bRAG langchain
1.0.0
If this project helps you, consider buying me a coffee ☕. Your support helps me keep contributing to the open-source community!
سيتم إطلاق منصة bRAGAI الرسمية قريبًا. انضم إلى قائمة الانتظار لتكون من أوائل المستخدمين!
يحتوي هذا المستودع على استكشاف شامل لجيل الاسترجاع المعزز (RAG) لمختلف التطبيقات. يوفر كل دفتر ملاحظات دليلاً عمليًا مفصلاً لإعداد RAG وتجربته بدءًا من المستوى التمهيدي وحتى التطبيقات المتقدمة، بما في ذلك الاستعلامات المتعددة وإنشاءات RAG المخصصة.
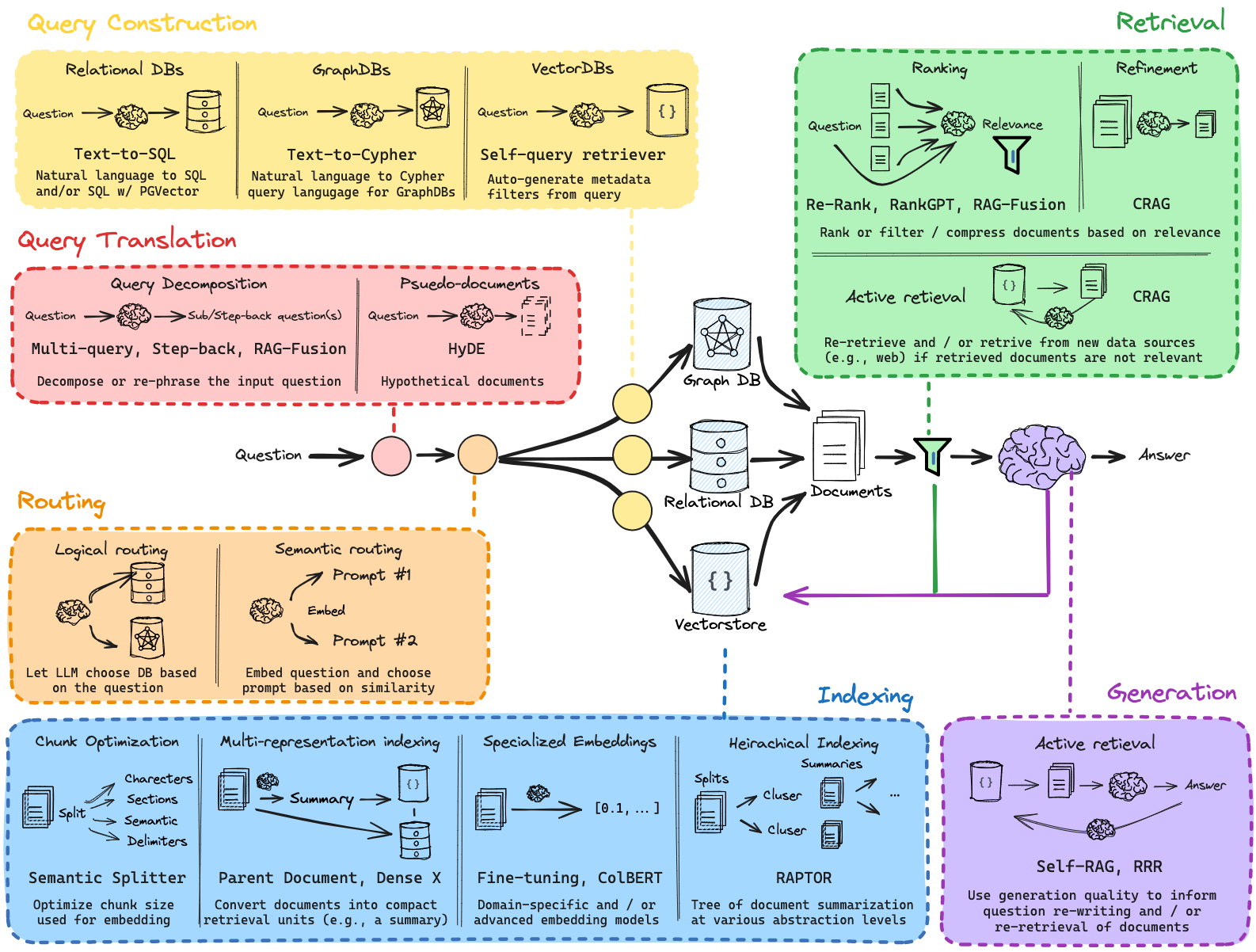
إذا كنت ترغب في الانتقال إليه مباشرة، فاطلع على الملف full_basic_rag.ipynb -> سيمنحك هذا الملف رمز بداية نموذجيًا لبرنامج الدردشة الآلي RAG القابل للتخصيص بالكامل.
تأكد من تشغيل ملفاتك في بيئة افتراضية (قسم الخروج Get Started )
يمكن العثور على دفاتر الملاحظات التالية ضمن الدليل tutorial_notebooks/ .
يوفر هذا الكمبيوتر المحمول التمهيدي نظرة عامة على بنية RAG وإعداداتها الأساسية. يمر دفتر الملاحظات عبر:
بناءً على الأساسيات، يقدم هذا الكمبيوتر الدفتري تقنيات الاستعلام المتعدد في مسار RAG، ويستكشف:
يتعمق هذا الكمبيوتر المحمول بشكل أعمق في تخصيص خط أنابيب RAG. ويغطي:
استمرارًا للتخصيص السابق، يستكشف هذا الكمبيوتر الدفتري ما يلي:
يجمع هذا الكمبيوتر الدفتري النهائي مكونات نظام RAG، مع التركيز على قابلية التوسع والتحسين:
المتطلبات السابقة: Python 3.11.7 (مفضل)
استنساخ المستودع :
git clone https://github.com/bRAGAI/bRAG-langchain.git
cd bRAG-langchain
إنشاء بيئة افتراضية
python -m venv venv
source venv/bin/activate
تثبيت التبعيات : تأكد من تثبيت الحزم المطلوبة المدرجة في ملف requirements.txt .
pip install -r requirements.txt
تشغيل دفاتر الملاحظات : ابدأ بـ [1]_rag_setup_overview.ipynb للتعرف على عملية الإعداد. تابع بشكل تسلسلي عبر دفاتر الملاحظات الأخرى لإنشاء وتجربة مفاهيم RAG الأكثر تقدمًا.
إعداد متغيرات البيئة :
قم بتكرار الملف .env.example في الدليل الجذر وقم بتسميته .env وقم بتضمين المفاتيح التالية (استبدلها بالمفاتيح الفعلية):
#LLM Modal
OPENAI_API_KEY="your-api-key"
#LangSmith
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
LANGCHAIN_API_KEY="your-api-key"
LANGCHAIN_PROJECT="your-project-name"
#Pinecone Vector Database
PINECONE_INDEX_NAME="your-project-index"
PINECONE_API_HOST="your-host-url"
PINECONE_API_KEY="your-api-key"
ترتيب دفتر الملاحظات : لمتابعة المشروع بطريقة منظمة:
ابدأ بـ [1]_rag_setup_overview.ipynb
تابع باستخدام [2]_rag_with_multi_query.ipynb
ثم انتقل عبر [3]_rag_routing_and_query_construction.ipynb
تابع مع [4]_rag_indexing_and_advanced_retrieval.ipynb
أنهي بـ [5]_rag_retrieval_and_reranking.ipynb
بعد إعداد البيئة وتشغيل دفاتر الملاحظات بالتسلسل، يمكنك:
تجربة إنشاء الاسترجاع المعزز : استخدم الإعداد الأساسي في [1]_rag_setup_overview.ipynb لفهم أساسيات RAG.
تنفيذ الاستعلام المتعدد : تعرف على كيفية تحسين ملاءمة الاستجابة من خلال تقديم تقنيات الاستعلام المتعدد في [2]_rag_with_multi_query.ipynb .
The notebooks and visual diagrams were inspired by Lance Martin's LangChain Tutorial.


