disclosure backend static
1.0.0
إن الريبو disclosure-backend-static هو الواجهة الخلفية التي تعمل على تشغيل Open Disclosure California.
لقد تم إنشاؤه على عجل قبل انتخابات عام 2016، وبالتالي تم تصميمه حول فلسفة "إنجاز المهمة". في ذلك الوقت، كنا قد صممنا بالفعل واجهة برمجة التطبيقات وقمنا ببناء (معظم) واجهة أمامية؛ تم إنشاء هذا الريبو لتنفيذ تلك في أسرع وقت ممكن.
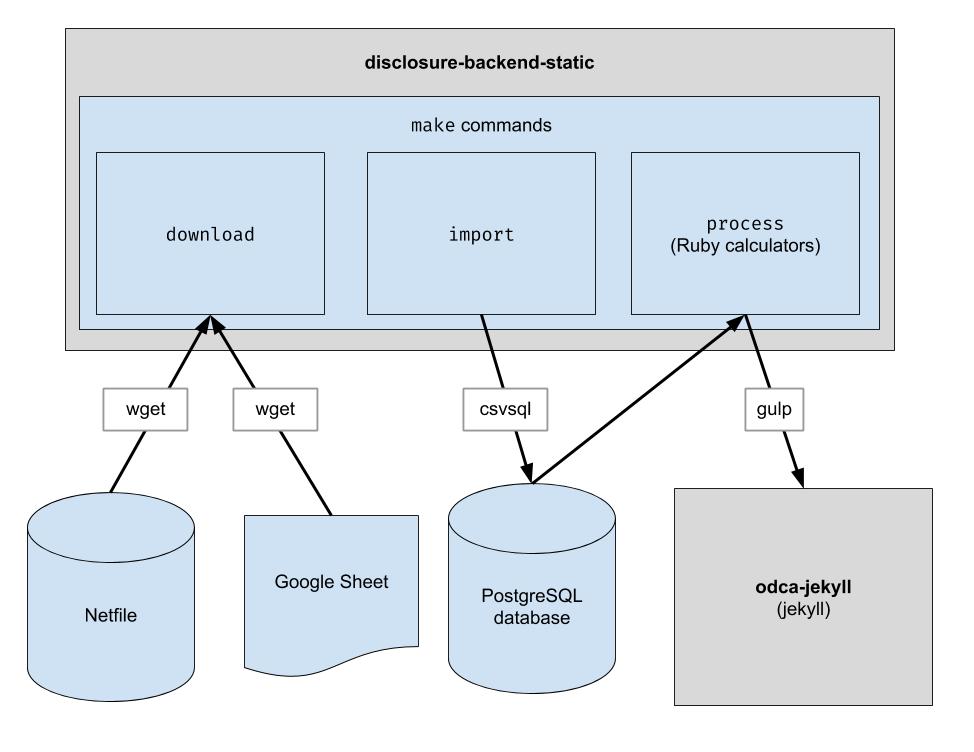
ينفذ هذا المشروع خط أنابيب ETL أساسيًا لتنزيل بيانات Oakland netfile، وتنزيل بيانات CSV برعاية بشرية لـ Oakland، والجمع بين الاثنين. الإخراج عبارة عن دليل لملفات JSON التي تحاكي بنية واجهة برمجة التطبيقات الحالية، لذا لن تكون هناك حاجة إلى تغييرات في كود العميل.
.ruby-version ) ملاحظة: لا تحتاج إلى تشغيل هذه الأوامر للتطوير على الواجهة الأمامية. كل ما عليك فعله هو استنساخ المستودع المجاور لمستودع الواجهة الأمامية.
إذا كنت تخطط لتعديل كود الواجهة الخلفية، فاتبع هذه الخطوات لإعداد جميع تبعيات التطوير الضرورية، بما في ذلك قاعدة بيانات PostgreSQL الجديدة وPython 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip بدلاً من pip لضمان استخدام Python 3: python3 -m pip install ...
pip نظامك تشير إلى Python 3، فيمكنك استخدام pip مباشرةً: pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
تم إعداد هذا المستودع للعمل في حاوية ضمن Codespaces. بمعنى آخر، يمكنك بدء تشغيل بيئة تم إعدادها بالفعل دون الحاجة إلى القيام بأي من خطوات التثبيت المطلوبة لإعداد بيئة محلية. يمكن استخدام هذا كطريقة لاستكشاف أخطاء التعليمات البرمجية وإصلاحها قبل الالتزام بمسار الإنتاج. قد تكون المعلومات التالية مفيدة للبدء في استخدام Codespaces:
Code وانقر فوق علامة التبويب Codespaces في القائمة المنسدلة/workspace في صفحة الويب، والتي ستبدو مألوفة إذا كنت قد عملت مع VS Code من قبلmake downloadpsql في الجهاز للاتصال بالخادمmake import بملء قاعدة بيانات Postgresgit pushتم تكوين هذا المستودع أيضًا للتشغيل داخل حاوية Docker. يشبه هذا Codespaces إلا أنه يمكنك استخدام أي بيئة تطوير متكاملة (IDE) والإعداد المحلي الذي تفضله. إليك كيفية البدء في استخدام Docker مع VSCode:
قم بتنزيل ملفات البيانات الخام. ما عليك سوى تشغيل هذا مرة واحدة كل فترة للحصول على أحدث البيانات.
$ make download
قم باستيراد البيانات إلى قاعدة البيانات لتسهيل معالجتها. ما عليك سوى تشغيل هذا بعد تنزيل البيانات الجديدة.
$ make import
تشغيل الآلات الحاسبة. يتم إخراج كل شيء إلى مجلد "الإنشاء".
$ make process
بشكل اختياري، قم بإعادة فهرسة مخرجات البناء في Algolia. (تتطلب إعادة الفهرسة متغيرات البيئة ALGOLIASEARCH_APPLICATION_ID وALGOLIASEARCH_API_KEY).
$ make reindex
إذا كنت تريد تقديم ملفات JSON الثابتة عبر خادم ويب محلي:
$ make run
عند تشغيل make import ، يتم إنشاء عدد من جداول postgres لاستيراد البيانات التي تم تنزيلها. يتم تعريف مخطط هذه الجداول بشكل صريح في دليل dbschema وقد يلزم تحديثه في المستقبل لاستيعاب البيانات المستقبلية. قد لا يكون حجم الأعمدة التي تحتوي على بيانات السلسلة كبيرًا بما يكفي للبيانات المستقبلية. على سبيل المثال، إذا كان عمود الاسم يقبل أسماء مكونة من 20 حرفًا على الأكثر وفي المستقبل، لدينا بيانات يبلغ طول الاسم فيها 21 حرفًا، فسوف تفشل عملية استيراد البيانات. عندما يحدث هذا، سيتعين علينا تحديث ملف المخطط المقابل في dbschema لدعم المزيد من الأحرف. ما عليك سوى إجراء التغيير وإعادة تشغيل make import للتحقق من نجاحه.
يُستخدم هذا المستودع لإنشاء ملفات البيانات التي يستخدمها موقع الويب. بعد تشغيل make process ، يتم إنشاء دليل build يحتوي على ملفات البيانات. يتم إيداع هذا الدليل في المستودع ثم يتم سحبه لاحقًا عند إنشاء موقع الويب. بعد إجراء تغييرات على التعليمات البرمجية، من المهم مقارنة دليل build الذي تم إنشاؤه بدليل build الذي تم إنشاؤه قبل تغيير التعليمات البرمجية والتحقق من أن التغييرات من تغييرات التعليمات البرمجية هي كما هو متوقع.
نظرًا لأن المقارنة الصارمة لجميع محتويات دليل build ستتضمن دائمًا التغييرات التي تحدث بشكل مستقل عن أي تغيير في التعليمات البرمجية، يجب على كل مطور أن يعرف هذه التغييرات المتوقعة من أجل إجراء هذا التحقق. لإزالة الحاجة إلى ذلك، يقوم ملف معين، bin/create-digests.py ، بإنشاء ملخصات لبيانات JSON في دليل build بعد استبعاد هذه التغييرات المتوقعة. للبحث عن التغييرات التي تستبعد هذه التغييرات المتوقعة، ما عليك سوى البحث عن تغيير في ملف build/digests.json .
حاليًا، هذه هي التغييرات المتوقعة التي تحدث بشكل مستقل عن أي تغيير في التعليمات البرمجية:
يتم استبعاد التغييرات المتوقعة قبل إنشاء ملخصات للبيانات الموجودة في دليل build . يمكن العثور على المنطق الخاص بذلك في الدالة clean_data الموجودة في الملف bin/create-digests.py . بعد تعديل الكود بحيث لم يعد التغيير المتوقع موجودًا، يمكن إزالة استبعاد هذا التغيير من clean_data . على سبيل المثال، لا يكون تقريب العوامات هو نفسه دائمًا في كل مرة يتم فيها تشغيل make process ، وذلك بسبب الاختلافات في البيئة. عندما يتم إصلاح الكود بحيث يكون تقريب الأعداد العشرية هو نفسه طالما لم تتغير البيانات، يمكن إزالة استدعاء round_float في clean_data .
تم إنشاء برنامج نصي إضافي لإنشاء تقرير يتيح مقارنة إجماليات المرشحين. البرنامج النصي هو bin/report-candidates.py ويقوم بإنشاء build/candidates.csv و build/candidates.xlsx . تتضمن التقارير قائمة بجميع المرشحين والإجماليات المحسوبة بطرق متعددة يجب أن يصل مجموعها إلى نفس العدد.
للتأكد من أن تغييرات مخطط قاعدة البيانات مرئية في طلبات السحب، يتم أيضًا حفظ مخطط postgres الكامل في ملف schema.sql في دليل build . نظرًا لأنه تتم إعادة إنشاء دليل build تلقائيًا لكل فرع في PR ويتم الالتزام به في المستودع، فإن أي تغيير في المخطط ناتج عن تغيير التعليمات البرمجية سيظهر اختلافًا في ملف schema.sql عند مراجعة PR.
يتم حساب كل مقياس عن المرشح بشكل مستقل. قد يكون المقياس شيئًا مثل "إجمالي المساهمات المستلمة" أو شيئًا أكثر تعقيدًا مثل "النسبة المئوية للمساهمات التي تقل عن 100 دولار أمريكي".
عند إضافة عملية حسابية جديدة، أول مكان جيد للبدء هو النموذج الرسمي 460. هل البيانات التي تبحث عنها مذكورة في هذا النموذج؟ إذا كان الأمر كذلك، فمن المحتمل أن تجده في قاعدة البيانات الخاصة بك بعد عملية الاستيراد. هناك أيضًا نموذجان آخران نستوردهما، مثل النموذج 496. (هذه هي أسماء الملفات الموجودة في دليل input . تحقق منها.)
يتم استيراد كل جدول من كل نموذج إلى جدول postgres منفصل. على سبيل المثال، يتم استيراد الجدول أ من النموذج 460 إلى جدول A-Contributions .
الآن بعد أن أصبح لديك طريقة للاستعلام عن البيانات، يجب أن تتوصل إلى استعلام SQL يحسب القيمة التي تحاول الحصول عليها. بمجرد أن تتمكن من التعبير عن الحساب الخاص بك كـ SQL، ضعه في ملف الآلة الحاسبة كما يلي:
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID .candidate.save_calculation .save_calculation . ستقوم هذه الطريقة بتسلسل الوسيطة الثانية الخاصة بها كـ JSON، حتى تتمكن من تخزين أي نوع من البيانات.candidate.calculation(:your_thing) . ستحتاج إلى إضافة هذا إلى استجابة API في ملف process.rb . هذه هي الطريقة التي تتدفق بها البيانات من خلال النهاية الخلفية. يتم سحب البيانات المالية من Netfile والتي يتم استكمالها بمعرفات ملفات تعيين جداول بيانات Google لمعلومات الاقتراع مثل أسماء المرشحين والمكاتب ومقاييس الاقتراع وما إلى ذلك. بمجرد تصفية البيانات وتجميعها وتحويلها، تستهلكها الواجهة الأمامية وتقوم بإنشاء HTML ثابت الواجهة الأمامية.
أثناء تثبيت الحزمة
error: use of undeclared identifier 'LZMA_OK'
يحاول:
brew unlink xz
bundle install
brew link xz
أثناء make download
wget: command not found
قم بتشغيل brew install wget .
أثناء make import
يبدو أن هناك مشكلة في أنظمة Macintosh التي تستخدم شرائح Apple.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
جرب ما يلي:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


