Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript ؟Browser بلا رأسقد يكون تجريف معظم مواقع الويب أمرًا سهلاً نسبيًا. لقد تم بالفعل تناول هذا الموضوع بإسهاب في هذا البرنامج التعليمي. ومع ذلك، هناك العديد من المواقع التي لا يمكن كشطها باستخدام نفس الطريقة. والسبب هو أن هذه المواقع تقوم بتحميل المحتوى ديناميكيًا باستخدام JavaScript.
تُعرف هذه التقنية أيضًا باسم AJAX (جافا سكريبت غير المتزامن وXML). تاريخيًا، تم تضمين هذا المعيار في إنشاء كائن XMLHttpRequest لاسترداد XML من خادم الويب دون إعادة تحميل الصفحة بأكملها. في هذه الأيام، نادرا ما يتم استخدام هذا الكائن مباشرة. عادة، يتم استخدام برنامج تضمين مثل jQuery لاسترداد محتوى مثل JSON أو HTML جزئي أو حتى الصور.
لاستخراج صفحة ويب عادية، يلزم وجود مكتبتين على الأقل. تقوم مكتبة requests بتنزيل الصفحة. بمجرد أن تصبح هذه الصفحة متاحة كسلسلة HTML، فإن الخطوة التالية هي تحليلها ككائن BeautifulSoup. يمكن بعد ذلك استخدام كائن BeautifulSoup هذا للعثور على بيانات محددة.
فيما يلي مثال بسيط لبرنامج نصي يطبع النص داخل عنصر h1 مع تعيين id على firstHeading .
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert Einsteinلاحظ أننا نعمل مع الإصدار 4 من مكتبة Beautiful Soup. تم إيقاف الإصدارات السابقة. قد ترى أن Beautiful Soup 4 مكتوب على أنه Beautiful Soup أو BeautifulSoup أو حتى bs4. جميعهم يشيرون إلى نفس مكتبة الحساء 4 الجميلة.
لن يعمل نفس الرمز إذا كان الموقع ديناميكيًا. على سبيل المثال، يحتوي نفس الموقع على نسخة ديناميكية على https://quotes.toscrape.com/js/ (لاحظ js في نهاية عنوان URL هذا).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output والسبب هو أن الموقع الثاني ديناميكي حيث يتم إنشاء البيانات باستخدام JavaScript .
هناك طريقتان للتعامل مع مثل هذه المواقع.
يتم تناول هذين النهجين بالتفصيل في هذا البرنامج التعليمي.
ومع ذلك، نحتاج أولاً إلى فهم كيفية تحديد ما إذا كان الموقع ديناميكيًا أم لا.
إليك أسهل طريقة لتحديد ما إذا كان موقع الويب ديناميكيًا باستخدام Chrome أو Edge. (يستخدم كلا هذين المتصفحين Chromium أسفل الغطاء).
افتح أدوات المطور بالضغط على المفتاح F12 . تأكد من أن التركيز على أدوات المطور واضغط على مجموعة المفاتيح CTRL+SHIFT+P لفتح قائمة الأوامر.
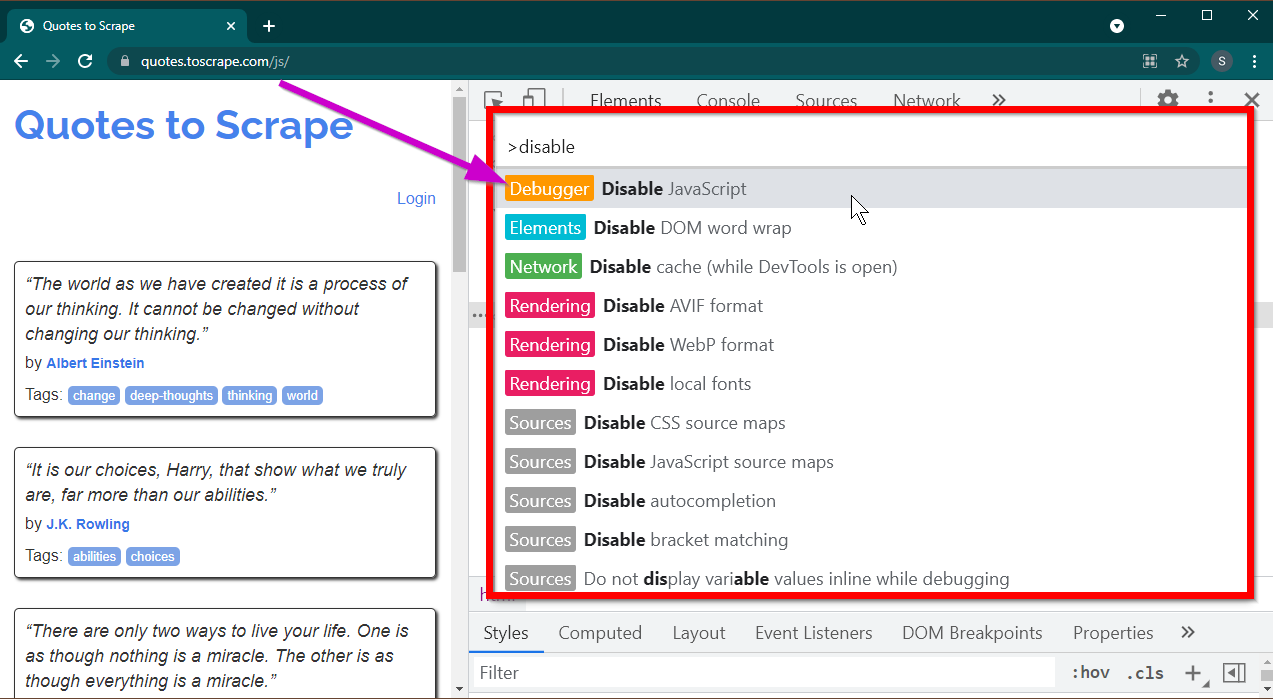
وسوف تظهر الكثير من الأوامر. ابدأ بكتابة disable وسيتم تصفية الأوامر لإظهار Disable JavaScript . حدد هذا الخيار لتعطيل JavaScript .
الآن قم بإعادة تحميل هذه الصفحة بالضغط على Ctrl+R أو F5 . سيتم إعادة تحميل الصفحة.
إذا كان هذا موقعًا ديناميكيًا، فسيختفي الكثير من المحتوى:
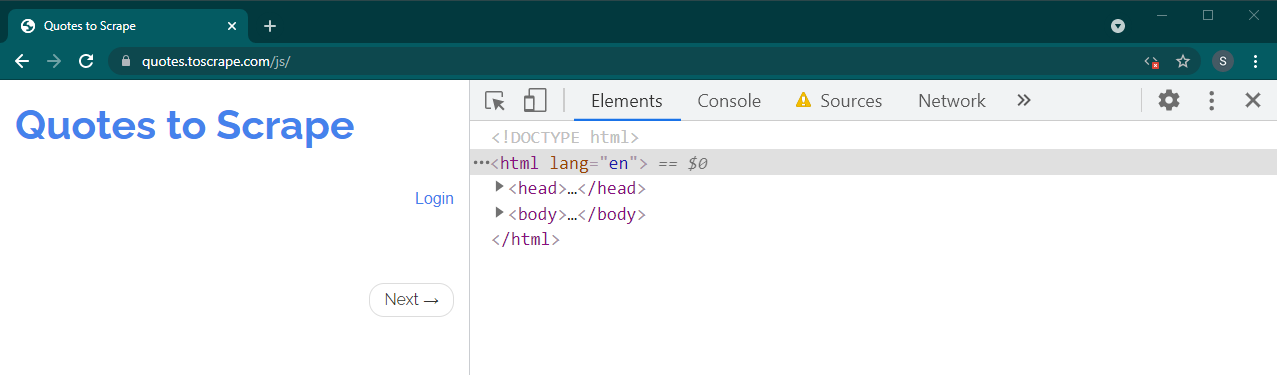
في بعض الحالات، ستظل المواقع تعرض البيانات ولكنها ستعود إلى الوظائف الأساسية. على سبيل المثال، يحتوي هذا الموقع على تمرير لا نهائي. إذا تم تعطيل JavaScript، فإنه يعرض ترقيم الصفحات العادي.
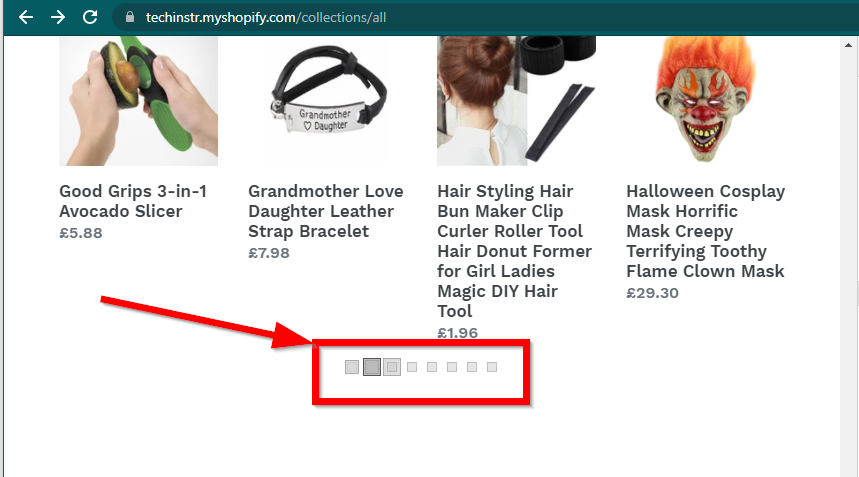 | 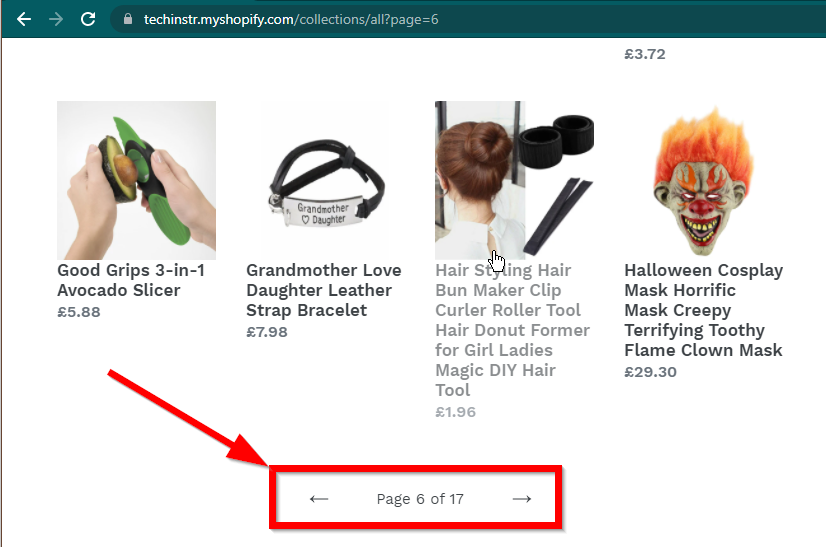 |
|---|---|
| تم تمكين جافا سكريبت | جافا سكريبت معطل |
السؤال التالي الذي يجب الإجابة عليه هو إمكانيات BeautifulSoup.
JavaScript ؟الجواب القصير هو لا.
من المهم فهم كلمات مثل التحليل والعرض. التحليل هو ببساطة تحويل تمثيل سلسلة لكائن Python إلى كائن فعلي.
إذن ما هو التقديم؟ العرض هو في الأساس تفسير HTML وJavaScript وCSS والصور إلى شيء نراه في المتصفح.
Beautiful Soup هي مكتبة Python لسحب البيانات من ملفات HTML. يتضمن ذلك تحليل سلسلة HTML في كائن BeautifulSoup. للتحليل، نحتاج أولاً إلى HTML كسلسلة للبدء بها. لا تحتوي مواقع الويب الديناميكية على البيانات بتنسيق HTML مباشرة. وهذا يعني أن BeautifulSoup لا يمكنه العمل مع مواقع الويب الديناميكية.
يمكن لمكتبة السيلينيوم أتمتة تحميل وعرض مواقع الويب في متصفح مثل Chrome أو Firefox. على الرغم من أن السيلينيوم يدعم سحب البيانات من HTML، فمن الممكن استخراج HTML كامل واستخدام Beautiful Soup بدلاً من ذلك لاستخراج البيانات.
لنبدأ في تجريف الويب الديناميكي باستخدام Python باستخدام السيلينيوم أولاً.
يتضمن تثبيت السيلينيوم تثبيت ثلاثة أشياء:
المتصفح الذي تختاره (والذي لديك بالفعل):
برنامج التشغيل للمتصفح الخاص بك:
حزمة بايثون السيلينيوم:
pip install seleniumconda-forge . conda install -c conda-forge selenium الهيكل الأساسي لبرنامج Python النصي لتشغيل المتصفح وتحميل الصفحة ثم إغلاق المتصفح بسيط:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()الآن بعد أن أصبح بإمكاننا تحميل الصفحة في المتصفح، فلننظر في استخراج عناصر محددة. هناك طريقتان لاستخراج العناصر: السيلينيوم والحساء الجميل.
هدفنا في هذا المثال هو العثور على عنصر المؤلف.
قم بتحميل الموقع https://quotes.toscrape.com/js/ في Chrome، وانقر بزر الماوس الأيمن فوق اسم المؤلف، ثم انقر فوق Inspect. يجب أن يؤدي هذا إلى تحميل أدوات المطور مع تمييز عنصر المؤلف على النحو التالي:
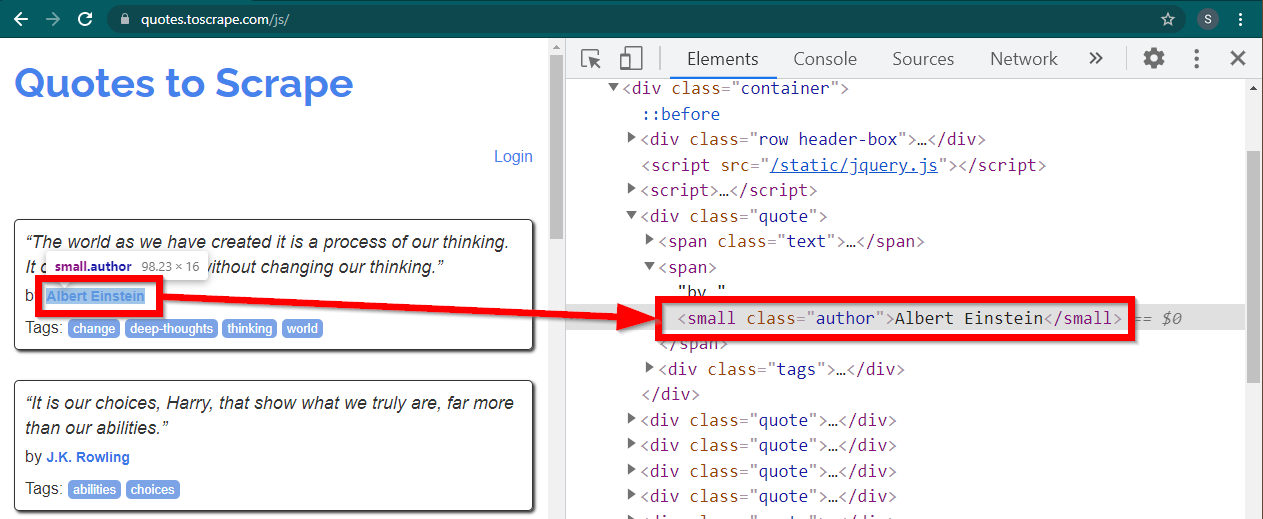
هذا عنصر small تم تعيين سمة class على author .
< small class =" author " > Albert Einstein </ small >يسمح السيلينيوم بطرق مختلفة لتحديد عناصر HTML. هذه الأساليب جزء من كائن برنامج التشغيل. بعض الطرق التي يمكن أن تكون مفيدة هنا هي كما يلي:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )هناك طرق قليلة أخرى، قد تكون مفيدة لسيناريو آخر. هذه الطرق هي كما يلي:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) ربما تكون الطرق الأكثر فائدة هي find_element(By.CSS_SELECTOR) و find_element(By.XPATH) . يجب أن تكون أي من هاتين الطريقتين قادرة على تحديد معظم السيناريوهات.
دعونا نعدل الكود بحيث يمكن طباعة المؤلف الأول.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()ماذا لو كنت تريد طباعة جميع المؤلفين؟
جميع أساليب find_element لها نظير - find_elements . لاحظ الجمع. للعثور على جميع المؤلفين، ما عليك سوى تغيير سطر واحد:
elements = driver . find_elements ( By . CLASS_NAME , "author" )يؤدي هذا إلى إرجاع قائمة العناصر. يمكننا ببساطة تشغيل حلقة لطباعة جميع المؤلفين:
for element in elements :
print ( element . text )ملاحظة: الكود الكامل موجود في ملف الكود selenium_example.py.
ومع ذلك، إذا كنت مرتاحًا بالفعل مع BeautifulSoup، فيمكنك إنشاء كائن BeautifulSoup.
كما رأينا في المثال الأول، يحتاج كائن Beautiful Soup إلى HTML. بالنسبة لمسح المواقع الثابتة على الويب، يمكن استرداد HTML باستخدام مكتبة requests . الخطوة التالية هي تحليل سلسلة HTML هذه إلى كائن BeautifulSoup.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )دعنا نتعرف على كيفية إنشاء موقع ويب ديناميكي باستخدام BeautifulSoup.
يبقى الجزء التالي دون تغيير عن المثال السابق.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) يتوفر HTML المعروض للصفحة في السمة page_source .
soup = BeautifulSoup ( driver . page_source , "lxml" )بمجرد توفر كائن الحساء، يمكن استخدام جميع أساليب الحساء الجميل كالمعتاد.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )ملاحظة: كود المصدر الكامل موجود في selenium_bs4.py
Browser بلا رأسبمجرد أن يصبح البرنامج النصي جاهزًا، ليست هناك حاجة لأن يكون المتصفح مرئيًا عند تشغيل البرنامج النصي. يمكن إخفاء المتصفح وسيظل البرنامج النصي يعمل بشكل جيد. يُعرف هذا السلوك للمتصفح أيضًا بالمتصفح بدون رأس.
لجعل المتصفح بدون رأس، قم باستيراد ChromeOptions . بالنسبة للمتصفحات الأخرى، تتوفر فئات الخيارات الخاصة بها.
from selenium . webdriver import ChromeOptions الآن، قم بإنشاء كائن من هذه الفئة، وقم بتعيين السمة headless على True.
options = ChromeOptions ()
options . headless = Trueوأخيرًا، أرسل هذا الكائن أثناء إنشاء مثيل Chrome.
driver = Chrome ( ChromeDriverManager (). install (), options = options )الآن، عند تشغيل البرنامج النصي، لن يكون المتصفح مرئيًا. راجع ملف selenium_bs4_headless.py للاطلاع على التنفيذ الكامل.
يعد تحميل المتصفح أمرًا مكلفًا، فهو يستهلك وحدة المعالجة المركزية (CPU) وذاكرة الوصول العشوائي (RAM) والنطاق الترددي الذي لا حاجة إليه حقًا. عندما يتم تجريف موقع ويب، تكون البيانات هي المهمة. ليست هناك حاجة حقًا إلى كل تلك CSS والصور والعرض.
الطريقة الأسرع والأكثر فعالية لاستخراج صفحات الويب الديناميكية باستخدام Python هي تحديد المكان الفعلي الذي توجد فيه البيانات.
هناك مكانان يمكن أن توجد فيهما هذه البيانات:
<script>دعونا نلقي نظرة على بعض الأمثلة.
افتح https://quotes.toscrape.com/js في Chrome. بمجرد تحميل الصفحة، اضغط على Ctrl+U لعرض المصدر. اضغط على Ctrl+F لإظهار مربع البحث، ابحث عن ألبرت.
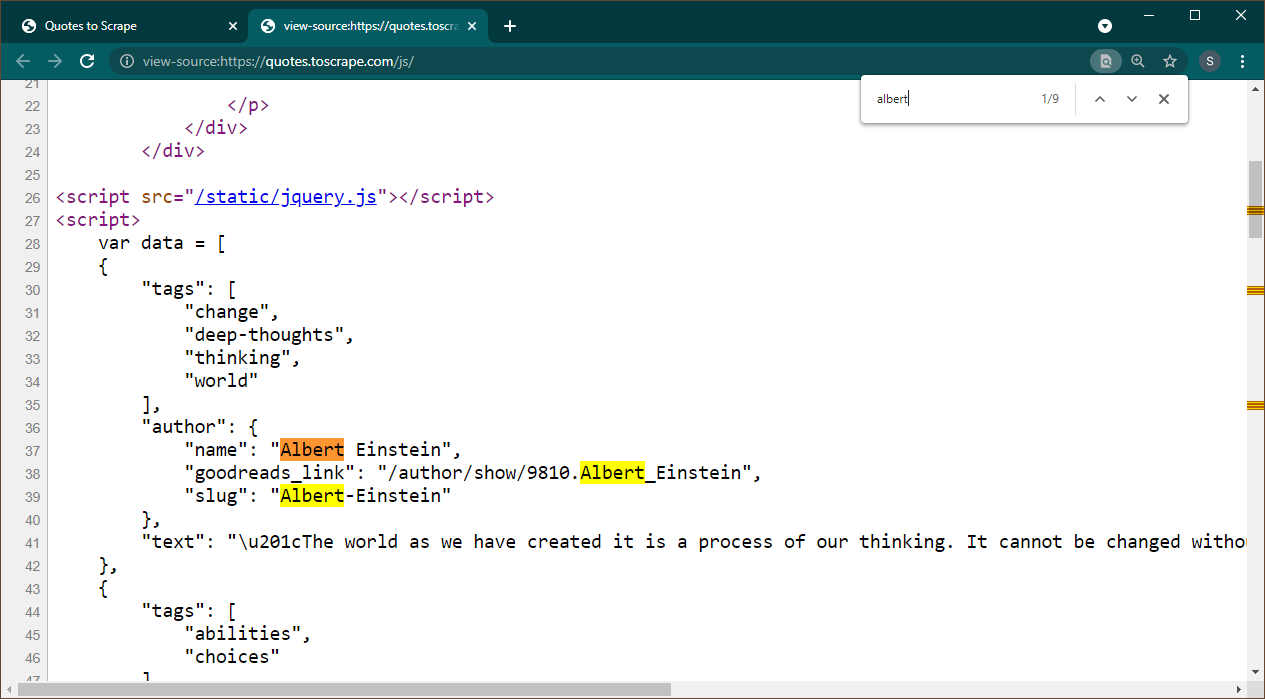
يمكننا أن نرى على الفور أن البيانات مضمنة ككائن JSON في الصفحة. لاحظ أيضًا أن هذا جزء من برنامج نصي حيث يتم تعيين هذه البيانات إلى متغير data .
في هذه الحالة يمكننا استخدام مكتبة الطلبات للحصول على الصفحة واستخدام Beautiful Soup لتحليل الصفحة والحصول على عنصر البرنامج النصي.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) لاحظ أن هناك عناصر <script> متعددة. الذي يحتوي على البيانات التي نحتاجها لا يحتوي على سمة src . دعونا نستخدم هذا لاستخراج عنصر البرنامج النصي.
script_tag = soup . find ( "script" , src = None )تذكر أن هذا البرنامج النصي يحتوي على تعليمات برمجية JavaScript أخرى بخلاف البيانات التي نهتم بها. ولهذا السبب، سنستخدم تعبيرًا عاديًا لاستخراج هذه البيانات.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )متغير البيانات عبارة عن قائمة تحتوي على عنصر واحد. يمكننا الآن استخدام مكتبة JSON لتحويل بيانات السلسلة هذه إلى كائن بيثون.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )سيكون الإخراج هو كائن بايثون:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................لا يمكن تحويل هذه القائمة إلى أي تنسيق كما هو مطلوب. لاحظ أيضًا أن كل عنصر يحتوي على رابط لصفحة المؤلف. هذا يعني أنه يمكنك قراءة هذه الروابط وإنشاء عنكبوت للحصول على البيانات من كل هذه الصفحات.
تم تضمين هذا الرمز الكامل في data_in_same_page.py.
يمكن للمواقع الديناميكية لكشط الويب أن تتبع مسارًا مختلفًا تمامًا. في بعض الأحيان يتم تحميل البيانات على صفحة منفصلة تمامًا. أحد الأمثلة على ذلك هو Librivox.
افتح أدوات المطور، وانتقل إلى علامة التبويب "الشبكة" وقم بالتصفية حسب XHR. الآن افتح هذا الرابط أو ابحث عن أي كتاب. سترى أن البيانات عبارة عن HTML مضمن في JSON.
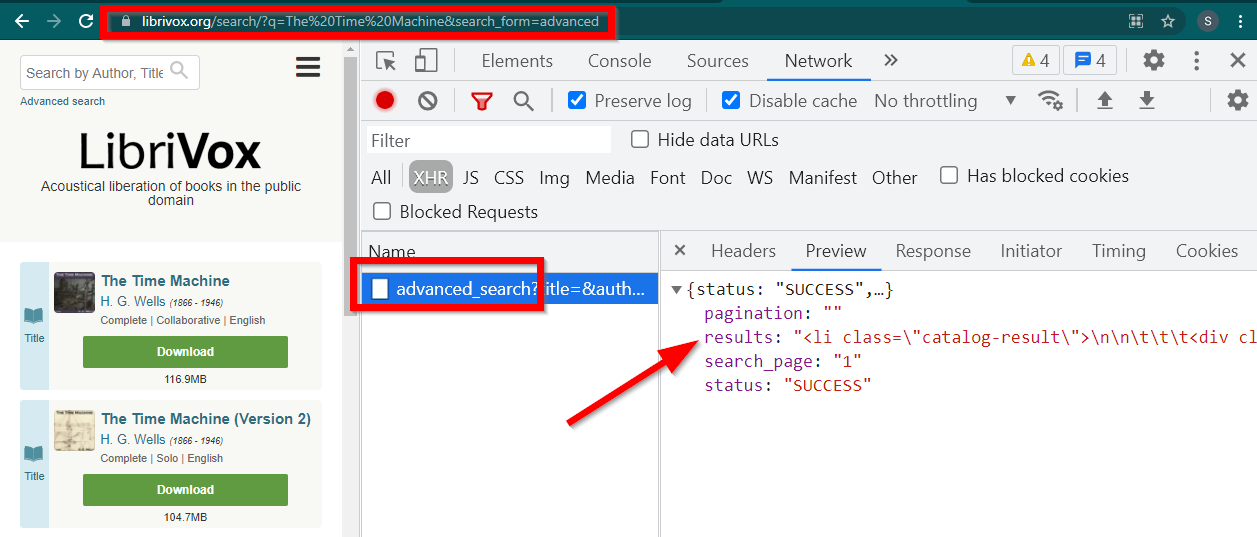
لاحظ بعض الأشياء:
عنوان URL الذي يعرضه المتصفح هو https://librivox.org/search/?q=...
البيانات موجودة في https://librivox.org/advanced_search?....
إذا نظرت إلى الرؤوس، ستجد أن صفحة البحث المتقدم يتم إرسال رأس خاص X-Requested-With: XMLHttpRequest
إليك مقتطف لاستخراج هذه البيانات:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )يتم تضمين الكود الكامل في ملف librivox.py.


