CTCWordBeamSearch
1.0.0
وحدة فك ترميز التصنيف الزمني الاتصالي (CTC) مع القاموس ونموذج اللغة (LM).
pip install .tests/ وقم بتنفيذ pytest للتحقق من نجاح التثبيت يوضح مثال اللعبة التالي كيفية استخدام البحث بشعاع الكلمات. النموذج الافتراضي (على سبيل المثال، نموذج التعرف على النص) قادر على التعرف على 3 أحرف مختلفة: "a" و"b" و"" (مسافة بيضاء). يمكن أن تحتوي الكلمات الموجودة في مثال اللعبة هذا على الأحرف "a" و"b" (ولكن ليس " " وهو فاصل الكلمات). يتم تدريب النموذج اللغوي من مجموعة نصية تحتوي على كلمتين فقط: "a" و"ba".
في مقتطف التعليمات البرمجية هذا، يتم إنشاء مثيل للبحث في حزمة الكلمات، ويتم فك تشفير مصفوفة numpy على شكل TxBx(C+1):
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )تقوم وحدة فك الترميز بإرجاع قائمة تحتوي على سلسلة تسميات تم فك تشفيرها لكل عنصر دفعة. للحصول على سلاسل الأحرف أخيرًا، قم بتعيين كل تسمية إلى الحرف المقابل لها:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )أمثلة:
tests/test_word_beam_search.py معلمات مُنشئ فئة WordBeamSearch :
0<len(wordChars)<len(chars) . في حالة الحاجة إلى اكتشاف كلمات مفردة فقط، ليست هناك حاجة إلى حرف فاصل، وبالتالي قد تكون المعلمتان متساويتين أيضًا: 0<len(wordChars)<=len(chars) الإدخال إلى أسلوب WordBeamSearch.compute :
البحث عن شعاع الكلمات هو خوارزمية فك تشفير CTC. يتم استخدامه لمهام التعرف على التسلسل مثل التعرف على النص المكتوب بخط اليد أو التعرف التلقائي على الكلام.
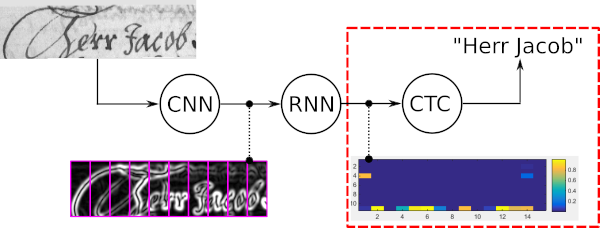
الخصائص الأربع الرئيسية للبحث بشعاع الكلمات هي:
يوضح النموذج التالي حالة استخدام نموذجية للبحث في حزمة الكلمات بالإضافة إلى النتائج المقدمة من خمسة أجهزة فك تشفير مختلفة. أفضل فك تشفير المسار والبحث عن شعاع الفانيليا يخطئان في الكلمات لأن أجهزة فك التشفير هذه تستخدم فقط الإخراج الصاخب للنموذج البصري. يؤدي توسيع البحث عن شعاع الفانيليا بواسطة LM على مستوى الحرف إلى تحسين النتيجة من خلال السماح فقط بتسلسلات الأحرف المحتملة. يستخدم تمرير الرمز المميز قاموسًا وLM على مستوى الكلمة، وبالتالي يحصل على كل الكلمات بشكل صحيح. ومع ذلك، فهو غير قادر على التعرف على سلاسل الأحرف العشوائية مثل الأرقام. يستطيع البحث في شعاع الكلمات التعرف على الكلمات باستخدام القاموس، ولكنه قادر أيضًا على التعرف بشكل صحيح على الأحرف غير الكلمة.

مزيد من المعلومات:
extras/prototype/extras/tf/ يرجى الاستشهاد بالمقالة التالية إذا كنت تستخدم البحث بشعاع الكلمات في عملك البحثي.
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


