VSA
1.0.0
[صفحة المشروع] [؟الورقة] [؟مساحة تعانق الوجه] [حديقة الحيوان النموذجية] [مقدمة] [؟فيديو]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
يعتمد العرض التوضيحي المحلي على التدرج، ويمكنك ببساطة تشغيله باستخدام:
python app.py
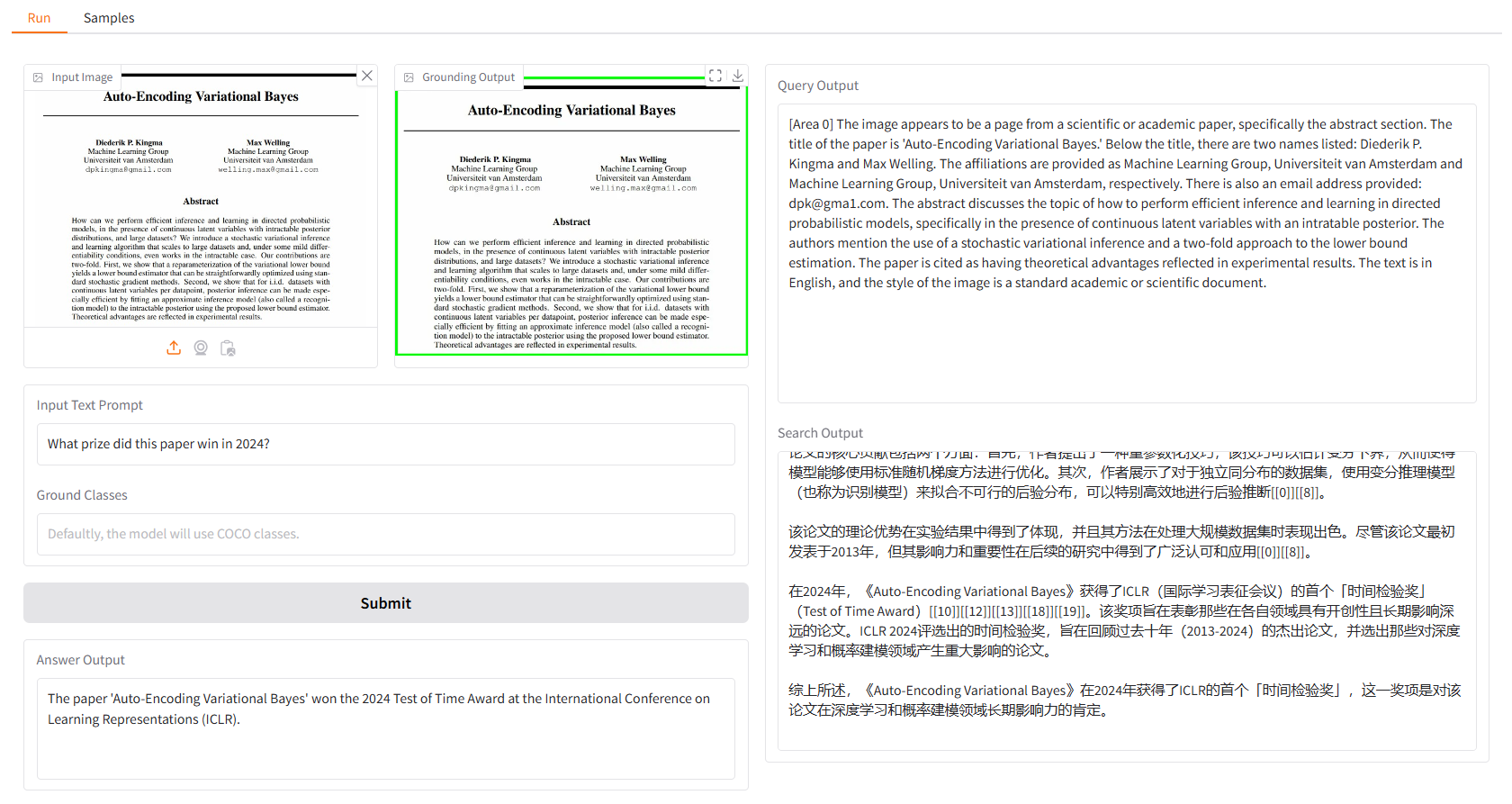
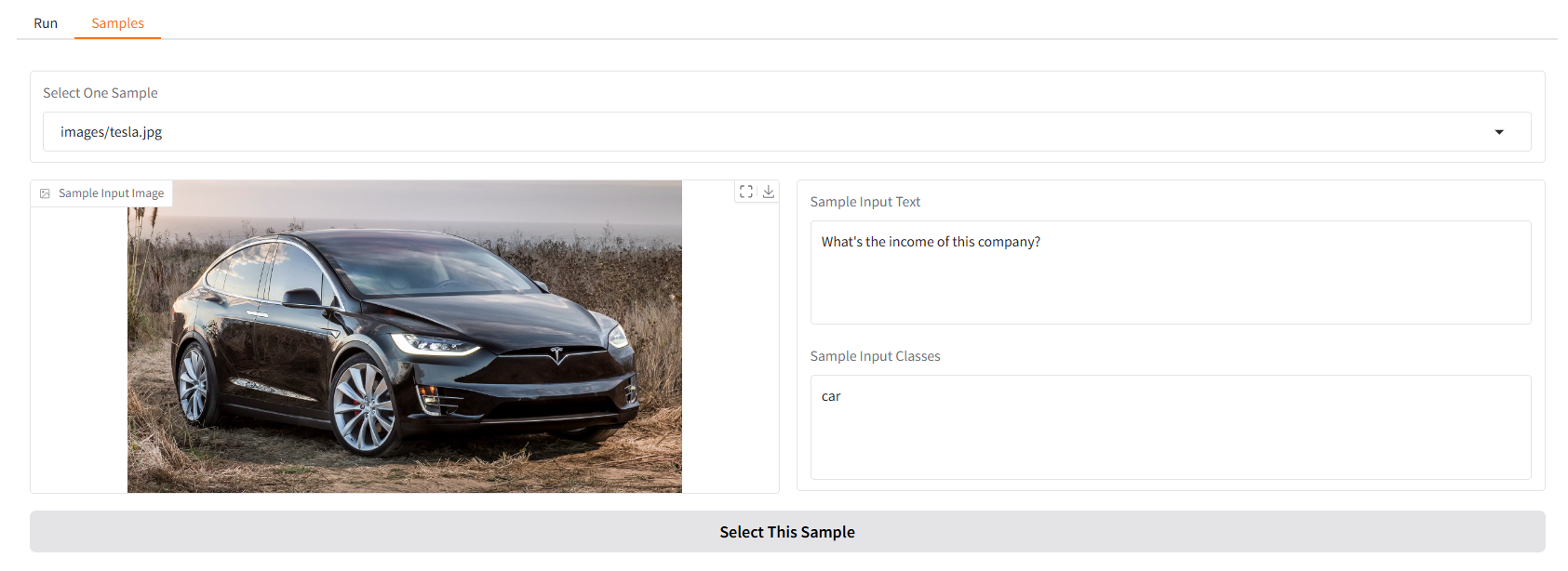
نحن نقدم لك بعض العينات لتبدأ بها. في واجهة مستخدم "النماذج"، يمكنك تحديد واحدة في لوحة "النماذج"، ثم انقر فوق "تحديد هذا النموذج"، وستجد أن نموذج الإدخال قد تم ملؤه بالفعل في واجهة المستخدم "تشغيل".
يمكنك أيضًا الدردشة مع Vision Search Assistant الخاص بنا في الجهاز عن طريق التشغيل.
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
ثم اختر صورة واكتب سؤالك.
تم إصدار هذا المشروع بموجب ترخيص Apache 2.0.
إن Vision Search Assistant مستوحى بشكل كبير من المساهمات البارزة التالية في مجتمع المصادر المفتوحة: GroundingDINO، LLaVA، MindSearch.
إذا وجدت هذا المشروع مفيدًا في بحثك، فيرجى مراعاة الاستشهاد بـ:
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


