Phi2 mini Chinese
1.0.0
هذا المشروع هو مشروع تجريبي، مع كود مفتوح المصدر وأوزان النموذج، وبيانات تدريب مسبق أقل. إذا كنت بحاجة إلى نموذج صغير صيني أفضل، فيمكنك الرجوع إلى مشروع ChatLM-mini-Chinese
حذر
هذا المشروع هو مشروع تجريبي وقد يخضع لتغييرات كبيرة في أي وقت، بما في ذلك بيانات التدريب وبنية النموذج وبنية دليل الملفات وما إلى ذلك. الإصدار الأول من النموذج ويرجى التحقق من tag v1.0
على سبيل المثال، إضافة نقاط في نهاية الجمل، وتحويل اللغة الصينية التقليدية إلى الصينية المبسطة، وحذف علامات الترقيم المتكررة (على سبيل المثال، تحتوي بعض مواد الحوار على الكثير من "。。。。。" )، وتوحيد NFKC Unicode (بشكل أساسي مشكلة كاملة- تحويل العرض إلى نصف العرض وبيانات صفحة الويب u3000 xa0) وما إلى ذلك.
للتعرف على عملية تنظيف البيانات المحددة، يرجى الرجوع إلى مشروع ChatLM-mini-Chinese.
يستخدم هذا المشروع رمز BPE byte level . هناك نوعان من أكواد التدريب المقدمة لقطاعات الكلمات: char level byte level .
بعد التدريب، يتذكر برنامج الرمز المميز التحقق مما إذا كانت هناك رموز خاصة شائعة في المفردات، مثل t و n وما إلى ذلك. يمكنك محاولة encode decode نص يحتوي على أحرف خاصة لمعرفة ما إذا كان من الممكن استعادته. إذا لم يتم تضمين هذه الأحرف الخاصة، قم بإضافتها من خلال وظيفة add_tokens . استخدم len(tokenizer) للحصول على حجم المفردات tokenizer.vocab_size لا يحسب الأحرف المضافة من خلال وظيفة add_tokens .
يستهلك تدريب Tokenizer قدرًا كبيرًا من الذاكرة:
يتطلب تدريب 100 مليون حرف byte level ما لا يقل عن 32G من الذاكرة (في الواقع، 32G ليست كافية، وسيتم تشغيل المبادلة بشكل متكرر). ويستغرق تدريب 13600k حوالي ساعة.
يتطلب التدريب char level الذي يبلغ 650 مليون حرف (وهو بالضبط مقدار البيانات الموجودة في ويكيبيديا الصينية) ما لا يقل عن 32 جيجا بايت من الذاكرة نظرًا لأنه يتم تشغيل المبادلة عدة مرات، فإن الاستخدام الفعلي أكثر بكثير من 32 جيجا بايت. ويستغرق التدريب 13600K حوالي نصف ساعة.
لذلك، عندما تكون مجموعة البيانات كبيرة (مستوى جيجابايت)، يوصى بأخذ عينة من مجموعة البيانات عند تدريب tokenizer .
استخدم كمية كبيرة من النص للتدريب المسبق غير الخاضع للرقابة، وذلك باستخدام مجموعة البيانات BELLE بشكل أساسي من bell open source .
تنسيق مجموعة البيانات: جملة واحدة لعينة واحدة إذا كانت طويلة جدًا، فيمكن اقتطاعها وتقسيمها إلى عينات متعددة.
أثناء عملية التدريب المسبق لـ CLM، تكون مدخلات ومخرجات النموذج هي نفسها، وعند حساب خسارة الإنتروبيا المتقاطعة، يجب إزاحتها بمقدار بت واحد ( shift ).
عند معالجة مجموعة الموسوعة، يوصى بإضافة علامة '[EOS]' في نهاية كل إدخال. عمليات معالجة النصوص الأخرى مماثلة. يجب وضع علامة '[EOS]' على نهاية doc (والتي يمكن أن تكون نهاية مقال أو نهاية فقرة). يمكن إضافة علامة البداية '[BOS]' أم لا.
استخدم بشكل أساسي مجموعة بيانات bell open source . شكرا لك رئيس بيل.
تنسيق البيانات لتدريب SFT هو كما يلي:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" عندما يحسب النموذج الخسارة، فإنه سيتجاهل الجزء الذي قبل العلامة "##回答:" (سيتم تجاهل "##回答:" أيضًا)، بدءًا من نهاية "##回答:" .
تذكر إضافة علامة خاصة بنهاية جملة EOS ، وإلا فلن تعرف متى تتوقف عند decode النموذج. يمكن ملء علامة بداية جملة BOS أو تركها فارغة.
اعتماد طريقة تحسين تفضيلات DPO أبسط وأكثر توفيرًا للذاكرة.
قم بضبط نموذج SFT وفقًا للتفضيلات الشخصية، ويجب أن تقوم مجموعة البيانات ببناء ثلاثة أعمدة: prompt ، chosen ، rejected . يحتوي العمود rejected على بعض البيانات من النموذج الأساسي في مرحلة sft (على سبيل المثال، sft يدرب 4 epoch ويستغرق وقتًا). نموذج نقطة تفتيش epoch 0.5) إنشاء، إذا كان التشابه بين الناتج rejected chosen أعلى من 0.9، فلن تكون هناك حاجة لهذه البيانات.
هناك نموذجان في عملية DPO، أحدهما هو النموذج الذي سيتم تدريبه، والآخر هو النموذج المرجعي عند التحميل، وهو في الواقع نفس النموذج، لكن النموذج المرجعي لا يشارك في تحديثات المعلمات.
مستودع وزن huggingface النموذجي: Phi2-Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
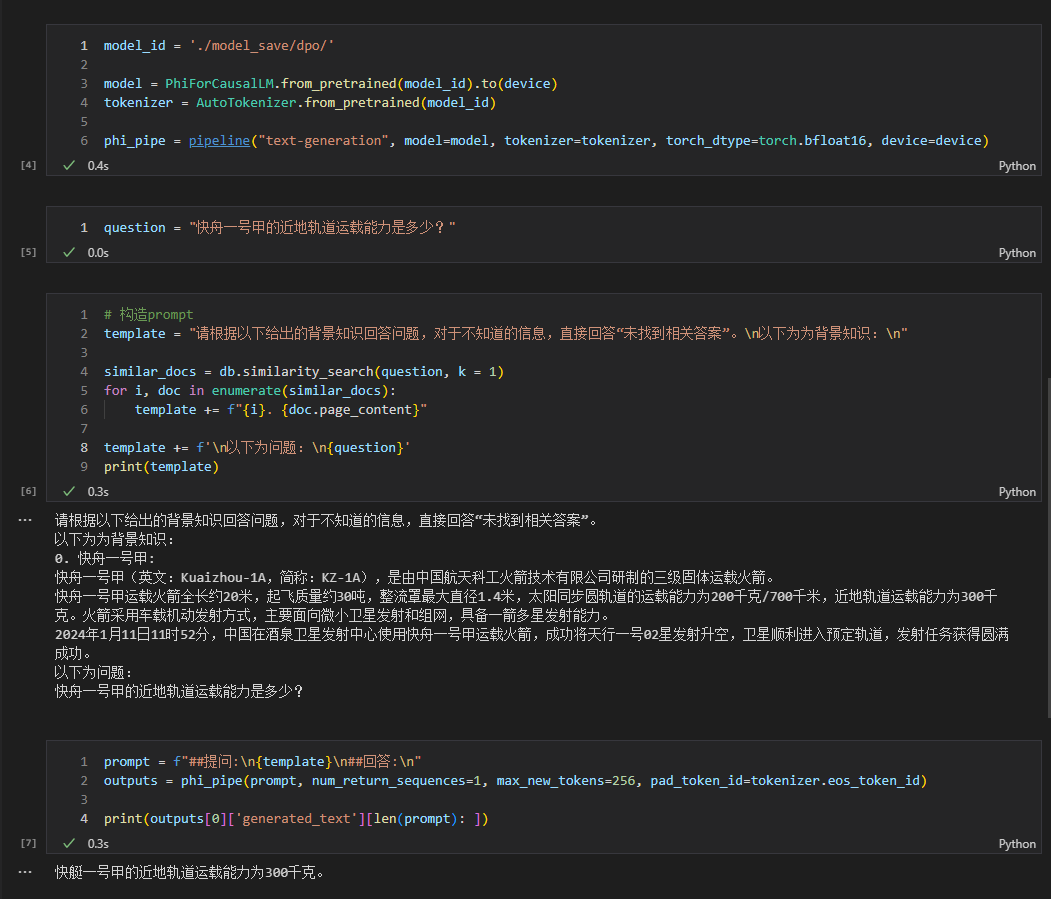
- 另外,如果感冒了,建议及时就医。 راجع rag_with_langchain.ipynb للحصول على الكود المحدد.
إذا كنت تعتقد أن هذا المشروع مفيد لك، يرجى ذكره.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
لا يتحمل هذا المشروع مخاطر ومسؤوليات مخاطر أمن البيانات والرأي العام الناجمة عن النماذج والأكواد مفتوحة المصدر، أو المخاطر والمسؤوليات الناشئة عن تضليل أي نموذج أو إساءة استخدامه أو نشره أو استغلاله بشكل غير صحيح.


