Patron
1.0.0
يحتوي هذا الريبو على الكود الخاص باختيار بيانات البدء البارد لورق ACL 2023 من أجل الضبط الدقيق لنموذج اللغة قليل اللقطة: نهج نشر عدم اليقين القائم على السرعة.
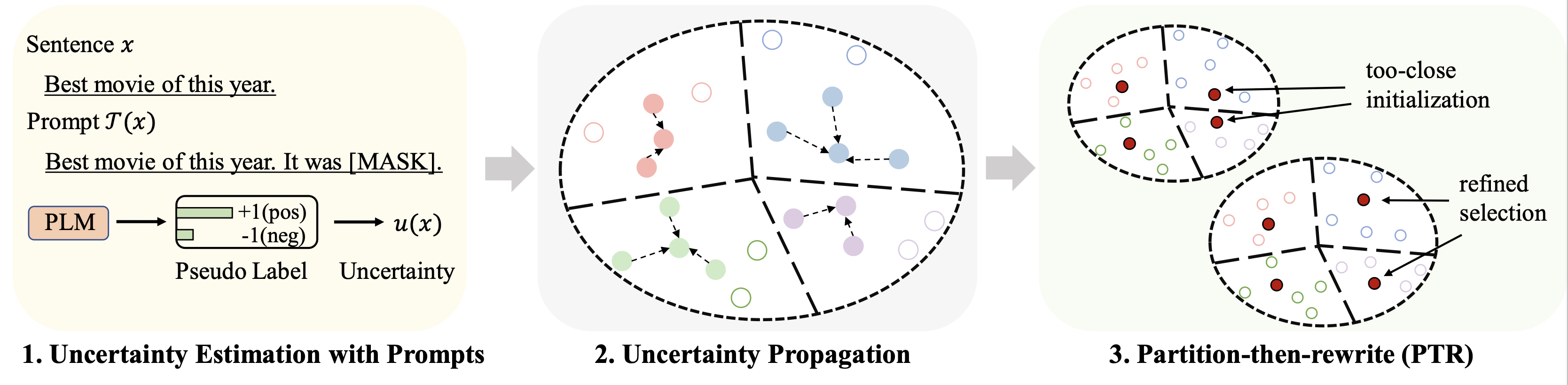
يتم تلخيص النتائج الخاصة بمجموعات البيانات المختلفة (باستخدام 128 تصنيفًا كميزانية) للضبط الدقيق على النحو التالي:
| طريقة | موقع آي إم دي بي | الصرخة كاملة | أخبار | ياهو! | DBedia | تريك | يقصد |
|---|---|---|---|---|---|---|---|
| الإشراف الكامل (قاعدة RoBERTa) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| أخذ العينات العشوائية | 86.6 | 47.7 | 84.5 | 60.2 | 95.0 | 85.6 | 76.7 |
| أفضل خط أساس (تشانغ وآخرون 2021) | 88.5 | 46.4 | 85.6 | 61.3 | 96.5 | 87.7 | 77.6 |
| Patron (لنا) | 89.6 | 51.2 | 87.0 | 65.1 | 97.0 | 91.1 | 80.2 |
للتعلم الفوري، نستخدم نفس المسار الذي يستخدمه LM-BFF. وتظهر النتيجة مع 128 تسمية على النحو التالي.
| طريقة | موقع آي إم دي بي | الصرخة كاملة | أخبار | ياهو! | DBedia | تريك | يقصد |
|---|---|---|---|---|---|---|---|
| الإشراف الكامل (قاعدة RoBERTa) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| أخذ العينات العشوائية | 87.7 | 51.3 | 84.9 | 64.7 | 96.0 | 85.0 | 78.2 |
| أفضل خط أساس (يوان وآخرون، 2020) | 88.9 | 51.7 | 87.5 | 65.9 | 96.8 | 86.5 | 79.5 |
| Patron (لنا) | 89.3 | 55.6 | 87.8 | 67.6 | 97.4 | 88.9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
نحن نستخدم مجموعات البيانات الأربع التالية للتجارب الرئيسية.
| مجموعة البيانات | مهمة | عدد الفصول | عدد البيانات غير المسماة/بيانات الاختبار |
|---|---|---|---|
| موقع آي إم دي بي | المشاعر | 2 | 25 ألف/25 ألف |
| الصرخة كاملة | المشاعر | 5 | 39 ألف / 10 ألف |
| ايه جي نيوز | موضوع الأخبار | 4 | 119 ألف / 7.6 ألف |
| ياهو! الإجابات | موضوع ضمان الجودة | 5 | 180 ك/30.1 ك |
| DBedia | موضوع الأنطولوجيا | 14 | 280 ألف/70 ألف |
| تريك | موضوع السؤال | 6 | 5 كيلو/0.5 كيلو |
يمكن العثور على البيانات المعالجة على هذا الرابط. سيتم شرح المجلد الذي سيتم وضع مجموعات البيانات فيه في الأجزاء التالية.
قم بتشغيل الأوامر التالية
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
نحن نقدم التنبؤ الزائف الذي تم الحصول عليه عبر المطالبات الموجودة في الرابط أعلاه لمجموعات البيانات. يرجى الرجوع إلى الأوراق الأصلية للحصول على التفاصيل.
قم بتشغيل الأوامر التالية (مثال على مجموعة بيانات AG News)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
بعض المعلمات الفائقة الهامة:
rho : المعلمة المستخدمة لانتشار عدم اليقين في المعادلة. 6 من الورقbeta : تنظيم المسافة في المعادلة. 8 من الورقةgamma : وزن مصطلح التنظيم في المعادلة. 10 من الورقة راجع مجلد finetune للحصول على تعليمات مفصلة.
راجع مجلد prompt_learning للحصول على تعليمات مفصلة.
انظر إلى هذا الارتباط باعتباره خط الأنابيب لإنشاء التنبؤات المستندة إلى السرعة. لاحظ أنك بحاجة إلى تخصيص نماذج اللفظ والقوالب السريعة.
لإنشاء تضمينات المستند، يمكنك اتباع الأوامر المذكورة أعلاه باستخدام SimCSE.
بمجرد إنشاء فهرس للبيانات المحددة، يمكنك استخدام المسارات في Running Fine-tuning Experiments Running Prompt-based Learning Experiments لتجارب الضبط الدقيق والمرتكزة على الموجه.
يرجى التكرم بالإشارة إلى الورقة التالية إذا وجدت هذا الريبو مفيدًا لبحثك. شكرا مقدما!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
نود أن نشكر المؤلفين من repo SimCSE وOpenPrompt على الكود المنظم جيدًا.


