nnl
gpt2-xl assets
nnl هو محرك استدلالي للنماذج الكبيرة على منصة GPU ذات الذاكرة المنخفضة.
النماذج الكبيرة كبيرة جدًا بحيث لا يمكن وضعها في ذاكرة وحدة معالجة الرسومات. يعالج nnl هذه المشكلة من خلال المفاضلة بين عرض النطاق الترددي PCIE والذاكرة.
خط أنابيب الاستدلال النموذجي هو كما يلي:
باستخدام تجمع ذاكرة GPU وإلغاء تجزئة الذاكرة، تتيح NNIL إمكانية استنتاج نموذج كبير على منصة GPU منخفضة النهاية.
هذا مجرد مشروع هواية تمت كتابته في بضعة أسابيع، حاليًا يتم دعم الواجهة الخلفية لـ CUDA فقط.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aسيقوم هذا الأمر بإنشاء مكتبتين ثابتتين: lib/lib nnl _cuda.a و lib/lib nnl _cuda_kernels.a . الأولى هي المكتبة الأساسية ذات الواجهة الخلفية لـ CUDA في لغة C++، والثانية مخصصة لنواة CUDA.
يتوفر هنا برنامج تجريبي لـ GPT2-XL (1.6B). يمكن تجميع هذا البرنامج بواسطة هذا الأمر:
make gpt2_1558mبعد تنزيل جميع الأوزان من الإصدار، يمكننا تشغيل الأمر التالي على منصة GPU منخفضة مثل GTX 1050 (ذاكرة 2 جيجابايت):
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " ويكون الإخراج كالتالي: 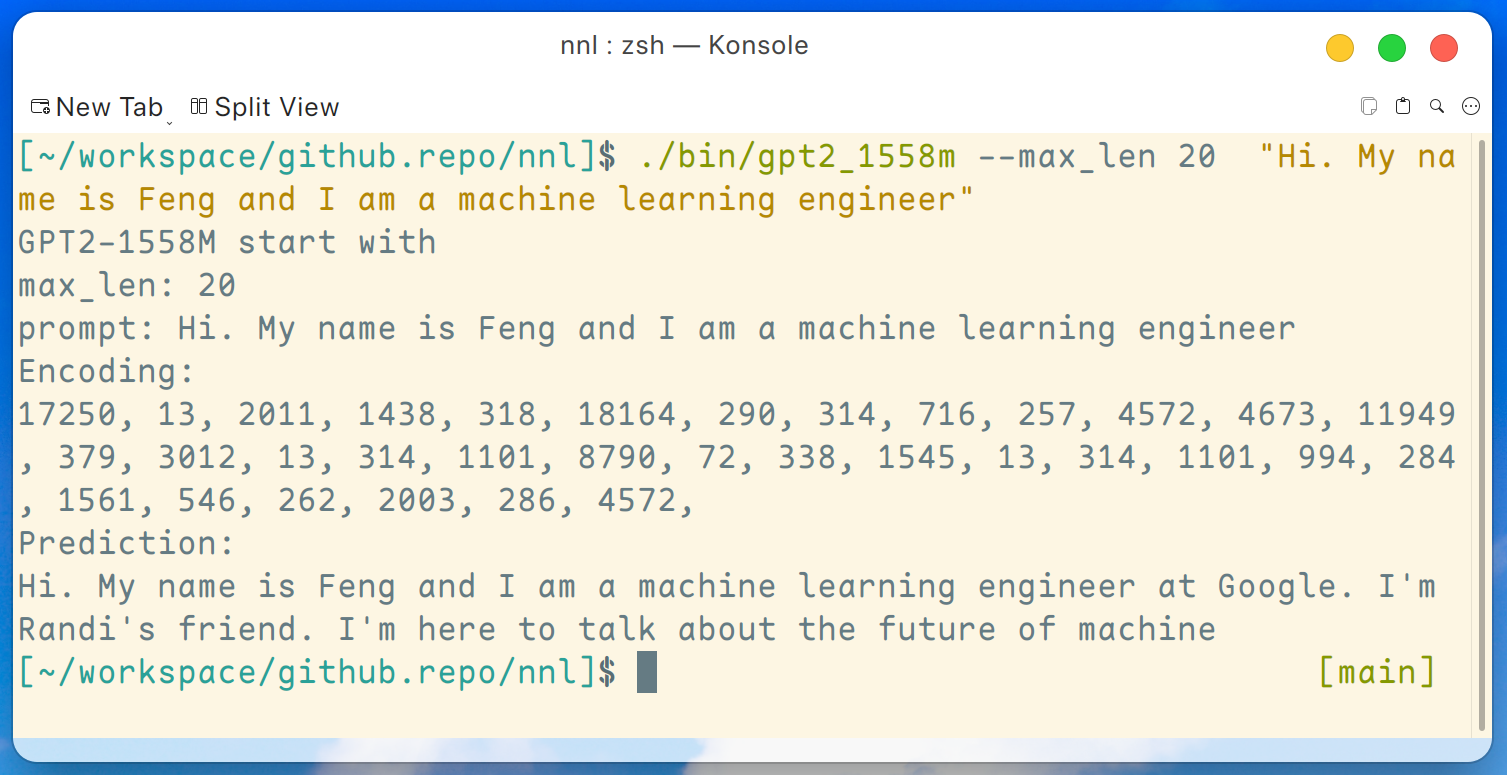
إخلاء المسؤولية: هذا مجرد مثال تم إنشاؤه بواسطة gpt2-xl، وأنا لا أعمل في Google ولا أعرف راندي.
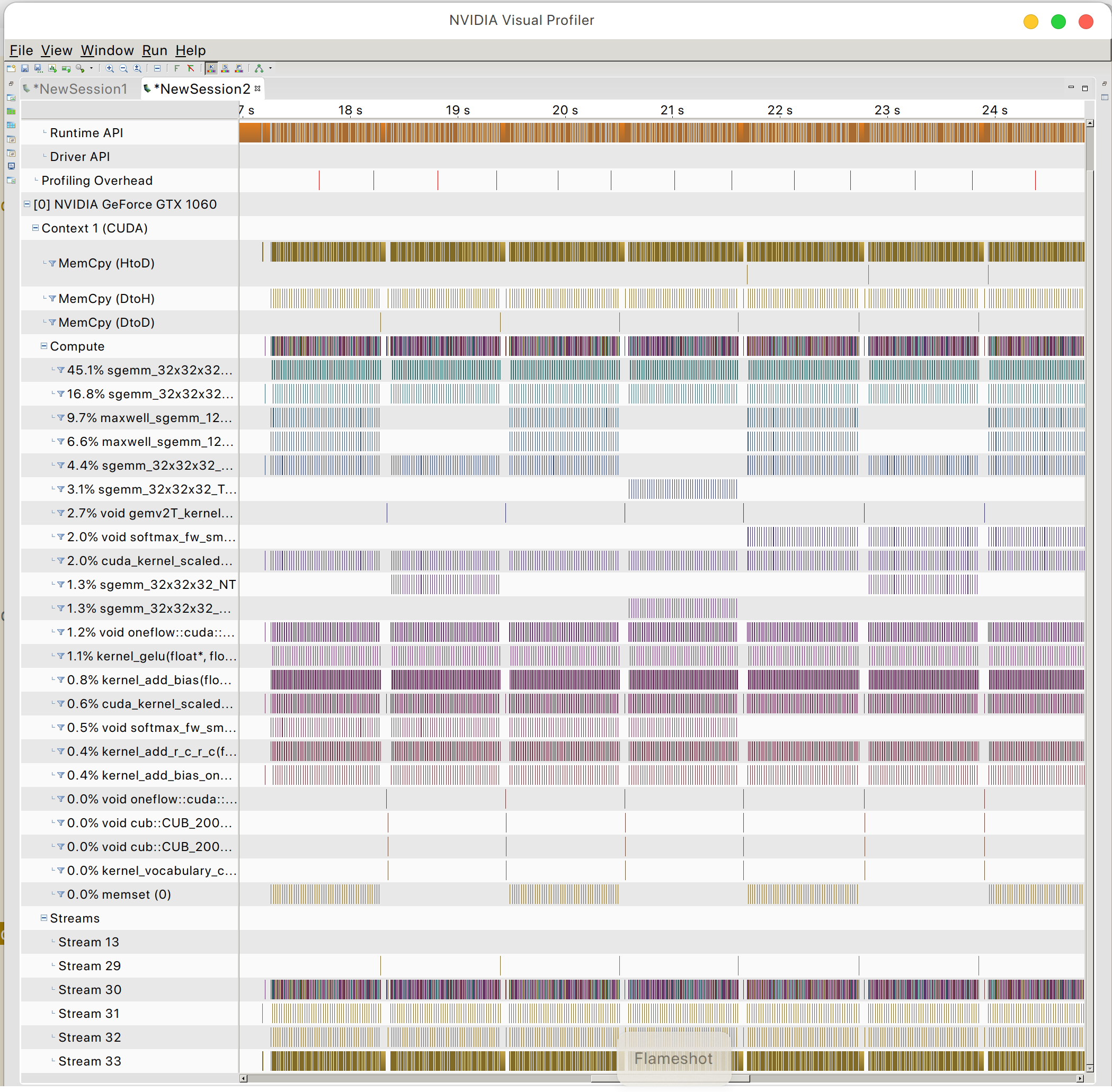
ويمكنك العثور على نمط الوصول إلى ذاكرة GPU
PeaceOSL