aug pe
1.0.0
؟ الورق • البيانات (Yelp/OpenReview/PubMed) • صفحة المشروع
يطبق هذا المستودع خوارزمية التطور الخاص المعزز (Aug-PE)، مما يعزز الوصول إلى واجهة برمجة التطبيقات الاستدلالية إلى نماذج اللغات الكبيرة (LLMs) لإنشاء نص تركيبي خاص تفاضلي (DP) دون الحاجة إلى التدريب النموذجي. قارنا ضبط DP-SGD وAug-PE:

تحت
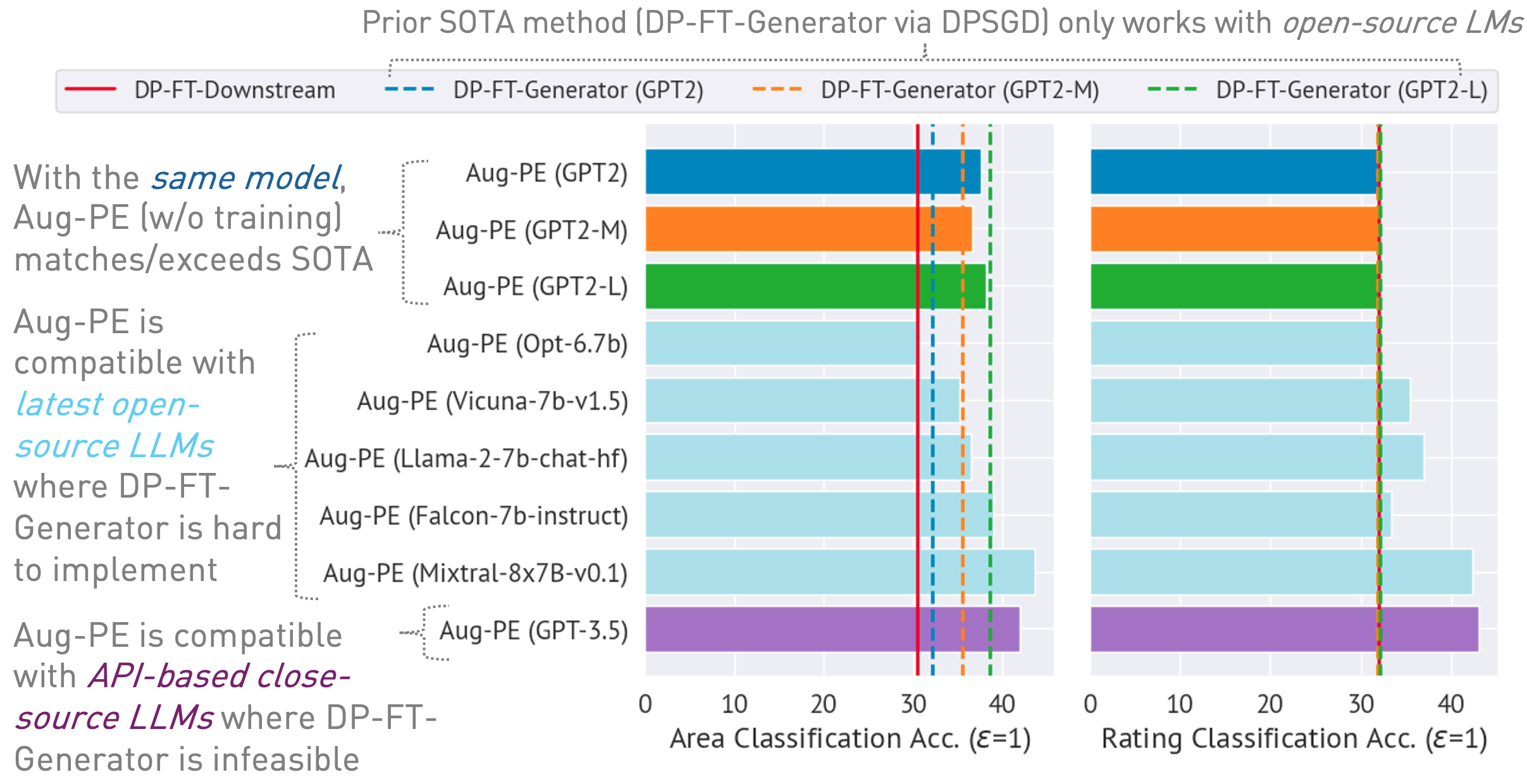
03/13/2024 : صفحة المشروع متاحة، والتي توضح الخوارزمية ونتائجها.03/11/2024 : يتوفر الكود وورقة ArXiv. conda env create -f environment.yml
conda activate augpe
توجد مجموعات البيانات في data/{dataset} حيث تكون dataset yelp و openreview و pubmed .
قم بتنزيل Yelp train.csv (1.21G) وPubMed train.csv (117 ميجابايت) من هذا الرابط أو قم بتنفيذ:
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvوصف مجموعة البيانات:
عمليات التضمين المسبقة للبيانات الخاصة (السطر 1 في خوارزمية Aug-PE):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp ملحوظة: تعد عملية حساب التضمينات لـ OpenReview وPubMed سريعة نسبيًا. ومع ذلك، نظرًا لحجم مجموعة بيانات Yelp الكبير (1.9 مليون عينة تدريبية)، قد تستغرق العملية حوالي 40 دقيقة.
احسب مستوى ضوضاء DP لمجموعة البيانات الخاصة بك في notebook/dp_budget.ipynb بالنظر إلى ميزانية الخصوصية
للتصور باستخدام Wandb، قم بتكوين --wandb_key و --project باستخدام مفتاحك واسم المشروع في dpsda/arg_utils.py .
استخدم شهادات LLM مفتوحة المصدر من Hugging Face لإنشاء بيانات تركيبية:
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedبعض المعلمات الفائقة الرئيسية:
noise : ضوضاء DP.epoch : نستخدم 10 فترات لإعداد DP. بالنسبة للإعداد غير DP، نستخدم 20 حقبة لـ Yelp و10 حقبة لمجموعات البيانات الأخرى.model_type : نموذج على الوجه المعانق، مثل ["gpt2"، "gpt2-medium"، "gpt2-large"، "meta-llama/Llama-2-7b-chat-hf"، "tiiuae/falcon-7b-instruct" ، "facebook/opt-6.7b"، "lmsys/vicuna-7b-v1.5"، "mistralai/Mixtral-8x7B-Instruct-v0.1"].num_seed_samples : عدد العينات الاصطناعية.lookahead_degree : عدد الاختلافات في تقدير تضمين العينات الاصطناعية (السطر 5 في خوارزمية Aug-PE). الافتراضي هو 0 (التضمين الذاتي).L : يتعلق بعدد الاختلافات لإنشاء عينات تركيبية مرشحة (السطر 18 في خوارزمية Aug-PE)feat_ext : نموذج التضمين على محولات الجملة المعانقة.select_syn_mode : حدد العينات الاصطناعية وفقًا لأصوات الرسم البياني أو الاحتمالية. الافتراضي هو rank (السطر 19 في خوارزمية Aug-PE)temperature : درجة الحرارة لتوليد LLM.ضبط النموذج النهائي باستخدام النص الاصطناعي DP وتقييم دقة النموذج على بيانات الاختبار الحقيقية:
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance قياس مسافة توزيع التضمين:
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distanceمن أجل عملية مبسطة تجمع بين جميع خطوات التوليد والتقييم:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset نحن نستخدم نموذجًا مغلق المصدر عبر Azure OpenAI API. يرجى تعيين المفتاح ونقطة النهاية في apis/azure_api.py
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} هنا يمكن أن يكون engine gpt-35-turbo في Azure.
قم بتشغيل البرنامج النصي التالي لإنشاء بيانات تركيبية، وتقييمها في المهمة النهائية، وحساب مسافة توزيع التضمين بين البيانات الحقيقية والتركيبية:
bash scripts/gpt-3.5-turbo/{dataset}.shنحن نستخدم المطالبات المتعلقة بطول النص لـ GPT-3.5 للتحكم في طول النص الذي تم إنشاؤه. نقدم العديد من المعلمات الفائقة الإضافية هنا:
dynamic_len لتمكين آلية الطول الديناميكي.word_var_scale : يستخدم تباين الضوضاء الغوسية لتحديد الكلمة المستهدفة.max_token_word_scale : الحد الأقصى لعدد الرموز لكل كلمة. لقد قمنا بتعيين max_token لإنشاء LLM استنادًا إلى Target_word (المحدد في الموجه) وmax_token_word_scale. استخدم دفتر الملاحظات لحساب فرق توزيع طول النص بين البيانات الحقيقية والاصطناعية: notebook/text_lens_distribution.ipynb
إذا وجدت عملنا مفيدًا، فيرجى التفكير في الاستشهاد به على النحو التالي:
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}إذا كانت لديك أي أسئلة تتعلق بالرمز أو الورقة، فلا تتردد في إرسال بريد إلكتروني إلى Chulin ([email protected]) أو فتح مشكلة.


