بقلم بوكيان تشنغ (بوكيانز) ويونغ كانغ هوانغ (يونغكان 1)
ملصق
قمنا بتنفيذ Corgy، وهو إطار عمل للتعلم العميق بلغة Swift وMetal. يمكن تضمين Corgy في كل من تطبيقات macOS وiOS واستخدامه لإنشاء شبكات عصبية مدربة وتقييمها بسهولة. لقد حققنا سرعة تزيد عن 60 مرة على أجهزة مختلفة ذات وحدات معالجة رسومات مختلفة.

إطار عمل Metal 2 عبارة عن واجهة مقدمة من Apple توفر وصولاً شبه مباشر إلى وحدة معالجة الرسومات (GPU) على iPhone/iPad وMac. إلى جانب الرسومات، قام Metal 2 بدمج مجموعة من المكتبات التي توفر دعمًا متوازيًا ممتازًا لعمليات الجبر الخطي الضرورية ووظائف معالجة الإشارات القادرة على العمل في أنواع مختلفة من أجهزة Apple. أتاحت لنا هذه المكتبات إنشاء نماذج تعلم عميق مُسرَّعة بوحدة معالجة الرسومات (GPU) جيدة التنفيذ على أجهزة iOS استنادًا إلى النموذج المُدرب المقدم من أطر العمل الأخرى. 1
بشكل عام، مرحلة الاستدلال للشبكة العصبية المدربة تتطلب عمليات حسابية مكثفة للغاية، خاصة بالنسبة لتلك النماذج التي تحتوي على عدد كبير جدًا من الطبقات أو المطبقة في السيناريوهات الضرورية لمعالجة الصور عالية الدقة. تجدر الإشارة إلى أن هناك قدرًا هائلاً من حسابات المصفوفة (مثل الطبقة التلافيفية) المناسبة لتطبيق عملية متوازية لتحسين الأداء.
التحدي الأول الذي واجهناه هو تصميم تجريد جيد لواجهة برمجة التطبيقات التي تكون معبرة وسهلة الاستخدام مع منحنى التعلم المنخفض الذي يسهل على مستخدمينا استخدامه.
خلال عملية التطوير بأكملها، بذلنا قصارى جهدنا للحفاظ على واجهة برمجة التطبيقات العامة بسيطة قدر الإمكان، مع توفير جميع الخصائص الضرورية لإنشاء كل مكون مطلوب من خلال الاستفادة من آلية البرمجة الوظيفية التي توفرها Swift. لقد قمنا أيضًا بإخفاء تجريد الأجهزة غير الضروري الذي توفره شركة Metal عن عمد لتسهيل منحنى التعلم.
على الرغم من أنه من السهل الحصول على النموذج المُدرب للشبكات المختلفة على الإنترنت، إلا أن عدم التجانس بينها الناتج عن التنفيذ المختلف لتطبيق أنواع مختلفة من الأدوات أدى إلى إنشاء مستورد نموذج عالمي.
من السهل فهم بعض العمليات الحسابية من خلال تصورها ولكنها تتطلب تفكيرًا يقظًا عندما تريد إنشاء تطبيق فعال عن طريق تلخيصها. الالتواء هو مثال تمثيلي.
الخاصية الجوهرية لعملية الالتواء لا تتمتع بموقع جيد، ومن الصعب فهم تنفيذ الفانيليا وغير فعال مع حلقات for المعقدة. نحتاج أيضًا إلى النظر في التجريد الذي يقدمه Metal 2 وإنشاء طريقة ملائمة لمشاركة المعلومات الضرورية وهياكل البيانات بين المضيف والجهاز مع دراسة متأنية لتمثيل البيانات وتخطيط الذاكرة.
خلال مرحلة التطوير، نحن نحرص على التعامل مع قدرة التعليمات البرمجية الخاصة بنا على العمل بشكل طبيعي على نظامي التشغيل macOS وiOS دون أي تنازل في الأداء على كلا النظامين الأساسيين. لقد بذلنا قصارى جهدنا للحفاظ على مكتبة التعليمات البرمجية القادرة على التجميع والتنفيذ في كلا النظامين الأساسيين. نحن حريصون على تعظيم الكود المشترك بين الأهداف المختلفة وإعادة استخدام الكود قدر الإمكان.
نظرًا لأن مكون طبقة الشبكة العصبية الذي تم تنفيذه بالكامل يجب أن يوفر الدعم بكمية معقولة من المعلمات التي تجعل المكون قابلاً للاستخدام بدرجة كافية، فإن تعقيد المكونات مثير للإعجاب بالفعل. على سبيل المثال، يجب أن تدعم الطبقة التلافيفية المعلمات التي تتضمن الحشو وخطوة التمدد وما إلى ذلك ويجب أخذها جميعًا في الاعتبار بحذر عند إجراء الموازاة التي تحقق أداءً معقولاً. قمنا ببناء بعض الشبكات البسيطة لإجراء اختبار الانحدار. يتم إنشاء حالات الاختبار في أطر عمل أخرى (PyTorch وKeras بشكل أساسي) للتأكد من أن كل عمليات التنفيذ تعمل بشكل صحيح.
تم تطوير Swift لأول مرة في يوليو 2010 وتم نشرها وأصبحت مفتوحة المصدر في عام 2014. على الرغم من مرور 4 سنوات تقريبًا على نشرها، إلا أن الافتقار إلى المكتبة المؤثرة لا يزال يمثل مشكلة لا يمكن تجاهلها. هناك سبب ما تسبب في هذه الحالة، وقد يكون الدور المهيمن لشركة Apple والطبيعة التكرارية السريعة لـ Swift هو السبب وراء هذه الظاهرة. بعض المكتبات المهمة بالنسبة لنا إما أنها ليست قوية أو فعالة بما يكفي لاحتياجاتنا، أو لا تتم صيانتها بشكل جيد من قبل المطور الفردي الذي اخترعها. لقد أمضينا الكثير من الوقت في تنفيذ فئة موتر جيدة الأداء Variable لتلبية متطلباتنا.
يعد هذا أيضًا سببًا آخر لعرقلة تطوير محلل نموذجي عالمي حيث أن وظيفة معالجة الملفات والسلاسل لها قدرة محدودة للغاية.
بالإضافة إلى ذلك، تقتصر أدوات التطوير وتصحيح الأخطاء بشكل أساسي على Xcode، على الرغم من وجود خيارات أخرى أكثر عمومية بالنسبة لنا، إلا أن Xcode لا يزال الأداة القياسية الفعلية لتطويرنا.
بالنسبة لضبط الأداء للأجهزة المحمولة، لا توفر Apple مواصفات الأجهزة التفصيلية لـ SoC الخاصة بها، ويتم استخدام الاسم التسويقي على نطاق واسع بواسطة الوسائط ومن الصعب استنتاج التأثير الدقيق لميزة معينة للأجهزة وضبط أداء التنفيذ. .
نحن نستخدم لغة برمجة سويفت وتحديداً Swift 4.2 وهي الأحدث حتى الآن؛ إطار عمل Metal 2 وبعض وظائف المكتبة التي يوفرها Metal Performance Shader (وظائف الجبر الخطي بشكل أساسي). على الرغم من أن Apple أطلقت CoreML SDK في ربيع 2017 والتي تضمنت بعض الدعم للشبكة العصبية التلافيفية، إلا أننا لا نستخدمها في Corgy لاكتساب خبرة لا تقدر بثمن في تطوير التنفيذ المتوازي لطبقات الشبكة وتوفير واجهات برمجة تطبيقات موجزة وبديهية مع سهولة الاستخدام الجيدة ومنحنى التعلم السلس للمستخدمين لترحيل نموذج من الأطر الأخرى دون عناء.
أجهزتنا المستهدفة هي جميع الأجهزة التي تعمل بنظامي macOS وiOS، مثل iMac وMacBook وiPhone وiPad. على وجه التحديد، الجهاز المزود بمنصة تدعم مكتبة الجبر الخطي MPS (أي بعد iOS 10.0 وmacOS 10.13)، مما يعني أن iPhone تم إطلاقه بعد iPhone 5، وتم إطلاق iPad بعد iPad (الجيل الرابع)، وiPod Touch (الجيل السادس) يتم دعمها كمنصة iOS. يحظى خط منتجات Mac بتغطية أوسع، بما في ذلك iMac الذي تم إنتاجه بعد أواخر عام 2009 أو الأحدث، وجميع سلسلة MacBook التي تم إطلاقها بعد منتصف عام 2010 وiMac Pro.
التجريد الموازي لـ Metal 2 متشابه إلى حد كبير مع CUDA: عند إرسال تمرير الكمبيوتر إلى GPU، سيكتب المبرمجون أولاً وظائف kernel التي سيتم تنفيذها بواسطة كل خيط، ثم يحددون عدد مجموعة الخيوط (المعروفة أيضًا باسم كتلة في CUDA) في الشبكة و عدد الخيوط في كل مجموعة خيوط، سيقوم Metal بتنفيذ النواة على هذه الشبكة، ويتم تنفيذ النواة بلغة C++ 14 تسمى لغة التظليل المعدنية. داخل كل مجموعة سلاسل، توجد وحدة أصغر تسمى مجموعة SIMD، وتعني مجموعة من سلاسل الرسائل التي تشترك في نفس تعليمات SIMD. ولكن في ظل تنفيذنا، ليست هناك حاجة للنظر في هذا.
يوفر Metal واجهة برمجة تطبيقات تسمى MTLCommandBuffer والتي تقوم بتخزين الأوامر المشفرة التي يتم الالتزام بها وتنفيذها بواسطة GPU. في كل مرة نرغب في إطلاق مهمة ليتم تنفيذها بواسطة GPU، سيتم تشفير وظائف kernel المترجمة مسبقًا في تعليمات GPU، ودمجها في خط أنابيب التظليل المعدني وإرسالها إلى MTLCommandBuffer. يتم أيضًا تعيين المخزن المؤقت المعدني المستخدم لتخزين معلمة الحساب التي يجب تمريرها إلى الجهاز في هذه المرحلة. بعد ذلك، مع وجود عدد محدد من مجموعات سلاسل الرسائل وسلاسل الرسائل لكل مجموعة، سيتم تشفير الأمر الذي يتم التعامل معه بواسطة مخزن الأوامر المؤقت بالكامل ويكون جاهزًا للالتزام بالجهاز. ستقوم وحدة معالجة الرسومات بجدولة المهمة وإخطار مؤشر ترابط وحدة المعالجة المركزية الذي يرسل العمل بعد انتهاء التنفيذ.
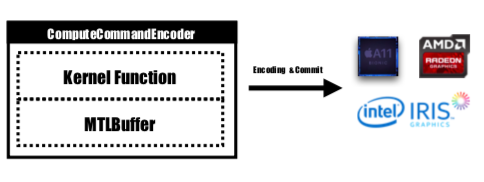
سيتم تشفير وظيفة kernel بواسطة MTLComputeCommandEncoder وسيتم إنشاء المهمة لجميع الأنظمة الأساسية المدعومة.
في تنفيذنا، استخدمنا على نطاق واسع طريقة بديهية لتعيين العنصر في سلاسل GPU: قم بتعيين كل عنصر في موتر الإخراج للطبقة الحالية إلى خيط GPU واحد: يحسب كل خيط ويحدث عنصرًا واحدًا بالضبط من الإخراج، وسيكون الإدخال للقراءة فقط، لذلك لا داعي للقلق بشأن المزامنة بين سلاسل الرسائل. ضمن هذا التعيين، قد تقرأ الخيوط ذات المعرفات المستمرة بيانات الإدخال من مواقع ذاكرة مختلفة ولكنها ستكتب دائمًا إلى مواقع الذاكرة المستمرة. لذلك لن تكون هناك عمليات مبعثرة عندما تقوم مجموعة SIMD بالكتابة إلى الذاكرة.
لقد صممنا فئة موتر Variable كأساس لكل عمليات التنفيذ، واستخدمنا عملية الجبر الخطي وقمنا بتغليفها في فئة Variable بدلاً من كتابة نواة إضافية للتعمق في العملية التي لا تركز بشكل أساسي على تقليل تعقيد التنفيذ وتوفير وقتنا للتركيز على تسريع طبقات الشبكة.
1. تغيير الإلتواء إلى ضرب المصفوفة العملاقة
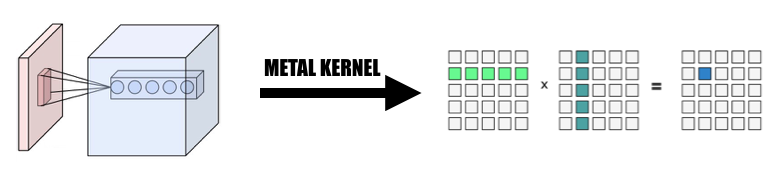
نقوم بجمع البيانات من المدخلات بطريقة متوازية لتشكيل مصفوفة عملاقة لكل من متغير الإدخال والوزن. نقوم بتخزين وزن كل طبقة تلافيفية لتجنب إعادة الحساب. سيتم إنشاء حشوة الطبقة التلافيفية أثناء تحويل التوازي أثناء الحساب، ثم نقوم باستدعاء MPSMatrixMultiply إلى المصفوفة العملاقة وتحويل البيانات من المصفوفة العملاقة مرة أخرى إلى فئة الموتر العادية التي أنشأناها. تم وصف الطريقة في شرائح الفصل.
2. تصميم وتنفيذ فئة المتغير
الفئة المتغيرة هي أساس تنفيذنا كتمثيل الموتر. لقد قمنا بتغليف MPSMatrixMultiplication للمتغير (حدد علامة الضرب Unicode (×) كمشغل infix لتمثيلها بشكل أنيق :-)).
بنية البيانات الأساسية للمتغير هي UnsafemutableBufferPointer الذي يشير إلى نوع البيانات، وقد اخترنا Float 32 بت من أجل البساطة. تحتفظ الفئة Variable بحجمين من البيانات، حيث يحتفظ count برقم العنصر الذي تم تخزينه بالفعل، والعدد actualCount هو حجم جميع العناصر التي تم تقريبها إلى حجم صفحة النظام الأساسي الذي تم الحصول عليه باستخدام getpagesize() .
نحافظ على هاتين القيمتين للتأكد من أن makeBuffer(bytesNoCopy:) ينشئ المخزن المؤقت مباشرة على منطقة VM المحددة ويتجنب إعادة التخصيص الزائدة عن الحاجة مما يقلل من الحمل. إذا كانت الذاكرة التي سيتم تمريرها إلى Metal غير محاذية للصفحة، فلن يتمكن Metal من استخدام هذه الذاكرة كمخزن مؤقت للإدخال أو الإخراج. سيتعين علينا استخدام طريقة makeBuffer(bytes:) التي ستقوم بإنشاء مخزن مؤقت جديد ونسخ البيانات من موقع ذاكرة الإدخال. لذلك نحتاج دائمًا إلى تخصيص ذاكرة أكبر مما هو مطلوب للتأكد من أن جميع الذكريات في Variable تتماشى مع الصفحة. لذا، نحتاج إلى قيمتين لتتبع مدى حجم هذا الجزء من الذاكرة بالضبط وما الحجم الذي يجب أن نستخدمه.
3. عدد العناصر التي تمت معالجتها بواسطة خيط واحد
لقد حاولنا تعيين خيط واحد إلى عدة عناصر، من 2 إلى 16 عنصرًا لكل خيط، وكان الأداء هو نفسه تقريبًا ولكن تمت إضافة الكثير من التعقيد إلى مشروعنا، لذلك تجاهلنا هذا النهج.
جميع إصدارات وحدة المعالجة المركزية المذكورة أدناه هي رمز وحدة المعالجة المركزية الساذج أحادي الترابط دون تحسين SIMD. يتم تطبيق تحسين المترجم على المستوى -Ofast .
أداء تنفيذنا جيد، وليس جيدًا بما فيه الكفاية.
لقد استخدمنا iPhone 6s وMacBook Pro مقاس 15 بوصة كمنصة مرجعية. الأجهزة محددة أدناه:
MacBook Pro (Retina مقاس 15 بوصة، منتصف عام 2015)
ايفون 6 اس
بالمقارنة مع تنفيذ إصدار وحدة المعالجة المركزية الساذج دون التوازي، فإن إصدار وحدة معالجة الرسومات لدينا أسرع بأكثر من 60 مرة .
نظرًا لأن نموذج MNIST صغير جدًا، فقد لا تعكس نتائجه التسريع الدقيق. وليس لدينا نسخة أحادية الخيط تم تنفيذها بشكل جيد، ولا يمكننا إعطاء رقم تسريع دقيق. نظرًا لأن إصدار وحدة المعالجة المركزية بطيء جدًا، فإن سرعة التسريع في Tiny YOLO كبيرة جدًا بحيث لا يمكن تصديقها.
تجربة سمة الشبكة:
منيست:
يولو:
نتيجة القياس:
| ايفون 6 اس | منيست | يولو الصغيرة |
|---|---|---|
| وحدة المعالجة المركزية | 1500 مللي ثانية | 753 ثانية |
| GPU | 0.025 ثانية | 0.5 ثانية |
| تسريع | ~60x | ~1500x |
| ماك بوك برو | منيست | يولو الصغيرة |
|---|---|---|
| وحدة المعالجة المركزية | 650 مللي ثانية | 729 ثانية |
| GPU | 10 مللي ثانية | 0.028 ثانية |
| تسريع | ~65x | ~26000x |
استنادا إلى المعيار أعلاه يمكننا أن نرى أنه مع زيادة حجم المشكلة،
لماذا نقول أن تسريعنا ليس جيدًا بما فيه الكفاية؟ لأنه عند المقارنة بتطبيق Apple الرسمي لـ MPSCNNConvolution ، فإننا نحقق سرعة تبلغ حوالي الثلث فقط، مما يعني أنه لا يزال هناك مساحة كبيرة للتحسين. تعتمد هذه المقارنة على تطبيق مفتوح المصدر لـ YOLO على iPhone باستخدام MPSCNNConvolution الرسمي الذي يمكنه التعرف على حوالي 5 صور في الثانية بينما يمكن لتطبيقنا أن يحقق فقط صورتين في الثانية.
ونظرًا لضيق الوقت، لم نتمكن من إنشاء إصدار أساسي أفضل وإصدار موازٍ لوحدة المعالجة المركزية لإجراء الاختبار المعياري، مما يجعل رقم السرعة كبيرًا جدًا.
كما أنه من المفيد الإبلاغ عن مكاسب الأداء على أحجام مختلفة للمشكلة. كما نرى، فإن MNIST لديها 0.1 مليون وزن فقط بينما لدى Tiny YOLO 17 مليونًا. يعد Tiny YOLO أكثر تعقيدًا من MNIST ولكن وقت تشغيل إصدار GPU لم يتوسع كثيرًا. وهذا مرة أخرى بسبب قانون أمدال. في كل مرة يتم فيها تشغيل مهمة GPU، يجب تشفير أوامر GPU المقابلة في المخزن المؤقت للأوامر. هذه العملية مسلسلة بطبيعتها. عندما يكون حجم المشكلة صغيرًا، تساهم هذه العملية كثيرًا في إجمالي وقت التشغيل، لذلك من خلال موازنة مرحلة استدلال الشبكة العصبية في MINST قد لا تحصل على نفس السرعة كما في Tiny YOLO، حيث يكون الحمل الزائد لوقت التشغيل مهملاً.
ما الذي حد من سرعتك؟
if و for s التي قد تسبب التباعد، مما يؤدي إلى سوء استخدام SIMD.تحليل أعمق: تفصيل وقت التنفيذ للمرحلة المختلفة.
خذ Tiny YOLO كمثال، في عينة تم تشغيلها بإجمالي وقت تشغيل يبلغ 227 مللي ثانية على جهاز Macbook، استخدمت الطبقات التلافيفية 207 مللي ثانية، أي 92% من إجمالي وقت التشغيل. استخدمت طبقات التجميع 14 مللي ثانية (6%)، واستخدمت ReLU 6 مللي ثانية (2%). وفقًا لقانون أمدال، إذا أردنا تحسين الأداء بشكل أكبر، فيجب علينا بالتأكيد مواصلة العمل على الطبقة التلافيفية.
بشكل عام، نعتقد أن اختيارنا للإطار المعدني لتسريع الشبكة العصبية على أجهزة iOS وmacOS هو اختيار سليم، خاصة لأجهزة iOS. نظرًا لأنه يحتوي على عدد أقل من النوى، حتى مع تعليمات SIMD، فمن غير المرجح أن تحصل نسخة وحدة المعالجة المركزية المضبوطة جيدًا على أداء مماثل لإصدار وحدة معالجة الرسومات.
يتم تنفيذ العمل المتساوي من قبل كلا أعضاء الفريق.
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


