Grounding_LLMs_with_online_RL
1.0.0
يحتوي هذا المستودع على الكود المستخدم في ورقتنا التي ترتكز على نماذج اللغة الكبيرة مع التعلم المعزز عبر الإنترنت.
يمكنك العثور على مزيد من المعلومات على موقعنا.
نقوم بتنفيذ أسس وظيفية لمعرفة LLMs في BabyAI-Text باستخدام طريقة GLAM : 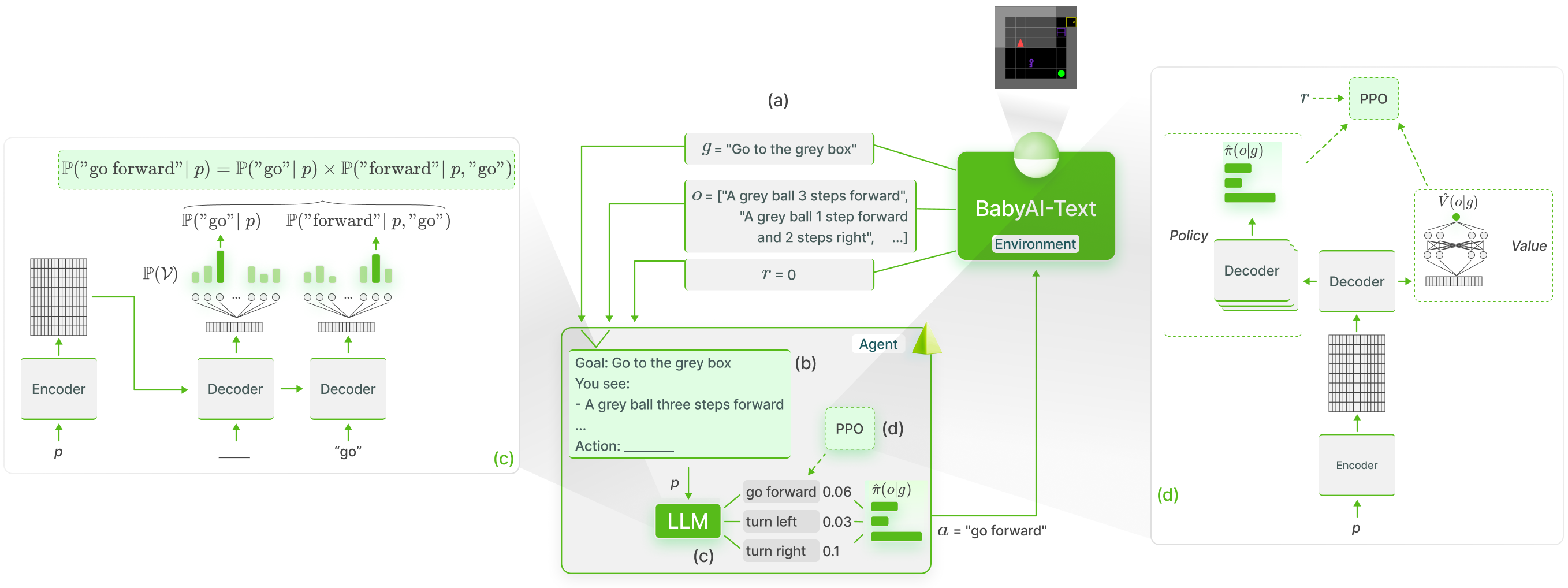
قمنا بإصدار بيئة BabyAI-Text الخاصة بنا جنبًا إلى جنب مع التعليمات البرمجية لإجراء تجاربنا (سواء تدريب الوكلاء أو تقييم أدائهم). نحن نعتمد على مكتبة Lamorel لاستخدام LLMs.
يتم تنظيم مستودعنا على النحو التالي:
؟ Grounding_LLMs_with_online_RL
┣ babyai-text - بيئة BabyAI-Text الخاصة بنا
┣ experiments - رمز تجاربنا
┃ ┣ agents - تنفيذ جميع وكلائنا
┃ ┃ ┣ bot - وكيل الروبوت الذي يستفيد من روبوت BabyAI
┃ ┃ ┣ random_agent - العميل يلعب بشكل عشوائي بشكل موحد
┃ ┃ ┣ drrn -- وكيل DRRN من هنا
┃ ┃ ┣ ppo - الوكلاء الذين يستخدمون PPO
┃ ┃ ┃ ┣ symbolic_ppo_agent.py -- رمزي PPO مقتبس من PPO الخاص بـ BabyAI
┃ ┃ ┃ ┗ llm_ppo_agent.py - تم إيقاف وكيل LLM الخاص بنا باستخدام PPO
┃ ┣ configs - تكوينات لاموريل لتجاربنا
┃ ┣ slurm - يستخدم البرامج النصية لبدء تجاربنا على مجموعة SLURM
┃ ┣ campaign - نصوص SLURM المستخدمة لإطلاق تجاربنا
┃ ┣ train_language_agent.py -- تدريب الوكلاء الذين يستخدمون BabyAI-Text (LLMs وDRRN) -> يحتوي على تنفيذنا لخسارة PPO لمجالات LLM بالإضافة إلى رؤوس إضافية فوق LLMs
┃ ┣ train_symbolic_ppo.py - تدريب SympicPPO على BabyAI (مع مهام BabyAI-Text)
┃ ┣ post-training_tests.py - اختبارات التعميم للوكلاء المدربين
┃ ┣ test_results.py -- أدوات لتنسيق النتائج
┃ ┗ clm_behavioral-cloning.py - رمز لإجراء الاستنساخ السلوكي على LLM باستخدام المسارات
conda create -n dlp python=3.10.8; conda activate dlp
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
تثبيت BabyAI-Text : راجع تفاصيل التثبيت في حزمة babyai-text
قم بتثبيت لاموريل
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
الرجاء استخدام Lamorel مع التكوينات الخاصة بنا. يمكنك العثور على أمثلة لنصوصنا التدريبية في الحملة.
لتدريب نموذج لغة على بيئة BabyAI-Text، يجب على المرء استخدام ملف train_language_agent.py . يستخدم هذا البرنامج النصي (الذي تم تشغيله باستخدام Lamorel) إدخالات التكوين التالية:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
num_steps : 1000 # Total number of training steps
max_episode_steps : 3 # Maximum number of steps in a single episode
frames_per_proc : 40 # The number of collected transitions to perform a PPO update will be frames_per_proc*number_envs
discount : 0.99 # Discount factor used in PPO
lr : 1e-6 # Learning rate used to finetune the LLM
beta1 : 0.9 # PPO's hyperparameter
beta2 : 0.999 # PPO's hyperparameter
gae_lambda : 0.99 # PPO's hyperparameter
entropy_coef : 0.01 # PPO's hyperparameter
value_loss_coef : 0.5 # PPO's hyperparameter
max_grad_norm : 0.5 # Maximum grad norm when updating the LLM's parameters
adam_eps : 1e-5 # Adam's hyperparameter
clip_eps : 0.2 # Epsilon used in PPO's losses clipping
epochs : 4 # Number of PPO epochs performed on each set of collected trajectories
batch_size : 16 # Minibatch size
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
template_test : 1 # Which prompt template to use to log evolution of action's probability (Section C of our paper). Choices or [1, 2].
nbr_obs : 3 # Number of past observation used in the promptللحصول على إدخالات التكوين المتعلقة بنموذج اللغة نفسه، يرجى مراجعة Lamorel.
لتقييم أداء الوكيل (على سبيل المثال، LLM مدرب، وروبوت BabyAI...) في مهام الاختبار، استخدم post-training_tests.py وقم بتعيين إدخالات التكوين التالية:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
max_episode_steps : 3 # Maximum number of steps in a single episode
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
nbr_obs : 3 # Number of past observation used in the prompt
number_episodes : 10 # Number of test episodes
language : ' english ' # Useful to perform the French experiment (Section H4)
zero_shot : true # Whether the zero-shot LLM (i.e. without finetuning should be used)
modified_action_space : false # Whether a modified action space (e.g. different from the one seen during training) should be used
new_action_space : # ["rotate_left","rotate_right","move_ahead","take","release","switch"] # Modified action space
im_learning : false # Whether a LLM produced with Behavioral Cloning should be used
im_path : " " # Path to the LLM learned with Behavioral Cloning
bot : false # Whether the BabyAI's bot agent should be used

