CrawlerTutorial
1.0.0
عندما نتصفح الإنترنت، غالبًا ما نرى مجموعة متنوعة من المحتويات المثيرة للاهتمام، مثل الأخبار والمنتجات ومقاطع الفيديو والصور وما إلى ذلك. ولكن إذا كنت ترغب في جمع كمية كبيرة من المعلومات المحددة من صفحات الويب هذه، فستستغرق العمليات اليدوية وقتًا طويلاً وشاقة.
في هذا الوقت، أصبح زاحف الويب (Web Crawler) مفيدًا! ببساطة، زاحف الويب هو برنامج يمكنه تقليد سلوك المتصفح البشري والزحف إلى معلومات الويب تلقائيًا. باستخدام إمكانيات التشغيل الآلي لهذا البرنامج، يمكننا بسهولة "الزحف" إلى البيانات التي نهتم بها من موقع الويب ثم تخزين هذه البيانات لتحليلها لاحقًا.
الطريقة التي يعمل بها زاحف الويب عادةً هي إرسال طلب HTTP أولاً إلى موقع الويب المستهدف، ثم الحصول على استجابة HTML من موقع الويب، وتحليل محتوى الصفحة، ثم استخراج البيانات المفيدة. على سبيل المثال، إذا أردنا جمع العنوان والمؤلف والوقت والمعلومات الأخرى للمقالات الموجودة على لوحة ثرثرة PTT، فيمكننا استخدام تقنية زاحف الويب لالتقاط هذه المعلومات وتخزينها تلقائيًا. بهذه الطريقة يمكنك الحصول على المعلومات التي تحتاجها دون تصفح الموقع يدويًا.
تحتوي برامج زحف الويب على العديد من التطبيقات العملية، مثل:
بالطبع، عند استخدام برامج زحف الويب، نحتاج إلى الالتزام بشروط الاستخدام وسياسة الخصوصية الخاصة بالموقع، ولا يمكننا الزحف إلى المعلومات بشكل ينتهك لوائح الموقع. وفي الوقت نفسه، من أجل ضمان التشغيل الطبيعي لموقع الويب، نحتاج أيضًا إلى تصميم استراتيجيات الزحف المناسبة لتجنب التحميل الزائد على موقع الويب.
يستخدم هذا البرنامج التعليمي Python3 وسيستخدم النقطة لتثبيت الحزم المطلوبة. يجب تثبيت الحزم التالية:
requests : تستخدم لإرسال واستقبال طلبات واستجابات HTTP.requests_html : يُستخدم لتحليل العناصر والزحف إليها في HTML.rich : دع المعلومات يتم إخراجها إلى وحدة التحكم بشكل جميل، مثل عرض جدول جميل.lxml أو PyQuery : يستخدم لتحليل العناصر في HTML.استخدم الإرشادات التالية لتثبيت هذه الحزم:
pip install requests requests_html rich lxml PyQueryفي الفصل الأساسي، سنقدم بإيجاز كيفية جمع البيانات من صفحة ويب PTT، مثل عنوان المقالة والمؤلف والوقت.
دعونا نستخدم مقالات قراءة الإصدارات الخاصة بـ PTT كأهداف للزاحف لدينا!
عند الزحف إلى صفحة ويب، نستخدم وظيفة requests.get() لمحاكاة المتصفح الذي يرسل طلب HTTP GET "لتصفح" صفحة الويب. ستعيد هذه الوظيفة كائن requests.Response ، الذي يحتوي على محتوى الاستجابة لصفحة الويب. ومع ذلك، تجدر الإشارة إلى أن هذا المحتوى يتم تقديمه في شكل كود مصدر نص خالص ولا يتم عرضه بواسطة المتصفح. يمكننا الحصول عليه من خلال خاصية response.text .
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )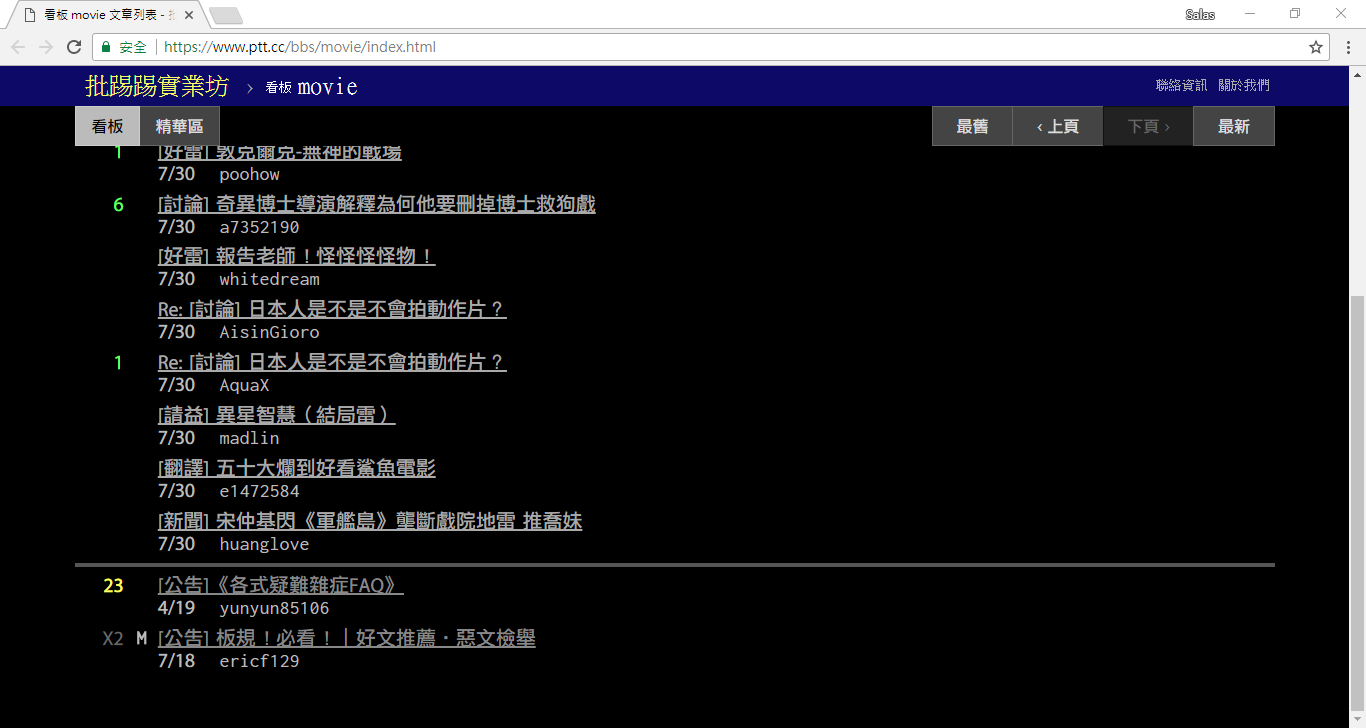
في الاستخدامات اللاحقة، سنحتاج إلى استخدام requests_html لتوسيع requests بالإضافة إلى التصفح مثل المتصفح، نحتاج أيضًا إلى تحليل صفحات الويب requests_html.HTML HTML. سوف تقوم requests_html بتعبئة كود المصدر الخاص بالنص العادي في response.text لاستخدامه لاحقًا. إعادة الكتابة أيضًا بسيطة جدًا، استخدم session.get() لاستبدال requests.get() أعلاه.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )ومع ذلك، عندما نحاول تطبيق هذا الأسلوب على النميمة، قد نواجه أخطاء. وذلك لأنه عندما نتصفح لوحة الشائعات لأول مرة، سيؤكد موقع الويب ما إذا كنا أكبر من 18 عامًا، وعندما ننقر للتأكيد، سيقوم المتصفح بتسجيل ملفات تعريف الارتباط المقابلة حتى لا نسأل مرة أخرى في المرة القادمة أدخل (يمكنك محاولة استخدام وضع التصفح المتخفي لفتح الاختبار وإلقاء نظرة على الصفحة الرئيسية لإصدار Bagua). ومع ذلك، بالنسبة لبرامج زحف الويب، نحتاج إلى تسجيل ملف تعريف الارتباط الخاص هذا حتى نتمكن من التظاهر باجتياز اختبار الثمانية عشر عامًا أثناء التصفح.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) بعد ذلك، يمكننا استخدام التابع response.html.find() لتحديد موقع العنصر واستخدام محدد CSS لتحديد العنصر الهدف. في هذه الخطوة، يمكننا أن نلاحظ أنه في إصدار الويب PTT، توجد معلومات عنوان كل مقالة في علامة div مع فئة r-ent . ولذلك، يمكننا استخدام div.r-ent محدد CSS لاستهداف هذه العناصر.
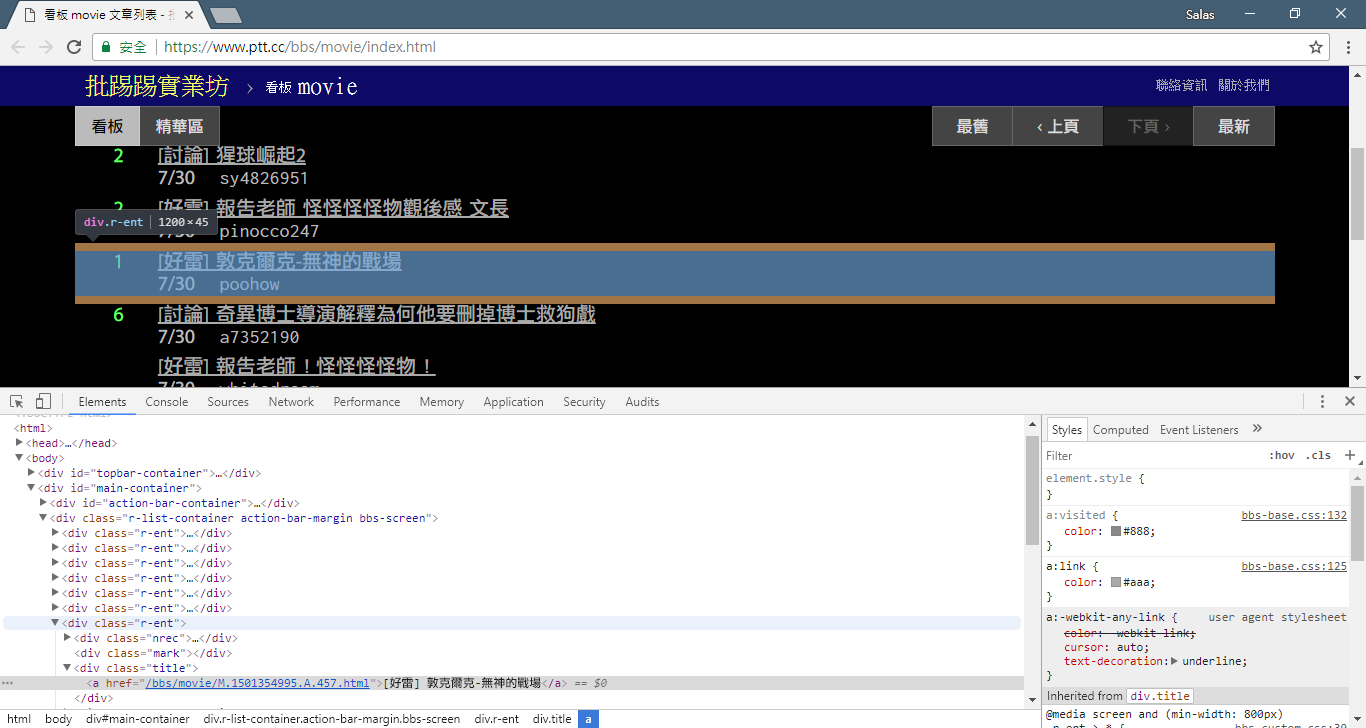
سيؤدي استخدام التابع response.html.find() إلى إرجاع قائمة بالعناصر التي تستوفي الشروط، حتى نتمكن من استخدام حلقة for لمعالجة هذه العناصر واحدًا تلو الآخر. داخل كل عنصر، يمكننا استخدام element.find() لتحليل العنصر بشكل أكبر واستخدام محددات CSS لتحديد المعلومات المراد استخراجها. في هذا المثال، يمكننا استخدام div.title لمحدد CSS لاستهداف عنصر العنوان. وبالمثل، يمكننا استخدام خاصية element.text للحصول على محتوى النص لعنصر ما.
فيما يلي نموذج التعليمات البرمجية باستخدام requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... في الخطوة السابقة، استخدمنا التابع response.html.find() لتحديد عناصر كل مقالة. يتم استهداف هذه العناصر باستخدام محدد CSS div.r-ent . يمكنك استخدام ميزة أدوات المطور لمراقبة بنية العناصر لصفحة الويب. بعد فتح صفحة الويب والضغط على المفتاح F12، سيتم عرض لوحة أدوات المطور، والتي تحتوي على بنية HTML لصفحة الويب ومعلومات أخرى.
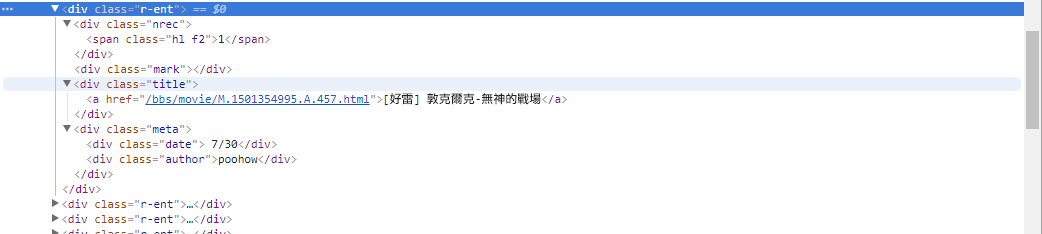
باستخدام أدوات المطور، يمكنك استخدام مؤشر الماوس لتحديد عنصر معين على صفحة الويب، ثم عرض بنية HTML للعنصر وسمات CSS والتفاصيل الأخرى في لوحة أدوات المطور. يساعدك هذا على تحديد العنصر الذي تريد استهدافه ومحدد CSS المقابل. بالإضافة إلى ذلك، قد تكتشف لماذا يخطئ البرنامج أحيانًا؟ ! بالنظر إلى إصدار الويب، وجدت أنه عندما تم حذف مقالة على الصفحة، كانت結構الكود المصدري لعنصر <本文已被刪除> على صفحة الويب مختلفة عن البنية الأصلية! لذا يمكننا تعزيزها بشكل أكبر للتعامل مع الموقف الذي يتم فيه حذف المقالات.
لنعد الآن إلى نموذج التعليمات البرمجية لاستخراج المعلومات باستخدام requests_html :
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )معالجة النصوص الناتج:
هنا يمكننا استخدام rich لعرض مخرجات جميلة. أولاً، قم بإنشاء كائن جدول rich ، ثم استبدل print في حلقة رمز المثال أعلاه بـ add_row إلى الجدول. وأخيرًا، نستخدم وظيفة print rich لإخراج الجدول بشكل صحيح إلى الوحدة الطرفية.
نتيجة التنفيذ
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )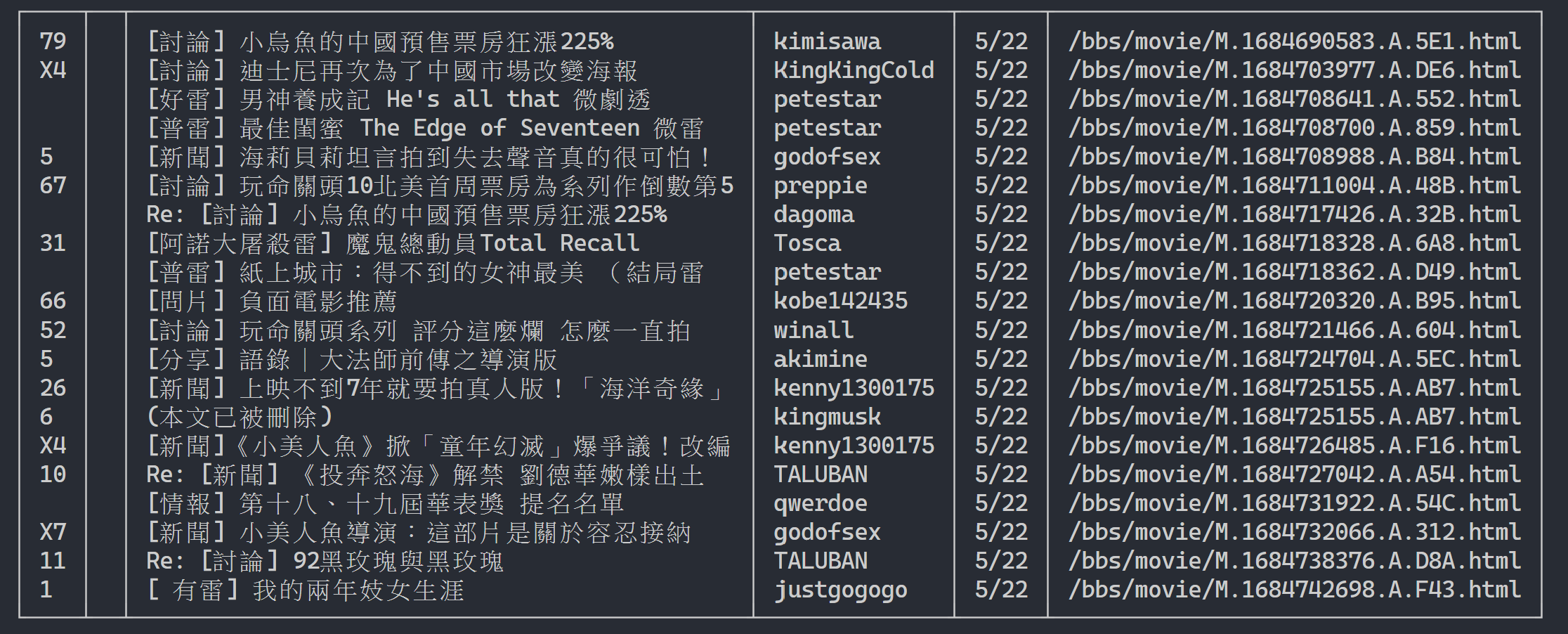
الآن، سوف نستخدم "طريقة الملاحظة" للعثور على رابط الصفحة السابقة. لا، أنا لا أسألك عن مكان الزر في متصفحك، بل عن "شجرة المصدر" في أدوات المطورين. أعتقد أنك اكتشفت أن الارتباط التشعبي للانتقال إلى الصفحة موجود في العنصر <a class="btn wide"> في <div class="action-bar"> . ولذلك يمكننا استخراجها على النحو التالي:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )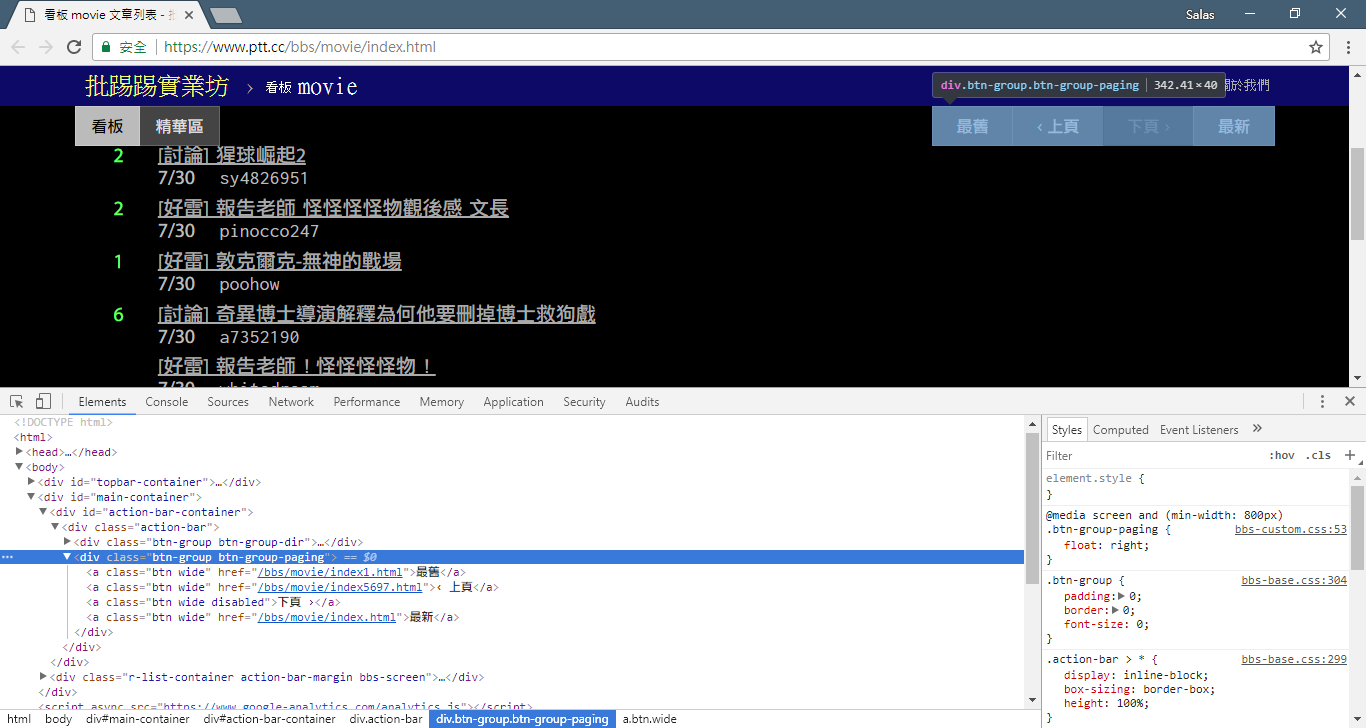
ما نحتاجه هو وظيفة "الصفحة السابقة" لماذا؟ نظرًا لأن أحدث المقالات في PTT يتم عرضها في المقدمة، لذا إذا كنت تريد البحث عن معلومات، فيجب عليك التمرير للأمام.
فكيف استخدامه؟ قم أولاً بالحصول على href الثاني في control (الفهرس هو 1)، ثم قد يبدو بهذا الشكل /bbs/movie/index3237.html ويجب أن يكون عنوان موقع الويب الكامل (URL) هو https://www.ptt.cc/ ( عنوان url للمجال)، لذا استخدم urljoin() (أو اتصال سلسلة مباشر) لمقارنة رابط الصفحة الرئيسية للفيلم ودمجه مع الرابط الجديد في عنوان URL كامل!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url الآن دعونا نعيد ترتيب الوظيفة لتسهيل الشرح اللاحق، فلنغير مثال معالجة كل عنصر من عناصر المقالة في الخطوة 3: دعنا نلقي نظرة على رسائل العنوان هذه في وظيفة مستقلة parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsبعد ذلك، يمكننا التعامل مع محتوى متعدد الصفحات
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlنتيجة الإخراج:
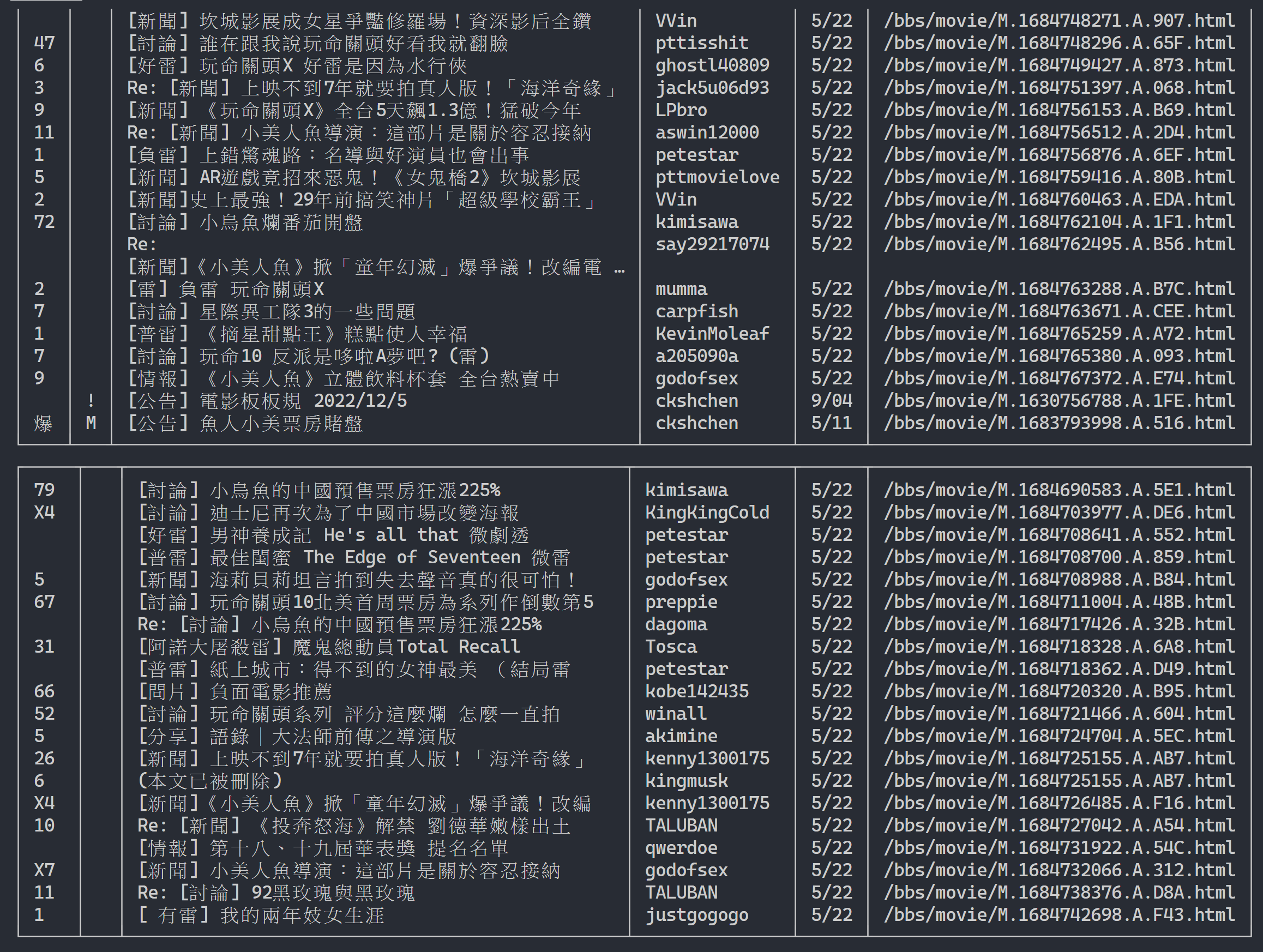
بعد الحصول على معلومات قائمة المقالات، فإن الخطوة التالية هي الحصول على محتوى المقالة (مقالة PO) (محتوى النشر)! link في البيانات الوصفية هو رابط كل مقالة، كما نستخدم urllib.parse.urljoin لتسلسل عنوان URL الكامل ثم إصدار HTTP GET للحصول على محتوى المقالة. يمكننا أن نلاحظ أن مهمة التقاط محتوى كل مقالة متكررة للغاية ومناسبة جدًا للمعالجة باستخدام طريقة الموازاة.
في Python، يمكنك استخدام multiprocessing.Pool Pool للقيام ببرمجة معالجة متعددة عالية المستوى ~ هذه هي أسهل طريقة لاستخدام العمليات المتعددة في Python! إنها مناسبة جدًا لسيناريو تطبيق SIMD (بيانات متعددة التعليمات الفردية). استخدم صيغة العبارة with لتحرير موارد العملية تلقائيًا بعد الاستخدام. يعد استخدام ProcessPool أيضًا بسيطًا جدًا، وهو pool.map(function, items) ، والذي يشبه إلى حد ما مفهوم البرمجة الوظيفية. قم بتطبيق الوظيفة على كل عنصر، وأخيرًا احصل على نفس عدد قوائم النتائج مثل العناصر.
يُستخدم في مهمة الزحف إلى محتوى المقالة التي تم تقديمها مسبقًا:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )مرفق نتائج التجربة:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章يمكن ملاحظة أن سرعة التنفيذ الإجمالية قد تم تسريعها بما يقرب من خمس مرات، ولكن كلما زاد عدد Process كان ذلك أفضل. بالإضافة إلى مواصفات الأجهزة مثل وحدة المعالجة المركزية، فإن ذلك يعتمد بشكل أساسي على قيود الأجهزة الخارجية مثل بطاقات الشبكة و سرعات الشبكة.
يمكن العثور على الكود أعلاه في ( src/basic_crawler.py )!
ميزة جديدة في PTT Web: البحث! متاح أخيرا على نسخة الويب
فلنستخدم أيضًا إصدار الفيلم من PTT كهدف للزاحف! يتضمن المحتوى القابل للبحث في الميزة الجديدة ما يلي:
يمكن لجميع الثلاثة الأوائل العثور على القواعد من الإصدار الجديد للكود المصدري للصفحة وإرسال الطلبات، ولكن يبدو أن البحث عن عدد التغريدات لم يظهر في واجهة مستخدم إصدار الويب، لذا فإليك المعلمات التي استخرجها المؤلف من PTT 網站原始碼. يتضمن PTT الذي نتصفحه عادةً خادم BBS (أي BBS) وخادم الويب الأمامي (إصدار الويب). خادم الويب الأمامي مكتوب بلغة Go (Golang) ويمكنه الوصول مباشرة إلى الواجهة الخلفية بيانات BBS واستخدامها يعرض وضع التفاعل العام لموقع الويب المحتوى في صفحة ويب للتصفح.
في الواقع، من السهل جدًا استخدام هذه الوظائف الجديدة، ما عليك سوى استخدام طلب HTTP GET وإضافة سلسلة استعلام قياسية للحصول على هذه المعلومات. عنوان URL endpoint الذي يوفر وظيفة البحث هو /bbs/{看板名稱}/search ، ما عليك سوى استخدام الاستعلام المقابل للحصول على نتائج البحث من هنا. أولاً، خذ الكلمة الرئيسية للعنوان كمثال،
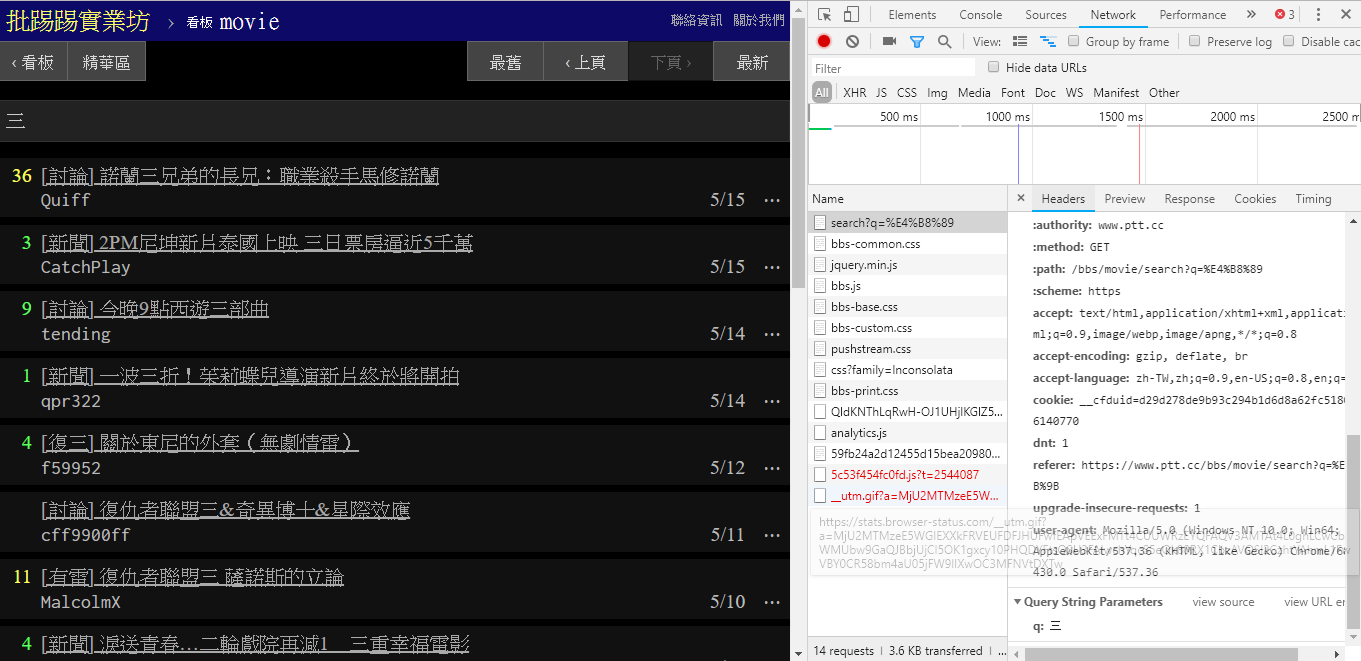
كما يتبين من الركن الأيمن السفلي من الصورة، عند البحث، يتم بالفعل إرسال طلب GET مع q=三إلى endpoint ، لذلك يجب أن يكون عنوان URL الكامل بالكامل مثل https://www.ptt.cc/bbs/movie/search?q=三، قد يكون عنوان URL المنسوخ من شريط العناوين على شكل https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 لأن الصينيين كانوا HTML مشفر ولكنه يمثل نفس المعنى. في requests ، إذا كنت تريد إضافة معلمات استعلام إضافية، فلن تحتاج إلى إنشاء نموذج السلسلة يدويًا بنفسك، كل ما عليك فعله هو وضعها في معلمات الوظيفة من خلال dict() لـ param= ، مثل هذا:
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })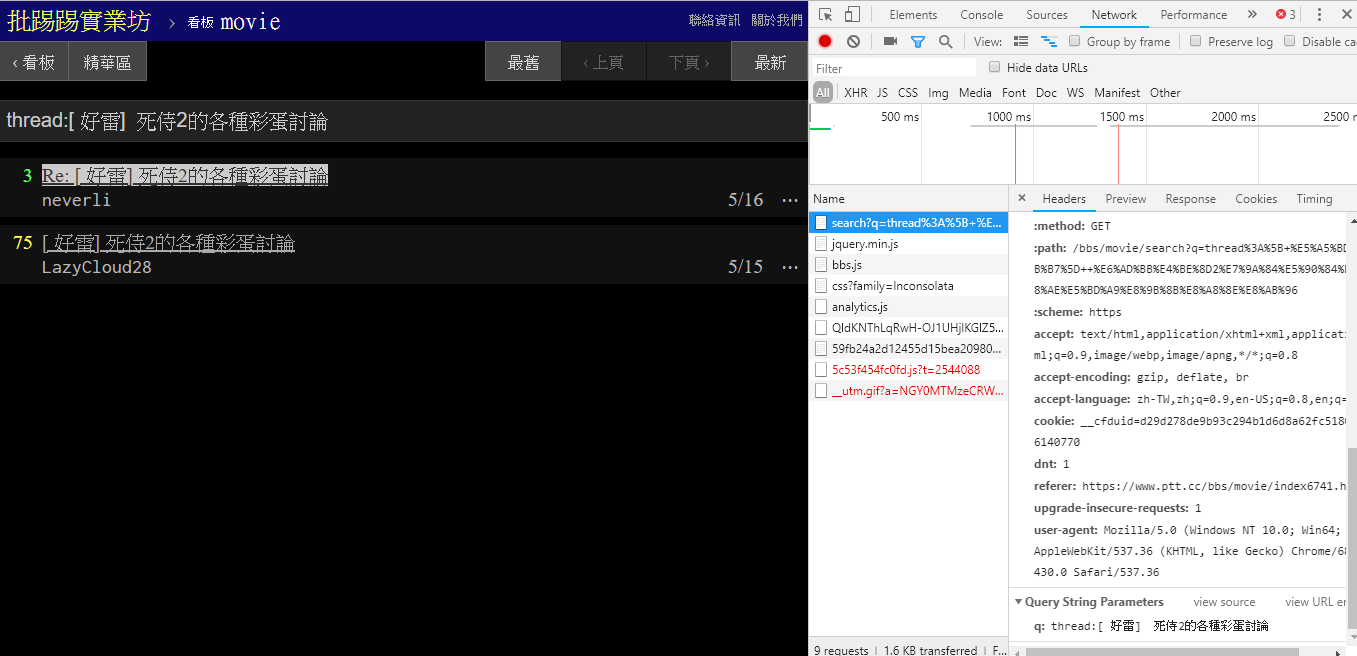
عند البحث عن نفس المقالة (الموضوع)، يمكنك أن ترى من المعلومات الموجودة في الزاوية اليمنى السفلية أنك تقوم بالفعل بربط thread: أمام العنوان وإرسال الاستعلام.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })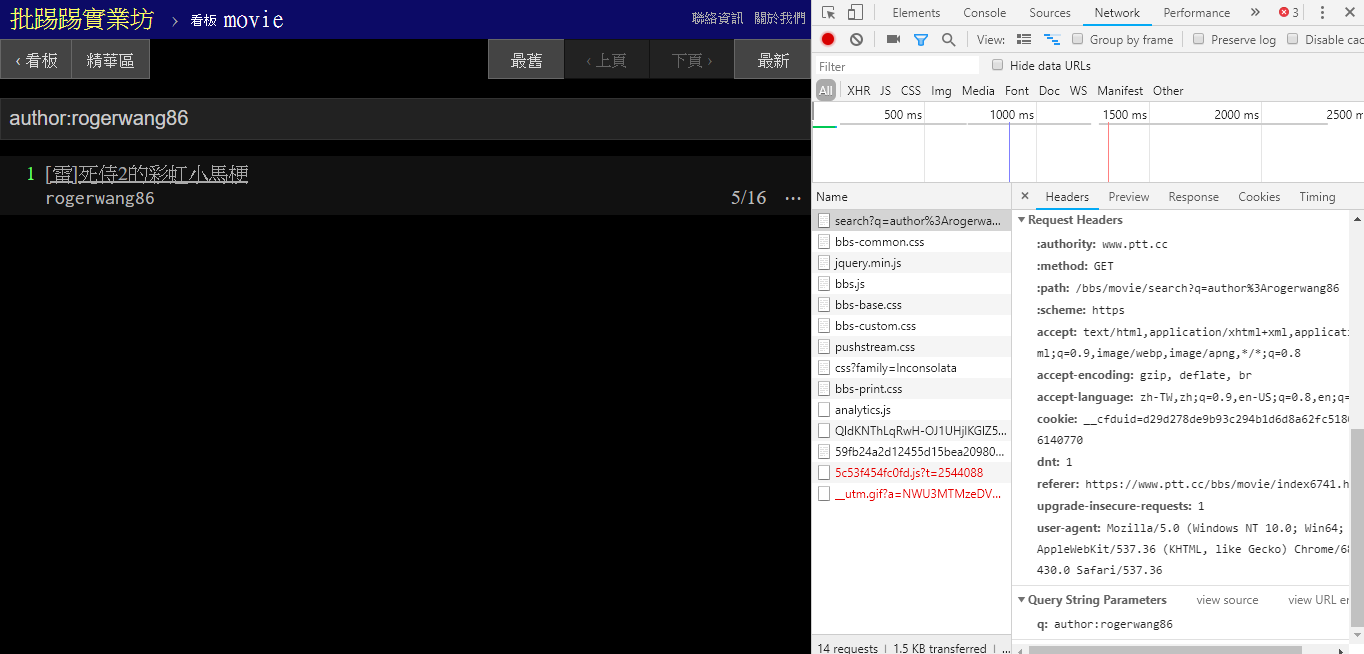
عند البحث عن مقالات لنفس المؤلف (المؤلف)، يمكن أيضًا أن ترى من المعلومات الموجودة في الزاوية اليمنى السفلية أن سلسلة author: متصلة باسم المؤلف ثم يتم إرسال الاستعلام.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })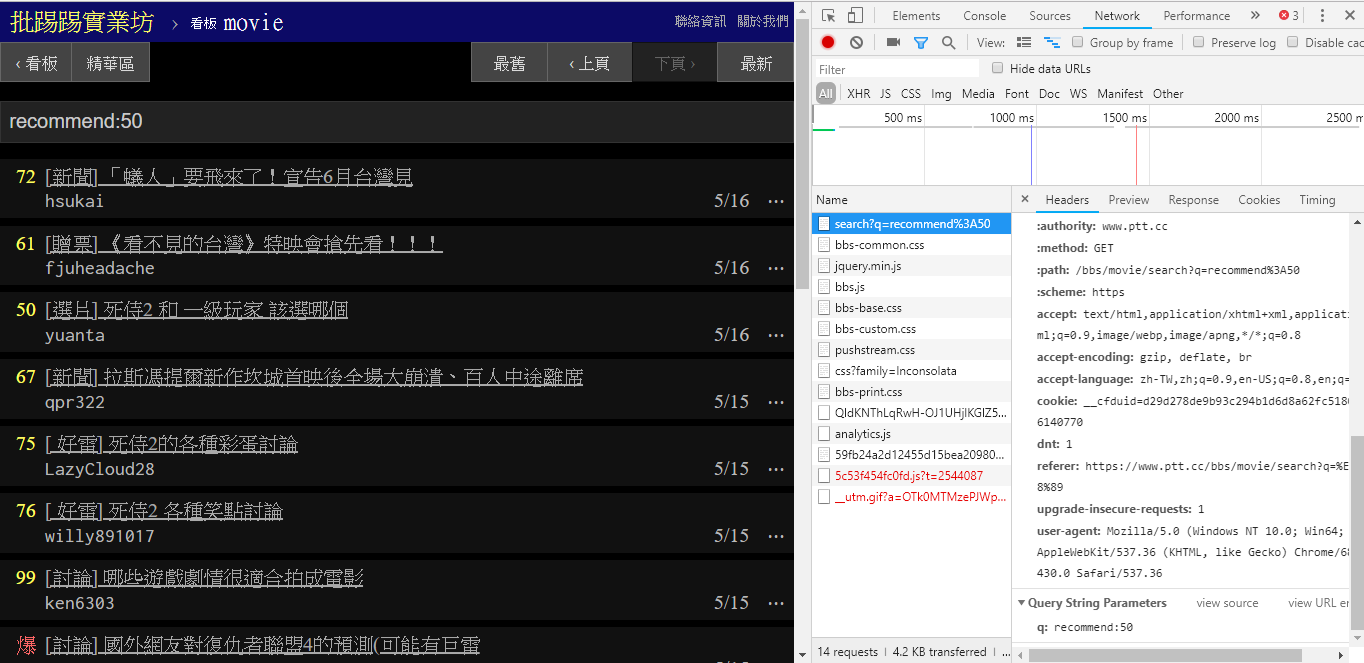
عند البحث عن مقالات تحتوي على عدد تغريدات أكبر من (موصى به)، قم بسلسلة سلسلة recommend: مع الحد الأدنى لعدد التغريدات التي تريد البحث عنها ثم أرسل الاستعلام. بالإضافة إلى ذلك، يمكن العثور على الكود المصدري لخادم الويب PTT أنه لا يمكن تعيين عدد التغريدات إلا ضمن ±100.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })كود مصدر وظيفة تحليل PTT Web لهذه المعلمات
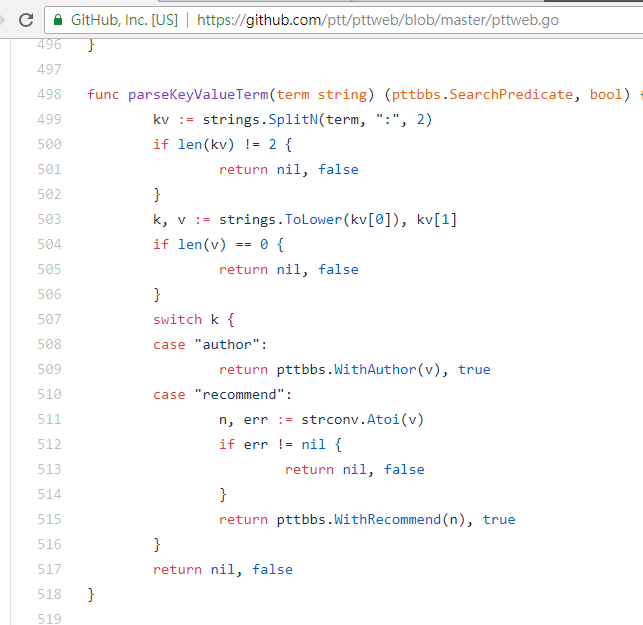
ومن الجدير بالذكر أيضًا أن العرض النهائي لنتائج البحث هو نفس التخطيط العام المذكور في الأساسيات، لذا يمكنك إعادة استخدام الوظائف السابقة مباشرةً Don't do it again!
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] هناك معلمة أخرى في البحث، وهي أن عدد page يشبه تمامًا بحث Google، وقد يحتوي الشيء الذي تم البحث عنه على عدة صفحات، لذا يمكنك استخدام هذه المعلمة الإضافية للتحكم في صفحة النتائج التي تريد الحصول عليها دون الحاجة إلى تحليل الارتباط الصفحة.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) يمكن أن يؤدي دمج جميع الوظائف السابقة في محلل ptt إلى توفير وظائف سطر الأوامر وبرامج爬蟲في شكل واجهات برمجة التطبيقات التي يمكن استدعاؤها برمجيًا.
scrapy للزحف بشكل ثابت إلى بيانات الضغط والتحدث.
تم إنتاج هذا العمل بواسطة leVirve وتم إصداره بموجب ترخيص Creative Commons Attribution 4.0 الدولي.


