obfuscated gradients
v1.0.0
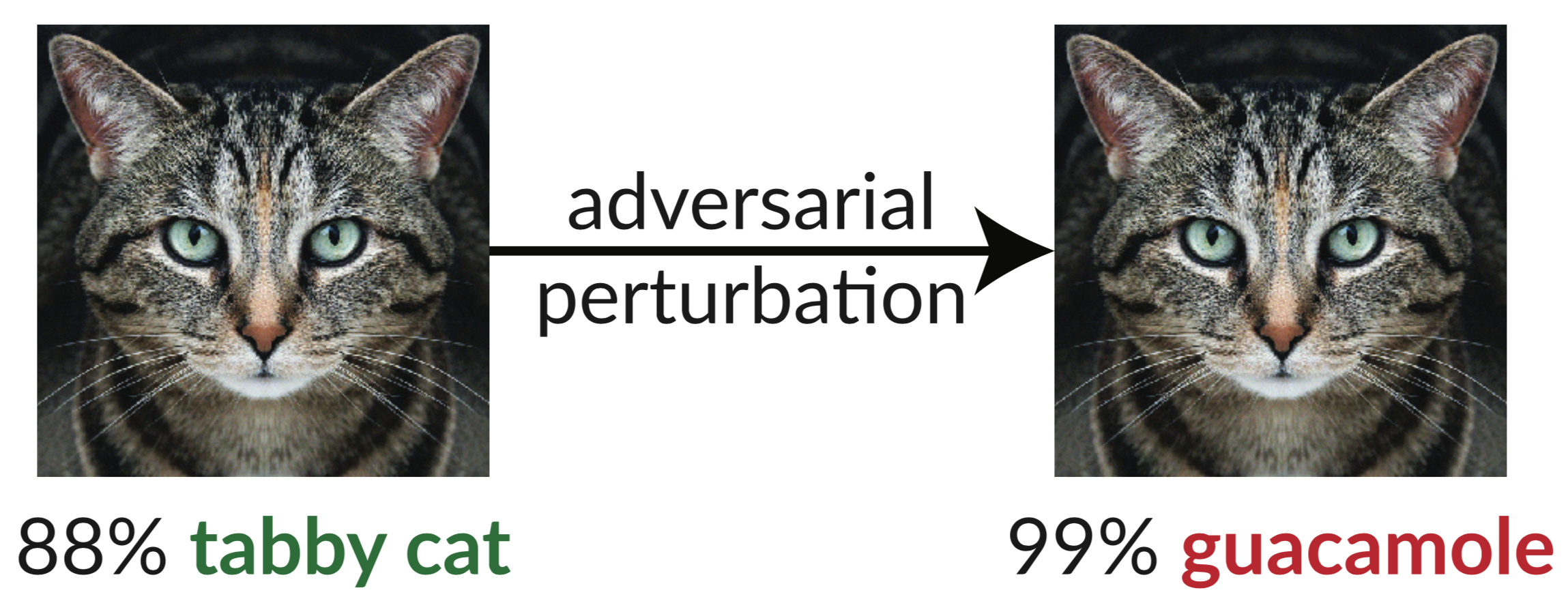
يوجد أعلاه مثال عدائي: صورة القطة المضطربة قليلاً تخدع مصنف InceptionV3 لتصنيفها على أنها "غواكامولي". من السهل تركيب مثل هذه "الصور الخادعة" باستخدام النسب المتدرج (Szegedy et al. 2013).
في بحثنا الأخير، قمنا بتقييم قوة تسع أوراق بحثية تم قبولها في ICLR 2018 كدفاعات آمنة غير معتمدة للصندوق الأبيض ضد أمثلة الخصومة. لقد وجدنا أن سبعة من الدفاعات التسعة توفر زيادة محدودة في القوة ويمكن كسرها من خلال تقنيات الهجوم المحسنة التي نطورها.
يوجد أدناه الجدول 1 من ورقتنا، حيث نعرض قوة كل دفاع مقبول للأمثلة العدائية التي يمكننا بناءها:
| الدفاع | مجموعة البيانات | مسافة | دقة |
|---|---|---|---|
| بوكمان وآخرون. (2018) | سيفار | 0.031 (لينف) | 0%* |
| ما وآخرون. (2018) | سيفار | 0.031 (لينف) | 5% |
| قوه وآخرون. (2018) | إيماج نت | 0.05 (ل2) | 0%* |
| ديلون وآخرون. (2018) | سيفار | 0.031 (لينف) | 0% |
| شيه وآخرون. (2018) | إيماج نت | 0.031 (لينف) | 0%* |
| سونغ وآخرون. (2018) | سيفار | 0.031 (لينف) | 9%* |
| سامانجوي وآخرون. (2018) | منيست | 0.005 (ل2) | 55%** |
| مادري وآخرون. (2018) | سيفار | 0.031 (لينف) | 47% |
| نا وآخرون. (2018) | سيفار | 0.015 (لينف) | 15% |
(الدفاعات المشار إليها بـ * تقترح أيضًا الجمع بين التدريب على المواجهة؛ ونورد هنا الدفاع وحده. راجع بحثنا، القسم 5 للحصول على الأعداد الكاملة. المبدأ الأساسي وراء الدفاع المشار إليه بـ ** له دقة 0٪؛ في الممارسة العملية، تتسبب عيوب الدفاع في حدوث خطأ نظريًا الهجوم الأمثل للفشل، راجع القسم 5.4.2 للحصول على التفاصيل.)
الدفاع الوحيد الذي لاحظناه والذي يزيد بشكل كبير من قوة أمثلة الخصومة ضمن نموذج التهديد المقترح هو "نحو نماذج التعلم العميق المقاومة للهجمات العدائية" (Madry et al. 2018)، ولم نتمكن من هزيمة هذا الدفاع دون الخروج عن نموذج التهديد . وحتى مع ذلك، فقد ثبت أن هذه التقنية يصعب توسيع نطاقها وفقًا لمقياس ImageNet (Kurakin et al. 2016). وتعتمد بقية الأوراق البحثية (إلى جانب ورقة نا وآخرون، التي تقدم قوة محدودة) إما عن غير قصد أو عن قصد على ما نسميه التدرجات المبهمة . تطبق الهجمات القياسية الانحدار المتدرج لتعظيم فقدان الشبكة على صورة معينة لإنشاء مثال عدائي على الشبكة العصبية. تتطلب أساليب التحسين هذه إشارة تدرج مفيدة لتحقيق النجاح. عندما يقوم الدفاع بتشويش التدرجات، فإنه يكسر إشارة التدرج هذه ويتسبب في فشل الأساليب القائمة على التحسين.
لقد حددنا ثلاث طرق تتسبب فيها الدفاعات في تدرجات مبهمة، ونبني هجمات لتجاوز كل حالة من هذه الحالات. تنطبق هجماتنا بشكل عام على أي دفاع يتضمن، سواء عن قصد أو عن غير قصد، عملية غير قابلة للتمييز أو يمنع إشارة التدرج من التدفق عبر الشبكة. نأمل أن يتمكن العمل المستقبلي من استخدام أساليبنا لإجراء تقييم أمني أكثر شمولاً.
خلاصة:
نحن نحدد التدرجات المبهمة، وهي نوع من إخفاء التدرج، كظاهرة تؤدي إلى شعور زائف بالأمان في الدفاعات ضد الأمثلة العدائية. في حين أن الدفاعات التي تسبب التدرجات المبهمة تبدو وكأنها تهزم الهجمات المتكررة القائمة على التحسين، فإننا نجد أن الدفاعات التي تعتمد على هذا التأثير يمكن التحايل عليها. نحن نصف السلوكيات المميزة للدفاعات التي تظهر التأثير، ولكل نوع من الأنواع الثلاثة من التدرجات المبهمة التي نكتشفها، نقوم بتطوير تقنيات الهجوم للتغلب عليها. في دراسة حالة، عند فحص دفاعات الصندوق الأبيض الآمنة غير المعتمدة في ICLR 2018، نجد أن التدرجات المبهمة هي أمر شائع، حيث تعتمد 7 من 9 دفاعات على التدرجات المبهمة. نجحت هجماتنا الجديدة في التحايل على 6 هجمات بشكل كامل، وواحدة جزئيًا، في نموذج التهديد الأصلي الذي تتناوله كل ورقة بحثية.
للحصول على التفاصيل، اقرأ ورقتنا.
يحتوي هذا المستودع على نماذجنا لتقنيات الهجوم العامة الموضحة في بحثنا، مما أدى إلى كسر 7 من دفاعات ICLR لعام 2018. لم تُصدر بعض الدفاعات كود المصدر (في الوقت الذي قمنا فيه بهذا العمل)، لذا كان علينا إعادة تنفيذها.
@inproceedings{obfuscated-gradients، المؤلف = {Anish Athalye and Nicholas Carlini and David Wagner}، العنوان = {التدرجات المبهمة تعطي إحساسًا زائفًا بالأمان: التحايل على الدفاعات إلى الأمثلة العدائية}، عنوان الكتاب = {وقائع المؤتمر الدولي الخامس والثلاثين حول الآلة التعلم، {ICML} 2018}، السنة = {2018}، الشهر = يوليو، عنوان URL = {https://arxiv.org/abs/1802.00420}،
} 

