fine grained sentiment app streamlit
1.0.0
يحتوي هذا الريبو على ما يعادل Streamlit لتطبيق تفاعلي موجود، والذي يشرح نتائج تصنيف المشاعر الدقيقة، الموضحة بالتفصيل في هذه السلسلة المتوسطة.
تم تنفيذ عدد من المصنفات وشرح نتائجها باستخدام مفسر LIME. تم تدريب المصنفين على مجموعة بيانات Stanford Sentiment Treebank (SST-5). تسميات الفصل هي أي من [1, 2, 3, 4, 5] ، حيث 1 سلبي للغاية و 5 إيجابي للغاية.
Streamlit هو إطار عمل خفيف الوزن وبسيط لإنشاء لوحات المعلومات في Python. ينصب التركيز الرئيسي لـ Streamlit على تزويد المطورين بالقدرة على إنشاء نماذج أولية لتصميمات واجهة المستخدم الخاصة بهم بسرعة باستخدام أقل عدد ممكن من أسطر التعليمات البرمجية. يتم تجريد جميع المهام الثقيلة المطلوبة عادةً لنشر تطبيق ويب، مثل تحديد خادم الواجهة الخلفية ومساراته، والتعامل مع طلبات HTTP، وما إلى ذلك، بعيدًا عن المستخدم. ونتيجة لذلك، يصبح من السهل جدًا تنفيذ تطبيق ويب بسرعة، بغض النظر عن خبرة المطور.
أولاً، قم بإعداد بيئة افتراضية وتثبيتها من requirements.txt :
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
لمزيد من التطوير، ما عليك سوى تنشيط البيئة الافتراضية الموجودة.
source venv/bin/activate
بعد إعداد البيئة الافتراضية وتنشيطها، قم بتشغيل التطبيق باستخدام الأمر أدناه.
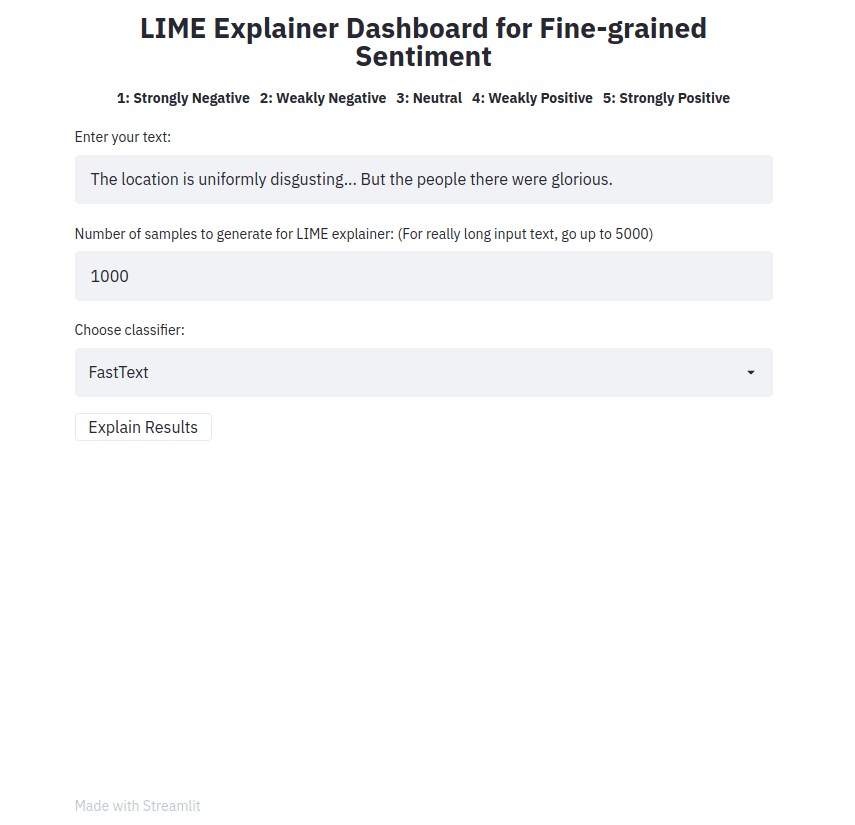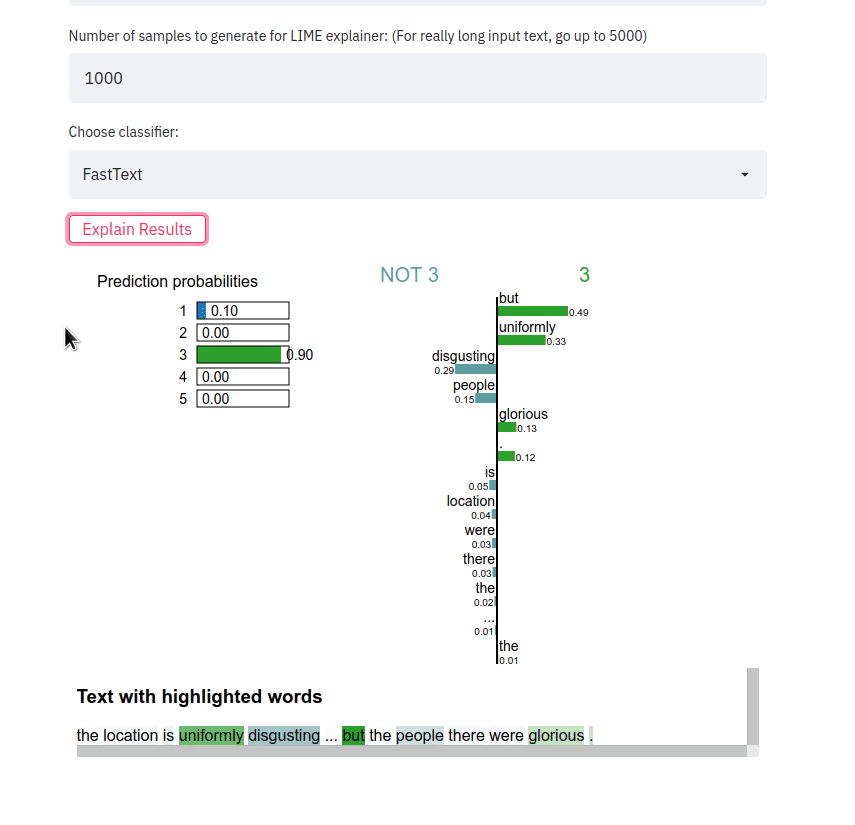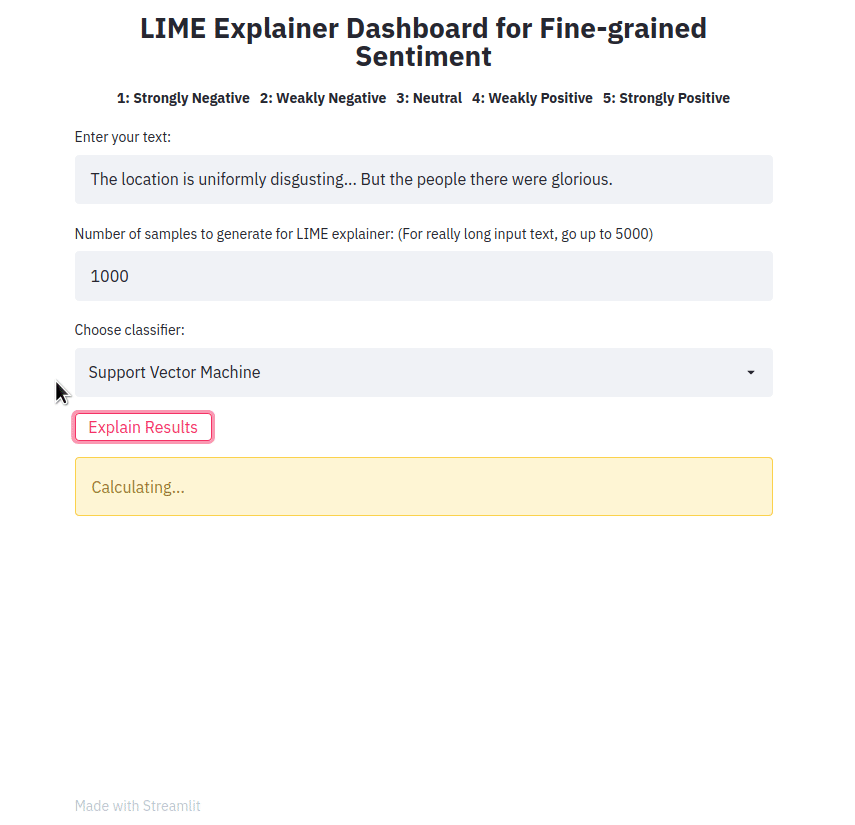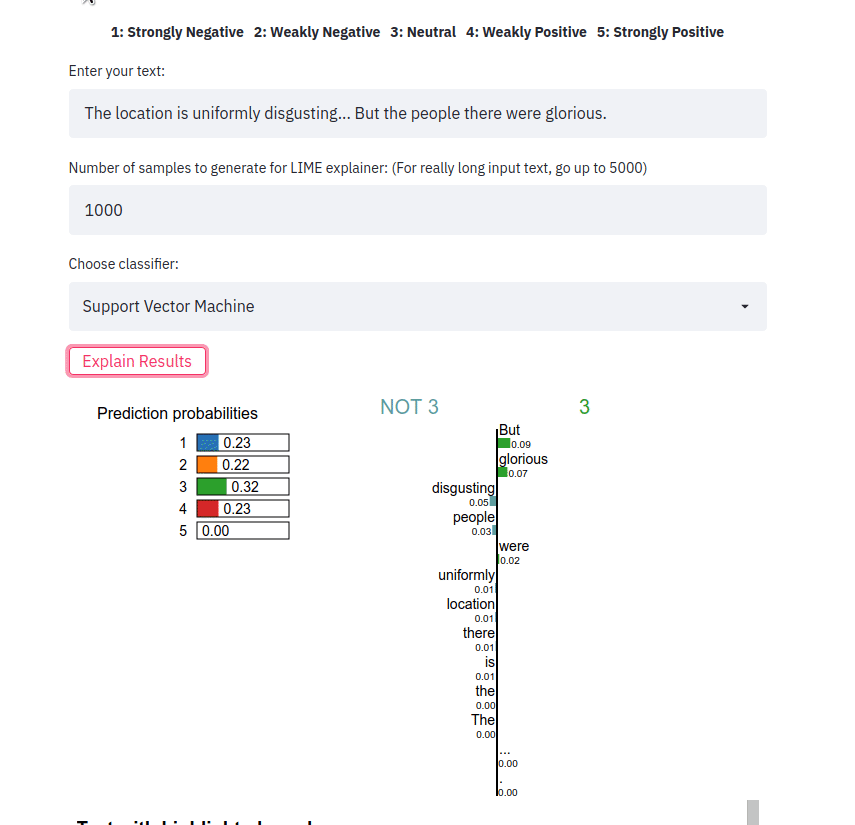
streamlit run app.py أدخل جملة، واختر نوع المصنف وانقر على الزر Explain results . يمكننا بعد ذلك ملاحظة الميزات (أي الكلمات أو الرموز المميزة) التي ساهمت في توقع المصنف بتسمية فئة معينة.
يأخذ تطبيق الواجهة الأمامية عينة نصية ويخرج تفسيرات LIME للطرق المختلفة. يتم نشر التطبيق باستخدام Heroku في هذا الموقع: https://sst5-explainer-streamlit.herokuapp.com/
العب بأمثلة النص الخاصة بك كما هو موضح أدناه وشاهد شرح نتائج المشاعر الدقيقة!
ملاحظة: نظرًا لأن النماذج المستندة إلى PyTorch (Flair والمحول السببي) مكلفة للغاية لتشغيل الاستدلال بها (تتطلب وحدة معالجة الرسومات)، لم يتم نشر هذه الأساليب. ومع ذلك، يمكن تشغيلها على مثيل محلي للتطبيق.