ndvr
1.0.0
المركز الثاني في هاكاثون البحث العصبي؟
لقد شهدنا نموًا هائلاً لبيانات الفيديو في مجموعة متنوعة من مواقع مشاركة الفيديو مع توفر مليارات مقاطع الفيديو على الإنترنت، وأصبح إجراء استرجاع مقاطع الفيديو شبه المكررة (NDVR) من قاعدة بيانات فيديو واسعة النطاق تحديًا كبيرًا. يهدف NDVR إلى استرداد مقاطع الفيديو شبه المكررة من قاعدة بيانات فيديو ضخمة، حيث يتم تعريف مقاطع الفيديو شبه المكررة على أنها مقاطع فيديو قريبة بصريًا من مقاطع الفيديو الأصلية.
لدى المستخدمين حافز قوي لنسخ مقطع فيديو قصير رائج وتحميل نسخة معززة لجذب الانتباه. مع نمو مقاطع الفيديو القصيرة، تظهر صعوبات وتحديات جديدة لاكتشاف مقاطع الفيديو القصيرة المكررة تقريبًا.
هنا، قمنا ببناء حل البحث العصبي باستخدام Jina لحل تحدي NDVR.
جدول المحتويات

مثال على مقاطع الفيديو المرشحة الإيجابية الصعبة. الصف العلوي: مضلع جانبي، مفلتر بالألوان، ومغسول بالماء. الصف الأوسط: تم تغيير الشاشة الأفقية إلى شاشة عمودية بهوامش سوداء كبيرة. صف بوتون: استدارة
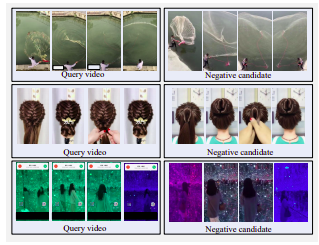
مثال على مقاطع الفيديو السلبية الصعبة. جميع المرشحين متشابهون بشكل مرئي مع الاستعلام ولكن ليس بالقرب من التكرارات.
هناك ثلاث إستراتيجيات لاختيار مقاطع الفيديو المرشحة:
قررنا اتباع استراتيجية الاسترجاع المتحول نظرًا لضيق الوقت والموارد. في التطبيقات الحقيقية، يقوم المستخدمون بنسخ مقاطع الفيديو الشائعة للحصول على حوافز شخصية. يختار المستخدمون عادةً تعديل مقاطع الفيديو المنسوخة قليلاً لتجاوز عملية الاكتشاف. تتضمن هذه التعديلات قص الفيديو وإدراج الحدود وما إلى ذلك.
لتقليد سلوك المستخدم هذا، قمنا بتعريف تحويل زمني واحد، أي تسريع الفيديو، وثلاثة تحويلات مكانية، أي اقتصاص الفيديو، وإدراج الحدود السوداء، وتدوير الفيديو.
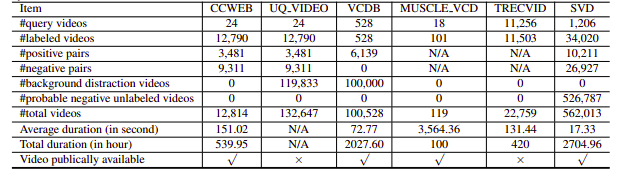
لسوء الحظ، كانت مجموعات بيانات NDVR التي تم البحث عنها إما منخفضة الدقة أو ضخمة أو محددة المجال أو غير متاحة للعامة (اتصلنا بعدد قليل منهم شخصيًا أيضًا). ومن ثم، قررنا إنشاء مجموعة بيانات صغيرة مخصصة للتجربة عليها.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexيتم تعريف تدفق الفهرس على النحو التالي:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueوينقسم هذا إلى الخطوات التالية:
نستخدم هنا ملف YAML لتحديد التدفق واستخدامه لفهرسة البيانات. تأخذ وظيفة index معلمة input_fn التي تأخذ مكررًا لتمرير مسارات الملفات، والتي سيتم تغليفها أيضًا في IndexRequest وإرسالها إلى التدفق.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query يمكنك بعد ذلك فتح Jinabox بنقطة النهاية المخصصة http://localhost:45678/api/search
يتم تعريف تدفق الاستعلام على النحو التالي:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlينقسم تدفق الاستعلام إلى الخطوات التالية:


