telegram archive server
v0.4.1 - 蔚蓝更新
روبوت بحث وأرشفة للدردشة الجماعية في Telegram مناسب لبيئة CJK.

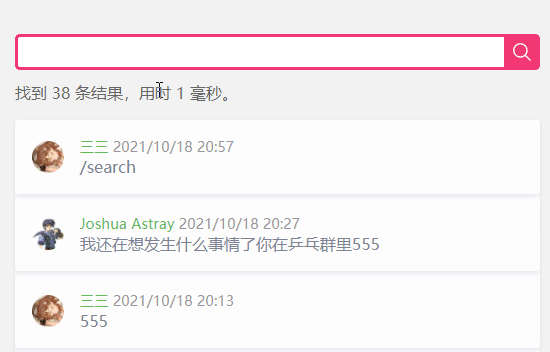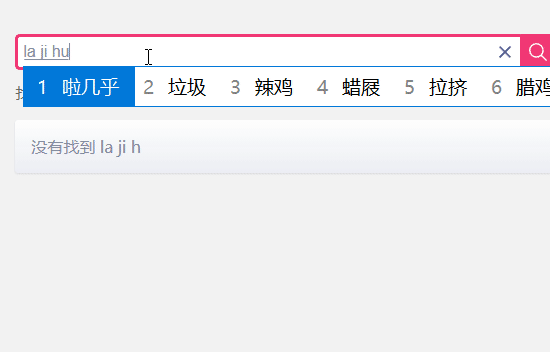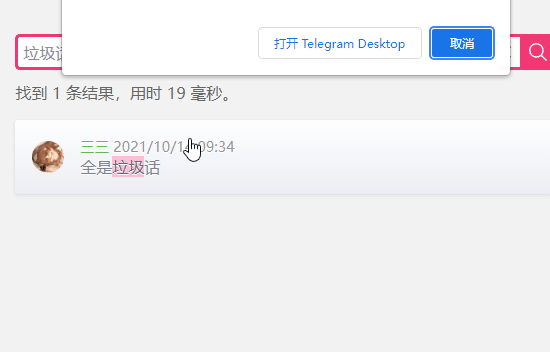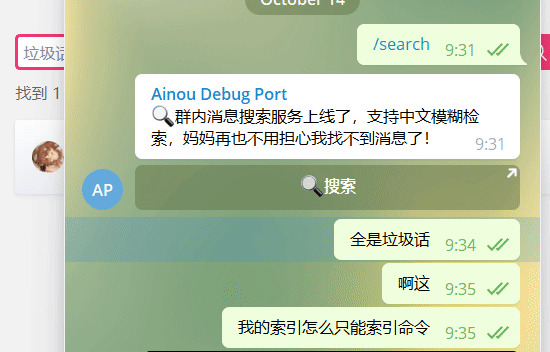
انقر فوق الزر [بحث] للمصادقة تلقائيًا وفتح واجهة البحث.
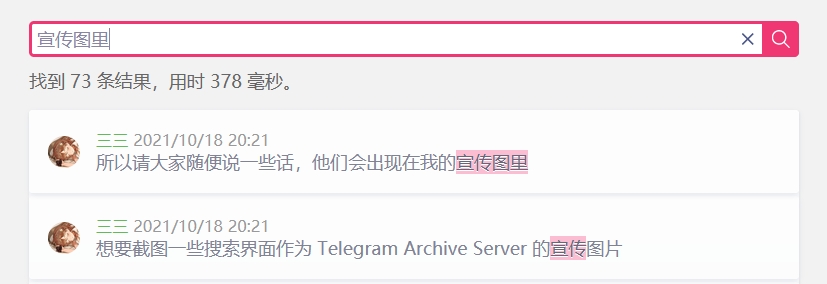
انقر على رابط الوقت للانتقال إلى واجهة الدردشة.
أنت بحاجة إلى:
قم بتنزيل ملف .env.example ، وارجع إلى التعليقات الداخلية، وقم بالتكوين وفقًا لذلك.
يمكنك حفظه كملف .env أو تكوينه كمتغير بيئة.
لا توفر TAS خدمة https مدمجة. يوصى باستخدام Caddy أو برنامج مشابه لعكس الوكيل TAS.
docker run -d --restart=always --env-file=.env quay.io/oott123/telegram-archive-serverبالطبع، يمكنك أيضًا تشغيله باستخدام Kubernetes أو docker-compose.
إذا لم يكن لديك Docker أو لا تريد استخدام Docker، فيمكنك أيضًا التجميع والنشر من التعليمات البرمجية المصدر. في هذه المرحلة تحتاج أيضًا إلى:
git clone https://github.com/oott123/telegram-archive-server.git
cd telegram-archive-server
# git checkout vX.X.X
cp .env.example .env
vim .env
yarn
yarn build
yarn start إرسال /search في المجموعة. قد يطالبك الروبوت بتعيين النطاق، ما عليك سوى اتباع التعليمات.
يجب على المستخدمين استيفاء المعايير التالية حتى تظهر الصورة الرمزية الخاصة بهم في نتائج البحث:
نظرًا لأن كفاءة فهرسة MeiliSearch ضعيفة للرسائل الجديدة، فلن تدخل الرسائل إلى الفهرس إلا عند استيفاء أي من الشروط التالية:
إذا لم يتم استخدام redis للاستمرار في قائمة انتظار الرسائل، فقد يتم فقدان الرسائل التي لم تدخل قائمة الانتظار عندما يكون البرنامج غير طبيعي أو عند إعادة تشغيل الخادم.
حاليًا يتم دعم استيراد المجموعة الفائقة فقط.
انقر فوق زر النقاط الثلاث الموجود على عميل سطح المكتب - قم بتصدير سجل الدردشة، وانتظر حتى يكتمل التصدير، واحصل على result.json .
ينفذ:
curl
-H " Content-Type: application/json "
-H " Authorization: Bearer $AUTH_IMPORT_TOKEN "
-XPOST -T result.json
http://localhost:3100/api/v1/import/fromTelegramGroupExportيمكن استيراد السجلات. لاحظ أنه يمكن استيراد السجلات من مجموعة واحدة فقط في المرة الواحدة.
إذا قمت بتمكين قائمة انتظار OCR، فستكون Redis مطلوبة (يمكن مشاركة مثيل مع ذاكرة التخزين المؤقت) وتكوين خدمة التعرف على طرف ثالث. عملية تحديد الهوية هي كما يلي:
يمكن إكمال التعرف والتخزين على مثيلات دور مختلفة: سيتم إكمال تنزيل الصور وتخزين النص على مثيل Bot، ويحتاج مثيل OCR فقط إلى الوصول إلى خدمة OCR.
يسمح هذا التصميم للمشرفين بتصميم تعريف مركزي دون اتصال (على سبيل المثال، استخدام مثيل استباقي لتشغيل خدمة التعريف وإيقاف تشغيلها بعد مسح قائمة الانتظار) لتقليل تكاليف التعريف.
إذا كنت تستخدم خدمة سحابية تابعة لجهة خارجية، فيمكنك إيقاف تشغيل قائمة انتظار OCR مباشرة، أو تمكين أدوار Bot وOCR في نفس المثيل.
ارجع إلى وثائق التعرف على النص في Google Cloud Vision وقواعد فوترة Google Cloud Vision. التكوين هو كما يلي:
OCR_DRIVER=google
OCR_ENDPOINT=eu-vision.googleapis.com # 或者 us-vision.googleapis.com ,决定 Google 在何处存储处理数据
GOOGLE_APPLICATION_CREDENTIALS=/path/to/google/credentials.json # 从 GCP 后台下载的 json 鉴权文件أنت بحاجة إلى مثيل paddleocr-web. التكوين هو كما يلي:
OCR_DRIVER=paddle-ocr-web
OCR_ENDPOINT=http://127.0.0.1:8980/apiقم بإنشاء مورد Azure Vision وقم بتكوين معلومات المورد كما يلي:
OCR_DRIVER=azure
OCR_ENDPOINT=https://tas.cognitiveservices.azure.com
OCR_CREDENTIALS=000000000000000000000000000000000docker run [...] dist/main ocr,bot
# or
node dist/main ocr,botDEBUG=app: * ,grammy * yarn start:debug بعد مصادقة خدمة البحث، سينتقل الخادم إلى: $HTTP_UI_URL/index.html مع معلمات URL التالية:
tas_server - عنوان URL الأساسي للخادم، على هيئة http://localhost:3100/api/v1tas_indexName - رقم المجموعة، على شكل supergroup1234567890tas_authKey - JWT صادر عن الخادم، والذي يمكن استخدامه كمفتاح واجهة برمجة تطبيقات MeiliSearch. يمكن البحث عن /api/v1/search/compilable/meili كمثيل MeiliSearch عادي.
يجب أن يستخدم اسم الفهرس رقم مجموعة في شكل supergroup1234567890 ؛ مفتاح API هو JWT الصادر عن الخادم.
يرجى ملاحظة أن الفلتر غير متاح مؤقتًا لأسباب أمنية.


