lieu
vements
محرك بحث بديل
تم إنشاؤه استجابة لبيئات اللامبالاة فيما يتعلق باستخدام البحث عن النص التشعبي واكتشافه. وبدلاً من ذلك، فإن الإنترنت ليس هو ما يمكن البحث فيه، بل هو الحي الذي يعيش فيه المرء. وبعبارة أخرى، Lieu هو محرك بحث محلي، وهو وسيلة لشبكات الويب الشخصية لزيادة الاتصالات الصدفة.
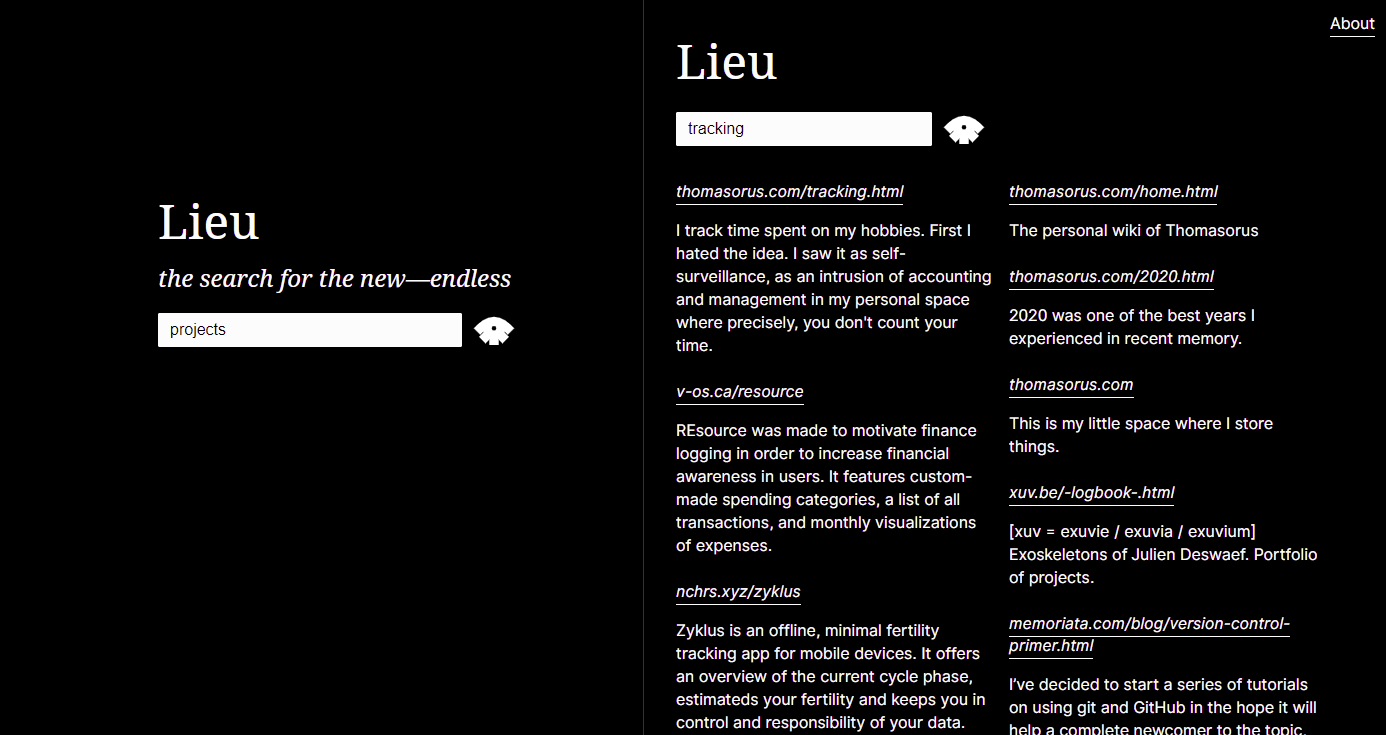
للحصول على بنية البحث الكاملة (بما في ذلك كيفية استخدام site: و -site: )، راجع بنية البحث ووثائق واجهة برمجة التطبيقات. لمزيد من النصائح، اقرأ الملحق.
$ lieu help
Lieu: neighbourhood search engine
Commands
- precrawl (scrapes config's general.url for a list of links: <li> elements containing an anchor <a> tag)
- crawl (start crawler, crawls all urls in config's crawler.webring file)
- ingest (ingest crawled data, generates database)
- search (interactive cli for searching the database)
- host (hosts search engine over http)
Example:
lieu precrawl > data/webring.txt
lieu crawl > data/crawled.txt
lieu ingest
lieu host
يتم إخراج أوامر الزحف والزحف المسبق الخاصة بـ Lieu إلى الإخراج القياسي، لسهولة فحص البيانات. عادةً ما تريد إعادة توجيه مخرجاتها إلى الملفات التي يقرأها Lieu، كما هو محدد في ملف التكوين. انظر أدناه للحصول على سير عمل نموذجي.
config.crawler.webringurl الخاص بالتكوين على تلك الصفحةprecrawl : lieu precrawl > data/webring.txtlieu crawl > data/crawled.txtlieu ingestlieu host بعد استيعاب البيانات باستخدام lieu ingest ، يمكنك أيضًا استخدام بدلاً من البحث في المجموعة في الجهاز باستخدام lieu search .
قم بتعديل قيم theme التكوين، المحددة أدناه.
ملف التكوين مكتوب بلغة TOML.
[ general ]
name = " Merveilles Webring "
# used by the precrawl command and linked to in /about route
url = " https://webring.xxiivv.com "
# used by the precrawl command to populate the Crawler.Webring file;
# takes simple html selectors. might be a bit wonky :)
webringSelector = " li > a[href]:first-of-type "
port = 10001
[ theme ]
# colors specified in hex (or valid css names) which determine the theme of the lieu instance
# NOTE: If (and only if) all three values are set lieu uses those to generate the file html/assets/theme.css at startup.
# You can also write directly to that file istead of adding this section to your configuration file
foreground = " #ffffff "
background = " #000000 "
links = " #ffffff "
[ data ]
# the source file should contain the crawl command's output
source = " data/crawled.txt "
# location & name of the sqlite database
database = " data/searchengine.db "
# contains words and phrases disqualifying scraped paragraphs from being presented in search results
heuristics = " data/heuristics.txt "
# aka stopwords, in the search engine biz: https://en.wikipedia.org/wiki/Stop_word
wordlist = " data/wordlist.txt "
[ crawler ]
# manually curated list of domains, or the output of the precrawl command
webring = " data/webring.txt "
# domains that are banned from being crawled but might originally be part of the webring
bannedDomains = " data/banned-domains.txt "
# file suffixes that are banned from being crawled
bannedSuffixes = " data/banned-suffixes.txt "
# phrases and words which won't be scraped (e.g. if a contained in a link)
boringWords = " data/boring-words.txt "
# domains that won't be output as outgoing links
boringDomains = " data/boring-domains.txt "
# queries to search for finding preview text
previewQueryList = " data/preview-query-list.txt "لاستخدامك الخاص، يجب تخصيص حقول التكوين التالية:
nameurlportsourcewebringbannedDomainsيمكن أن تظل الملفات المحددة بواسطة التكوين التالية كما هي إلا إذا كانت لديك متطلبات محددة:
databaseheuristicswordlistbannedSuffixespreviewQueryListللحصول على ملخص كامل للملفات ووظائفها المختلفة، راجع وصف الملفات.
بناء ثنائي:
# this project has an experimental fulltext-search feature, so we need to include sqlite's fts engine (fts5)
go build --tags fts5
# or using go run
go run --tags fts5 . إنشاء ثنائيات إصدار جديدة:
./release.sh كود المصدر AGPL-3.0-or-later ، Inter متاح بموجب SIL OPEN FONT LICENSE Version 1.1 ، Noto Serif مرخص Apache License, Version 2.0 .


