segment anything
1.0.0
يرجى الاطلاع على إصدارنا الجديد في Segment Anything Model 2 (SAM 2) .
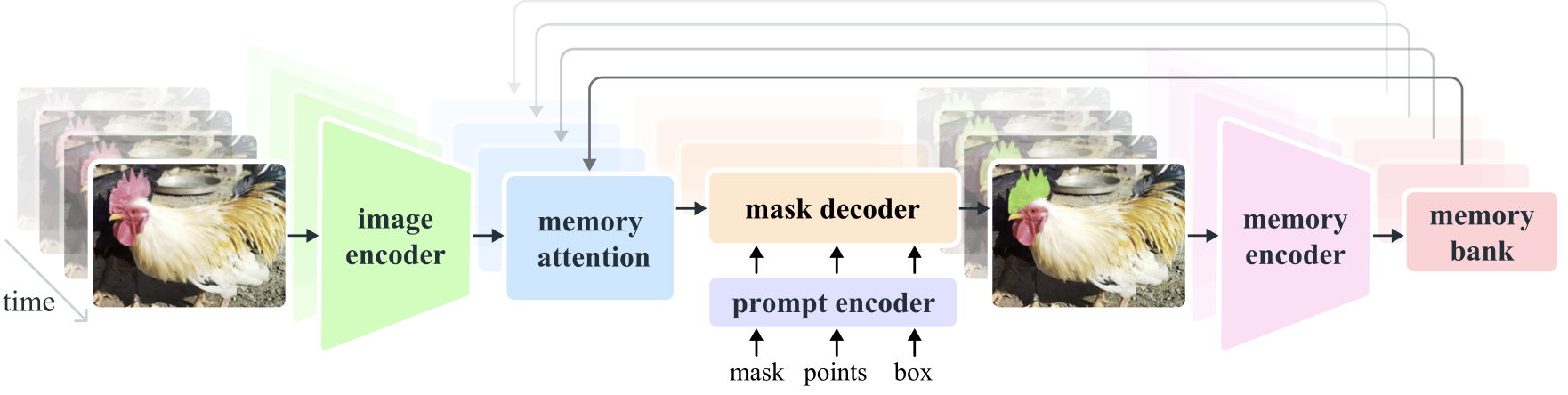
يُعد نموذج Segment Anything Model 2 (SAM 2) نموذجًا أساسيًا لحل التجزئة المرئية السريعة في الصور ومقاطع الفيديو. نقوم بتوسيع SAM إلى الفيديو من خلال اعتبار الصور فيديو بإطار واحد. تصميم النموذج عبارة عن بنية محولات بسيطة مع ذاكرة متدفقة لمعالجة الفيديو في الوقت الفعلي. نحن نبني محرك بيانات نموذج داخل الحلقة، والذي يعمل على تحسين النموذج والبيانات من خلال تفاعل المستخدم، لجمع مجموعة بيانات SA-V الخاصة بنا ، وهي أكبر مجموعة بيانات لتجزئة الفيديو حتى الآن. يوفر SAM 2، الذي تم تدريبه على بياناتنا، أداءً قويًا عبر مجموعة واسعة من المهام والمجالات المرئية.
أبحاث ميتا آي آي، فير
ألكسندر كيريلوف، إريك مينتون، نيكيلا رافي، هانزي ماو، كلوي رولاند، لورا جوستافسون، تيتي شياو، سبنسر وايتهيد، أليكس بيرج، وان ين لو، بيوتر دولار، روس جيرشيك
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
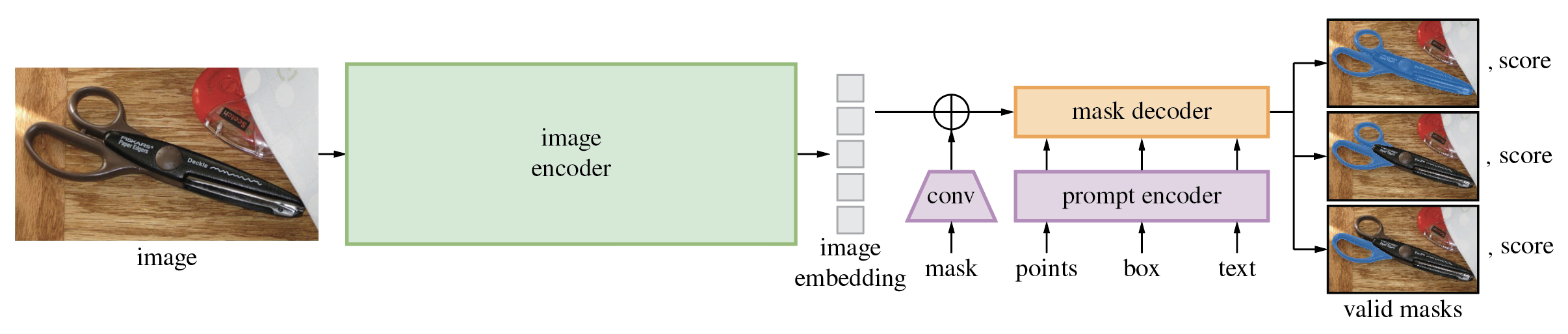
يُنتج نموذج Segment Anything Model (SAM) أقنعة كائنات عالية الجودة من مطالبات الإدخال مثل النقاط أو المربعات، ويمكن استخدامه لإنشاء أقنعة لجميع الكائنات في الصورة. وقد تم تدريبه على مجموعة بيانات مكونة من 11 مليون صورة و1.1 مليار قناع، ويتمتع بأداء قوي بدون لقطة في مجموعة متنوعة من مهام التجزئة.


يتطلب الكود python>=3.8 وكذلك pytorch>=1.7 و torchvision>=0.8 . برجاء اتباع التعليمات الواردة هنا لتثبيت تبعيات PyTorch وTorchVision. يوصى بشدة بتثبيت كل من PyTorch وTorchVision بدعم CUDA.
تثبيت شريحة أي شيء:
pip install git+https://github.com/facebookresearch/segment-anything.git
أو استنساخ المستودع محليًا وتثبيته باستخدام
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
تعد التبعيات الاختيارية التالية ضرورية للمعالجة اللاحقة للقناع، وحفظ الأقنعة بتنسيق COCO، وأمثلة دفاتر الملاحظات، وتصدير النموذج بتنسيق ONNX. مطلوب jupyter أيضًا لتشغيل نماذج دفاتر الملاحظات.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
قم أولاً بتنزيل نقطة تفتيش نموذجية. بعد ذلك يمكن استخدام النموذج في بضعة أسطر فقط للحصول على أقنعة من موجه معين:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
أو قم بإنشاء أقنعة لصورة بأكملها:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
بالإضافة إلى ذلك، يمكن إنشاء أقنعة للصور من سطر الأوامر:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
راجع أمثلة دفاتر الملاحظات حول استخدام SAM مع المطالبات وإنشاء الأقنعة تلقائيًا لمزيد من التفاصيل.


يمكن تصدير وحدة فك ترميز القناع خفيف الوزن من SAM إلى تنسيق ONNX بحيث يمكن تشغيلها في أي بيئة تدعم وقت تشغيل ONNX، مثل المتصفح الموجود في العرض التوضيحي. تصدير النموذج مع
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
راجع مثال دفتر الملاحظات للحصول على تفاصيل حول كيفية الجمع بين المعالجة المسبقة للصور عبر العمود الفقري لـ SAM مع التنبؤ بالقناع باستخدام نموذج ONNX. يوصى باستخدام أحدث إصدار ثابت من PyTorch لتصدير ONNX.
يحتوي المجلد demo/ المجلد على تطبيق React بسيط مكون من صفحة واحدة يوضح كيفية تشغيل تنبؤ القناع باستخدام نموذج ONNX المُصدَّر في متصفح ويب مزود بمؤشرات ترابط متعددة. يرجى الاطلاع على demo/README.md لمزيد من التفاصيل.
تتوفر ثلاثة إصدارات من الطراز بأحجام أساسية مختلفة. يمكن إنشاء مثيل لهذه النماذج عن طريق التشغيل
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
انقر فوق الروابط أدناه لتنزيل نقطة التحقق الخاصة بنوع النموذج المقابل.
default أو vit_h : نموذج ViT-H SAM.vit_l : نموذج ViT-L SAM.vit_b : نموذج ViT-B SAM. انظر هنا للحصول على نظرة عامة على قاعدة البيانات. يمكن تنزيل مجموعة البيانات هنا. من خلال تنزيل مجموعات البيانات، فإنك توافق على أنك قرأت وقبلت شروط ترخيص أبحاث مجموعة البيانات SA-1B.
نقوم بحفظ الأقنعة لكل صورة كملف json. يمكن تحميله كقاموس في بايثون بالتنسيق أدناه.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}يمكن العثور على معرفات الصور في sa_images_ids.txt والتي يمكن تنزيلها باستخدام الرابط أعلاه أيضًا.
لفك تشفير قناع بتنسيق COCO RLE إلى ثنائي:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
انظر هنا لمزيد من الإرشادات للتعامل مع الأقنعة المخزنة بتنسيق RLE.
النموذج مرخص بموجب ترخيص Apache 2.0.
انظر المساهمة ومدونة قواعد السلوك.
أصبح مشروع Segment Anything ممكنًا بمساعدة العديد من المساهمين (أبجديًا):
آرون أدكوك، فايبهاف أجروال، مرتضى بهروز، تشينج يانج فو، آشلي جابرييل، أهوفا جولدستاند، ألين جودمان، سومانث جورام، جيابو هو، سوميا جاين، ديفانش كوكريجا، روبرت كو، جوشوا لين، يانجهاو لي، ليليان لونج، جيتندرا مالك، ماليكا مالهوترا، ويليام نجان، أومكار باركي، نيخيل راينا، ديرك رو، نيل سيجور، فانيسا ستارك، بالا فاراداراجان، برام واستي، زاكاري وينستروم
إذا كنت تستخدم SAM أو SA-1B في بحثك، فيرجى استخدام إدخال BibTeX التالي.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


