Megatron LM
NVIDIA Megatron Core 0.9.0
يتكون هذا المستودع من مكونين أساسيين: Megatron-LM و Megatron-Core . يعمل Megatron-LM كإطار عمل موجه نحو البحث يستفيد من Megatron-Core للتدريب على نماذج اللغة الكبيرة (LLM). من ناحية أخرى، تعد Megatron-Core مكتبة لتقنيات التدريب المحسنة لوحدة معالجة الرسومات والتي تأتي مع دعم رسمي للمنتج بما في ذلك واجهات برمجة التطبيقات ذات الإصدارات والإصدارات المنتظمة. يمكنك استخدام Megatron-Core جنبًا إلى جنب مع Megatron-LM أو Nvidia NeMo Framework للحصول على حل شامل وسحابي أصلي. وبدلاً من ذلك، يمكنك دمج وحدات بناء Megatron-Core في إطار التدريب المفضل لديك.
تم طرح ميجاترون (1 و2 و3) لأول مرة في عام 2019، وأثار موجة من الابتكار في مجتمع الذكاء الاصطناعي، مما مكن الباحثين والمطورين من الاستفادة من أسس هذه المكتبة لتعزيز التقدم في LLM. اليوم، تم استلهام العديد من أطر عمل مطوري LLM الأكثر شيوعًا من مكتبة Megatron-LM مفتوحة المصدر وتم بناؤها بشكل مباشر، مما أدى إلى تحفيز موجة من النماذج التأسيسية والشركات الناشئة في مجال الذكاء الاصطناعي. تتضمن بعض أطر عمل LLM الأكثر شيوعًا المبنية على Megatron-LM Colossal-AI وHuggingFace Accelerate وNVIDIA NeMo Framework. يمكن العثور على قائمة بالمشاريع التي استخدمت ميجاترون مباشرة هنا.
Megatron-Core هي مكتبة مفتوحة المصدر تعتمد على PyTorch وتحتوي على تقنيات مُحسّنة لوحدة معالجة الرسومات وتحسينات متطورة على مستوى النظام. فهو يلخصها في واجهات برمجة التطبيقات القابلة للتركيب والتركيب، مما يسمح بالمرونة الكاملة للمطورين والباحثين النموذجيين لتدريب المحولات المخصصة على نطاق واسع على البنية التحتية للحوسبة المتسارعة من NVIDIA. هذه المكتبة متوافقة مع جميع وحدات معالجة الرسوميات NVIDIA Tensor Core، بما في ذلك دعم تسريع FP8 لبنيات NVIDIA Hopper.
تقدم Megatron-Core كتل بناء أساسية مثل آليات الانتباه وكتل وطبقات المحولات وطبقات التطبيع وتقنيات التضمين. وظائف إضافية مثل إعادة حساب التنشيط ونقاط التفتيش الموزعة مدمجة أصلاً في المكتبة. تم تحسين جميع العناصر الأساسية والوظائف لوحدة معالجة الرسومات، ويمكن إنشاؤها باستخدام إستراتيجيات الموازاة المتقدمة لتحقيق سرعة التدريب المثلى والاستقرار على البنية التحتية للحوسبة المتسارعة من NVIDIA. يتضمن المكون الرئيسي الآخر لمكتبة Megatron-Core تقنيات توازي النماذج المتقدمة (الموتر، والتسلسل، وخطوط الأنابيب، والسياق، وتوازي خبراء وزارة البيئة).
يمكن استخدام Megatron-Core مع NVIDIA NeMo، وهي منصة ذكاء اصطناعي على مستوى المؤسسات. وبدلاً من ذلك، يمكنك استكشاف Megatron-Core باستخدام حلقة تدريب PyTorch الأصلية هنا. تفضل بزيارة وثائق Megatron-Core لمعرفة المزيد.
قاعدة التعليمات البرمجية الخاصة بنا قادرة على تدريب نماذج اللغات الكبيرة بكفاءة (أي النماذج التي تحتوي على مئات المليارات من المعلمات) مع توازي النماذج والبيانات. لتوضيح كيفية توسعة برنامجنا مع وحدات معالجة الرسومات وأحجام النماذج المتعددة، فإننا نأخذ في الاعتبار نماذج GPT التي تتراوح من 2 مليار معلمة إلى 462 مليار معلمة. تستخدم جميع النماذج حجم مفردات يبلغ 131.072 وطول تسلسل يبلغ 4096. ونقوم بتغيير الحجم المخفي وعدد رؤوس الانتباه وعدد الطبقات للوصول إلى حجم نموذج محدد. مع زيادة حجم النموذج، نقوم أيضًا بزيادة حجم الدفعة بشكل متواضع. تستخدم تجاربنا ما يصل إلى 6144 وحدة معالجة رسوميات H100. نقوم بإجراء تداخل دقيق للبيانات المتوازية ( --overlap-grad-reduce --overlap-param-gather ) والموتر الموازي ( --tp-comm-overlap ) والاتصال المتوازي لخطوط الأنابيب (ممكّن افتراضيًا) مع الحساب لتحسين قابلية التوسع. يتم قياس الإنتاجية المبلغ عنها للتدريب الشامل وتتضمن جميع العمليات بما في ذلك تحميل البيانات وخطوات المحسن والاتصال وحتى التسجيل. لاحظ أننا لم ندرب هذه النماذج على التقارب.
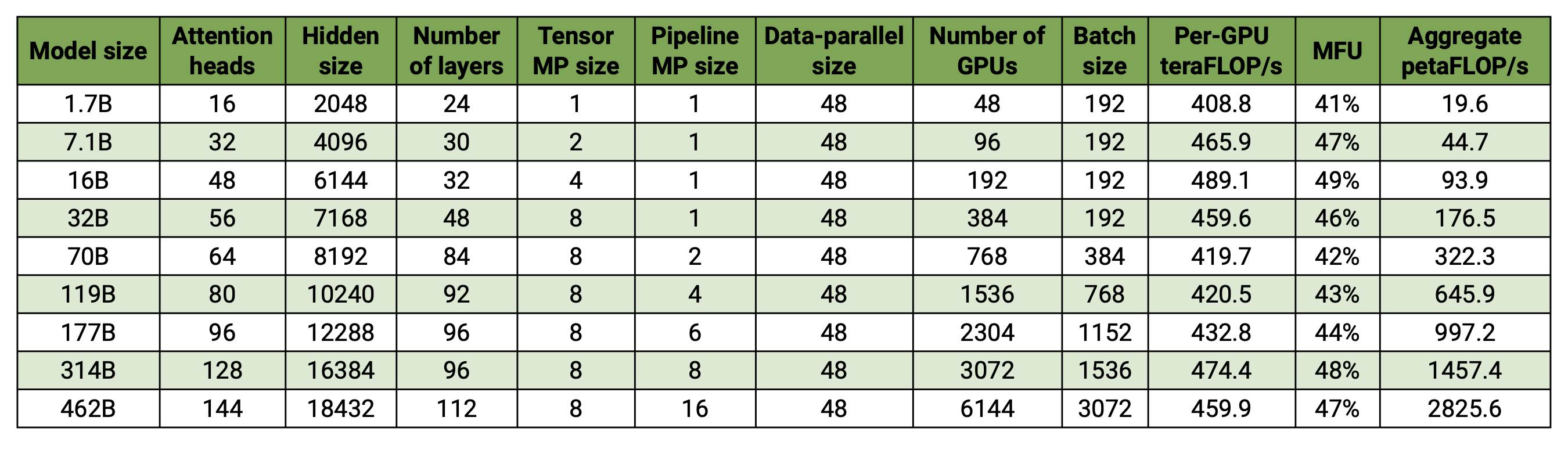
تُظهر نتائجنا ذات القياس الضعيف تحجيمًا خطيًا فائقًا (يزيد MFU من 41% لأصغر نموذج يتم اعتباره إلى 47-48% لأكبر النماذج)؛ وذلك لأن وحدات GEMM الأكبر حجمًا تتمتع بكثافة حسابية أعلى وبالتالي تكون أكثر كفاءة في التنفيذ.
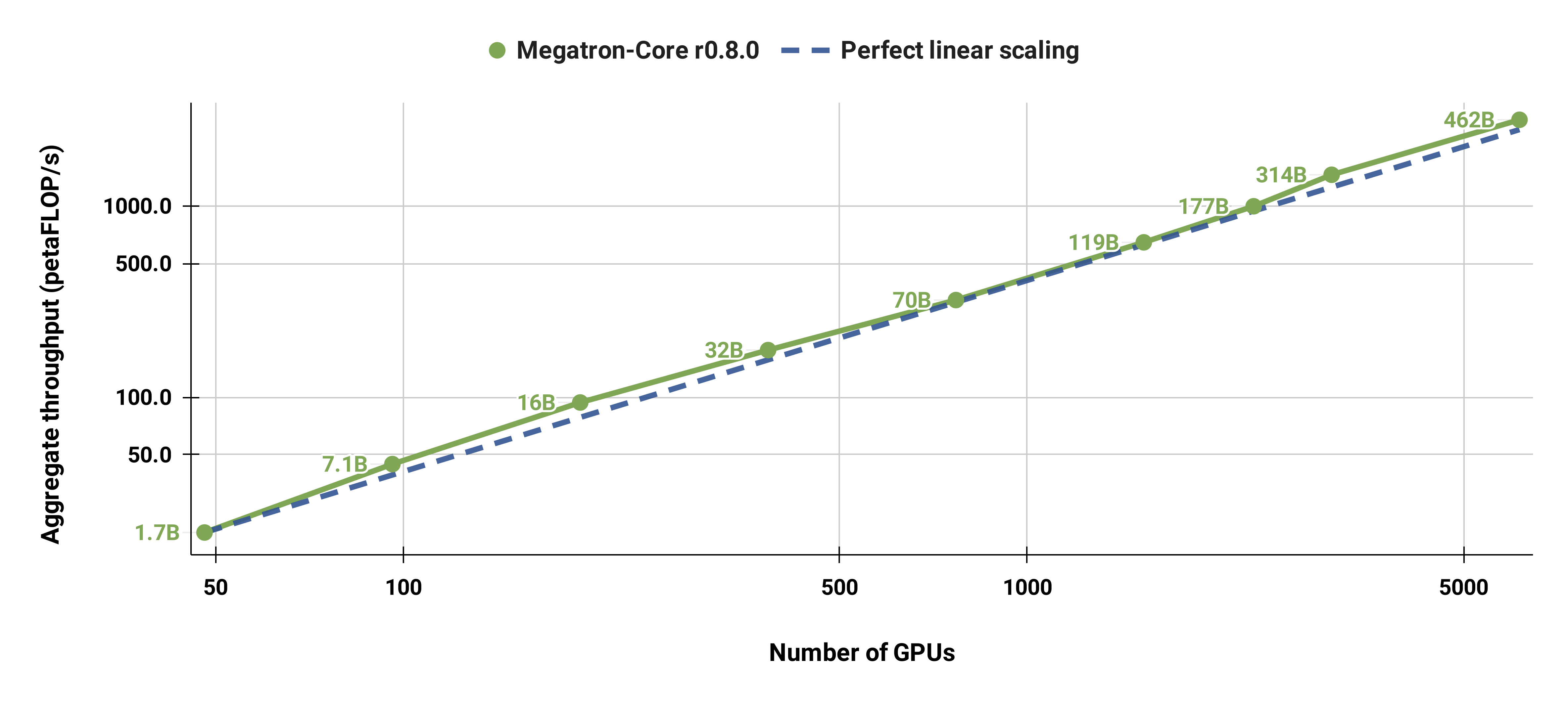
لقد قمنا أيضًا بتوسيع نطاق نموذج GPT-3 القياسي (يحتوي إصدارنا على ما يزيد قليلاً عن 175 مليار معلمة بسبب حجم المفردات الأكبر) من 96 وحدة معالجة رسوميات H100 إلى 4608 وحدة معالجة رسوميات، باستخدام نفس حجم الدفعة المكون من 1152 تسلسلًا طوال الوقت. يصبح الاتصال أكثر تعرضًا على نطاق أوسع، مما يؤدي إلى انخفاض في MFU من 47% إلى 42%.
نوصي بشدة باستخدام الإصدار الأحدث من حاوية PyTorch الخاصة بـ NGC مع عقد DGX. إذا لم تتمكن من استخدام هذا لسبب ما، فاستخدم أحدث إصدارات pytorch وcuda وnccl وNVIDIA APEX. تتطلب المعالجة المسبقة للبيانات NLTK، على الرغم من أن هذا ليس مطلوبًا للتدريب أو التقييم أو المهام النهائية.
يمكنك تشغيل مثيل لحاوية PyTorch وتركيب Megatron ومجموعة البيانات ونقاط التفتيش باستخدام أوامر Docker التالية:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
لقد قدمنا نقاط تفتيش BERT-345M وGPT-345M مُدربة مسبقًا لتقييم أو ضبط المهام النهائية. للوصول إلى نقاط التحقق هذه، قم أولاً بالتسجيل في NVIDIA GPU Cloud (NGC) Registry CLI وإعداده. يمكن العثور على مزيد من الوثائق لتنزيل النماذج في وثائق NGC.
وبدلاً من ذلك، يمكنك تنزيل نقاط التفتيش مباشرةً باستخدام:
BERT-345M-uncased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
تتطلب النماذج ملفات المفردات لتشغيلها. يمكن استخراج ملف BERT WordPiece vocab من نماذج BERT المدربة مسبقًا من Google: uncased، cased. يمكن تنزيل ملف GPT vocab وجدول الدمج مباشرة.
بعد التثبيت، هناك العديد من مسارات العمل الممكنة. والأكثر شمولاً هو:
ومع ذلك، يمكن استبدال الخطوتين 1 و2 باستخدام أحد النماذج المدربة مسبقًا المذكورة أعلاه.
لقد قدمنا العديد من البرامج النصية للتدريب المسبق لكل من BERT وGPT في دليل examples ، بالإضافة إلى البرامج النصية لكل من المهام الصفرية والمهام النهائية المضبوطة بدقة بما في ذلك تقييم MNLI وRACE وWikiText103 وLAMBADA. يوجد أيضًا برنامج نصي لإنشاء نص تفاعلي لـ GPT.
تتطلب بيانات التدريب المعالجة المسبقة. أولاً، ضع بيانات التدريب الخاصة بك بتنسيق json فضفاض، بحيث يحتوي json واحد على عينة نصية في كل سطر. على سبيل المثال:
{"src": "www.nvidia.com"، "text": "الثعلب البني السريع"، "type": "Eng"، "id": "0"، "title": "الجزء الأول"}
{"src": "الإنترنت"، "text": "يقفز فوق الكلب الكسول"، "type": "Eng"، "id": "42"، "title": "الجزء الثاني"}
يمكن تغيير اسم حقل text الخاص بـ json باستخدام علامة --json-key في preprocess_data.py أما البيانات التعريفية الأخرى فهي اختيارية ولا يتم استخدامها في التدريب.
تتم بعد ذلك معالجة ملف json السائب إلى تنسيق ثنائي للتدريب. لتحويل json إلى تنسيق mmap، استخدم preprocess_data.py . مثال على البرنامج النصي لإعداد البيانات لتدريب BERT هو:
أدوات بايثون/preprocess_data.py
--إدخال my-corpus.json
--بادئة الإخراج ماي بيرت
--vocab-ملف bert-vocab.txt
--رمز مميز من نوع BertWordPieceLowerCase
--تقسيم الجمل
سيكون الناتج عبارة عن ملفين، في هذه الحالة، my-bert_text_sentence.bin و my-bert_text_sentence.idx . --data-path المحدد في تدريب BERT اللاحق هو المسار الكامل واسم الملف الجديد، ولكن بدون امتداد الملف.
بالنسبة إلى T5، استخدم نفس المعالجة المسبقة مثل BERT، وربما قم بإعادة تسميته إلى:
--بادئة الإخراج my-t5
يلزم إجراء بعض التعديلات الطفيفة للمعالجة المسبقة لبيانات GPT، وهي إضافة جدول دمج ورمز مميز لنهاية المستند وإزالة تقسيم الجملة وتغيير نوع الرمز المميز:
أدوات بايثون/preprocess_data.py
--إدخال my-corpus.json
--بادئة الإخراج my-gpt2
--ملف-vocab gpt2-vocab.json
--رمز مميز من نوع GPT2BPETokenizer
--دمج الملف gpt2-merges.txt
--append-eod
هنا تتم تسمية ملفات الإخراج باسم my-gpt2_text_document.bin و my-gpt2_text_document.idx . كما كان من قبل، في تدريب GPT، استخدم الاسم الأطول بدون الامتداد كـ --data-path .
تم توضيح المزيد من وسائط سطر الأوامر في الملف المصدر preprocess_data.py .
يقوم البرنامج النصي examples/bert/train_bert_340m_distributed.sh بتشغيل تدريب مسبق لمعلمة GPU 345M BERT واحدة. تصحيح الأخطاء هو الاستخدام الأساسي لتدريب GPU الفردي، حيث تم تحسين قاعدة التعليمات البرمجية ووسيطات سطر الأوامر للتدريب الموزع بشكل كبير. معظم الحجج واضحة إلى حد ما. افتراضيًا، يتضاءل معدل التعلم خطيًا عبر تكرارات التدريب بدءًا من --lr إلى الحد الأدنى الذي تم تعيينه بواسطة --min-lr عبر تكرارات --lr-decay-iters . يتم تحديد جزء تكرارات التدريب المستخدمة للإحماء بواسطة --lr-warmup-fraction . على الرغم من أن هذا تدريب فردي لوحدة معالجة الرسومات، فإن حجم الدُفعة المحدد بواسطة --micro-batch-size هو حجم دفعة مسار واحد للأمام والخلف وسيقوم الكود بتنفيذ خطوات تراكم متدرجة حتى يصل إلى global-batch-size وهو حجم الدُفعة لكل التكرار. يتم تقسيم البيانات إلى نسبة 949:50:1 لمجموعات التدريب/التحقق من الصحة/الاختبار (الافتراضي هو 969:30:1). يحدث هذا التقسيم سريعًا، ولكنه يكون متسقًا عبر عمليات التشغيل باستخدام نفس البذرة العشوائية (1234 افتراضيًا، أو يتم تحديده يدويًا باستخدام --seed ). نحن نستخدم train-iters حسب تكرارات التدريب المطلوبة. وبدلاً من ذلك، يمكن للمرء توفير --train-samples وهو العدد الإجمالي للعينات التي سيتم التدريب عليها. إذا كان هذا الخيار موجودًا، فبدلاً من توفير --lr-decay-iters ، سيحتاج المرء إلى توفير --lr-decay-samples .
يتم تحديد خيارات التسجيل وحفظ نقطة التفتيش والفاصل الزمني للتقييم. لاحظ أن --data-path يتضمن الآن لاحقة _text_sentence الإضافية التي تمت إضافتها في المعالجة المسبقة، ولكنه لا يتضمن امتدادات الملفات.
تم توضيح المزيد من وسائط سطر الأوامر في الملف المصدر arguments.py .py .
لتشغيل train_bert_340m_distributed.sh ، قم بإجراء أي تعديلات مطلوبة بما في ذلك تعيين متغيرات البيئة لـ CHECKPOINT_PATH و VOCAB_FILE و DATA_PATH . تأكد من ضبط هذه المتغيرات على مساراتها في الحاوية. ثم قم بتشغيل الحاوية مع Megatron والمسارات الضرورية المثبتة (كما هو موضح في الإعداد) وقم بتشغيل البرنامج النصي النموذجي.
يقوم البرنامج النصي examples/gpt3/train_gpt3_175b_distributed.sh بتشغيل تدريب مسبق لمعلمة GPU 345M GPT واحدة. كما هو مذكور أعلاه، يهدف تدريب GPU الفردي في المقام الأول إلى أغراض تصحيح الأخطاء، حيث تم تحسين التعليمات البرمجية للتدريب الموزع.
وهو يتبع إلى حد كبير نفس تنسيق البرنامج النصي BERT السابق مع بعض الاختلافات الملحوظة: نظام الترميز المستخدم هو BPE (الذي يتطلب جدول دمج وملف مفردات json ) بدلاً من WordPiece، وتسمح بنية النموذج بتسلسلات أطول (لاحظ أن يجب أن يكون الحد الأقصى لتضمين الموضع أكبر من أو يساوي الحد الأقصى لطول التسلسل)، وتم ضبط --lr-decay-style على تسوس جيب التمام. لاحظ أن --data-path يتضمن الآن لاحقة _text_document الإضافية التي تمت إضافتها في المعالجة المسبقة، ولكنه لا يتضمن امتدادات الملفات.
تم توضيح المزيد من وسائط سطر الأوامر في الملف المصدر arguments.py .py .
يمكن إطلاق train_gpt3_175b_distributed.sh بنفس الطريقة الموضحة في BERT. قم بتعيين env vars وقم بإجراء أي تعديلات أخرى، وقم بتشغيل الحاوية بالتركيبات المناسبة، وقم بتشغيل البرنامج النصي. مزيد من التفاصيل في examples/gpt3/README.md
يشبه إلى حد كبير BERT وGPT، حيث يقوم البرنامج النصي examples/t5/train_t5_220m_distributed.sh بتشغيل تدريب مسبق T5 لوحدة معالجة الرسومات (معلمة ~ 220M). يتمثل الاختلاف الأساسي بين BERT وGPT في إضافة الوسيطات التالية لاستيعاب بنية T5:
--kv-channels تحدد البعد الداخلي لمصفوفات "المفتاح" و"القيمة" لجميع آليات الانتباه في النموذج. بالنسبة لـ BERT وGPT، يكون هذا افتراضيًا هو الحجم المخفي مقسومًا على عدد رؤوس الانتباه، ولكن يمكن تهيئته لـ T5.
--ffn-hidden-size يضبط الحجم المخفي في شبكات التغذية الأمامية داخل طبقة المحولات. بالنسبة لـ BERT وGPT، يكون هذا افتراضيًا 4 أضعاف الحجم المخفي للمحول، ولكن يمكن تهيئته لـ T5.
--encoder-seq-length و --decoder-seq-length يضبطان طول التسلسل لجهاز التشفير ووحدة فك التشفير بشكل منفصل.
تظل جميع الحجج الأخرى كما كانت بالنسبة للتدريب المسبق لـ BERT وGPT. قم بتشغيل هذا المثال بنفس الخطوات الموضحة أعلاه للبرامج النصية الأخرى.
مزيد من التفاصيل في examples/t5/README.md
تستخدم البرامج النصية pretrain_{bert,gpt,t5}_distributed.sh مشغل PyTorch الموزع للتدريب الموزع. على هذا النحو، يمكن تحقيق التدريب متعدد العقد من خلال ضبط متغيرات البيئة بشكل صحيح. راجع وثائق PyTorch الرسمية لمزيد من الوصف لمتغيرات البيئة هذه. بشكل افتراضي، يستخدم التدريب متعدد العقد الواجهة الخلفية الموزعة nccl. مجموعة بسيطة من الوسائط الإضافية واستخدام وحدة PyTorch الموزعة مع المشغل المرن torchrun (المكافئ لـ python -m torch.distributed.run ) هي المتطلبات الإضافية الوحيدة لاعتماد التدريب الموزع. راجع أيًا من pretrain_{bert,gpt,t5}_distributed.sh لمزيد من التفاصيل.
نستخدم نوعين من التوازي: توازي البيانات والنموذج. يتم تطبيق توازي البيانات الخاص بنا megatron/core/distributed ، ويدعم تداخل تقليل التدرج مع التمرير الخلفي عند استخدام خيار سطر الأوامر --overlap-grad-reduce .
ثانيًا، قمنا بتطوير نهج متوازي ثنائي الأبعاد بسيط وفعال. لاستخدام البعد الأول، توازي نموذج الموتر (تقسيم تنفيذ وحدة محول واحدة على وحدات معالجة رسوميات متعددة، راجع القسم 3 من ورقتنا)، أضف علامة --tensor-model-parallel-size لتحديد عدد وحدات معالجة الرسومات التي سيتم من بينها قم بتقسيم النموذج مع الوسيطات التي تم تمريرها إلى المشغل الموزع كما هو مذكور أعلاه. لاستخدام البعد الثاني، توازي التسلسل، حدد --sequence-parallel ، والذي يتطلب أيضًا تمكين توازي نموذج الموتر لأنه ينقسم عبر نفس وحدات معالجة الرسومات (مزيد من التفاصيل في القسم 4.2.2 من ورقتنا).
لاستخدام توازي نموذج خط الأنابيب (تقسيم وحدات المحولات إلى مراحل مع عدد متساو من وحدات المحولات في كل مرحلة، ثم تنفيذ خط الأنابيب عن طريق تقسيم الدفعة إلى دفعات صغيرة أصغر، راجع القسم 2.2 من ورقتنا)، استخدم --pipeline-model-parallel-size -علامة --pipeline-model-parallel-size لتحديد عدد المراحل التي سيتم تقسيم النموذج إليها (على سبيل المثال، تقسيم نموذج يحتوي على 24 طبقة محولات عبر 4 مراحل يعني أن كل مرحلة تحصل على 6 طبقات محولات لكل منها).
لدينا أمثلة لكيفية استخدام هذين النموذجين المختلفين من نموذج التوازي، الأمثلة النصية التي تنتهي بـ distributed_with_mp.sh .
وبخلاف هذه التغييرات الطفيفة، فإن التدريب الموزع مطابق للتدريب على وحدة معالجة رسومات واحدة.
يمكن تمكين جدول خطوط الأنابيب المتداخلة (مزيد من التفاصيل في القسم 2.2.2 من ورقتنا) باستخدام الوسيطة --num-layers-per-virtual-pipeline-stage ، التي تتحكم في عدد طبقات المحولات في المرحلة الافتراضية (افتراضيًا مع الجدول غير المشذر، ستنفذ كل وحدة معالجة رسومات مرحلة افتراضية واحدة باستخدام NUM_LAYERS / PIPELINE_MP_SIZE من طبقات المحولات). يجب أن يكون العدد الإجمالي للطبقات في نموذج المحول قابلاً للقسمة على قيمة الوسيطة هذه. بالإضافة إلى ذلك، يجب أن يكون عدد الدُفعات الصغيرة في التدفق (المحسوب كـ GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) قابلاً للقسمة على PIPELINE_MP_SIZE عند استخدام هذا الجدول (يتم تحديد هذا الشرط في تأكيد في التعليمات البرمجية). الجدول الزمني المشذّب غير مدعوم لخطوط الأنابيب ذات المرحلتين ( PIPELINE_MP_SIZE=2 ).
لتقليل استخدام ذاكرة وحدة معالجة الرسومات عند تدريب نموذج كبير، فإننا ندعم أشكالًا مختلفة من فحص التنشيط وإعادة الحساب. بدلاً من تخزين جميع عمليات التنشيط في الذاكرة لاستخدامها أثناء الدعم الخلفي، كما كان الحال تقليديًا في نماذج التعلم العميق، يتم الاحتفاظ (أو تخزينها) فقط في الذاكرة (أو تخزين) عمليات التنشيط عند "نقاط تفتيش" معينة في النموذج، ويتم إعادة حساب عمليات التنشيط الأخرى على -الذبابة عند الحاجة للدعامة الخلفية. لاحظ أن هذا النوع من فحص التحقق، أي فحص التنشيط ، يختلف تمامًا عن فحص معلمات النموذج وحالة المحسن، المذكورة في مكان آخر.
نحن ندعم مستويين من تفاصيل إعادة الحساب: selective full . تعتبر إعادة الحساب الانتقائية هي الإجراء الافتراضي ويوصى بها في جميع الحالات تقريبًا. يحتفظ هذا الوضع في الذاكرة بعمليات التنشيط التي تشغل مساحة تخزين أقل في الذاكرة وتكون إعادة حسابها أكثر تكلفة ويعيد حساب عمليات التنشيط التي تستهلك مساحة تخزين أكبر في الذاكرة ولكنها غير مكلفة نسبيًا لإعادة حسابها. انظر ورقتنا للحصول على التفاصيل. يجب أن تجد أن هذا الوضع يعمل على زيادة الأداء إلى الحد الأقصى مع تقليل الذاكرة المطلوبة لتخزين عمليات التنشيط. لتمكين إعادة حساب التنشيط الانتقائي، ما عليك سوى استخدام --recompute-activations .
بالنسبة للحالات التي تكون فيها الذاكرة محدودة للغاية، فإن عملية إعادة الحساب full تحفظ فقط المدخلات إلى طبقة المحولات، أو مجموعة، أو كتلة، من طبقات المحولات، وتعيد حساب كل شيء آخر. لتمكين التنشيط الكامل، استخدم إعادة الحساب --recompute-granularity full . عند استخدام إعادة حساب التنشيط full ، هناك طريقتان: uniform block ، يتم اختيارهما باستخدام الوسيطة --recompute-method .
تقسم الطريقة uniform طبقات المحول بشكل موحد إلى مجموعات من الطبقات (كل مجموعة ذات حجم --recompute-num-layers ) وتخزن تنشيطات الإدخال لكل مجموعة في الذاكرة. حجم المجموعة الأساسية هو 1، وفي هذه الحالة، يتم تخزين تنشيط الإدخال لكل طبقة محول. عندما تكون ذاكرة وحدة معالجة الرسومات غير كافية، فإن زيادة عدد الطبقات لكل مجموعة يقلل من استخدام الذاكرة، مما يتيح تدريب نموذج أكبر. على سبيل المثال، عند ضبط --recompute-num-layers على 4، يتم تخزين تنشيط الإدخال لكل مجموعة مكونة من 4 طبقات محولات فقط.
تقوم طريقة block بإعادة حساب عمليات تنشيط الإدخال لعدد محدد (مقدم بواسطة --recompute-num-layers ) لطبقات المحولات الفردية لكل مرحلة من مراحل خط الأنابيب وتخزن عمليات تنشيط الإدخال للطبقات المتبقية في مرحلة خط الأنابيب. يؤدي تقليل --recompute-num-layers إلى تخزين عمليات تنشيط الإدخال إلى المزيد من طبقات المحولات، مما يقلل من إعادة حساب التنشيط المطلوبة في الدعامة الخلفية، وبالتالي تحسين أداء التدريب مع زيادة استخدام الذاكرة. على سبيل المثال، عندما نحدد 5 طبقات لإعادة حساب 8 طبقات لكل مرحلة من مراحل خط الأنابيب، تتم إعادة حساب عمليات تنشيط الإدخال لطبقات المحولات الخمس الأولى فقط في خطوة الدعم الخلفي بينما يتم تخزين عمليات تنشيط الإدخال للطبقات الثلاث الأخيرة. --recompute-num-layers يمكن زيادتها بشكل تدريجي حتى تصبح مساحة تخزين الذاكرة المطلوبة صغيرة بما يكفي لتناسب الذاكرة المتوفرة، وبالتالي الاستفادة القصوى من الذاكرة وزيادة الأداء.
الاستخدام: --use-distributed-optimizer . متوافق مع كافة النماذج وأنواع البيانات.
المحسن الموزع هو تقنية لتوفير الذاكرة، حيث يتم توزيع حالة المحسن بالتساوي عبر صفوف متوازية للبيانات (مقابل الطريقة التقليدية لتكرار حالة المحسن عبر صفوف متوازية للبيانات). كما هو موضح في Zero: تحسينات الذاكرة نحو نماذج معلمات تريليونية للتدريب، يقوم تطبيقنا بتوزيع جميع حالات المُحسِّن التي لا تتداخل مع حالة النموذج. على سبيل المثال، عند استخدام معلمات نموذج fp16، يحتفظ المحسن الموزع بنسخته المنفصلة من معلمات وتدرجات fp32 الرئيسية، والتي يتم توزيعها عبر صفوف DP. ومع ذلك، عند استخدام معلمات نموذج bf16، تكون درجات fp32 الرئيسية للمُحسِّن الموزع هي نفس درجات fp32 للنموذج، وبالتالي لا يتم توزيع الدرجات في هذه الحالة (على الرغم من أن معلمات fp32 الرئيسية لا تزال موزعة، لأنها منفصلة عن bf16 المعلمات النموذجية).
يختلف التوفير النظري للذاكرة اعتمادًا على مجموعة النموذج Param dtype وgrad dtype. في تطبيقنا، يكون العدد النظري للبايتات لكل معلمة (حيث يكون "d" هو الحجم المتوازي للبيانات):
| الأمثل غير الموزع | الأمثل الموزعة | |
|---|---|---|
| FP16 بارام، FP16 الخريجين | 20 | 4+16/د |
| bf16 بارام، FP32 غراد | 18 | 6+12/د |
| FP32 بارام، FP32 غراد | 16 | 8+8/د |
كما هو الحال مع موازاة البيانات العادية، يمكن تسهيل تداخل تقليل التدرج (في هذه الحالة، تقليل التشتت) مع التمرير الخلفي باستخدام علامة --overlap-grad-reduce . بالإضافة إلى ذلك، يمكن أن يتداخل تداخل المعلمة all-gather مع التمريرة الأمامية باستخدام --overlap-param-gather .
الاستخدام: --use-flash-attn . دعم أبعاد رأس الانتباه على الأكثر 128.
FlashAttention عبارة عن خوارزمية سريعة وفعالة في الذاكرة لحساب الانتباه الدقيق. فهو يسرع تدريب النموذج ويقلل من متطلبات الذاكرة.
لتثبيت FlashAttention:
pip install flash-attn في examples/gpt3/train_gpt3_175b_distributed.sh قدمنا مثالاً لكيفية تكوين Megatron لتدريب GPT-3 مع 175 مليار معلمة على 1024 وحدة معالجة رسوميات. تم تصميم البرنامج النصي من أجل slurm باستخدام البرنامج المساعد pyxis ولكن يمكن اعتماده بسهولة مع أي برنامج جدولة آخر. يستخدم توازي موتر ذو 8 اتجاهات وتوازي خط أنابيب ذو 16 اتجاهًا. من خلال الخيارات global-batch-size 1536 و rampup-batch-size 16 16 5859375 ، سيبدأ التدريب بحجم الدفعة العالمي 16 وسيزيد حجم الدفعة العالمي خطيًا إلى 1536 على 5,859,375 عينة بخطوات تدريجية 16. يمكن أن تكون مجموعة بيانات التدريب إما مجموعة واحدة أو مجموعات بيانات متعددة مدمجة مع مجموعة من الأوزان.
مع حجم الدفعة العالمية الكاملة البالغ 1536 على 1024 وحدة معالجة رسوميات A100، يستغرق كل تكرار حوالي 32 ثانية مما يؤدي إلى 138 تيرا فلوب لكل وحدة معالجة رسومات، وهو ما يمثل 44% من ذروة FLOPs النظرية.
Retro (Borgeaud et al., 2022) هو نموذج لغة لوحدة فك ترميز الانحدار الذاتي فقط (LM) تم تدريبه مسبقًا مع زيادة الاسترجاع. يتميز Retro بقابلية التوسع العملية لدعم التدريب المسبق على نطاق واسع من الصفر عن طريق الاسترجاع من تريليونات الرموز المميزة. يوفر التدريب المسبق مع الاسترجاع آلية تخزين أكثر كفاءة للمعرفة الواقعية، عند مقارنتها بتخزين المعرفة الواقعية ضمنيًا ضمن معلمات الشبكة، وبالتالي تقليل معلمات النموذج إلى حد كبير مع تحقيق درجة أقل من الحيرة من GPT القياسي. يوفر Retro أيضًا المرونة لتحديث المعرفة المخزنة في LMs (Wang et al., 2023a) عن طريق تحديث قاعدة بيانات الاسترجاع دون تدريب LMs مرة أخرى.
يقوم InstructRetro (Wang et al., 2023b) بتوسيع حجم Retro إلى 48B، ويضم أكبر LLM تم تدريبه مسبقًا مع الاسترجاع (اعتبارًا من ديسمبر 2023). يتفوق نموذج الأساس الذي تم الحصول عليه، Retro 48B، إلى حد كبير على نظير GPT من حيث الحيرة. من خلال ضبط التعليمات على Retro، يُظهر InstructRetro تحسنًا كبيرًا مقارنة بالتعليمات التي تم ضبطها على GPT في المهام النهائية في إعداد اللقطة الصفرية. على وجه التحديد، يبلغ متوسط التحسن في InstructRetro 7% مقارنة بنظيره في GPT عبر 8 مهام ضمان الجودة القصيرة، و10% مقارنة بـ GPT عبر 4 مهام ضمان الجودة الطويلة الصعبة. نجد أيضًا أنه يمكن للمرء استئصال برنامج التشفير من بنية InstructRetro واستخدام العمود الفقري لوحدة فك ترميز InstructRetro مباشرةً كـ GPT، مع تحقيق نتائج قابلة للمقارنة.
في هذا الريبو، نقدم دليل إعادة إنتاج شامل لتنفيذ تغطية Retro وInstructRetro
راجع أدوات/retro/README.md للحصول على نظرة عامة مفصلة.
انظر الأمثلة/مامبا للحصول على التفاصيل.
نحن نقدم العديد من وسائط سطر الأوامر، المفصلة في البرامج النصية المدرجة أدناه، للتعامل مع العديد من المهام النهائية والمضبوطة بدقة. ومع ذلك، يمكنك أيضًا ضبط النموذج الخاص بك من نقطة تفتيش مُدربة مسبقًا على مجموعات أخرى حسب الرغبة. للقيام بذلك، ما عليك سوى إضافة علامة --finetune وضبط ملفات الإدخال ومعلمات التدريب داخل البرنامج النصي للتدريب الأصلي. ستتم إعادة تعيين عدد التكرارات إلى الصفر، وستتم إعادة تهيئة المُحسِّن والحالة الداخلية. إذا تمت مقاطعة الضبط الدقيق لأي سبب من الأسباب، فتأكد من إزالة علامة --finetune قبل المتابعة، وإلا فسيبدأ التدريب مرة أخرى من البداية.
نظرًا لأن التقييم يتطلب ذاكرة أقل بكثير من التدريب، فقد يكون من المفيد دمج نموذج تم تدريبه بالتوازي لاستخدامه على عدد أقل من وحدات معالجة الرسومات في المهام النهائية. البرنامج النصي التالي ينجز هذا. يقرأ هذا المثال في نموذج GPT مع موتر رباعي الاتجاه وتوازي نموذج خط أنابيب رباعي الاتجاه ويكتب نموذجًا بموتر ثنائي الاتجاه وتوازي نموذج خط أنابيب ثنائي الاتجاه.
أدوات بايثون/checkpoint/convert.py
--نموذج من نوع GPT
--load-dir نقاط التفتيش/gpt3_tp4_pp4
--save-dir نقاط التفتيش/gpt3_tp2_pp2
--الهدف-الموتر-الحجم الموازي 2
- خط الأنابيب المستهدف - الحجم الموازي 2
تم توضيح العديد من المهام النهائية لكل من طرازي GPT وBERT أدناه. يمكن تشغيلها في أوضاع موزعة ومتوازية مع نفس التغييرات المستخدمة في البرامج النصية للتدريب.
لقد قمنا بتضمين خادم REST بسيط لاستخدامه في إنشاء النص في tools/run_text_generation_server.py . يمكنك تشغيله كما لو كنت تبدأ مهمة تدريب مسبق، مع تحديد نقطة تفتيش مناسبة تم تدريبها مسبقًا. هناك أيضًا عدد قليل من المعلمات الاختيارية: temperature ، top-k ، و top-p . راجع --help أو الملف المصدر لمزيد من المعلومات. راجع الأمثلة/inference/run_text_generation_server_345M.sh للحصول على مثال لكيفية تشغيل الخادم.
بمجرد تشغيل الخادم، يمكنك استخدام tools/text_generation_cli.py للاستعلام عنه، ويستغرق الأمر وسيطة واحدة وهي المضيف الذي يعمل عليه الخادم.
الأدوات/text_generation_cli.py المضيف المحلي:5000
يمكنك أيضًا استخدام CURL أو أي أدوات أخرى للاستعلام عن الخادم مباشرةً:
حليقة 'http://localhost:5000/api' -X 'PUT' -H 'نوع المحتوى: application/json; charset=UTF-8' -d '{"prompts":["Hello World"], "tokens_to_generate":1}'
راجع megatron/inference/text_generation_server.py لمزيد من خيارات واجهة برمجة التطبيقات.
قمنا بتضمين مثال في examples/academic_paper_scripts/detxoify_lm/ لإزالة السموم من نماذج اللغة من خلال الاستفادة من القوة التوليدية لنماذج اللغة.
راجع الأمثلة/academic_paper_scripts/detxoify_lm/README.md للحصول على برامج تعليمية خطوة بخطوة حول كيفية إجراء التدريب على التكيف مع المجال وإزالة السموم من LM باستخدام المجموعة المولدة ذاتيًا.
نقوم بتضمين أمثلة على البرامج النصية لتقييم GPT على تقييم حيرة WikiText ودقة LAMBADA Cloze.
حتى للمقارنة مع الأعمال السابقة، نقوم بتقييم الحيرة على مجموعة بيانات اختبار WikiText-103 على مستوى الكلمة، وحساب الحيرة بشكل مناسب بالنظر إلى التغيير في الرموز المميزة عند استخدام مُرمز الكلمات الفرعية الخاص بنا.
نستخدم الأمر التالي لتشغيل تقييم WikiText-103 على نموذج معلمة 345M.
المهمة = "WIKITEXT103"
VALID_DATA=<مسار نص الويكي>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=نقاط التفتيش/gpt2_345m
COMMON_TASK_ARGS="--عدد الطبقات 24
--الحجم المخفي 1024
--عدد الرؤوس 16
--الطول التسلسلي 1024
--أقصى موضع للتضمين 1024
--fp16
--ملف vocab $VOCAB_FILE"
مهام بايثون/main.py
--المهمة $TASK
$COMMON_TASK_ARGS
--بيانات صالحة $VALID_DATA
--رمز مميز من نوع GPT2BPETokenizer
--دمج الملف $MERGE_FILE
--تحميل $CHECKPOINT_PATH
--حجم الدفعة الصغيرة 8
--فاصل السجل 10
--عدم التحميل الأمثل
--no-load-rng
لحساب دقة إغلاق LAMBADA (دقة التنبؤ بالرمز الأخير بالنظر إلى الرموز المميزة السابقة)، نستخدم نسخة مُعالجة ومُزيلة الترميز من مجموعة بيانات LAMBADA.
نستخدم الأمر التالي لتشغيل تقييم LAMBADA على نموذج معلمة 345M. لاحظ أنه يجب استخدام علامة --strict-lambada لطلب مطابقة الكلمات بالكامل. تأكد من أن lambada جزء من مسار الملف.
المهمة = "لامبادا"
VALID_DATA=<مسار لامبادا>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=نقاط التفتيش/gpt2_345m
COMMON_TASK_ARGS=<مثل تلك الموجودة في تقييم ارتباك نص Wiki أعلاه>
مهام بايثون/main.py
--المهمة $TASK
$COMMON_TASK_ARGS
--بيانات صالحة $VALID_DATA
--رمز مميز من نوع GPT2BPETokenizer
--صارم لامبادا
--دمج الملف $MERGE_FILE
--تحميل $CHECKPOINT_PATH
--حجم الدفعة الصغيرة 8
--فاصل السجل 10
--عدم التحميل الأمثل
--no-load-rng
تم توضيح المزيد من وسائط سطر الأوامر في الملف المصدر main.py
يقوم البرنامج النصي التالي بضبط نموذج BERT للتقييم على مجموعة بيانات RACE. يحتوي دليل TRAIN_DATA و VALID_DATA على مجموعة بيانات RACE كملفات .txt منفصلة. لاحظ أنه بالنسبة لـ RACE، فإن حجم الدُفعة هو عدد استعلام RACE المطلوب تقييمه. نظرًا لأن كل استعلام RACE يحتوي على أربع عينات، فإن حجم الدُفعة الفعال الذي تم تمريره عبر النموذج سيكون أربعة أضعاف حجم الدُفعة المحدد في سطر الأوامر.
TRAIN_DATA="البيانات/السباق/القطار/الوسط"
VALID_DATA="data/RACE/dev/middle
البيانات/السباق/ديف/عالية"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=نقاط التفتيش/bert_345m
CHECKPOINT_PATH=checkpoints/bert_345m_race
COMMON_TASK_ARGS="--عدد الطبقات 24
--الحجم المخفي 1024
--عدد الرؤوس 16
--الطول التسلسلي 512
--أقصى موضع للتضمين 512
--fp16
--ملف vocab $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--بيانات القطار $TRAIN_DATA
--بيانات صالحة $VALID_DATA
--نقطة تفتيش مدربة مسبقًا $PRETRAINED_CHECKPOINT
--فاصل الحفظ 10000
--احفظ $CHECKPOINT_PATH
--الفاصل الزمني للسجل 100
--الفاصل الزمني 1000
--التقييم 10
- اضمحلال الوزن 1.0e-1"
مهام بايثون/main.py
--سباق المهام
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--رمز مميز من نوع BertWordPieceLowerCase
--العصور 3
--حجم الدفعة الصغيرة 4
--lr 1.0e-5
--lr-warmup-fraction 0.06
يقوم البرنامج النصي التالي بضبط نموذج BERT للتقييم باستخدام مجموعة أزواج الجمل MultiNLI. نظرًا لأن المهام المطابقة متشابهة تمامًا ، يمكن تعديل البرنامج النصي بسرعة للعمل مع مجموعة بيانات أزواج أسئلة Quora (QQP) أيضًا.
Train_data = "Data/Glue_data/mnli/train.tsv"
alight_data = "data/glue_data/mnli/dev_matched.tsv
البيانات/glue_data/mnli/dev_mishatched.tsv "
pretRained_CheckPoint = نقاط التفتيش/Bert_345m
vocab_file = bert-vocab.txt
checkpoint_path = نقاط التفتيش/bert_345m_mnli
common_task_args = <مثل تلك الموجودة في تقييم العرق أعلاه>
common_task_args_ext = <نفس تلك الموجودة في تقييم العرق أعلاه>
مهام بيثون/main.py
-المهام mnli
$ common_task_args
$ common_task_args_ext
-Tokenizer-Type BertwordpieCelowercase
-epochs 5
-Micro-Patch-Size 8
-LR 5.0E-5
-lr-warmup-fraction 0.065
تعد عائلة LLAMA-2 من النماذج مجموعة مفتوحة المصدر من نماذج المسبقة والمبادرة (للدردشة) التي حققت نتائج قوية عبر مجموعة واسعة من المعايير. في وقت الإصدار ، تم تحقيق نماذج LLAMA-2 من بين أفضل النتائج لنماذج المصدر المفتوح ، وكانت تنافسية مع نموذج GPT-3.5 مغلق (انظر https://arxiv.org/pdf/2307.09288.pdf).
يمكن تحميل نقاط التفتيش LLAMA-2 في Megatron من أجل الاستدلال والاستعادة. انظر الوثائق هنا.
تدعم عائلة GPTModel Megatron-Core خوارزميات القياس المتقدم والاستدلال عالي الأداء من خلال Tensorrt-LLM.
شاهد تحسين نموذج Megatron ونشره لأمثلة llama2 و nemotron3 .
نحن لا نستضيف أي مجموعات بيانات لتدريب GPT أو BERT ، ومع ذلك ، فإننا نتفصل عن مجموعتها حتى يتم استنساخ نتائجنا.
نوصي باتباع عملية استخراج بيانات Wikipedia المحددة بواسطة Google Research: "المعالجة المسبقة الموصى بها هي تنزيل أحدث تفريغ ، واستخراج النص باستخدام wikiextractor.py ، ثم تطبيق أي تنظيف ضروري لتحويله إلى نص عادي."
نوصي باستخدام وسيطة --json عند استخدام Wikiextractor ، والتي ستقوم بإلقاء بيانات Wikipedia في تنسيق JSON فضفاض (كائن JSON واحد لكل سطر) ، مما يجعله أكثر قابلية للإدارة على نظام الملفات وأيضًا قابلاً للاستهلاك بواسطة Codebase الخاص بنا. نوصي بمزيد من المعالجة المسبقة لمجموعة بيانات JSON هذه مع توحيد علامات الترقيم NLTK. لتدريب Bert ، استخدم علامة- --split-sentences إلى preprocess_data.py كما هو موضح أعلاه لتشمل فترات راحة الجملة في الفهرس المنتجة. إذا كنت ترغب في استخدام بيانات Wikipedia لتدريب GPT ، فلا يزال بإمكانك تنظيفها باستخدام NLTK/Spacy/FTFY ، ولكن لا تستخدم علامة- --split-sentences .
نحن نستخدم مكتبة OpenWebText المتاحة للجمهور من عمل Jcpeterson و Eukaryote31 لتنزيل عناوين URL. نرشح بعد ذلك ، وننظف ، ونؤسس جميع المحتوى الذي تم تنزيله وفقًا للإجراء الموضح في دليل OpenWebText الخاص بنا. بالنسبة إلى Reddit urls المقابلة للمحتوى حتى أكتوبر 2018 ، وصلنا إلى حوالي 37 جيجابايت من المحتوى.
يمكن أن يكون التدريب Megatron مستنسخًا ؛ لتمكين هذا الوضع استخدام --deterministic-mode . هذا يعني أن نفس التكوين التدريبي الذي يتم تشغيله مرتين في نفس بيئة HW و SW يجب أن ينتج نقاط تفتيش نموذج متطابقة وخسائر وقيم مترية الدقة (قد تختلف مقاييس وقت التكرار).
يوجد حاليًا ثلاثة تحسينات معروفة ميغاترون التي تنهار مع استنساخ بينما لا تزال تنتج تدريبًا متطابقًا تقريبًا:
NCCL_ALGO ). لقد اختبرنا ما يلي: ^NVLS ، Tree ، Ring ، CollnetDirect ، CollnetChain . يعترف الرمز باستخدام ^NVLS ، والذي يسمح لـ NCCL باختيار خوارزميات غير NVLS ؛ يبدو أن اختياره مستقر.--use-flash-attn .NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 .بالإضافة إلى ذلك ، تم التحقق من interminisim فقط في حاويات NGC Pytorch حتى الأحدث من 23.12. إذا لاحظت nondeterminism في تدريب Megatron في ظل ظروف أخرى ، فيرجى فتح مشكلة.
فيما يلي بعض المشاريع التي استخدمنا فيها مباشرة Megatron:


