DiSQ Score
1.0.0
التنفيذ الرسمي لورقتنا: الأسئلة السقراطية الخطابية: تقييم صدق فهم النماذج اللغوية لعلاقات الخطاب (2024) ييسونغ مياو، هونغفو ليو، وينكيانغ لي، نانسي إف تشين، مين-ين كان.ACL 2024.
ورقة PDF: https://yisong.me/publications/acl24-DiSQ-CR.pdf
الشرائح: https://yisong.me/publications/acl24-DiSQ-Slides.pdf
الملصق: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
هل ترغب في معرفة DiSQ Score لأي نموذج لغة؟ مرحبًا بك في استخدام هذا الأمر المكون من سطر واحد!

نحن نقدم أمرًا مبسطًا لتقييم أي نموذج لغة (LM) تمت استضافته في مركز نماذج HuggingFace. يُنصح باستخدام هذا لأي نموذج جديد (خاصة تلك التي لم تتم دراستها في ورقتنا).
bash scripts/one_model.sh <modelurl>
يحدد المتغير modelurl المسار المختصر في مركز Huggingface، على سبيل المثال،
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
قبل تشغيل ملفات bash، يرجى تحرير ملف bash لتحديد المسار إلى HuggingFace Cache المحلي.
على سبيل المثال، في scripts/one_model.sh:
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
يمكنك تغيير YOUR_PATH إلى موقع الدليل المطلق لذاكرة Huggingface Cache (على سبيل المثال /disk1/yisong/hf-cache ).
نوصي بمساحة خالية تبلغ 200 جيجابايت على الأقل.
سيتم حفظ ملف نصي للإخراج في data/results/verbalizations/Meta-Llama-3-8B.txt ، والذي يحتوي على:
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
نقوم بتخزين مجموعات البيانات الخاصة بنا في ملفات JSON الموجودة في data/datasets/dataset_pdtb.json و data/datasets/dataset_ted.json . على سبيل المثال، لنأخذ مثالًا واحدًا من مجموعة بيانات PDTB:
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
فيما يلي الحقول الموجودة في إدخال القاموس هذا:
Didx : معرف الخطاب.arg1 و arg2 : الوسيطتان.DR : علاقة الخطاب.Conn : الخطاب الضام.events : قائمة بالأزواج، تخزن أزواج الأحداث المتوقعة كإشارات بارزة.context : سياق الخطاب. cd DiSQ-Score
bash scripts/question_generation.sh
سوف يستدعي ملف bash هذا question_generation.py لإنشاء أسئلة ضمن تكوينات مختلفة.
وسيطات question_generation.py هي كما يلي:
--dataset : يحدد مجموعة البيانات، إما pdtb أو ted .--modelname : تم إنشاء أسماء مستعارة للنماذج. يشير 13b إلى LLaMA2-13B، 13bchat إلى LLaMA2-13B-Chat، و vicuna-13b إلى Vicuna-13B. يمكن العثور على عناوين URL المحددة لهذه النماذج في disq_config.py .--version : يحدد إصدار قوالب المطالبة المطلوب استخدامه، مع الخيارات v1 و v2 و v3 و v4 .--paraphrase : يستبدل الأسئلة القياسية بنسختها المعاد صياغتها، مع الخيارين p1 و p2 . على عكس الدوال القياسية التي تستدعي qa_utils.py ، فإن الدوال المعاد صياغتها تستدعي qa_utils_p1.py و qa_utils_p2.py على التوالي.--feature : يحدد الميزات اللغوية التي سيتم استخدامها في أسئلة المناقشة. تشمل السمات اللغوية conn (الخطاب الضام)، context (سياق الخطاب). تتطلب بيانات ضمان الجودة التاريخية وجود برنامج نصي منفصل. سيتم تخزين المخرجات، على سبيل المثال، data/questions/dataset_pdtb_prompt_v1.json ضمن dataset==pdtb و version==v1 .
نطلب من مستخدمينا إنشاء الأسئلة بأنفسهم لأن هذا الأسلوب تلقائي ويساعد في توفير المساحة في مستودع GitHub الخاص بنا (والذي قد يصل إلى 200 ميجابايت تقريبًا). إذا لم تتمكن من تشغيل ملف bash، يرجى الاتصال بنا للحصول على ملفات الأسئلة.
cd DiSQ-Score
bash scripts/question_answering.sh
سيستدعي ملف bash هذا question_answering.py لإجراء الأسئلة الخطابية السقراطية (DiSQ) لأي نموذج محدد. يأخذ question_answering.py جميع الوسيطات من question_generation.py ، بالإضافة إلى الوسيطات الجديدة التالية:
--modelurl : يحدد عنوان URL لأي نماذج جديدة غير موجودة حاليًا في ملف التكوين. على سبيل المثال، يحدد "meta-llama/Meta-Llama-3-8B" نموذج LLaMA3-8B وسيحل محل وسيطة modelname .--hf-path : يحدد المسار لتخزين معلمات النموذج الكبيرة. يوصى بمساحة خالية على القرص تبلغ 200 جيجابايت على الأقل.--device_number : يحدد معرف وحدة معالجة الرسومات المراد استخدامها. سيتم تخزين المخرجات، على سبيل المثال، data/results/13bchat_dataset_pdtb_prompt_v1/ . التنبؤ لكل سؤال عبارة عن قائمة من الرموز المميزة واحتمالاتها، المخزنة في ملف مخلل داخل المجلد.
تحذير: تمت إزالة نموذج المعالج من قبل المطورين. ننصح المستخدمين بعدم تجربة هذه النماذج. تحقق من موضوع المناقشة على: https://huggingface.co/posts/WizardLM/329547800484476.
cd DiSQ-Score
bash scripts/eval.sh
سوف يستدعي ملف bash هذا eval.py لتقييم تنبؤات النموذج التي تم الحصول عليها مسبقًا.
يأخذ eval.py نفس مجموعة المعلمات التي يستخدمها question_answering.py .
سيتم تخزين نتيجة التقييم في disq_score_pdtb.csv إذا كانت مجموعة البيانات المحددة هي PDTB.
يوجد 20 عمودًا في ملف CSV، وهي:
taskcode : يشير إلى التكوين الذي يتم اختباره، على سبيل المثال، dataset_pdtb_prompt_v1_13bchat .modelname : يحدد نموذج اللغة الذي يتم اختباره.version : يشير إلى إصدار المطالبة.paraphrase : المعلمة لإعادة الصياغة.feature : تحدد الميزة التي تم استخدامها.Overall : مجموع DiSQ Score .Targeted : النتيجة المستهدفة، أحد المكونات الثلاثة في DiSQ Score .Counterfactual : النتيجة المغايرة للواقع، وهي أحد المكونات الثلاثة في DiSQ Score .Consistency : درجة الاتساق، أحد المكونات الثلاثة في DiSQ Score .Comparison.Concession : DiSQ Score لعلاقة الخطاب المحددة هذه.لاحظ أننا نختار أفضل النتائج بين الإصدارات v1 إلى v4 لتهميش تأثير قوالب المطالبة.
للقيام بذلك، يستخرج eval.py أفضل النتائج تلقائيًا:
| رمز المهمة | اسم الموديل | إصدار | إعادة صياغة | ميزة | إجمالي | مستهدفة | واقعي | تناسق | المقارنة.الامتياز | المقارنة.التباين | الطوارئ.السبب | الطوارئ.النتيجة | توسيع.الاتصال | التوسع. التكافؤ | التوسعة | التوسعة. مستوى التفاصيل | توسيع.استبدال | مؤقت.غير متزامن | مؤقت.متزامن |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_pdtb_prompt_v4_7b | 7 ب | v4 | 0.074 | 0.956 | 0.084 | 0.929 | 0.03 | 0.083 | 0.095 | 0.095 | 0.077 | 0.054 | 0.086 | 0.068 | 0.155 | 0.036 | 0.047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7bchat | الإصدار 1 | 0.174 | 0.794 | 0.271 | 0.811 | 0.231 | 0.435 | 0.132 | 0.173 | 0.214 | 0.105 | 0.121 | 0.15 | 0.199 | 0.107 | 0.04 | ||
| dataset_pdtb_prompt_v2_13b | 13 ب | الإصدار 2 | 0.097 | 0.945 | 0.112 | 0.912 | 0.037 | 0.099 | 0.081 | 0.094 | 0.126 | 0.101 | 0.113 | 0.107 | 0.077 | 0.083 | 0.093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13bchat | الإصدار 1 | 0.253 | 0.592 | 0.545 | 0.785 | 0.195 | 0.485 | 0.129 | 0.173 | 0.289 | 0.155 | 0.326 | 0.373 | 0.285 | 0.194 | 0.028 | ||
| dataset_pdtb_prompt_v2_vicuna-13b | فيكونا-13ب | الإصدار 2 | 0.325 | 0.512 | 0.766 | 0.829 | 0.087 | 0.515 | 0.201 | 0.352 | 0.369 | 0.0 | 0.334 | 0.46 | 0.199 | 0.511 | 0.074 |
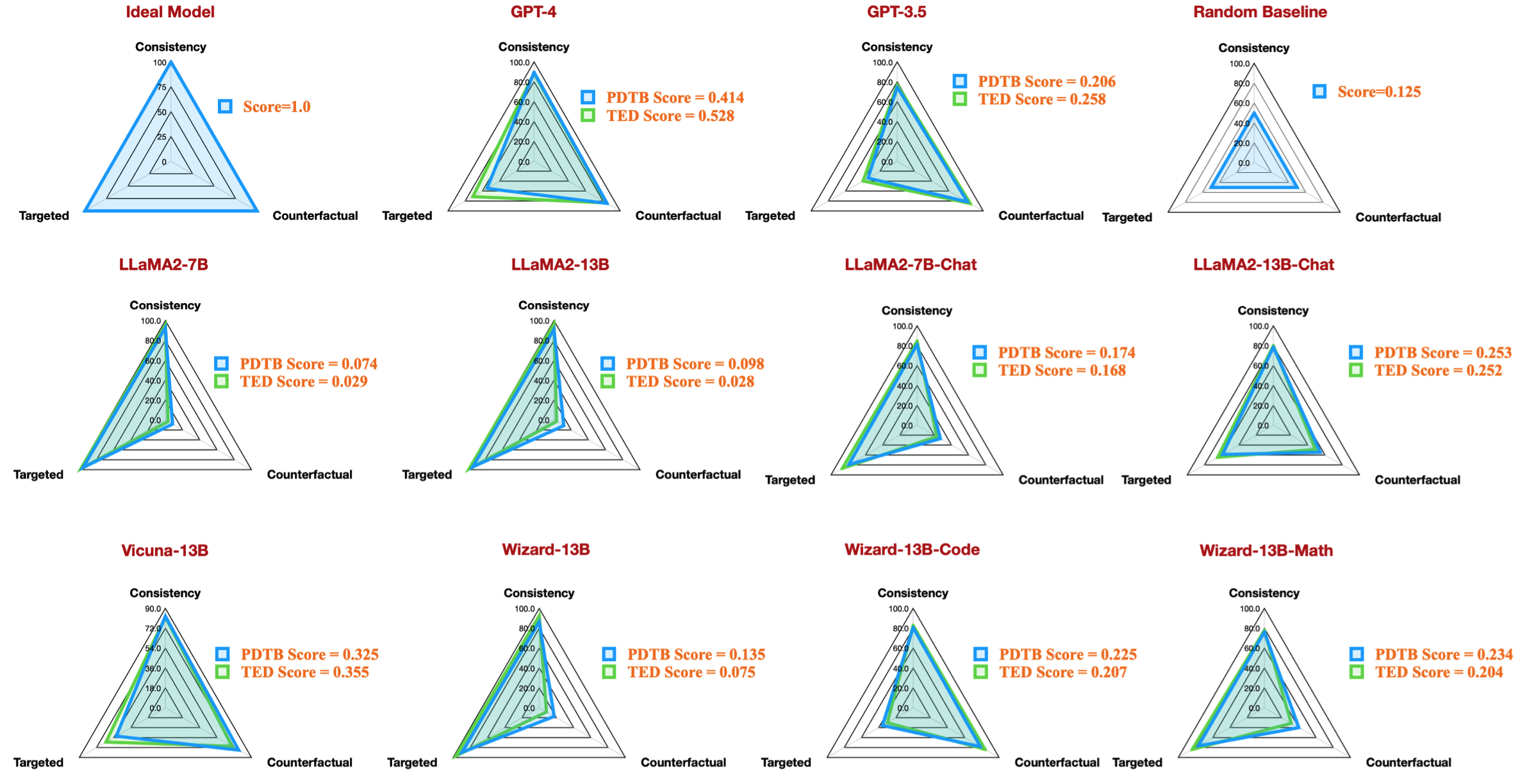
على سبيل المثال، يوضح هذا الجدول أفضل نتيجة لمجموعات بيانات PDTB للنماذج المتاحة مفتوحة المصدر، والتي تعيد إنتاج شكل الرادار في ورقتنا:
ونقدم أيضًا تعليمات لتقييم أسئلة المناقشة حول السمات اللغوية:
--feature كـ conn context في question_generation.py (الخطوة 1) وأعد تشغيل جميع التجارب.question_generation_history.py . سيقوم هذا البرنامج النصي باستخراج الإجابات من نتائج ضمان الجودة المخزنة وإنشاء أسئلة جديدة.بالنسبة لمعظم مستخدمي NLP، ربما ستتمكن من تشغيل التعليمات البرمجية الخاصة بنا مع البيئات الافتراضية (conda) الموجودة لديك.
عندما أجرينا تجاربنا، كانت إصدارات الحزمة على النحو التالي:
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
ومع ذلك، لاحظنا أن الموديلات الأحدث تتطلب إصدارات حزمة مطورة:
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
إذا وجدت عملنا مثيرًا للاهتمام، فنحن نرحب بك كثيرًا لتجربة مجموعة البيانات/قاعدة البيانات الخاصة بنا.
يرجى التكرم بالاستشهاد بأبحاثنا إذا كنت قد استخدمت مجموعة البيانات/قاعدة البيانات الخاصة بنا:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
إذا كانت لديك أسئلة أو تقارير أخطاء، يرجى إثارة مشكلة أو الاتصال بنا مباشرة عبر البريد الإلكتروني:
عنوان البريد الإلكتروني: ؟@؟
أين ?️= yisong , ?= comp.nus.edu.sg
CC بواسطة 4.0


