pianola
1.0.0
 البيانولا أثناء العمل" style="max-width: 100%;">
البيانولا أثناء العمل" style="max-width: 100%;">
pianola هو تطبيق يقوم بتشغيل موسيقى البيانو التي تم إنشاؤها بواسطة الذكاء الاصطناعي. يقوم المستخدمون بزراعة نموذج الذكاء الاصطناعي (أي "المطالبة") عن طريق تشغيل الملاحظات على لوحة المفاتيح، أو اختيار مقتطفات من المقطوعات الموسيقية الكلاسيكية.
في هذا التمهيدي، نشرح كيفية عمل الذكاء الاصطناعي وندخل في تفاصيل حول بنية النموذج.
يمكن تمثيل الموسيقى بعدة طرق، بدءًا من أشكال الموجات الصوتية الخام وحتى معايير MIDI شبه المنظمة. في pianola ، نقوم بتقسيم النغمات الموسيقية إلى فترات زمنية منتظمة وموحدة (على سبيل المثال، النغمات السادسة عشرة/شبه النوتة). تعتبر الملاحظات التي يتم تشغيلها خلال فترة زمنية تنتمي إلى نفس الخطوة الزمنية، وتشكل سلسلة من الخطوات الزمنية تسلسلاً. باستخدام التسلسل المستند إلى الشبكة كمدخل، يتنبأ نموذج الذكاء الاصطناعي بالملاحظات في الخطوة الزمنية التالية، والتي بدورها تُستخدم كمدخل للتنبؤ بالخطوة الزمنية اللاحقة بطريقة انحدارية.
بالإضافة إلى النغمات التي سيتم تشغيلها، يتنبأ النموذج أيضًا بالمدة (طول الوقت الذي يتم فيه الضغط على النغمة) والسرعة (مدى قوة الضغط على المفتاح) لكل نغمة.
يتكون النموذج من ثلاث وحدات: جهاز التضمين والمحول ووحدة فك التشفير. تستعير هذه الوحدات من بنيات معروفة جيدًا مثل شبكات Inception، ومحولات LLaMA، وسلاسل المصنفات متعددة العلامات، ولكن يتم تكييفها للعمل مع البيانات الموسيقية ودمجها في نهج جديد.
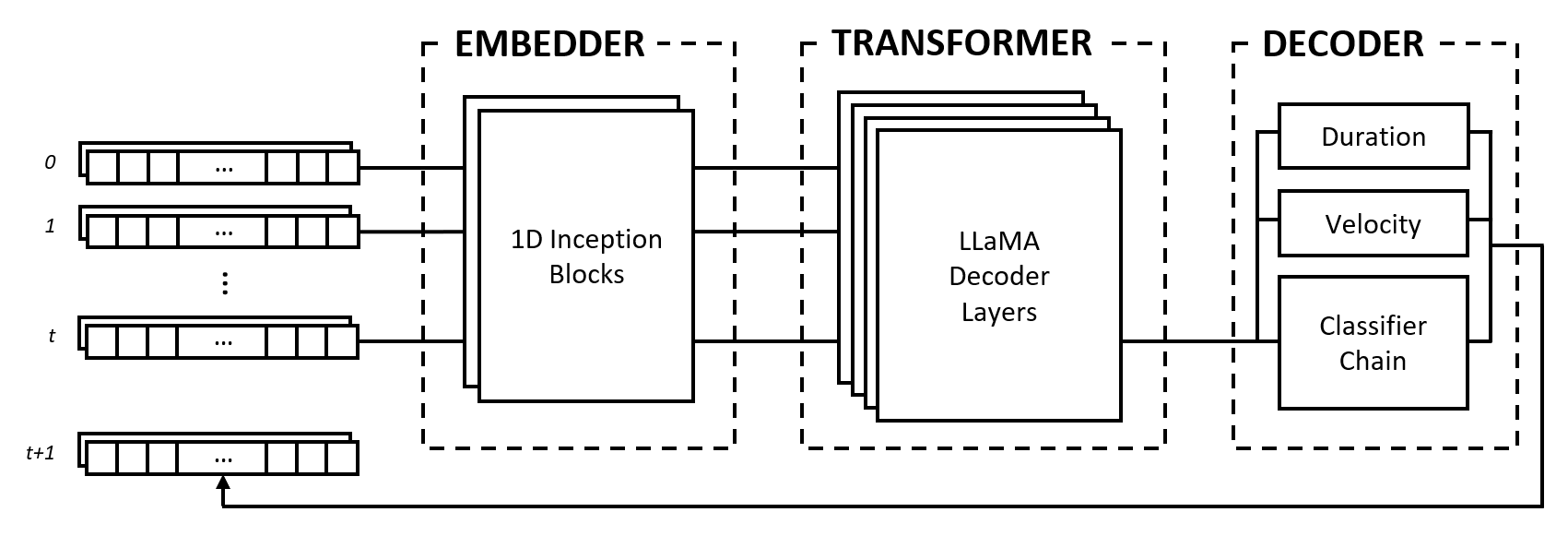
يقوم جهاز التضمين بتحويل كل خطوة زمنية لإدخال الشكل (num_notes, num_features) إلى متجه التضمين الذي يمكن تغذيته في المحول. ومع ذلك، على عكس عمليات تضمين النص التي تقوم بتعيين متجهات ساخنة واحدة إلى مساحة ذات أبعاد أخرى، فإننا نوفر تحيزًا استقرائيًا من خلال تطبيق طبقات تلافيفية ومجمعة على الإدخال. نحن نفعل ذلك لعدة أسباب:
2^num_notes ، حيث يكون num_notes هو 64 أو 88 للبيانو القصير إلى العادي)، لذلك لا يمكن تمثيلها كمتجهات واحدة ساخنة.للسماح للمضمن بمعرفة المسافات المفيدة، فإننا نستلهم من شبكات Inception ونقوم بتجميع مجموعات من أحجام مختلفة للنواة.
تتكون وحدة المحول من طبقات محولات LLaMA التي تطبق الاهتمام الذاتي على تسلسل متجهات تضمين المدخلات.
مثل العديد من نماذج الذكاء الاصطناعي التوليدية، تستخدم هذه الوحدة فقط جزء "وحدة فك التشفير" من نموذج المحولات الأصلي الذي صممه فاسواني وآخرون. (2017). نحن نستخدم تسمية "المحول" هنا لتمييز هذه الوحدة عن الوحدة التالية، والتي تقوم بفك التشفير الفعلي للحالات التي تنتجها طبقات الاهتمام الذاتي.
نحن نختار بنية LLaMA على الأنواع الأخرى من المحولات في المقام الأول لأنها تستخدم التضمين الموضعي الدوار (RoPE)، الذي يشفر المواضع النسبية مع تضاؤل المسافة عبر الخطوات الزمنية. نظرًا لأننا نمثل البيانات الموسيقية على شكل فترات زمنية ثابتة، فإن المواضع النسبية وكذلك المسافات بين الخطوات الزمنية هي أجزاء مهمة من المعلومات التي يمكن للمحول استخدامها بشكل واضح لفهم وتوليد الموسيقى بإيقاع ثابت.
يأخذ جهاز فك التشفير الحالات التي تتم مراقبتها ويتنبأ بالملاحظات التي سيتم تشغيلها مع فتراتها وسرعاتها. تتكون الوحدة من عدة مكونات فرعية، وهي سلسلة تصنيف للتنبؤ بالملاحظات والإدراك الحسي متعدد الطبقات (MLPs) للتنبؤ بالميزات.
تتكون سلسلة المصنفات من مصنفات ثنائية num_notes ، أي مصنف واحد لكل مفتاح على البيانو، لإنشاء مصنف متعدد العلامات. من أجل تعزيز الارتباطات بين الملاحظات، يتم ربط المصنفات الثنائية معًا بحيث تؤثر نتائج الملاحظات السابقة على التنبؤات الخاصة بالملاحظات التالية. على سبيل المثال، إذا كان هناك ارتباط إيجابي بين نغمات الأوكتاف، فإن النغمة السفلية النشطة (مثل C3 ) تؤدي إلى احتمالية أعلى للتنبؤ بالنغمة الأعلى (مثل C4 ). يعد هذا مفيدًا أيضًا في حالات الارتباطات السلبية، حيث يمكن للمرء الاختيار بين ملاحظتين متجاورتين تؤديان إلى مقياس رئيسي أو ثانوي (على سبيل المثال CDE مقابل CD-Eb )، ولكن ليس كليهما.
لتحقيق الكفاءة الحسابية، حددنا طول السلسلة بـ 12 وصلة، أي أوكتاف واحد. وأخيرا، يتم استخدام استراتيجية فك تشفير العينات لاختيار الملاحظات المتعلقة باحتمالات التنبؤ الخاصة بها.
يتم التعامل مع ميزات المدة والسرعة على أنها مشكلات انحدار ويتم التنبؤ بها باستخدام الفانيليا MLPs. في حين يتم التنبؤ بالميزات لكل ملاحظة، فإننا نستخدم وظيفة فقدان مخصصة أثناء التدريب والتي تقوم فقط بتجميع فقدان الميزات من الملاحظات النشطة، على غرار وظيفة الخسارة المستخدمة في تصنيف الصور مع مهمة الترجمة.
إن اختيارنا لتمثيل البيانات الموسيقية كشبكة له مزاياه وعيوبه. نناقش هذه النقاط من خلال مقارنتها بالمفردات المستندة إلى الحدث التي اقترحها Oore et al. (2018)، مساهمة مستشهد بها للغاية في توليد الموسيقى.
واحدة من المزايا الرئيسية لنهجنا هو فصل الفهم الجزئي والكلي للموسيقى، مما يؤدي إلى فصل واضح للواجبات بين المضمن والمحول. يتمثل دور الأول في تفسير تفاعل النوتات الموسيقية على المستوى الجزئي، مثل كيفية تشكيل المسافات النسبية بين النوتات الموسيقية للعلاقات الموسيقية مثل الأوتار، وتتمثل مهمة الأخير في تجميع هذه المعلومات عبر البعد الزمني لفهم الأسلوب الموسيقي على المستوى الكلي. مستوى.
في المقابل، يضع التمثيل القائم على الحدث العبء الكامل على نموذج التسلسل لتفسير الرموز المميزة التي يمكن أن تمثل درجة الصوت أو التوقيت أو السرعة، وهي ثلاثة مفاهيم متميزة. هوانغ وآخرون. (2018) وجدوا أنه من الضروري إضافة آلية اهتمام نسبي إلى نموذج المحول الخاص بهم من أجل توليد استمرارات متماسكة، مما يشير إلى أن النموذج يتطلب انحيازًا استقرائيًا لأداء جيد مع هذا التمثيل.
في تمثيل الشبكة، يعد اختيار طول الفاصل الزمني عبارة عن مقايضة بين دقة البيانات وتناثرها. يؤدي الفاصل الزمني الأطول إلى تقليل دقة توقيت النوتة الموسيقية، مما يقلل من التعبير الموسيقي وربما يضغط على العناصر السريعة مثل الترنيمات والنغمات المتكررة. من ناحية أخرى، يؤدي الفاصل الزمني الأقصر إلى زيادة التناثر بشكل كبير من خلال تقديم الكثير من الخطوات الزمنية الفارغة، وهي مشكلة مهمة بالنسبة لنماذج المحولات لأنها مقيدة بطول التسلسل.
بالإضافة إلى ذلك، يمكن تعيين البيانات الموسيقية إلى شبكة إما عبر مرور الوقت ( 1 timestep == X milliseconds ) أو كما هو مكتوب في النوتة الموسيقية ( 1 timestep == 1 sixteenth note/semiquaver )، ولكل منها مقايضاتها الخاصة . يتجنب التمثيل المستند إلى الحدث هذه المشكلات تمامًا عن طريق تحديد مرور الوقت كحدث.
على الرغم من عيوبه، فإن التمثيل الشبكي يتمتع بميزة عملية حيث أنه من الأسهل العمل به في تطوير pianola . إن مخرجات النموذج قابلة للقراءة من قبل الإنسان ويتوافق عدد الخطوات الزمنية مع مقدار ثابت من الوقت، مما يجعل تطوير الميزات الجديدة أسرع بكثير.
علاوة على ذلك، فإن البحث في تمديد أطوال تسلسل نماذج Transformer والتحسينات المستمرة للأجهزة سيقلل تدريجيًا من المشكلات الناجمة عن تناثر البيانات، واعتبارًا من أواخر عام 2023، نشهد نماذج لغوية كبيرة يمكنها التعامل مع عشرات الآلاف من الرموز المميزة. مع تحسين التقنيات وتسهيل الوصول إلى الأجهزة القوية، نعتقد أن الدقة ستستمر في التحسن، تمامًا كما حدث في توليد الصور، مما يؤدي إلى قدر أكبر من التعبير والفروق الدقيقة في الموسيقى التي يتم إنشاؤها بواسطة الذكاء الاصطناعي.
الكود المصدري لهذا المشروع مرئي للعامة لأغراض البحث الأكاديمي وتبادل المعرفة. يتم الاحتفاظ بجميع الحقوق من قبل المبدع (المبدعين) ما لم يتم منح الأذونات بشكل صريح.
تم تعديل أيقونة الموقع من Freepik - Flaticon.
تواصل معنا على outlook.com على العنوان bruce <dot> ckc .


