meena chatbot
1.0.0
هذه هي محاولتي لإعادة إنشاء Meena، وهو برنامج chatbot متطور تم تطويره بواسطة Google Research وتم وصفه في الورقة البحثية نحو Chatbot ذو مجال مفتوح يشبه الإنسان.
بالنسبة لهذا التنفيذ، استخدمت مكتبة التعلم العميق Tensor2tensor، باستخدام نموذج محول متطور كما هو موضح في الورقة.
مجموعة التدريب المستخدمة هي مجموعة OpenSubtitles باللغة الإيطالية. العديد من اللغات الأخرى متاحة هنا.
على غرار العمل المنجز في الورقة، يتكون هذا النموذج من كتلة تشفير واحدة و12 كتلة وحدة فك تشفير لإجمالي 108 مليون معلمة. المُحسِّن المستخدم هو Adafactor بنفس جدول معدل التدريب كما هو موضح في المقالة.
فيما يلي النتائج بعد تدريب النموذج على 40 مليون جملة من مجموعة بيانات OpenSubtitles باللغة الإيطالية. يبدأ معدل التعلم عند 0.01 ويظل ثابتًا لمدة 10 آلاف خطوة ثم يتضاءل مع الجذر التربيعي العكسي لعدد الخطوات.
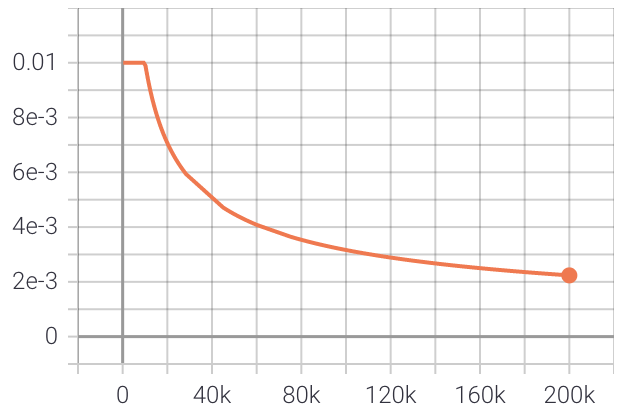
إليكم مؤامرة خسارة التقييم أثناء التدريب. 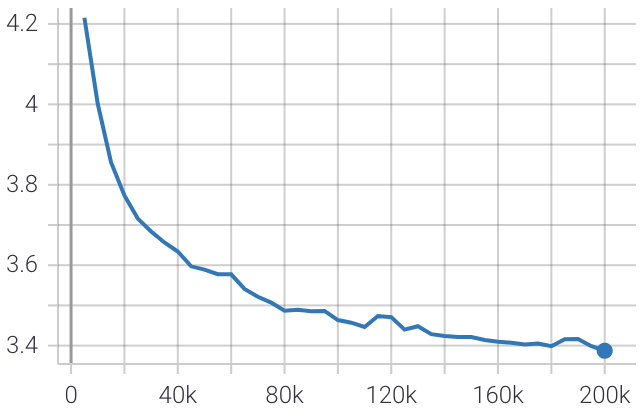
درجة الحيرة النهائية هي 10.4 وهي قريبة جدًا من درجة الحيرة التي حققها Google meena chatbot 10.2.
تُظهر الورقة وجود علاقة بين درجة الحيرة ومتوسط الحساسية والخصوصية الذي يرتبط بـ "الشبه البشري" لروبوت الدردشة. تُظهر درجة الحيرة لدينا أن الروبوت الخاص بنا أفضل من روبوتات الدردشة الأخرى مثل Cleverbot وDialoGPT: 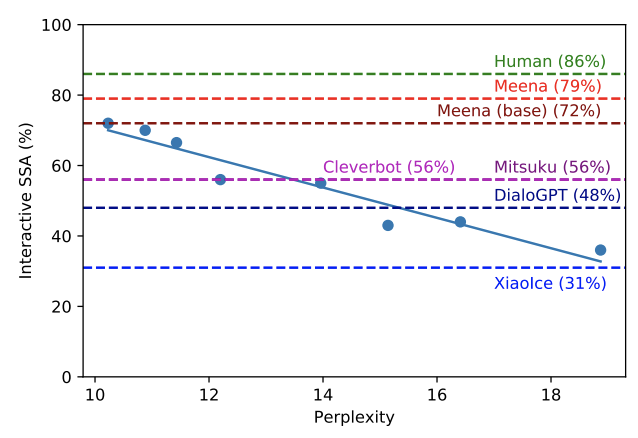
ومع ذلك، فإن مجموعة البيانات المستخدمة لا تمثل المحادثات العادية بين البشر. ومع ذلك، توفر Opensubtitles مجموعات بيانات كبيرة جدًا بالعديد من اللغات.
ما عليك سوى تشغيل دفتر الملاحظات meena_chatbot_inference.ipynb .
وإلا قم بتنزيل النموذج التالي واستخرجه. قم بتعيين MODEL_DIR وCHECKPOINT_NAME المناسبين في predict.py وتشغيل main.py
للتدريب، ما عليك سوى تشغيل دفتر ipython على Google Colab، وسيتم حفظ النموذج على Google Drive. في نهاية التنفيذ، يمكنك التفاعل مع chatbot.
يمكن تصدير النموذج عن طريق نسخ الملفات التالية في مجلد:
وقم بتشغيل main.py بعد تعيين دليل النموذج المناسب.
يوفر server.py واجهة برمجة تطبيقات HTTP بسيطة لخدمة روبوت الدردشة.


