الألبكة-rlhf
ضبط LLaMA باستخدام RLHF (التعلم المعزز بالملاحظات البشرية).
العرض التوضيحي عبر الإنترنت
تعديلات على DeepSpeed Chat
الخطوة 1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- تدرب فقط على الردود وأضف eos
- إزالة end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
- التسميات تختلف عن المدخلات
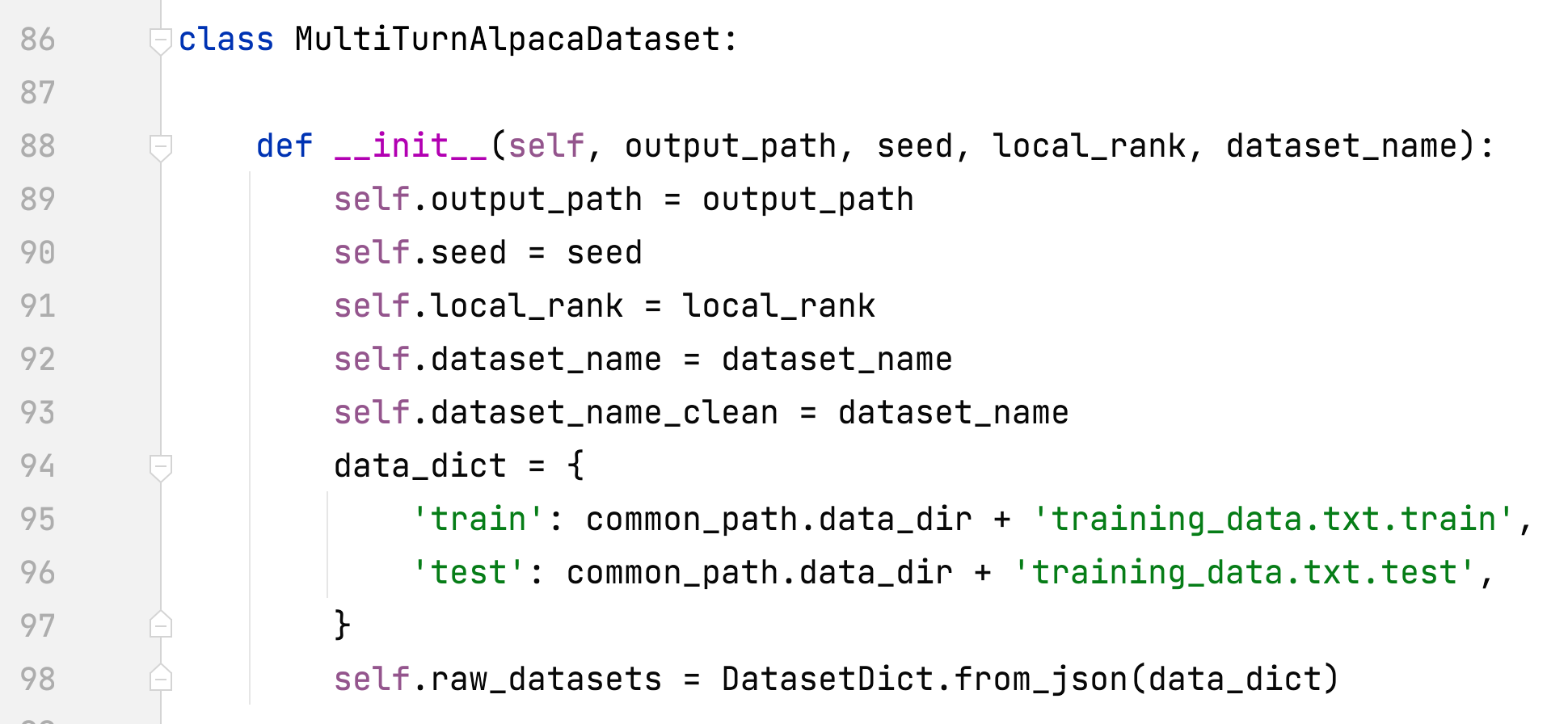
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- إضافة MultiTurnAlpacaDataset
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
- دعم أسماء وحدات متعددة لورا
الخطوة 2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- alpca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- إصلاح عدم الاستقرار العددي
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- إزالة end_of_conversation_token
الخطوة 3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- إصلاح الخلل في الحد الأقصى للطول
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# call
- إصلاح الخلل الجانبي للحشوة
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOtrainer#_generate_sequence
- قم بإخفاء الرموز المميزة بعد eos
ستي بخطوة
- تشغيل جميع الخطوات الثلاث على 2 x A100 80G
- مجموعات البيانات
- ورقة Dahoas/rm-static تعانق الوجه GitHub
- MultiTurnAlpaca
- هذه نسخة متعددة المنعطفات من مجموعة بيانات الألبكة وهي مبنية على AlpacaDataCleaned وChatAlpaca.
- أدخل الدليل ./alpaca_rlhf أولاً، ثم قم بتشغيل الأوامر التالية:
- الخطوة 1: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- عند إضافة --sft_only_data_path MultiTurnAlpaca، يرجى فك ضغط data/data.zip أولاً.
- الخطوة 2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -HF --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
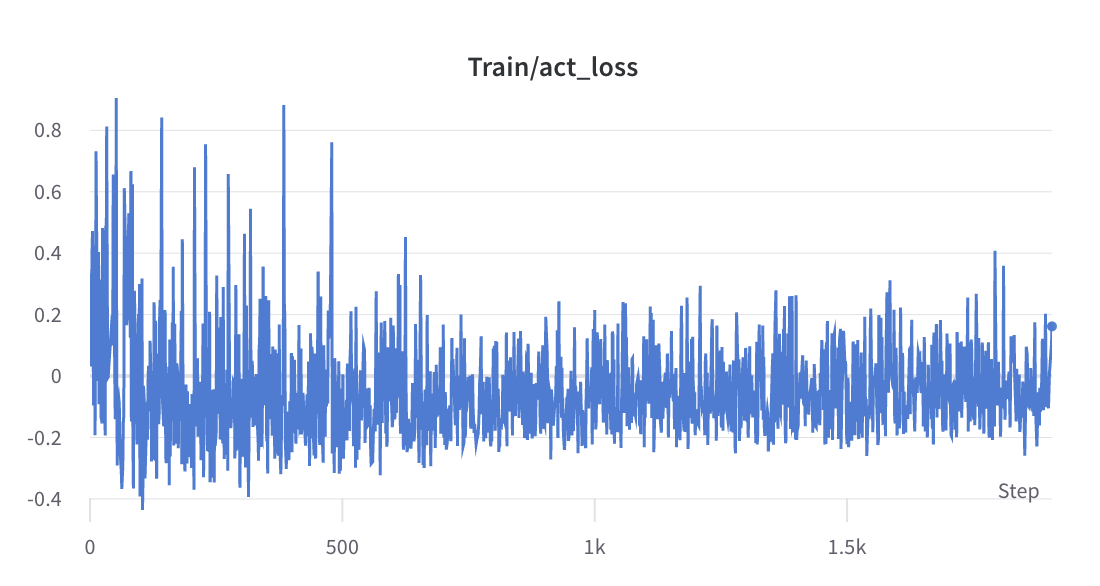
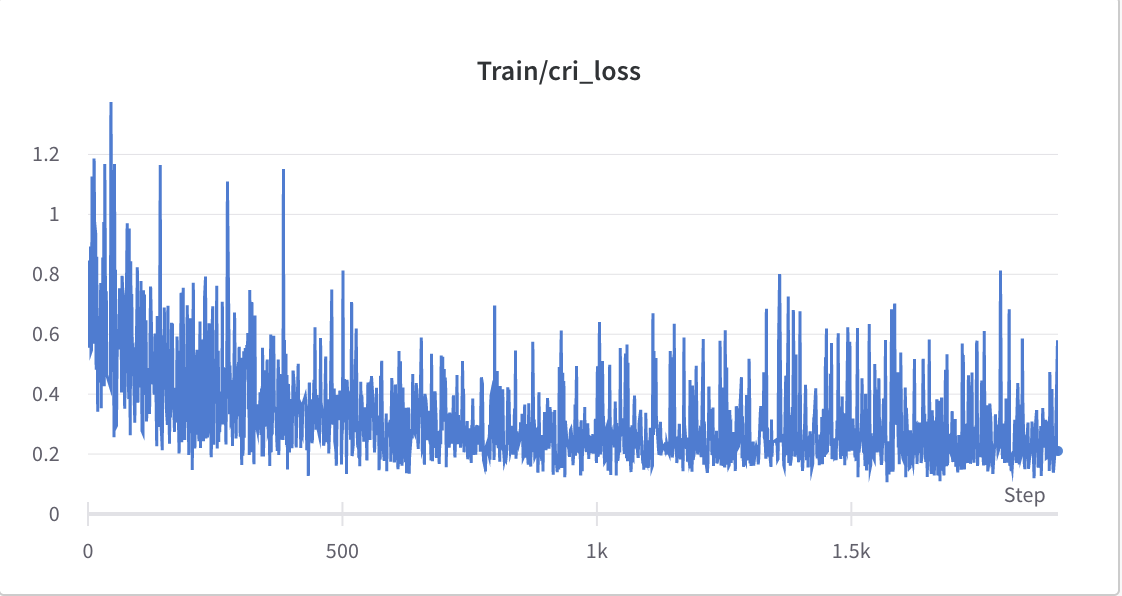
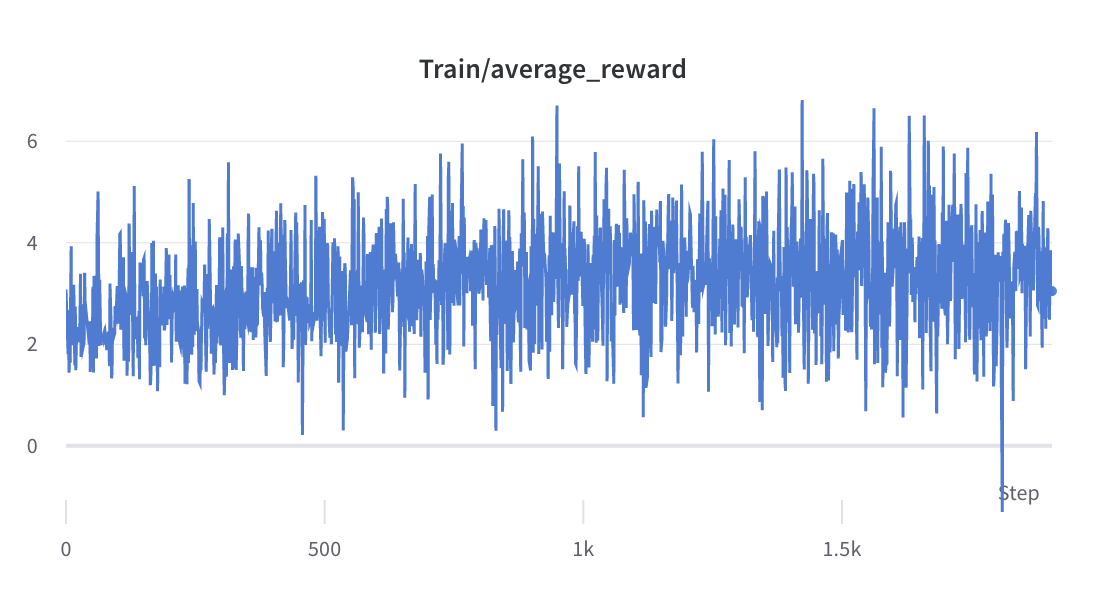
- عملية التدريب من الخطوة 2
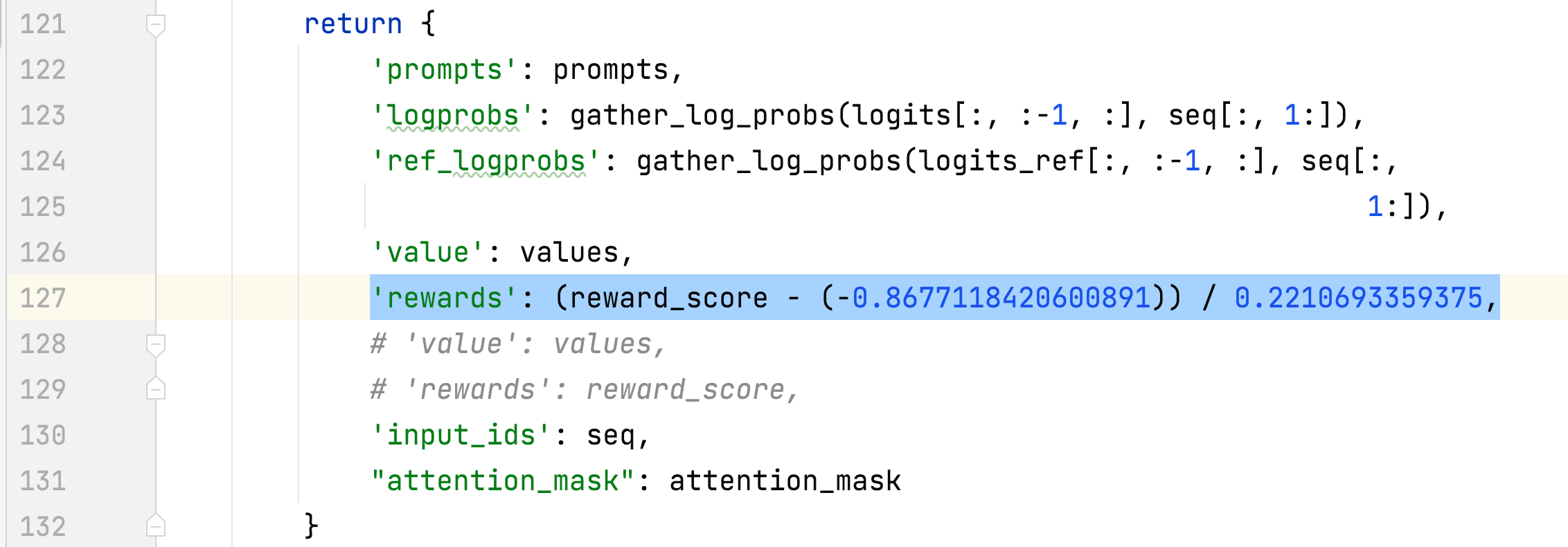
- يتم جمع المتوسط والانحراف المعياري لمكافأة الاستجابات المختارة واستخدامهما لتطبيع المكافأة في الخطوة 3. وفي إحدى التجارب، يكونان -0.8677118420600891 و0.2210693359375 على التوالي ويتم استخدامهما في alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOtrainer#generate_experience أساليب: 'rewards': (reward_score - (-0.8677118420600891)) / 0.2210693359375.
- الخطوة 3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/الممثل/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
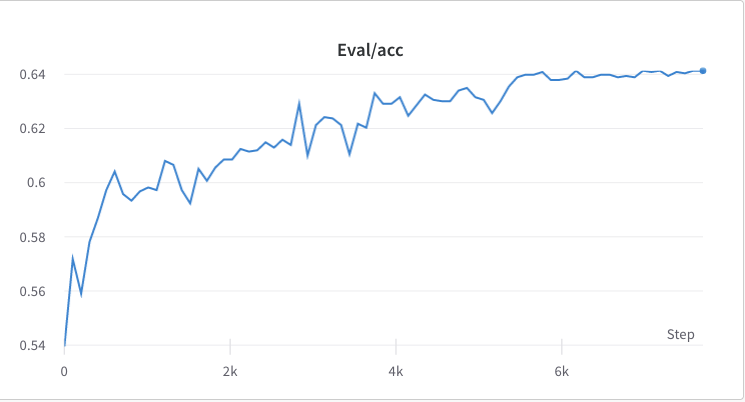
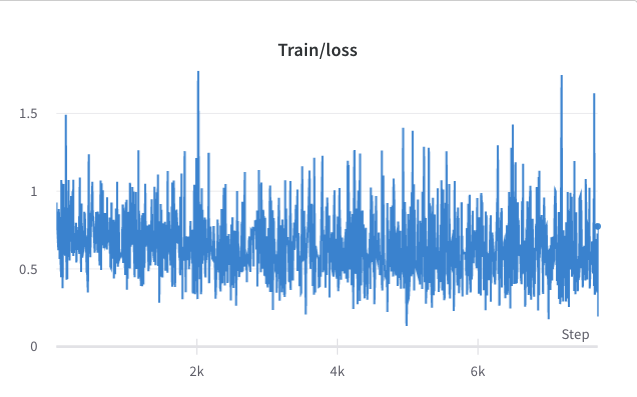
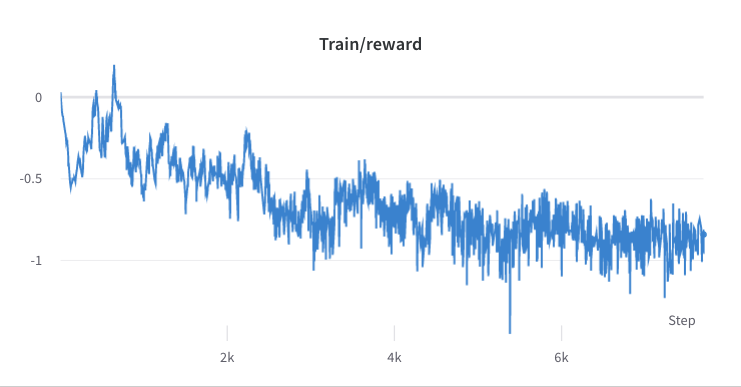
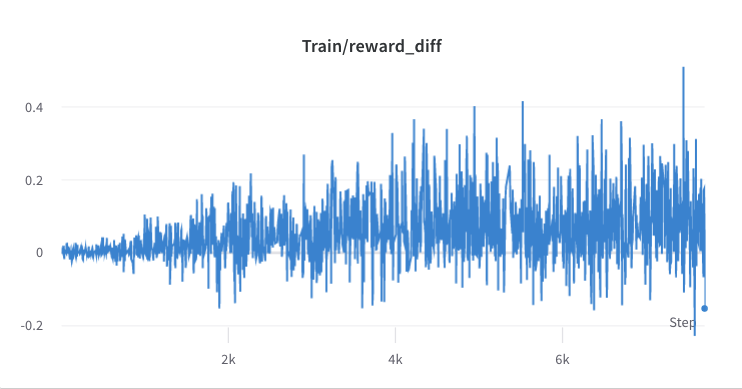
- عملية التدريب من الخطوة 3
- الاستدلال
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
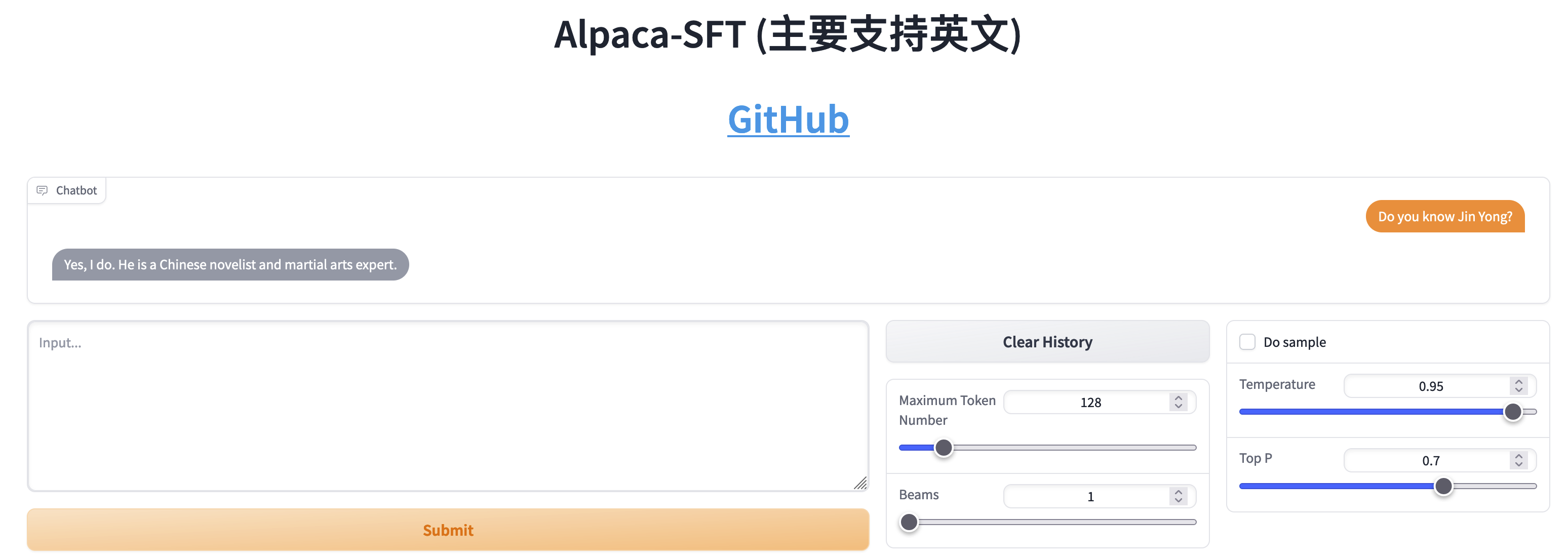
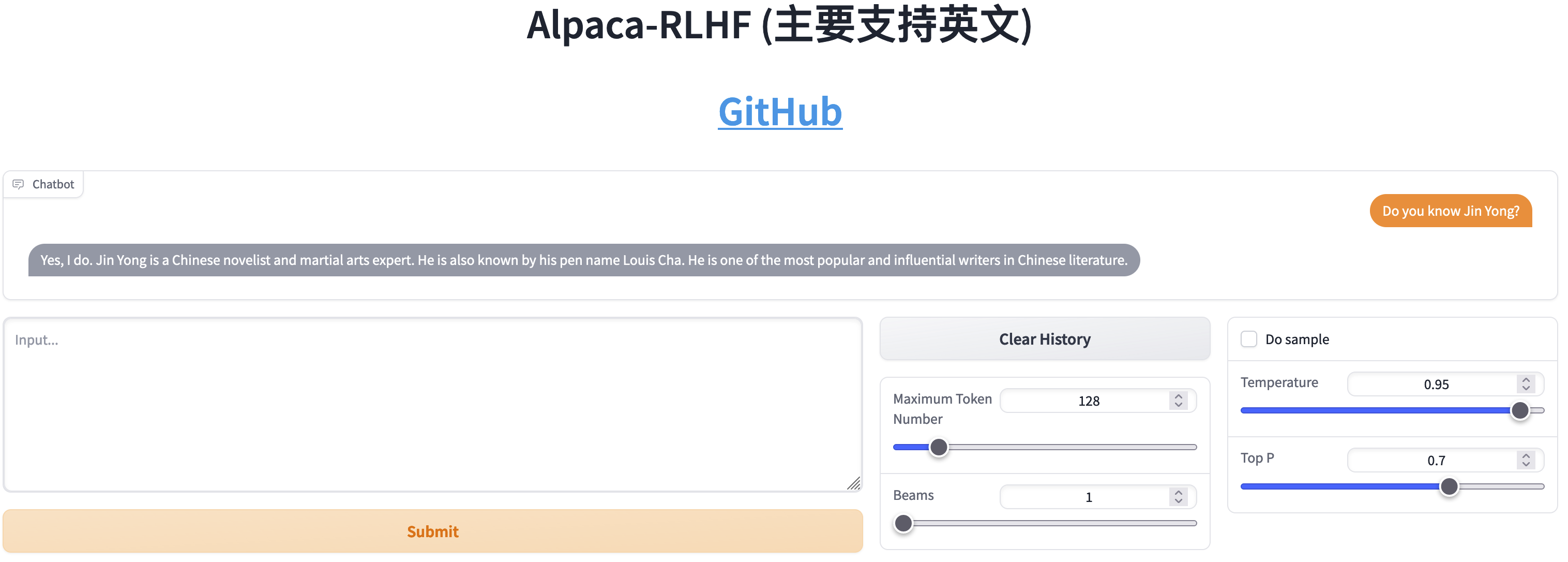
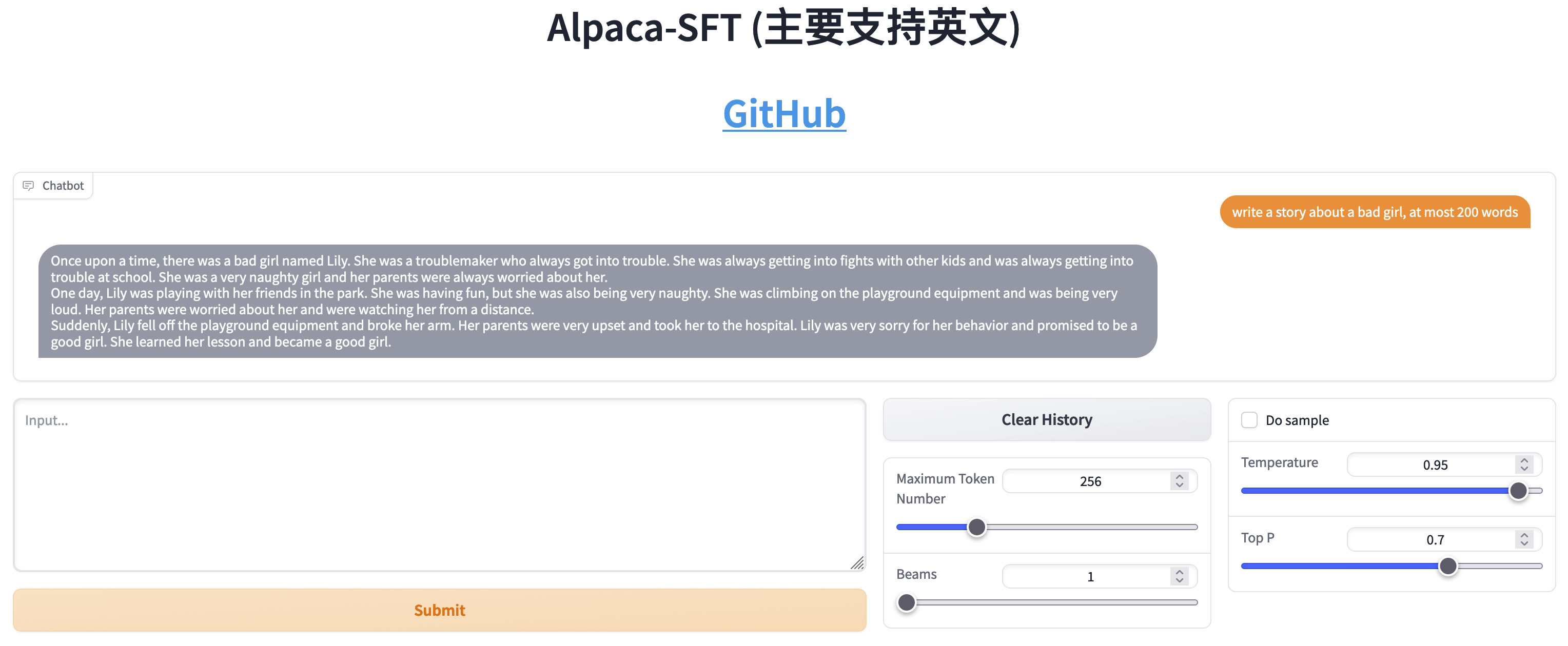
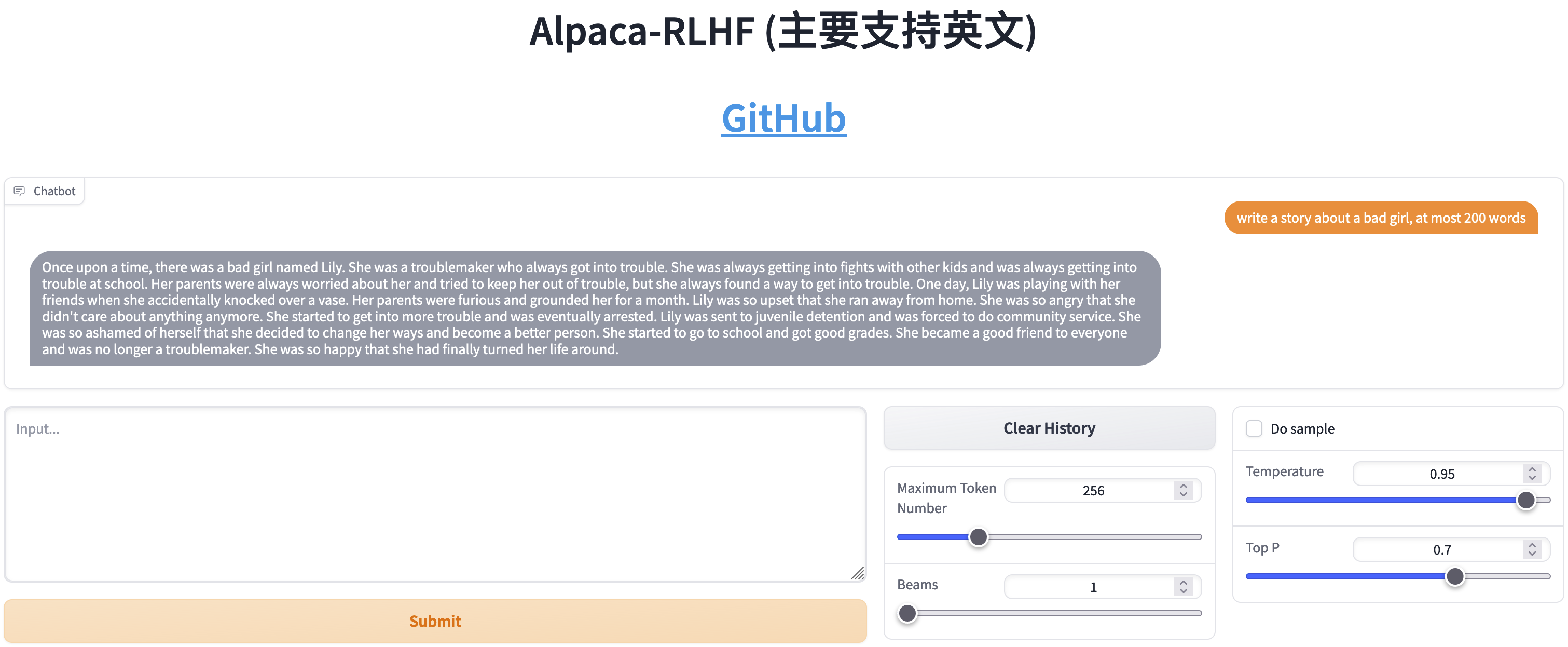
مقارنة بين SFT وRLHF
مراجع
مقالات
- 如何正确复现 إرشاد GPT / RLHF؟
- تم تصميم PPO لـ 10 سلاسل من الماكينات (PPO算法简洁Pytorch)
مصادر
أدوات
مجموعات البيانات
- مجموعة بيانات التفضيلات البشرية في جامعة ستانفورد (SHP)
- سمو-RLHF
- hh-rlhf
- تدريب مساعد مفيد وغير ضار من خلال التعلم المعزز من ردود الفعل البشرية [ورقة]
- داهوا/ثابت-hh
- داهوا/RM-ثابت
- جي بي تي-4-LLM
- مساعد مفتوح
المستودعات ذات الصلة
- my-alpaca
- الألبكة متعددة الأدوار