرستها والاستعلام عنها والتي تتضمن عمليات التضمين
ابدأ روابط الاتصال بالإضافة إلى اسم الفهرس (اختياريًا) للعمل معه
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec تحديد التعيين للفهرس. يمكن توفير قوائم الحقول ذات الصلة للبحث عن الكلمات الرئيسية أو البحث الدلالي (المتجه الكثيف). يحتوي أيضًا على معلمات لحجم المتجه الكثيف حيث يمكن أن تختلف تلك المعلمات create_index - تستخدم المواصفات التي تم إنشاؤها مسبقًا لإنشاء فهرس جاهز للبحث
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - يقوم بتقسيم ملف csv كبير إلى أجزاء ويستخدم بشكل متكرر أداة تضمين مساعدة محددة مسبقًا لإنشاء قائمة التضمينات لكل قطعة ومن ثم تغذية النتائج إلى الفهرس
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )البحث - يسمح بتحديد إما الكلمة الرئيسية ("المطابقة" في المرن) أو البحث الدلالي (كثيف في المرن). ومن الجدير بالذكر أنه يتطلب نفس وظيفة التضمين المستخدمة في write_large_csv
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )بعد الإعداد الناجح، استخدم دفاتر الملاحظات التالية لإنجاز كل هذا
يجمع هذا الريبو بين الأعمال الرائعة التالية لأشخاص رائعين. يرجى الاطلاع على عملهم إذا لم تكن قد قمت بذلك بعد ...


