Image to text chrome extension
1.0.0
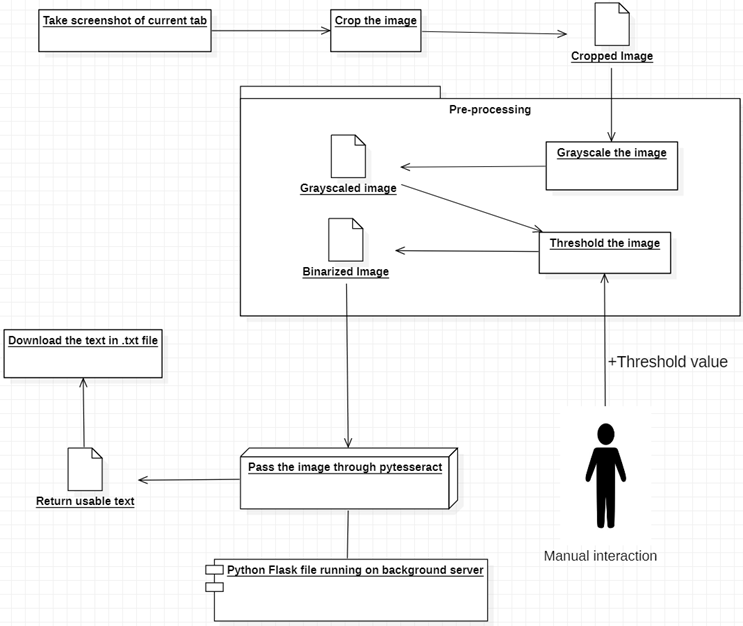
امتداد Chrome يمكنه التعرف على أي نوع من النص في متصفحك من أي فيديو أو صورة باستخدام مفهوم التعرف الضوئي على الحروف. التعرف الضوئي على الحروف (OCR) هو الشكل المختصر للتعرف البصري على الأحرف أو في نصوص أخرى للبحث عن الكلمات في الصور. لقد أصدرت Google سابقًا محركًا يسمى Tesseract OCR، وهذا يعني أن Google توفر لك برنامجًا تم تدريبه بالفعل على التعرف على النصوص عليه، لذلك لا يتعين علي القيام بأشياء معقدة مثل تدريب البيانات على التعرف الضوئي على الحروف بنفسي. ولكن للحصول على مزيد من الدقة، يتعين علينا معالجة الصورة مسبقًا قبل تمريرها عبر Tesseract، حيث أن Tesseract لديه بعض الظروف المحددة مسبقًا والتي يجب اتباعها للحصول على نتيجة دقيقة. لذا، بالنسبة لوظيفة الامتداد الخاص بنا، فإنه يأخذ أولاً لقطة شاشة من علامة التبويب المفتوحة حاليًا، ثم يقطع الجزء المطلوب باستخدام اللوحة القماشية ويضبطه باستخدام الحد الثنائي بحيث يمكنه ملء متطلبات التعرف الضوئي على الحروف لإعطاء نتائج أكثر دقة. ثم أرسله إلى pytesseract (إصدار Python من Tesseract) حتى يتمكن من تحويله. في النهاية، احصل على النص وقم بتنزيله بتنسيق ملف .txt. بحيث يمكن للمستخدم فتحه في المفكرة أو أي محرر نصوص آخر ومقارنة النص وتعديله إذا لزم الأمر.
كثيرًا ما أواجه مقتطفات من التعليمات البرمجية على موقع youtube أو أي موقع ويب آخر، والآن أقدر بشدة الجهد الذي يبذله صانعو البرامج التعليمية في مقاطع الفيديو الخاصة بهم في كل مرة أواجه فيها جزءًا من التعليمات البرمجية التي لا توفر رابطًا لتنزيلها أو نسخها. لذا، للحصول على أكواد من مقاطع الفيديو هذه، قمت بإنشاء هذا المشروع بمساعدة البرنامج المساعد tesseract حتى أتمكن من استخراج النص من مقاطع الفيديو أو الصور هذه.
يمكن العثور على تنفيذ الوحدات والعرض التوضيحي في ملف ppt.
pip install pytesseract
npm i flask
ملف jQuery min مرفق مع الملفات في حالة رغبتك في تغييره أو استخدام طريقة cdn يمكنك تغييره.


