LaTeX OCR
1.0.0
الهدف من هذا المشروع هو إنشاء نظام قائم على التعلم يأخذ صورة لمعادلة رياضية ويعيد كود LaTeX المقابل.
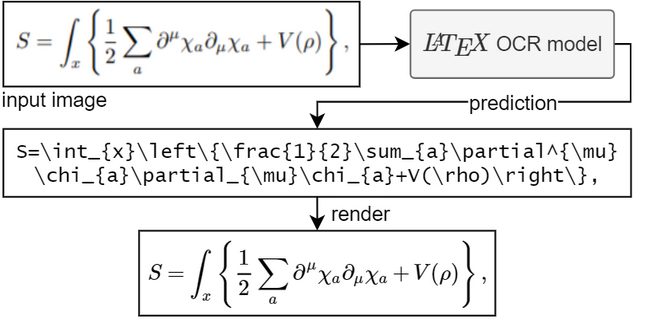
لتشغيل النموذج تحتاج إلى Python 3.7+
إذا لم يكن PyTorch مثبتًا لديك. اتبع تعليماتهم هنا.
تثبيت الحزمة pix2tex :
pip install "pix2tex[gui]"
سيتم تنزيل نقاط التفتيش النموذجية تلقائيًا.
هناك ثلاث طرق للحصول على تنبؤ من الصورة.
يمكنك استخدام أداة سطر الأوامر عن طريق استدعاء pix2tex . هنا يمكنك تحليل الصور الموجودة بالفعل من القرص والصور الموجودة في الحافظة الخاصة بك.
بفضل @katie-lim، يمكنك استخدام واجهة مستخدم رائعة كطريقة سريعة للحصول على التنبؤ بالنموذج. ما عليك سوى الاتصال بواجهة المستخدم الرسومية باستخدام latexocr . من هنا يمكنك التقاط لقطة شاشة ويتم عرض كود اللاتكس المتوقع باستخدام MathJax ونسخه إلى الحافظة الخاصة بك.
في نظام التشغيل Linux، من الممكن استخدام واجهة المستخدم الرسومية مع gnome-screenshot (التي تأتي مع دعم شاشات متعددة) إذا تم تثبيت gnome-screenshot مسبقًا. بالنسبة إلى Wayland، سيتم استخدام grim و slurp عندما يكونا متاحين. لاحظ أن gnome-screenshot غير متوافقة مع مؤلفي Wayland المعتمدين على wlroots. بما أن gnome-screenshot ستكون مفضلة عندما تكون متاحة، فقد تضطر إلى ضبط متغير البيئة SCREENSHOT_TOOL على grim في هذه الحالة (القيم الأخرى المتوفرة هي gnome-screenshot و pil ).
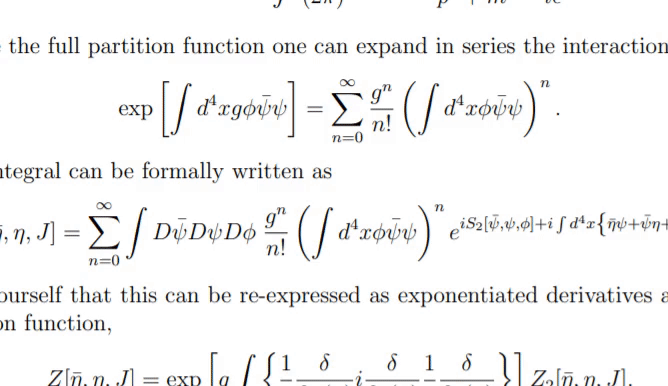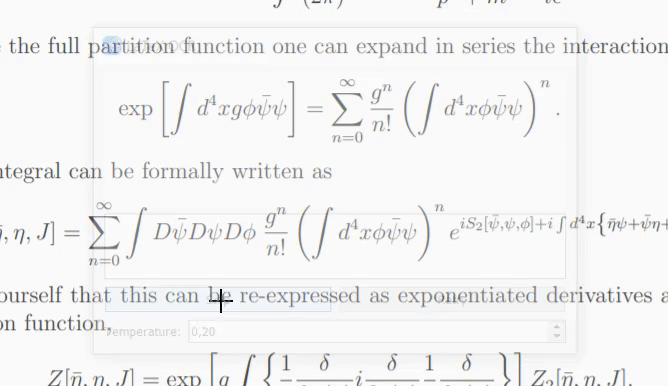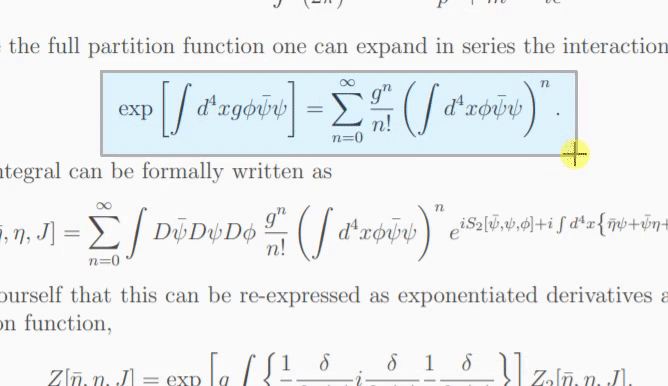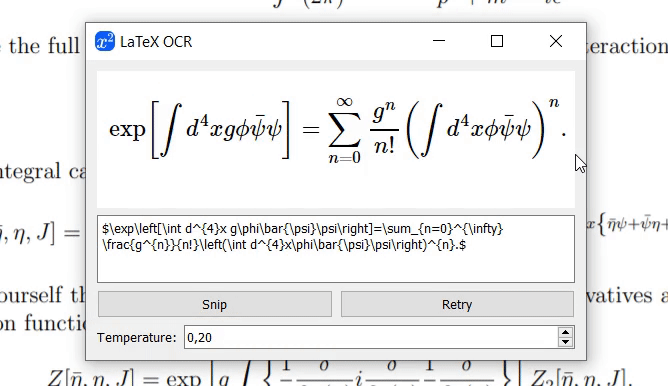
إذا لم يكن النموذج متأكدًا مما هو موجود في الصورة، فقد يُخرج تنبؤًا مختلفًا في كل مرة تنقر فيها على "إعادة المحاولة". باستخدام معلمة temperature ، يمكنك التحكم في هذا السلوك (درجة الحرارة المنخفضة ستؤدي إلى نفس النتيجة).
يمكنك استخدام واجهة برمجة التطبيقات. هذا له تبعيات إضافية. التثبيت عبر pip install -U "pix2tex[api]" وتشغيله
بايثون -م pix2tex.api.run
لبدء عرض توضيحي لـ Streamlit يتصل بواجهة برمجة التطبيقات (API) على المنفذ 8502. هناك أيضًا صورة عامل إرساء متاحة لواجهة برمجة التطبيقات (API): https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
لتشغيل العرض التجريبي المبسط أيضًا
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
وانتقل إلى http://localhost:8501/
استخدم من داخل بايثون
من PIL استيراد Imagefrom pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))يعمل النموذج بشكل أفضل مع الصور ذات الدقة الأصغر. ولهذا السبب أضفت خطوة المعالجة المسبقة حيث تتنبأ شبكة عصبية أخرى بالدقة المثلى لصورة الإدخال. سيقوم هذا النموذج تلقائيًا بتغيير حجم الصورة المخصصة لتشبه بيانات التدريب بشكل أفضل وبالتالي زيادة أداء الصور الموجودة في البرية. ومع ذلك، فهي ليست مثالية وقد لا تكون قادرة على التعامل مع الصور الضخمة على النحو الأمثل، لذا لا تقم بتكبير الصورة بالكامل قبل التقاط الصورة.
تحقق دائمًا من النتيجة بعناية. يمكنك محاولة إعادة التنبؤ بدقة أخرى إذا كانت الإجابة خاطئة.
هل تريد استخدام الحزمة؟
أحاول تجميع الوثائق الآن.
زيارة هنا: https://pix2tex.readthedocs.io/
قم بتثبيت اثنين من التبعيات pip install "pix2tex[train]" .
نحتاج أولاً إلى دمج الصور مع تسميات الحقيقة الأساسية الخاصة بها. لقد كتبت فئة مجموعة بيانات (تحتاج إلى مزيد من التحسين) تحفظ المسارات النسبية للصور باستخدام رمز LaTeX الذي تم تقديمها به. لإنشاء ملف اختيار مجموعة البيانات، قم بتشغيل
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
لاستخدام الرمز المميز الخاص بك، قم بتمريره عبر --tokenizer (انظر أدناه).
يمكنك العثور على بيانات التدريب التي تم إنشاؤها على Google Drive أيضًا (formulae.zip - الصور، math.txt - التصنيفات). كرر الخطوة للتحقق من صحة البيانات والاختبار. جميعها تستخدم نفس الملف النصي للتسمية.
قم بتحرير إدخال data (و valdata ) في ملف التكوين إلى ملف .pkl الذي تم إنشاؤه حديثًا. قم بتغيير المعلمات الفائقة الأخرى إذا كنت تريد ذلك. راجع pix2tex/model/settings/config.yaml للحصول على قالب.
الآن لتشغيل التدريب الفعلي
python -m pix2tex.train --config path_to_config_file
إذا كنت ترغب في استخدام بياناتك الخاصة، فقد تكون مهتمًا بإنشاء أداة الرموز المميزة الخاصة بك باستخدامها
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
لا تنس تحديث المسار إلى الرمز المميز في ملف التكوين وتعيين num_tokens على حجم المفردات الخاصة بك.
يتكون النموذج من جهاز تشفير ViT [1] مزود بعمود فقري ResNet ووحدة فك ترميز Transformer [2].
| درجة بلو | مسافة التحرير المعيارية | دقة رمزية |
|---|---|---|
| 0.88 | 0.10 | 0.60 |
نحتاج إلى بيانات مقترنة حتى تتعلم الشبكة. لحسن الحظ، هناك الكثير من أكواد LaTeX على الإنترنت، على سبيل المثال، ويكيبيديا، arXiv. نستخدم أيضًا الصيغ من مجموعة البيانات im2latex-100k [3]. كل ذلك يمكن العثور عليه هنا
من أجل عرض العمليات الحسابية في العديد من الخطوط المختلفة، نستخدم XeLaTeX، وننشئ ملف PDF ثم نقوم في النهاية بتحويله إلى PNG. بالنسبة للخطوة الأخيرة، نحتاج إلى استخدام بعض أدوات الطرف الثالث:
XeLaTeX
ImageMagick مع Ghostscript. (لتحويل pdf إلى png)
Node.js لتشغيل KaTeX (لتطبيع كود اللاتكس)
Python 3.7+ والتبعيات (المحددة في setup.py )
الرياضيات اللاتينية الحديثة، GFSNeohellenicMath.otf، Asana Math، XITS Math، Cambria Math
إضافة المزيد من مقاييس التقييم
إنشاء واجهة المستخدم الرسومية
إضافة بحث شعاع
دعم الصيغ المكتوبة بخط اليد (تم ذلك نوعًا ما، راجع دفتر تدريب colab)
تقليل حجم النموذج (التقطير)
العثور على المعلمات الفائقة الأمثل
تعديل هيكل النموذج
إصلاح تجريف البيانات وكشط المزيد من البيانات
تتبع النموذج (#2)
المساهمات من أي نوع هي موضع ترحيب.
تم أخذ الكود وتعديله من lucidrains، rwightman، im2markup، arxiv_leaks، pkra: Mathjax، harupy: أداة القطع
[1] الصورة تستحق 16 × 16 كلمة
[2] الاهتمام هو كل ما تحتاجه
[3] إنشاء الصورة إلى العلامات مع الاهتمام الخشن إلى الدقيق


