DialogStudio
1.0.0

ورقة، معانقة، نموذج، تويتر
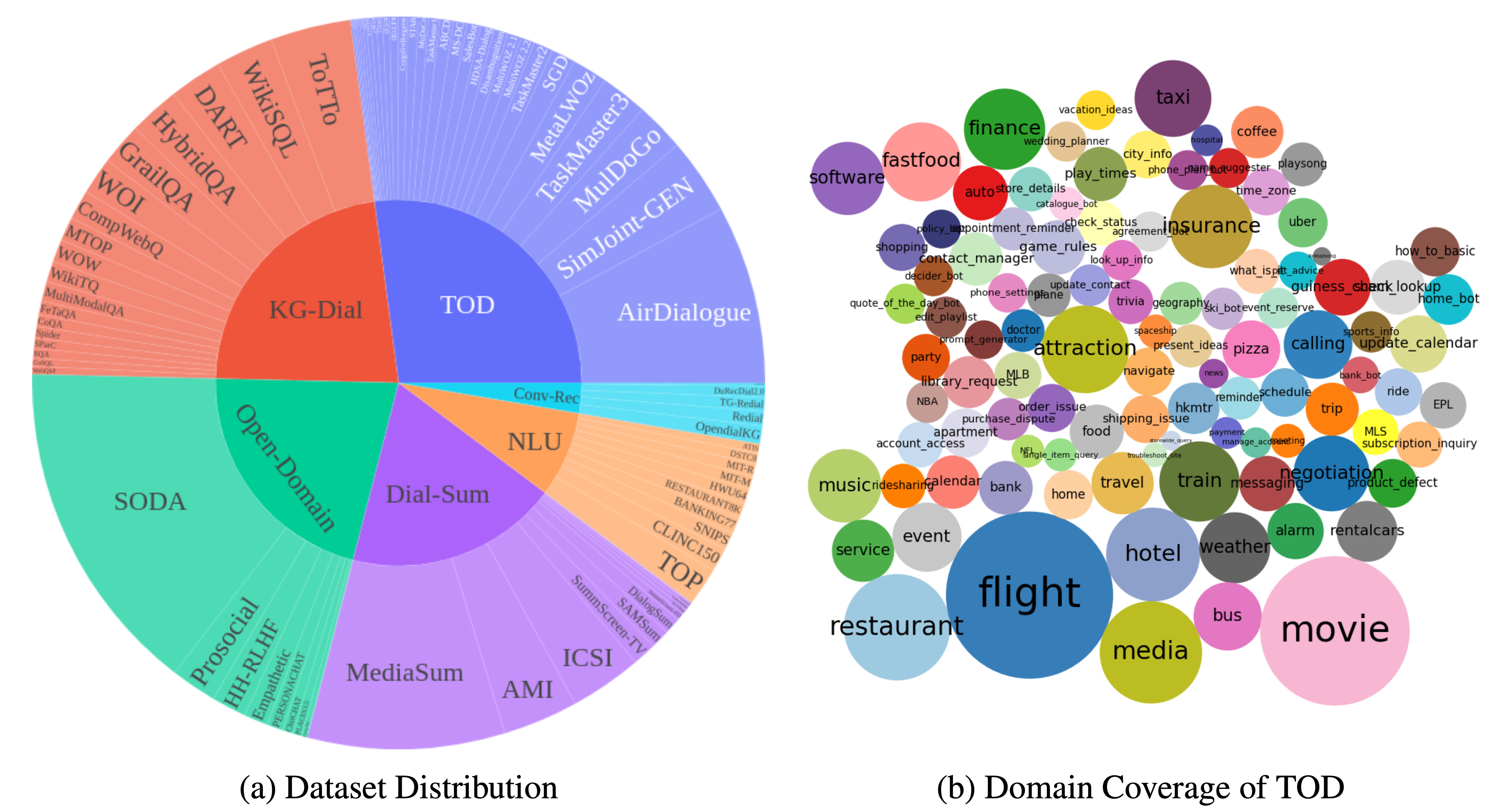
DialogStudio عبارة عن مجموعة كبيرة ومجموعات بيانات حوار موحدة. يقدم الشكل أدناه ملخصًا للإحصائيات العامة المرتبطة بـ DialogStudio . قام DialogStudio بتوحيد كل مجموعة بيانات مع الحفاظ على معلوماتها الأصلية، وهذا يساعد في دعم البحث في كل من مجموعات البيانات الفردية والتدريب على نماذج اللغة الكبيرة (LLM). القائمة الكاملة لجميع مجموعات البيانات المتاحة هنا.
يمكن تنزيل البيانات من خلال Huggingface كما تم تقديمه في تحميل البيانات. نقدم أيضًا أمثلة لكل مجموعة بيانات في هذا الريبو. لمزيد من التفاصيل التفصيلية والفئة المحددة، يرجى الرجوع إلى المجلدات الفردية المقابلة لكل فئة ضمن مجموعة DialogStudio ، على سبيل المثال مجموعة بيانات MULTIWOZ2_2 ضمن فئة الحوارات الموجهة نحو المهام.
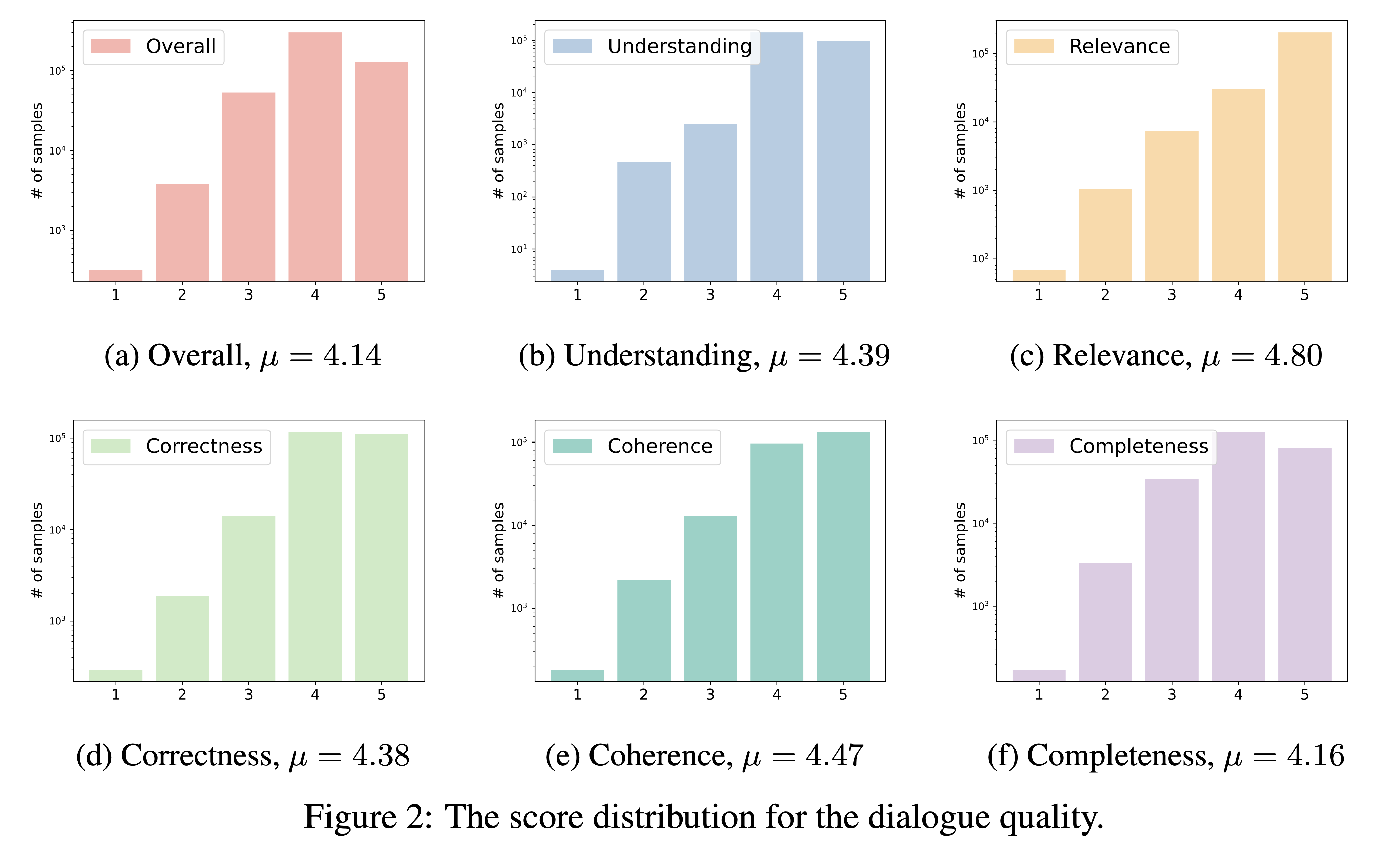
يقوم DialogStudio بتقييم جودة الحوار بناءً على ستة معايير حاسمة، وهي الفهم والملاءمة والصحة والتماسك والاكتمال والجودة الشاملة. يتم تسجيل كل معيار على مقياس من 1 إلى 5، مع حجز أعلى الدرجات للحوارات الاستثنائية.
نظرًا للعدد الكبير من مجموعات البيانات المدمجة في DialogStudio ، استخدمنا "gpt-3.5-turbo" لتقييم 33 مجموعة بيانات متميزة. يمكن الوصول إلى البرنامج النصي المقابل المستخدم لهذا التقييم من خلال الرابط.
يتم عرض نتائج تقييم جودة الحوار أدناه. ونعتزم إصدار نتائج التقييم للحوارات المختارة بشكل فردي في الفترة المقبلة.
يمكنك تحميل أي مجموعة بيانات في DialogStudio من مركز HuggingFace عن طريق المطالبة بـ {dataset_name} ، وهو بالضبط اسم مجلد مجموعة البيانات. يتم وصف جميع مجموعات البيانات المتاحة في محتوى مجموعة البيانات.
يوجد أدناه مثال لتحميل مجموعة البيانات MULTIWOZ2_2 ضمن فئة الحوارات الموجهة نحو المهام:
قم بتحميل مجموعة البيانات
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )هنا هيكل إخراج MultiWOZ 2.2
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})يتم تقسيم مجموعات البيانات إلى عدة فئات في مستودع GitHub ومركز HuggingFace. يمكنك التحقق من جدول مجموعة البيانات لمزيد من المعلومات. ويمكنك النقر فوق كل مجلد للتحقق من بعض الأمثلة:
لقد طرحنا الإصدار 1.0 من النماذج ( DialogStudio -t5-base-v1.0، DialogStudio -t5-large-v1.0، DialogStudio -t5-3b-v1.0) التي تم تدريبها على عدد قليل من مجموعات بيانات DialogStudio المحددة. تحقق من كل بطاقة نموذجية لمزيد من التفاصيل.
فيما يلي مثال واحد لتشغيل النموذج على وحدة المعالجة المركزية:
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))يتبع مشروعنا الهيكل التالي فيما يتعلق بالترخيص:
للحصول على معلومات الترخيص التفصيلية، يرجى الرجوع إلى التراخيص المحددة المصاحبة لمجموعات البيانات الأصلية. ومن المهم أن تتعرف على هذه الشروط لأننا لا نتحمل مسؤولية قضايا الترخيص.
نتقدم بالشكر الجزيل لجميع مؤلفي مجموعة البيانات الذين ساهموا في مجال الذكاء الاصطناعي للمحادثة. على الرغم من الجهود الحثيثة، قد تحدث أخطاء في اقتباساتنا أو مراجعنا. إذا اكتشفت أي أخطاء أو سهو، فيرجى إثارة مشكلة أو إرسال طلب سحب لمساعدتنا على التحسين. شكرًا لك!
تم تطوير البيانات والتعليمات البرمجية الموجودة في هذا المستودع في الغالب من أجل الورقة أدناه أو مشتقة منها. إذا كنت تستخدم مجموعات البيانات من DialogStudio ، فنطلب منك الاستشهاد بكل من العمل الأصلي وعملنا (تم قبوله بواسطة نتائج EACL 2024 كورقة طويلة).
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
نحن ندعو بحماس المساهمات من المجتمع! انضم إلينا في مهمتنا المشتركة لدفع مجال الذكاء الاصطناعي للمحادثة إلى الأمام!


